blog
How to Design a Geographically Distributed MariaDB Cluster

It is very common to see databases distributed across multiple geographical locations. One scenario for doing this type of setup is for disaster recovery, where your standby data center is located in a separate location than your main datacenter. It might as well be required so that the databases are located closer to the users.
The main challenge to achieving this setup is by designing the database in a way that reduces the chance of issues related to the network partitioning.
MariaDB Cluster can be a good choice to build such an environment for several reasons. We would like to discuss them here and also talk a bit about how such an environment may look like.
Why Use MariaDB Cluster for Geo-Distributed Environments?
First reason is that MariaDB Cluster can support multiple writers. This makes the write routing way easier to design – you just write to the local MariaDB nodes. Of course, given synchronous replication, latency impacts the write performance and you may see that your writes are getting slower if you spread your cluster too far geographically. After all, you can’t ignore the laws of physics and they say, as of now at least, that even the speed of light in fiber connections is limited. Any routers added on top of that will also increase latency even if only by a couple milliseconds.
Second, lag handling in MariaDB Cluster. Asynchronous replication is a subject for replication lag – slaves may not be up to date with the data if they struggle to apply all the changes in time. In MariaDB Cluster this is different – flow control is a mechanism that is intended to keep the cluster in sync. Well, almost – in some edge cases you can still observe lag. We are talking here about, typically, milliseconds, a couple seconds at most while in the asynchronous replication sky is the limit.
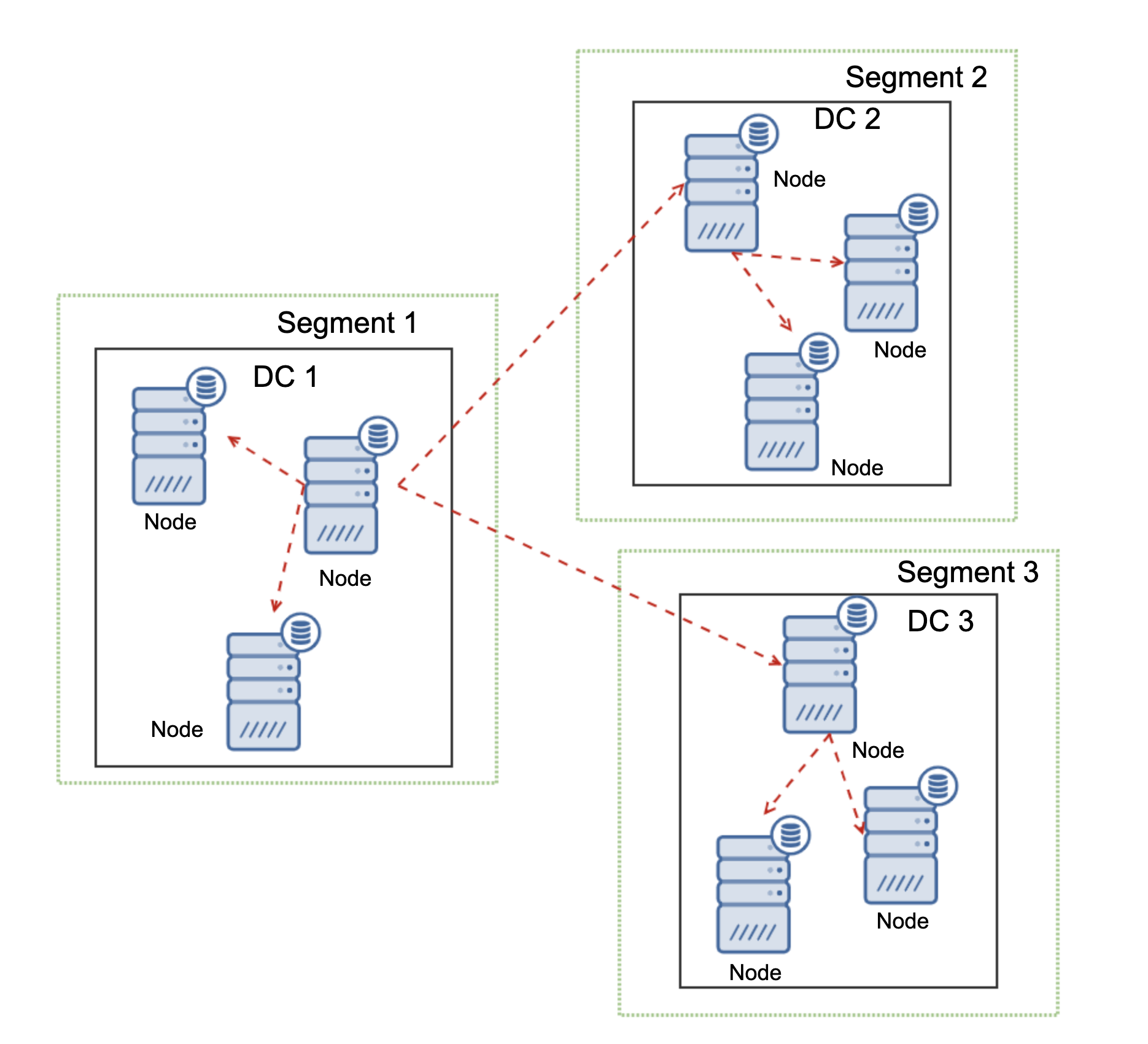
Third, segments. By default MariaDB CLuster uses all to all communication and every writeset is sent by the node to all other nodes in the cluster. This behavior can be changed using segments. Segments allow users to split MariaDB Clusters in several parts. Each segment may contain multiple nodes and it elects one of them as a relay node. Such nodes receive writesets from other segments and redistribute them across MariaDB nodes local to the segment. As a result, as you can see on the diagram above, it is possible to reduce the replication traffic going over WAN three times – just two “replicas” of the replication stream are being sent over WAN: one per datacenter compared to one per slave in asynchronous replication.
Finally, where MariaDB Cluster really shines is the handling of the network partitioning. MariaDB Cluster constantly monitors the state of the nodes in the cluster. Every node attempts to connect with its peers and exchange the state of the cluster. If a subset of nodes is not reachable, MariaDB attempts to relay the communication so if there is a way to reach those nodes, they will be reached.
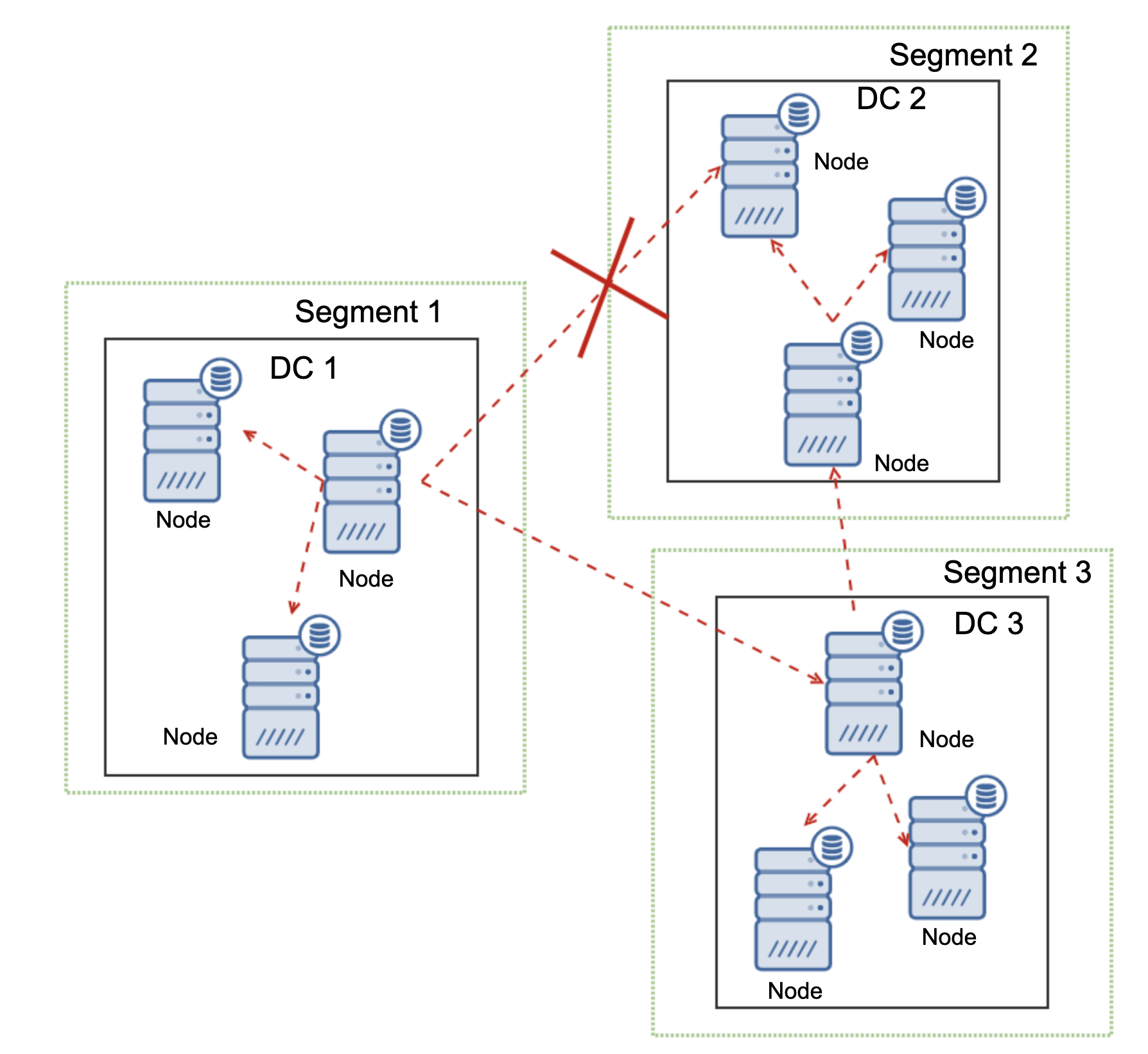
An example can be seen on the diagram above: DC 1 lost the connectivity with DC2 but DC2 and DC3 can connect. In this case one of the nodes in DC3 will be used to relay data from DC1 to DC2 ensuring that the intra-cluster communication can be maintained.
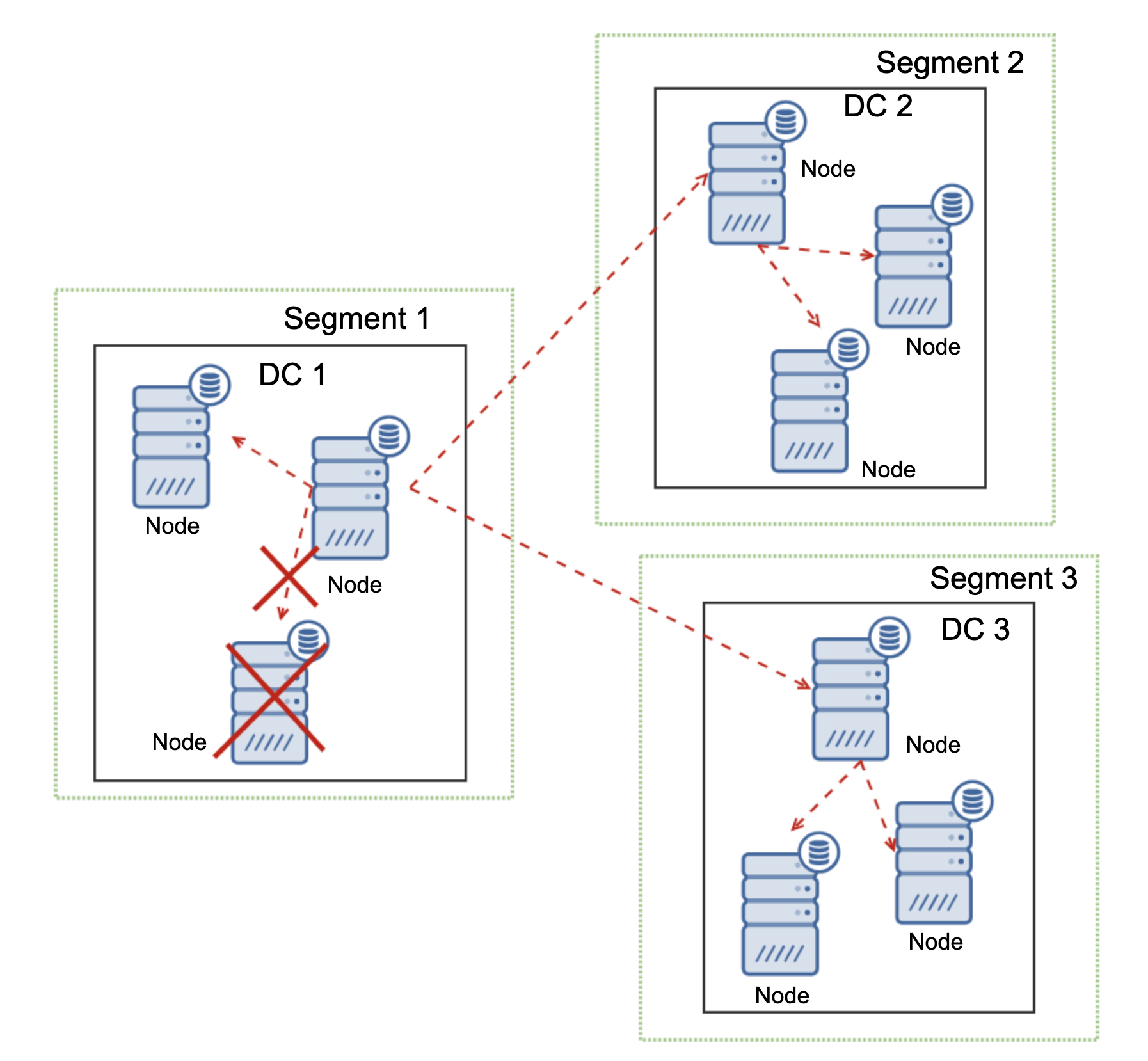
MariaDB is able to take actions based on the state of the cluster. It implements quorum – majority of the nodes have to be available in order for the cluster to be able to operate. If node gets disconnected from the cluster and cannot reach any other node, it will cease to operate.
As can be seen on the diagram above, there’s a partial loss of the network communication in DC1 and the affected node is removed from the cluster, ensuring that the application will not access outdated data.
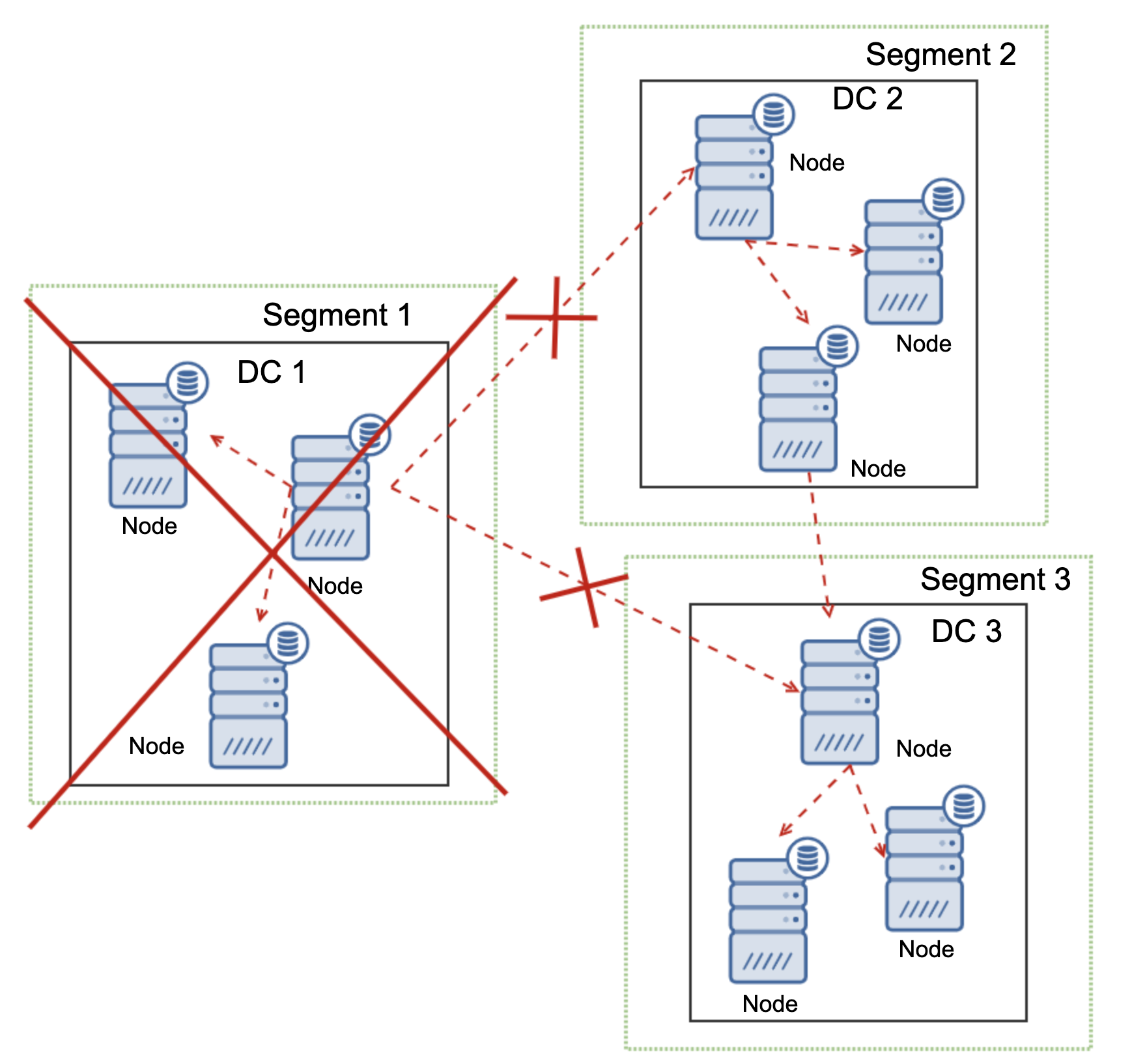
This is also true on a larger scale. The DC1 got all of its communication cut off. As a result, the whole datacenter has been removed from the cluster and neither of its nodes will serve the traffic. The rest of the cluster maintained majority (6 out of 9 nodes are available) and it reconfigured itself to keep the connection between DC 2 and DC3. In the diagram above we assumed the writer hits the node in DC2 but please keep in mind that MariaDB is capable of running with multiple writers.
Designing Geographically Distributed MariaDB Cluster
We went through some of the features that make MariaDB Cluster a nice fit for geo-distributed environments, let’s focus now a bit on the design. At the beginning, let’s explain what the environment we are working with. We will use three remote data centers, connected via Wide Area Network (WAN). Each datacenter will receive writes from local application servers. Reads will also be only local. This is intended to avoid unnecessary traffic crossing the WAN.
To make this blog less complicated, we won’t be going into details of how the connectivity should look like. We assume some sort of a properly configured, secure connection across all datacenters. VPN or other tools can be used to implement that.
We will use MaxScale as a loadbalancer. MaxScale will be deployed locally in each datacenter. It will also route traffic only to the local nodes. Remote nodes can always be added manually and we will explain cases where this might be a good solution. Applications can be configured to connect to one of the local MaxScale nodes using a round-robin algorithm. We can as well use Keepalived and Virtual IP to route the traffic towards the single MaxScale node, as long as a single MaxScale node would be able to handle all of the traffic.
Another possible solution is to collocate MaxScale with application nodes and configure the application to connect to the proxy on the localhost. This approach works quite well under the assumption that it is unlikely that MaxScale will not be available yet the application would work ok on the same node. Typically what we see is either node failure or network failure, which would affect both MaxScale and application at the same time.
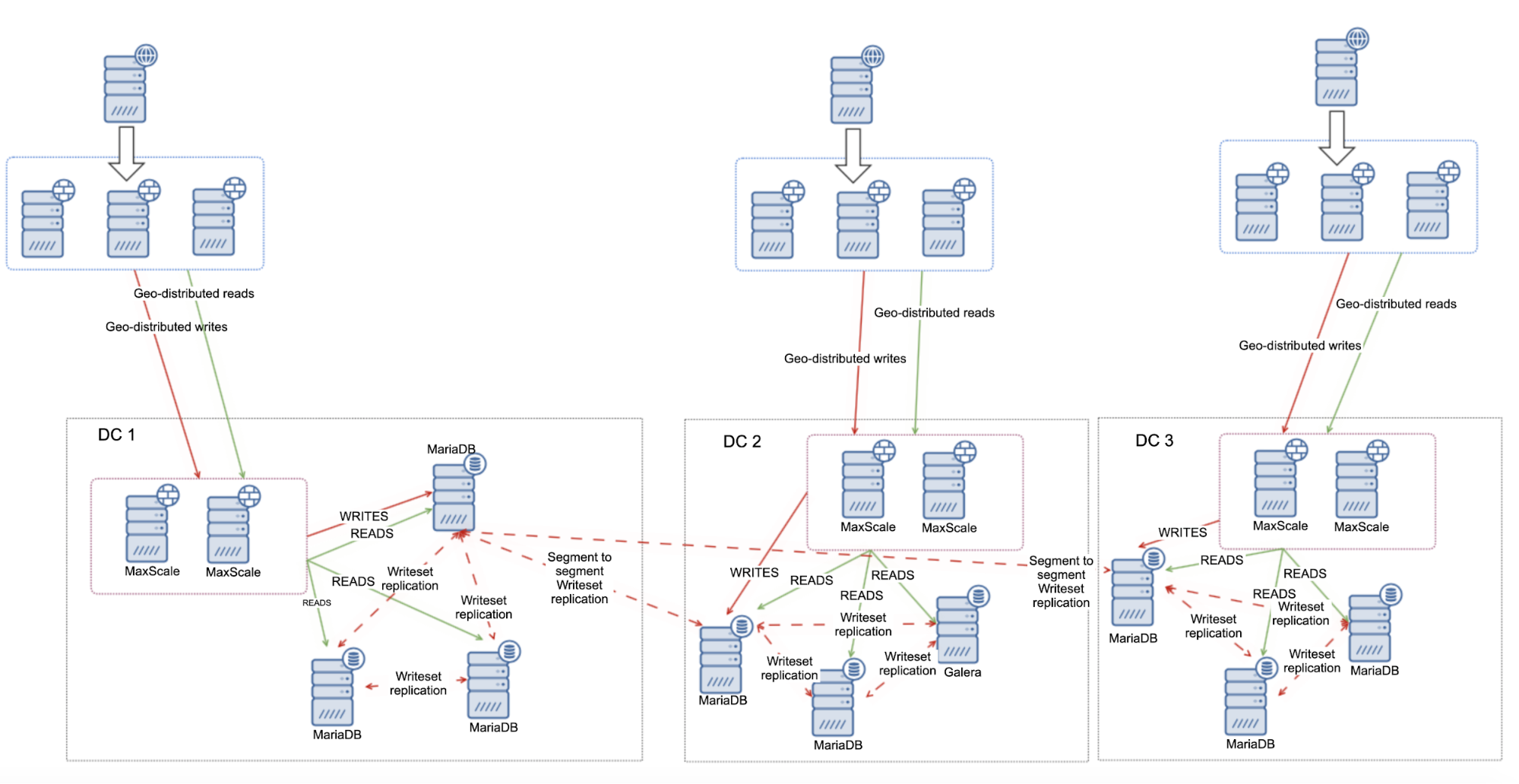
The diagram above shows the version of the environment, where MaxScale forms proxy farms – all proxy nodes with the same configuration, load balanced using Keepalived, or just simply round robin from the application across all MaxScale nodes. MaxScale is configured to distribute the workload across all MariaDB nodes in the local datacenter. One of those nodes would be picked as a node to send the writes to while SELECTs would be distributed across all nodes. Having one dedicated writer node in a datacenter helps to reduce the number of possible certification conflicts, leading to, typically, better performance. To reduce this even further we would have to start sending the traffic over the WAN connection, which is not ideal as the bandwidth utilization would significantly increase. Right now, with segments in place, only two copies of the writeset are being sent across datacenters – one per DC.
Conclusion
As you can see, MariaDB Cluster can easily be used to create geo-distributed clusters that can work even across the world. The limiting factor will be network latency. If it is too high, you may have to consider using separate MariaDB clusters connected using asynchronous replication.



