blog
A Guide to the MariaDB Columnstore for MySQL Admins

The typical MySQL DBA might be familiar working and managing an OLTP (Online Transaction Processing) database as part of their daily routine. You may be familiar with how it works and how to manage complex operations. While the default storage engine that MySQL ships is good enough for OLAP (Online Analytical Processing) it’s pretty simplistic, especially those who would like to learn artificial intelligence or who deal with forecasting, data mining, data analytics.
In this blog, we’re going to discuss the MariaDB ColumnStore. The content will be tailored for the benefit of the MySQL DBA who might have less understanding with the ColumnStore and how it might be applicable for OLAP (Online Analytical Processing) applications.
OLTP vs OLAP
OLTP
The typical MySQL DBA activity for dealing this type of data is by using OLTP (Online Transaction Processing). OLTP is characterized by large database transactions doing inserts, updates, or deletes. OLTP-type of databases are specialized for fast query processing and maintaining data integrity while being accessed in multiple environments. Its effectiveness is measured by the number of transactions per second (tps). It is fairly common for the parent-child relationship tables (after implementation of the normalization form) to reduce redundant data in a table.
Records in a table are commonly processed and stored sequentially in a row-oriented manner and are highly indexed with unique keys to optimize data retrieval or writes. This is also common for MySQL, especially when dealing with large inserts or high concurrent writes or bulk inserts. Most of the storage engines that MariaDB supports are applicable for OLTP applications – InnoDB (the default storage engine since 10.2), XtraDB, TokuDB, MyRocks, or MyISAM/Aria.
Applications like CMS, FinTech, Web Apps often deal with heavy writes and reads and often require high throughput. To make these applications work often requires deep expertise in high-availability, redundancy, resilience, and recovery.
OLAP
OLAP deals with the same challenges as OLTP, but uses a different approach (especially when dealing with data retrieval.) OLAP deals with larger datasets and is common for data warehousing, often used for business intelligence type of applications. It is commonly used for Business Performance Management, Planning, Budgeting, Forecasting, Financial Reporting, Analysis, Simulation Models, Knowledge Discovery, and Data Warehouse Reporting.
Data which is stored in OLAP is typically not as critical as that stored in OLTP. This is because most of the data can be simulated coming from OLTP and then can be fed to your OLAP database. This data is typically used for bulk loading, often needed for business analytics which eventually be rendered into visual graphs. OLAP also performs multidimensional analysis of business data and delivers results which can be used for complex calculations, trend analysis, or sophisticated data modeling.
OLAP usually stores data persistently using a columnar format. In MariaDB ColumnStore, however, the records are broken-out based on its columns and are stored separately into a file. This way data retrieval is very efficient, as it scans only the relevant column referred in your SELECT statement query.
Think of it like this, OLTP processing handles your daily and crucial data transactions that runs your business application, while OLAP helps you manage, predict, analyze, and better market your product – the building blocks of having a business application.
What is MariaDB ColumnStore?
MariaDB ColumnStore is a pluggable columnar storage engine that runs on MariaDB Server. It utilizes a parallel distributed data architecture while keeping the same ANSI SQL interface that is used across the MariaDB server portfolio. This storage engine has been around for a while, as it was originally ported from InfiniDB (A now defunct code which is still available on github.) It is designed for big data scaling (to process petabytes of data), linear scalability, and real-time response to analytics queries. It leverages the I/O benefits of columnar storage; compression, just-in-time projection, and horizontal & vertical partitioning to deliver tremendous performance when analyzing large data sets.
Lastly, MariaDB ColumnStore is the backbone of their MariaDB AX product as the main storage engine used by this technology.
How is MariaDB ColumnStore Different From InnoDB?
InnoDB is applicable for OLTP processing that requires your application to respond the fastest way possible. It’s useful if your application are dealing with that nature. On the other hand, MariaDB ColumnStore is a suitable choice for managing big data transactions or large data sets that involves complex joins, aggregation at different levels of dimension hierarchy, project a financial total for a wide range of years, or using equality and range selections. These approaches using ColumnStore do not require you to index these fields, since it can perform sufficiently faster. InnoDB can’t really handle this type of performance, although there’s no stopping you from trying that as is doable with InnoDB, but at a cost. This requires you to add indexes, which adds large amounts of data to your disk storage. This means it can take more time to finish your query, and it might not finish at all if it’s trapped in a time-loop.
MariaDB ColumnStore Architecture
Let’s look at the MariaDB ColumStore architecture below:
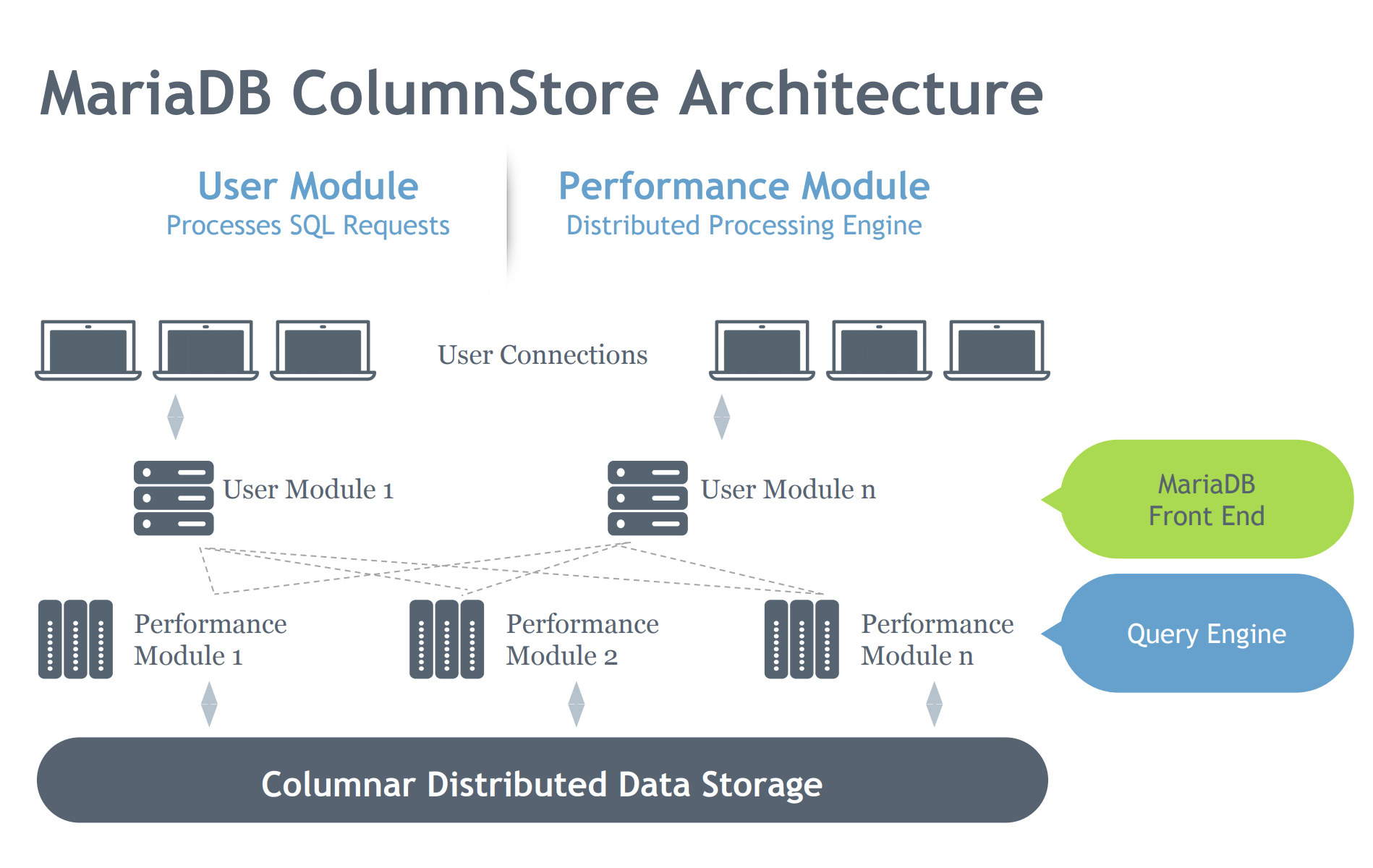
In contrast to the InnoDB architecture, the ColumnStore contains two modules which denotes its intent is to work efficiently on a distributed architectural environment. InnoDB is intended to scale on a server, but spans on a multiple-interconnected nodes depending on a cluster setup. Hence, ColumnStore has multiple level of components which takes care the processes requested to the MariaDB Server. Let’s dig on this components below:
- User Module (UM): The UM is responsible for parsing the SQL requests into an optimized set of primitive job steps executed by one or more PM servers. The UM is thus responsible for query optimization and orchestration of query execution by the PM servers. While multiple UM instances can be deployed in a multi-server deployment, a single UM is responsible for each individual query. A database load balancer, like MariaDB MaxScale, can be deployed to appropriately balance external requests against individual UM servers.
- Performance Module (PM): The PM executes granular job steps received from a UM in a multi-threaded manner. ColumnStore allows distribution of work across many Performance Modules. The UM is composed of the MariaDB mysqld process and ExeMgr process.
- Extent Maps: ColumnStore maintains metadata about each column in a shared distributed object known as the Extent Map The UM server references the Extent Map to help assist in generating the correct primitive job steps. The PM server references the Extent Map to identify the correct disk blocks to read. Each column is made up of one or more files and each file can contain multiple extents. As much as possible the system attempts to allocate contiguous physical storage to improve read performance.
- Storage: ColumnStore can use either local storage or shared storage (e.g. SAN or EBS) to store data. Using shared storage allows for data processing to fail over to another node automatically in case of a PM server failing.
Below is how MariaDB ColumnStore processes the query,
- Clients issue a query to the MariaDB Server running on the User Module. The server performs a table operation for all tables needed to fulfill the request and obtains the initial query execution plan.
- Using the MariaDB storage engine interface, ColumnStore converts the server table object into ColumnStore objects. These objects are then sent to the User Module processes.
- The User Module converts the MariaDB execution plan and optimizes the given objects into a ColumnStore execution plan. It then determines the steps needed to run the query and the order in which they need to be run.
- The User Module then consults the Extent Map to determine which Performance Modules to consult for the data it needs, it then performs Extent Elimination, eliminating any Performance Modules from the list that only contain data outside the range of what the query requires.
- The User Module then sends commands to one or more Performance Modules to perform block I/O operations.
- The Performance Module or Modules carry out predicate filtering, join processing, initial aggregation of data from local or external storage, then send the data back to the User Module.
- The User Module performs the final result-set aggregation and composes the result-set for the query.
- The User Module / ExeMgr implements any window function calculations, as well as any necessary sorting on the result-set. It then returns the result-set to the server.
- The MariaDB Server performs any select list functions, ORDER BY and LIMIT operations on the result-set.
- The MariaDB Server returns the result-set to the client.
Query Execution Paradigms
Let’s dig a bit more how does ColumnStore executes the query and when it impacts.
ColumnStore differs with the standard MySQL/MariaDB storage engines such as InnoDB since ColumnStore gains performance by only scanning necessary columns, utilizing system maintained partitioning, and utilizing multiple threads and servers to scale query response time. Performance is benefited when you only include columns that are necessary for your data retrieval. This means that the greedy asterisk (*) in your select query has significant impact compared to a SELECT
Same as with InnoDB and other storage engines, data type has also significance in performance on what you used. If say you have a column that can only have values 0 through 100 then declare this as a tinyint as this will be represented with 1 byte rather than 4 bytes for int. This will reduce the I/O cost by 4 times. For string types an important threshold is char(9) and varchar(8) or greater. Each column storage file uses a fixed number of bytes per value. This enables fast positional lookup of other columns to form the row. Currently the upper limit for columnar data storage is 8 bytes. So for strings longer than this the system maintains an additional ‘dictionary’ extent where the values are stored. The columnar extent file then stores a pointer into the dictionary. So it is more expensive to read and process a varchar(8) column than a char(8) column for example. So where possible you will get better performance if you can utilize shorter strings especially if you avoid the dictionary lookup. All TEXT/BLOB data types in 1.1 onward utilize a dictionary and do a multiple block 8KB lookup to retrieve that data if required, the longer the data the more blocks are retrieved and the greater a potential performance impact.
In a row based system adding redundant columns adds to the overall query cost but in a columnar system a cost is only occurred if the column is referenced. Therefore additional columns should be created to support different access paths. For instance store a leading portion of a field in one column to allow for faster lookups but additionally store the long form value as another column. Scans on a shorter code or leading portion column will be faster.
Query joins are optimized-ready for large scale joins and avoid the need for indexes and the overhead of nested loop processing. ColumnStore maintains table statistics so as to determine the optimal join order. Similar approaches shares with InnoDB like if the join is too large for the UM memory, it uses disk-based join to make the query completed.
For aggregations, ColumnStore distributes aggregate evaluation as much as possible. This means that it shares across the UM and PM to handle queries especially or very large number of values in the aggregate column(s). Select count(*) is internally optimized to pick the least number of bytes storage in a table. This means that it would pick CHAR(1) column (uses 1 byte) over it INT column which takes 4 bytes. The implementation still honors ANSI semantics in that select count(*) will include nulls in the total count as opposed to an explicit select(COL-N) which excludes nulls in the count.
Order by and limit are currently implemented at the very end by the mariadb server process on the temporary result set table. This has been mentioned in the step #9 on how ColumnStore processes the query. So technically, the results are passed to MariaDB Server for sorting the data.
For complex queries that uses subqueries, it’s basically the same approach where are executed in sequence and is managed by UM, same as with Window functions are handled by UM but it uses a dedicated faster sort process, so it’s basically faster.
Partitioning your data is provided by ColumnStore which it uses Extent Maps which maintains the min/max values of column data and provide a logical range for partitioning and remove the need for indexing. Extent Maps also provides manual table partitioning, materialized views, summary tables and other structures and objects that row-based databases must implement for query performance. There are certain benefits for columned values when they are in order or semi-order as this allows for very effective data partitioning. With min and max values, entire extent maps after the filter and exclusion will be eliminated. See this page in their manual about Extent Elimination. This generally works particularly well for time-series data or similar values that increase over time.
Installing The MariaDB ColumnStore
Installing the MariaDB ColumnStore can be simple and straightforward. MariaDB has a series of notes here which you can refer to. For this blog, our installation target environment is CentOS 7. You can go to this link https://downloads.mariadb.com/ColumnStore/1.2.4/ and check out the packages based on your OS environment. See the detailed steps below to help you speed up:
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpmOnce done, you need to run postConfigure command to finally install and setup your MariaDB ColumnStore. In this sample installation, there are two nodes I have setup running on vagrant machine:
csnode1:192.168.2.10
csnode2:192.168.2.20
Both of these nodes are defined in its respective /etc/hosts and both nodes are targeted are set to have its User and Performance Modules combined in both hosts. The installation is a little bit trivial at first. Hence, we share how you can configure it so you can have a basis. See the details below for the sample installation process:
[root@csnode1 ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[root@csnode1 ~]# . /etc/profile.d/columnstoreAlias.sh
[root@csnode1 ~]#Once installation and setup is done, MariaDB will create a master/slave setup for this so whatever we have loaded from csnode1, it will be replicated to csnode2.
Dumping your Big Data
After your installation, you might have no sample data to try. IMDB has shared a sample data which you can download on their site https://www.imdb.com/interfaces/. For this blog, I created a script which does everything for you. Check it out here https://github.com/paulnamuag/columnstore-imdb-data-load. Just make it executable, then run the script. It will do everything for you by downloading the files, create the schema, then load data to the database. It’s simple as that.
Running Your Sample Queries
Now, let’s try running some sample queries.
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)Basically, it’s faster and quick. There are queries that you cannot processed the same you run with other storage engines, such as InnoDB. For example, I tried to play around and do some foolish queries and see how it reacts and it results to:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.Hence, I found MCOL-1620 and MCOL-131 and it points to setting infinidb_vtable_mode variable. See below:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.But setting infinidb_vtable_mode=0, which means it treats query as generic and highly compatible row-by-row processing mode. Some WHERE clause components can be processed by ColumnStore, but joins are processed entirely by mysqld using a nested-loop join mechanism. See below:
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)It took sometime though as it explains that it processed entirely by mysqld. Still, optimizing and writing good queries still the best approach and not delegate everything to ColumnStore.
Additionally, you have some help to analyze your queries by running commands such as SELECT calSetTrace(1); or SELECT calGetStats();. You can use these set of commands, for example, optimize the low and bad queries or view its query plan. Check it out here for more details on analyzing the queries.
Administering ColumnStore
Once you have fully setup MariaDB ColumnStore, it ships with its tool named mcsadmin for which you can use to do some administrative tasks. You can also use this tool to add another module, assign or move to DBroots from PM to PM, etc. Check out their manual about this tool.
Basically, you can do the following, for example, checking the system information:
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0Conclusion
MariaDB ColumnStore is a very powerful storage engine for your OLAP and big data processing. This is entirely open source which is very advantageous to use than using proprietary and expensive OLAP databases available in the market. Yet, there are other alternatives to try such as ClickHouse, Apache HBase, or Citus Data’s cstore_fdw. However, neither of these are using MySQL/MariaDB so it might not be your viable option if you choose to stick on the MySQL/MariaDB variants.



