blog
An Introduction to Time Series Databases

Long gone are the times where “the” database was single Relational Database Management System installed typically on the most powerful server in the datacenter. Such database served all kinds of requests – OLTP, OLAP, anything business required. Nowadays databases run on commodity hardware, they are also more sophisticated in terms of the high availability and specialized to handle particular type of traffic. Specialization allows them to achieve much better performance – everything is optimized to deal with a particular kind of data: optimizer, storage engine, even language doesn’t have to be SQL, like it used to be in the past. It can be SQL-based with some extensions allowing for more efficient data manipulation, or it can be as well something totally new, created from scratch.
Today we have analytical, columnar databases like ClickHouse or MariaDB AX, we have big data platforms like Hadoop, NoSQL solutions like MongoDB or Cassandra, key-value datastores like Redis. We also have Time-Series databases like Prometheus or TimeScaleDB. This is what we will focus on in this blog post. Time-Series databases – what are they and why you would want to use yet another datastore in your environment.
What Time-Series Databases Are For?
As the name suggests, time-series databases are designed to store data that changes with time. This can be any kind of data which was collected over time. It might be metrics collected from some systems – all trending systems are examples of the time-series data.
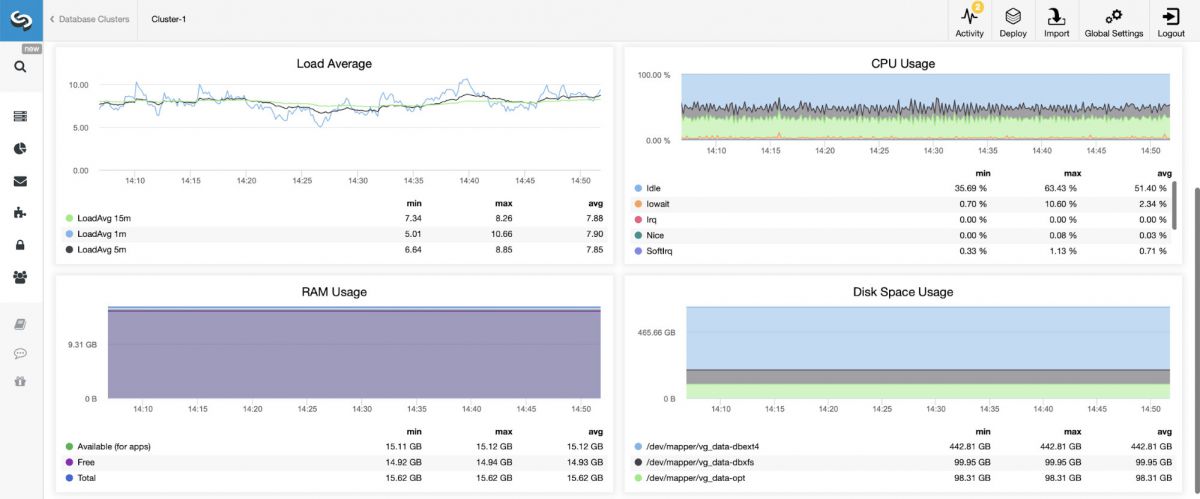
Whenever you look at the dashboards in ClusterControl, you’re actually looking at the visual representation of the time-series data stored in Prometheus, a time-series database.
Time-series data is not limited to database metrics. Everything can be a metric. How the flow of people entering a mall changes over time? How traffic changes in a city? How the usage of the public transport changes during the day? Water flow in a stream or a river. Amount of energy generated by a water plant. All of this and everything else which can be measured in time is an example of the time-series data. Such data you can query, plot, analyze in order to find correlations between different metrics.
How Data is Structured in a Time-Series Database?
As you can imagine, the most important piece of data in the time-series database is time. There are two main ways of storing data. One, something that resembles key-value storage may look like this:
| Timestamp | Metric 1 |
|---|---|
| 2019-03-28 00:00:01 | 2356 |
| 2019-03-28 00:00:02 | 6874 |
| 2019-03-28 00:00:03 | 3245 |
| 2019-03-28 00:00:04 | 2340 |
In short, for every timestamp we has some value for our metric.
Another example will involve more metrics. Instead of storing each metric in a separate table or collection, it is possible to store multiple metrics alongside.
| Timestamp | Metric 1 | Metric 2 | Metric 3 | Metric 4 | Metric 5 |
|---|---|---|---|---|---|
| 2019-03-28 00:00:01 | 765 | 873 | 124 | 98 | 0 |
| 2019-03-28 00:00:02 | 5876 | 765 | 872 | 7864 | 634 |
| 2019-03-28 00:00:03 | 234 | 7679 | 98 | 65 | 34 |
| 2019-03-28 00:00:04 | 345 | 3 | 598 | 0 | 7345 |
This data structure helps to query the data more efficiently when the metrics are related. Instead of reading multiple tables and joining them to get all the metrics together, it is enough to read one single table and all the data is ready to be processed and presented.
You may wonder – what is really new here? How does this differ from a regular table in MySQL or other relational database? Well, the table design is quite similar but there are significant differences in the workload which, when a datastore is designed to exploit them, may significantly improve performance.
Time-series data typically is only appended – it is quite unlikely that you will be updating old data. You typically do not delete particular rows, on the other hand you may want some sort of the aggregation of the data over time. This, when taken into account when designing the database internals, will make a significant difference over “standard” relational (and not relational also) databases intended to serve Online Transaction Processing type of traffic: what is the most important is the ability to consistently store (jngest) large amounts of data that is coming in with time.
It is possible to use an RDBMS to store time-series data, but the RDBMS is not optimized for it. Data and indexes generated on the back of it can get very large, and slow to query. Storage engines used in RDBMS are designed to store a variety of different data types. They are typically optimized for Online Transaction Processing workload which includes frequent data modification and deletion. Relational databases also tend to lack specialized functions and features related to processing time-series data. We mentioned that you probably want to aggregate data that is older than a certain period of time. You may also want to be able to easily run some statistical functions on your time-series data to smooth it up, determine and compare trends, interpolate data and many more. For example, here you can find some of the functions Prometheus makes available to the users.
Examples of Time-series Databases
There are multiple existing time-series databases on the market so it is not possible to cover all of them. We would still like to give some examples of the time-series databases which you may know or maybe even used (knowingly or not).
InfluxDB
InfluxDB has been created by InfluxData. It is an open-source time-series database written in Go. The datastore provides SQL-like language to query the data, which makes it easy for the developers to integrate into their applications. InfluxDB works also as part of a commercial offering, which covers the whole stack designed to provide a full-featured, highly available environment for processing time-series data.
Prometheus
Prometheus is another open source project that is also written in Go. It is commonly used as a backend for different open source tools and projects, for example Percona Monitoring and Management. Prometheus is also been a time-series database of choice for ClusterControl.
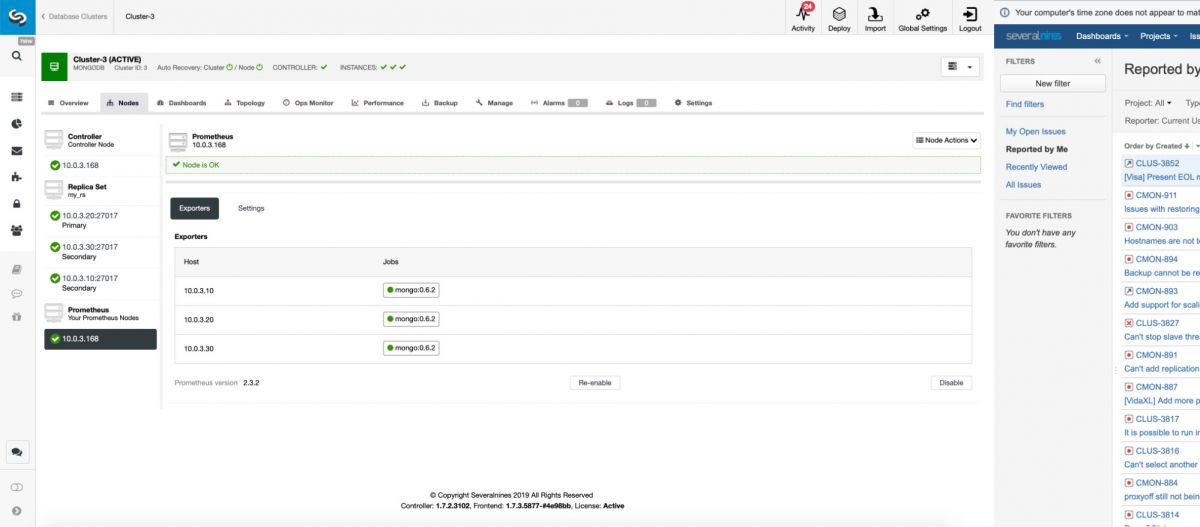
Prometheus can be deployed from ClusterControl to be used to store the time-series data collected on the database servers monitored and managed by ClusterControl:
Being used widely in the open source world, Prometheus is quite easy to integrate into your existing environment using multiple exporters.
RRDtool
This might be an example of time-series database which many people use without knowing they do that. RRDtool is a very popular open source project for storing and visualising time-series data. If you ever used Cacti, it was based on RRDtool. If you designed your own solution, it is quite likely that you also used RRDtool as the backend to store your data. Nowadays it is not as popular as it used to be but back in 2000 – 2010 this was the most common way of storing the time-series data. Fun fact – early versions of ClusterControl made use of it.
TimeScale
TimeScale is a time-series database developed on top of the PostgreSQL. It is an extension on PostgreSQL, which rely on the underlying datastore for providing access to data, which means it accepts all the SQL you may want to use. Being an extension, it utilizes all the other features and extensions of PostgreSQL. You can mix time-series and other type of data, for example to join time-series and metadata, enriching the output. You can also do more advanced filtering utilizing JOINs and non-time-series tables. Leveraging GIS support in PostgreSQL TimeScale can easily used in tracking geographical locations over time. It can also leverage all the scaling possibilities that PostgreSQL offers, including replication.
Timestream
Amazon Web Services also has an offering for time-series databases. Timestream has been announced quite recently, in November, 2018. It adds another datastore to the AWS portfolio, this time helping users to handle time-series data coming from sources like Internet of Things appliances or monitored services. It also can be used to store metrics derived from logs created by multiple services, allowing users to run analytical queries on them, helping to understand patterns and conditions under which services work.
Timestream, as most AWS services, provides an easy way of scaling should the need for storing and analyzing the data grow in time.
As you can see, there are numerous options on the market and this is not surprising. Time-series data analysis is getting more and more traction recently, it becomes more and more critical for business operations. Luckily, given the large number of offerings, both open source and commercial, it is quite likely that you can find a tool which will suit your needs.



