blog
An Expert’s Guide to Slony Replication for PostgreSQL

What is Slony?
Slony-I (referred to as just ‘Slony’ from here on out) is a third-party replication system for PostgreSQL that dates back to before version 8.0, making it one of the older options for replication available. It operates as a trigger-based replication method that is a ‘master to multiple slaves’ solution.
Slony operates by installing triggers on each table to be replicated, on both master and slaves, and every time the table gets an INSERT, UPDATE, or DELETE, it logs which record gets changed, and what the change is. Outside processes, called the ‘slon daemons’, connect to the databases as any other client and fetch the changes from the master, then replay them on all slave nodes subscribed to the master. In a well performing replication setup, this asynchronous replication can be expected to be anywhere 1 to 20 seconds lagged behind the master.
As of this writing, the latest version of Slony is at version 2.2.6, and supports PostgreSQL 8.3 and above. Support continues to this day with minor updates, however if a future version of PostgreSQL changes fundamental functionality of transactions, functions, triggers, or other core features, the Slony project may decide to discontinue large updates to support such drastic new approaches.
PostgreSQL’s mascot is an elephant known as ‘Slonik’, which is Russian for ‘little elephant’. Since this replication project is about many PostgreSQL databases replicating with each other, the Russian word for elephants (plural) is used: Slony.
Concepts
- Cluster: An instance of Slony replication.
- Node: A specific PostgreSQL database as Slony replication node, which operates as either a master or slave for a replication set.
- Replication Set: A group of tables and / or sequences to be replicated.
- Subscribers: A subscriber is a node that is subscribed to a replication set, and receives replication events for all tables and sequences within that set from the master node.
- Slony Daemons: The main workers that execute replication, a Slony daemon is kicked off for every node in the replication set and establishes various connections to the node it manages, as well as the master node.
How it is Used
Slony is installed either by source or through the PGDG (PostgreSQL Global Development Group) repositories which are available for Red Hat and Debian based linux distributions. These binaries should be installed on all hosts that will contain either a master or slave node in the replication system.
After installation, a Slony replication cluster is set up by issuing a few commands using the ‘slonik’ binary. ‘slonik’ is a command with a simple, yet unique syntax of its own to initialize and maintain a slony cluster. It is the main interface for issuing commands to the running Slony cluster that is in charge of replication.
Interfacing with Slony can be done by either writing custom slonik commands, or compiling slony with the –with-perltools flag, which provides the ‘altperl’ scripts that help generate these slonik scripts needed.
Creating a Slony Replication Cluster
A ‘Replication Cluster’ is a collection of databases that are part of replication. When creating a replication cluster, an init script needs to be written that defines the following:
- The name of the Slony cluster desired
- The connection information for each node part of replication, each with an immutable node number.
- Listing all tables and sequences to be replicated as part of a ‘replication set’.
An example script can be found in Slony’s official documentation.
When executed, slonik will connect to all nodes defined and create the Slony schema on each. When the Slony daemons are kicked off, they will then clear out all data in the replicated tables on the slave (if there is any), and copy over all data from the master to the slave(s). From that point on, the daemons will continually replicate changes recorded on the master to all subscribed slaves.
Clever Configurations
While Slony is initially a Master-to-Multiple-Slave replication system, and has mainly been used in that way, there are several other features and clever usages that make Slony more useful than a simple replication solution. The highly customizable nature of Slony keeps it relevant for a variety of situations for administrators that can think outside of the box.
Cascading Replication
Slony nodes can be set up to cascade replication down a chain of different nodes. If the master node is known to take an extremely heavy load, each additional slave will increase that load slightly. With cascading replication, a single slave node connected to the master can be configured as a ‘forwarding node’, which will then be responsible to sending replication events to more slaves, keeping the load on the master node to a minimum.
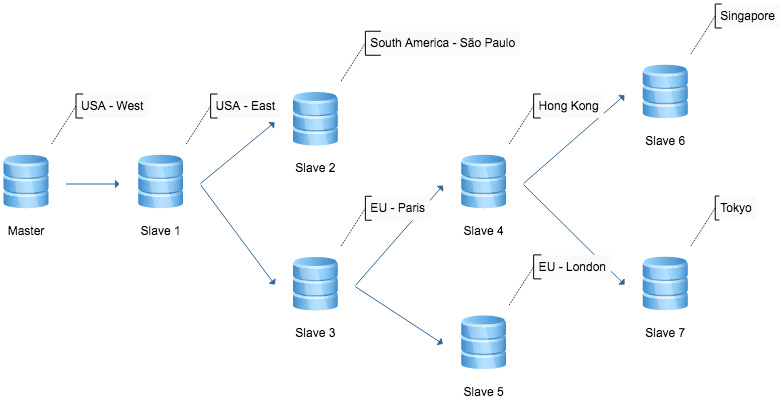
Data Processing on a Slave Node
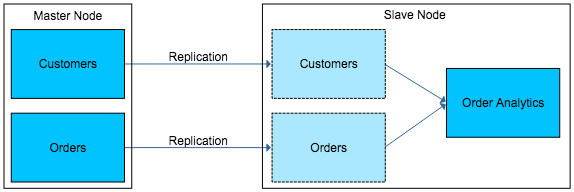
Unlike PostgreSQL’s built in replication, the slave nodes are not actually ‘read only’, only the tables that are being replicated are locked down as ‘read only’. This means on a slave node, data processing can take place by creating new tables not part of replication to house processed data. Tables part of replication can also have custom indexes created depending on the access patterns that may differ from the slave and the master.
Read only tables on the slaves can still have custom trigger based functions executed on data changes, allowing more customization with the data.
Minimal Downtime Upgrades
Upgrading major versions of PostgreSQL can be extremely time consuming. Depending on data size and table count, an upgrade including the ‘analyze’ process post-upgrade could take several days even. Since Slony can replicate data between PostgreSQL clusters of different versions, it can be used to set up replication between an older version as the master and a newer version as the slave. When the upgrade is to happen, simply perform a ‘switchover’, making the slave the new master, and the old master becomes the slave. When the upgrade is marked a success, decommission the Slony replication cluster and shut down the old database.
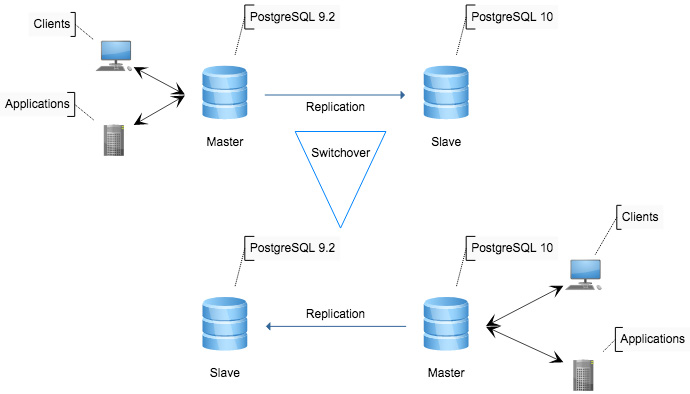
High Availability With Frequent Server Maintenance
Like the minimal downtime for upgrades, server maintenance can be done easily with no downtime by performing a ‘switchover’ between two or more nodes, allowing a slave to be rebooted with updates / other maintenance. When the slave comes back online, it will re-connect to the replication cluster and catch up on all the replicated data. End users connecting to the database may have long transactions disrupted, but downtime itself would be seconds as the switchover happens, rather than however long it takes to reboot / update the host.
Log Shipping
Though not likely to be popular solution, a Slony slave can be set up as a ‘log shipping’ node, where all data it receives through replication can be written to SQL files, and shipped. This can be used for a variety of reasons, such as writing to an external drive and transporting to a slave database manually, and not over a network, compressed and kept archived for future backups, or even have an external program parse the SQL files and modify the contents.
Multiple database data sharing
Since any number of tables can be replicated at will, Slony replication sets can be set up to share specific tables between databases. While similar access can be achieved through Foreign Data Wrappers (which have improved in recent PostgreSQL releases), it may be a better solution to use Slony depending on the usage. If a large amount of data is needed to be fetched from one host to another, having Slony replicate that data means the needed data will already exist on the requesting node, eliminating long transfer time.
Delayed Replication
Usually replication is desired to be as quick as possible, but there can be some scenarios where a delay is desired. The slon daemon for a slave node can be configured with a lag_interval, meaning it won’t receive any replication data until the data is old as specified. This can be useful for quick access to lost data if something goes wrong, for example if a row is deleted, it will exist on the slave for 1 hour for quick retrieval.
Things to Know:
- Any DDL changes to tables that are part of replication must be executed using the slonik execute command.
- Any table to be replicated must have either a primary key, or a UNIQUE index without nullable columns.
- Data that is replicated from the master node is replicated after any data may have been functionally generated. Meaning if data was generated using something like ‘random()’, the resulting number is stored and replicated on the slaves, rather than ‘random()’ being run again on the slave returning a different result.
- Adding Slony replication will increase server load slightly. While efficiently written, each table will have a trigger that logs each INSERT, UPDATE, and DELETE to a Slony table, expect about 2-10% server load increase, depending on database size and workload.
Tips and Tricks:
- Slony daemons can run on any host that has access to all other hosts, however the highest performing configuration is to have the daemons run on the nodes they are managing. For example, the master daemon running on the master node, the slave daemon running on the slave node.
- If setting up a replication cluster with a very large amount of data, the initial copy can take quite a long time, meaning all changes that happen from kickoff till the copy is done could mean even longer to catch up and be in sync. This can be solved by either adding a few tables at a time to replication (very time consuming), or by creating a data directory copy of the master database to the slave, then doing a ‘subscribe set’ with the OMIT COPY option set to true. With this option, Slony will assume that the slave table is 100% identical to the master, and not clear it out and copy data over.
- The best scenario for this is to create a Hot Standby using the built in tools for PostgreSQL , and during a maintenance window with zero connections modifying data, bring the standby online as a master, validate data matches between the two, initiate the slony replication cluster with OMIT COPY = true, and finally re-enable client connections. This may take time to do the setup for the Hot Standby, but the process won’t cause huge negative impact to clients.
Community and Documentation
The community for Slony can found in the mailing lists, located at http://lists.slony.info/mailman/listinfo/slony1-general, which also includes archives.
Documentation is available on the official website, http://slony.info/documentation/, and provides help with log analysis, and syntax specification for interfacing with slony.



