blog
Disaster Recovery for Galera Cluster Deployed to a Hybrid Cloud

Running a Galera Cluster in a hybrid cloud should consist of at least two different geographical sites, connecting hosts in the on-premises or private cloud with the ones in the public cloud. Whether you use unbreakable private cloud or public cloud platforms, Disaster Recovery (DR) is indeed a key issue. This is not about copying your data to a backup site and being able to restore it, this is about business continuity and how fast you can recover services when disaster strikes.
In this blog post, we will look into different ways of designing your Galera Clusters for fault tolerance in a hybrid cloud environment.
Active-Active Setup
Galera Cluster should be running with an odd number total of nodes in a cluster, and commonly starts with 3 nodes. This is because Galera Cluster uses quorum to automatically determine the primary component, where a majority of connected nodes should be able to serve the cluster at a time, in case of cluster partitioning happened.
For an active-active setup hybrid cloud setup, Galera requires at least 3 different sites, forming a Galera Cluster across WAN. Generally, you would need a third site to act as an arbitrator, voting for quorum and preserving the “primary component” if any of the sites are unreachable. This can be set up as a minimum of a 3-node cluster on 3 different sites (1 node per site), similar to the following diagram:
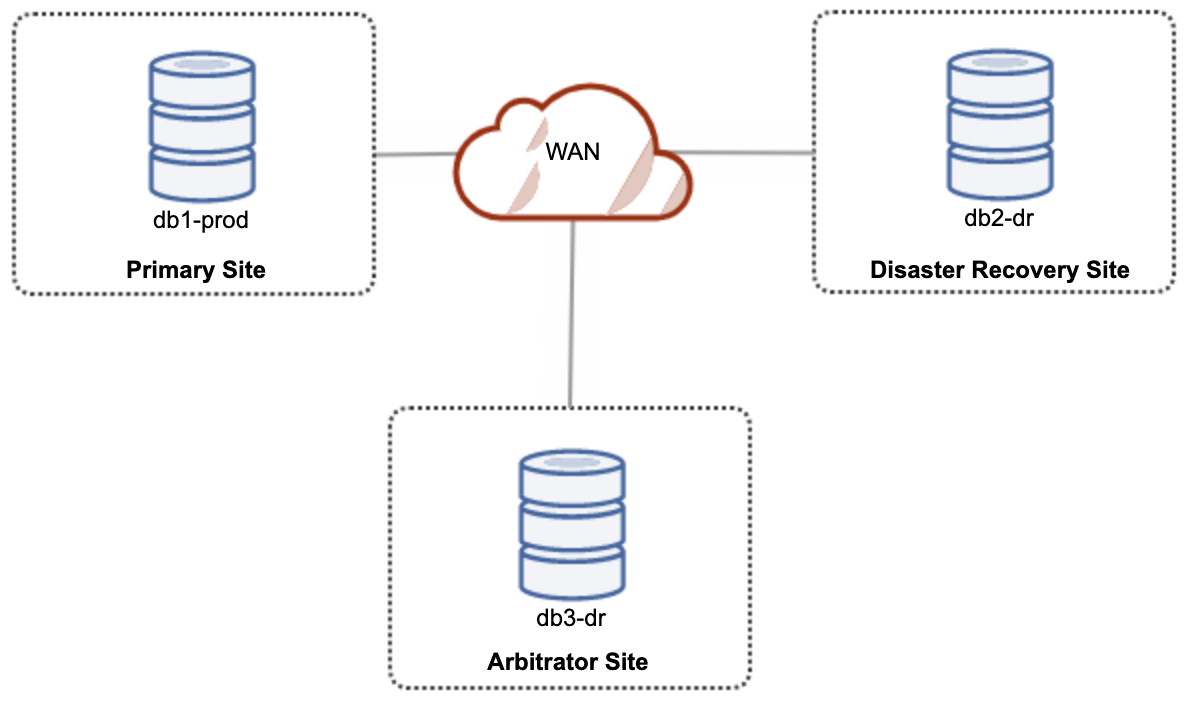
However, for performance and reliability purposes, it is recommended to have a 7-node cluster, as shown in the following diagram:
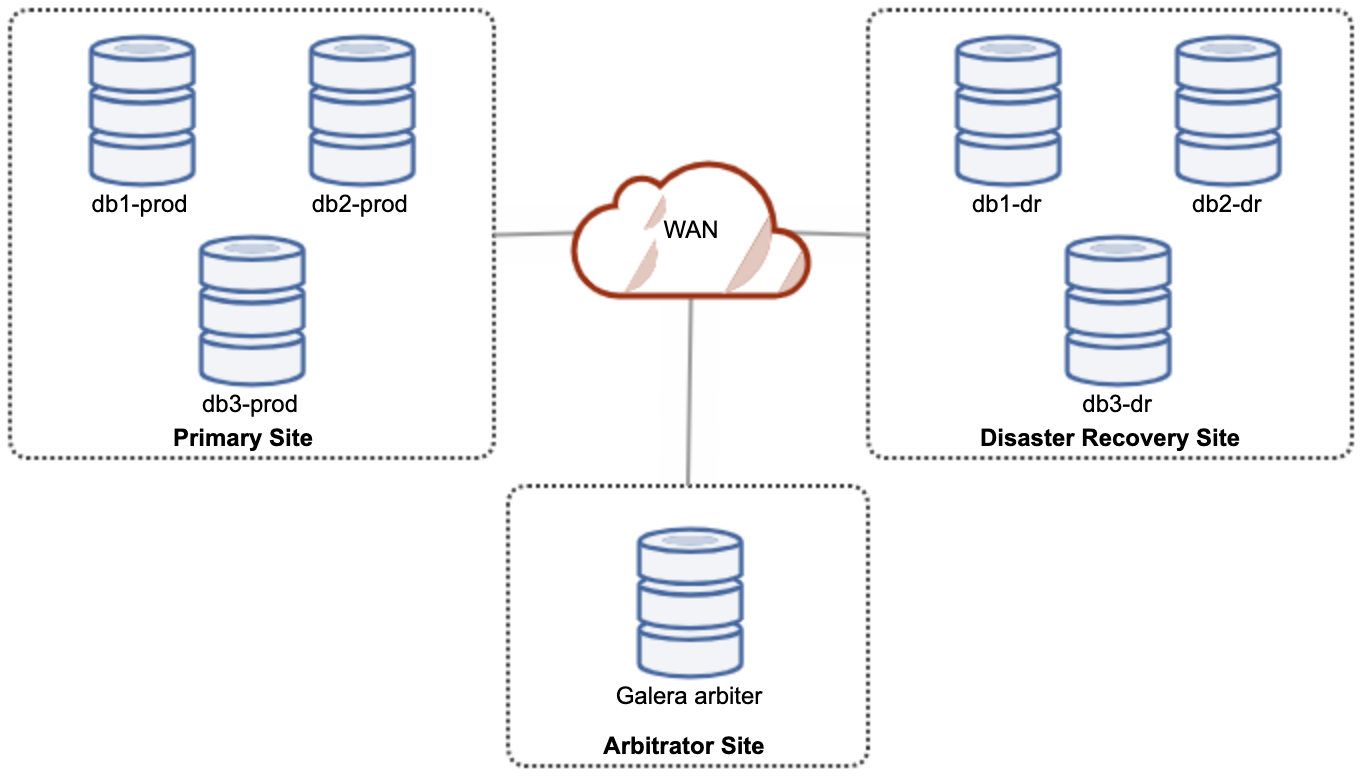
This is considered the best topology to support an active-active setup, where the DR site should be available almost immediately, without any intervention. Both sites can receive reads/writes at any moment provided the cluster is in the quorum.
However, it is very costly to have 3 sites, and 7 database nodes (the 7th node can be replaced with a garbd since it’s very unlikely to be used to serve data to the clients/applications). This commonly not a popular deployment at the beginning of the project due to the huge upfront cost and how sensitive the Galera group communication and replication to network latency.
Active-Passive Setup
In an active-passive configuration, at least 2 sites are required and only one site is active at a time, known as the primary site and the nodes on the secondary site only replicate data coming from the primary server/cluster. For Galera Cluster, we can use either MySQL asynchronous replication (master-slave replication) or we can also use Galera’s virtually-synchronous replication with some tuning to tone down its writeset replication to act as asynchronous replication.
The secondary site must be protected against accidental writes, by using the read-only flag, application firewall, reverse proxy or any other means since the data flow is always coming from the primary to the secondary site unless a failover has initiated and promoted the secondary site as the primary.
Using asynchronous replication
A good thing about asynchronous replication is that the replication does not impact the source server/cluster, but it is allowed to be lagging behind the master. This setup will make the primary and DR site independent of each other, loosely connected with asynchronous replication. This can be set up as a minimum of a 4-node cluster on 2 different sites, similar to the following diagram:
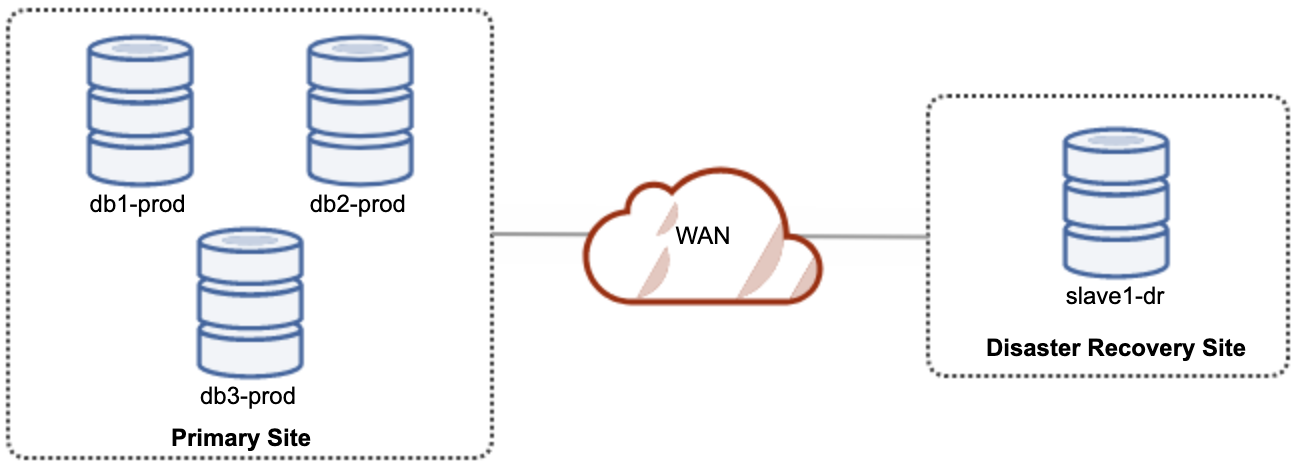
One of the Galera nodes in the DR site will be a slave, that replicates from one of the Galera nodes (master) in the primary site. Both sites have to produce binary logs with GTID and log_slave_updates are enabled – the updates that come from the asynchronous replication stream will be applied to the other nodes in the cluster. However, for production usage, we recommend having two sets of clusters on both site, as shown in the following diagram:
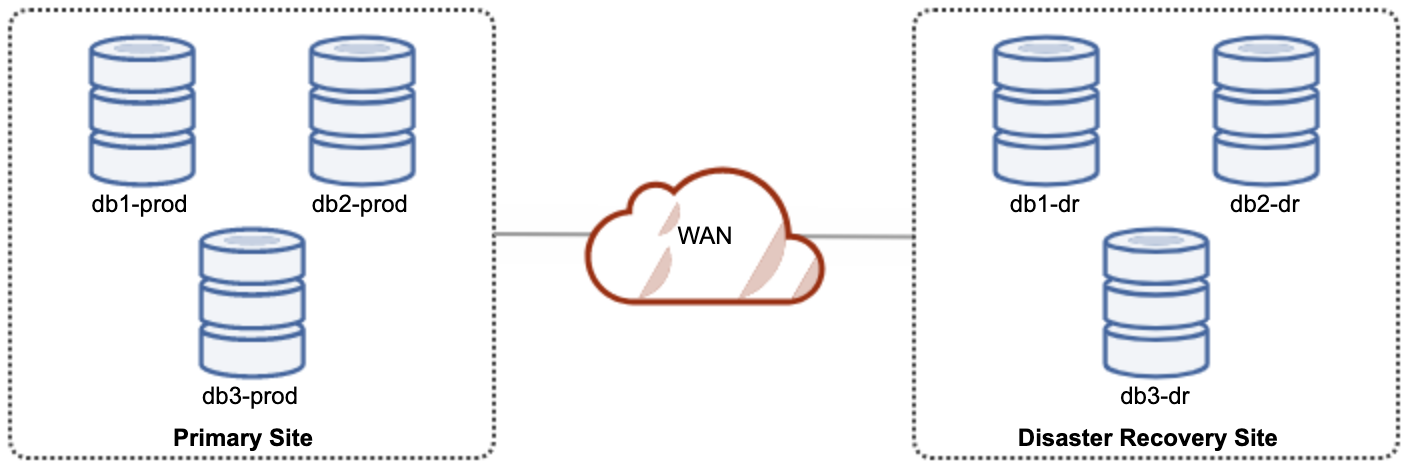
By having two separate clusters, they will be loosely coupled and not impacting each other, e.g. a cluster failure on the primary site will not affect the DR site. Performance-wise, WAN latency will not impact updates on the active cluster. These are shipped asynchronously to the backup site. The DR cluster could potentially run on smaller instances in a public cloud environment, as long as they can keep up with the primary cluster. The instances can be upgraded if needed. Applications should send writes to the primary site, and the secondary site must be set to run in read-only mode. The disaster recovery site can be used for other purposes like database backup, binary logs backup and reporting or processing analytical queries (OLAP).
On the downside, there is a chance of data loss during failover/fallback if the slave was lagging. Therefore, it’s recommended to enable semi-synchronous replication to lower the risk of data loss. Note that using semi-synchronous replication still does not provide strong guarantees against data loss, if compared to Galera’s virtually-synchronous replication. Read this MySQL manual carefully, for example, these sentences:
“With semisynchronous replication, if the source crashes and a failover to a replica is carried out, the failed source should not be reused as the replication source, and should be discarded. It could have transactions that were not acknowledged by any replica, which were therefore not committed before the failover.”
The failover process is pretty straightforward. To promote the disaster recovery site, simply turn off the read-only flag and start directing the application to the database nodes in the DR site. The fallback strategy is a bit tricky though, and it requires some expertise in staging the data on both sites, switching the master/slave role of a cluster and redirecting the slave replication flow to the opposite way.
Using Galera Replication
For active-passive setup, we can place the majority of the nodes located in the primary site while the minority of the nodes located in the disaster recovery site, as shown in the following screenshot for a 3-node Galera Cluster:
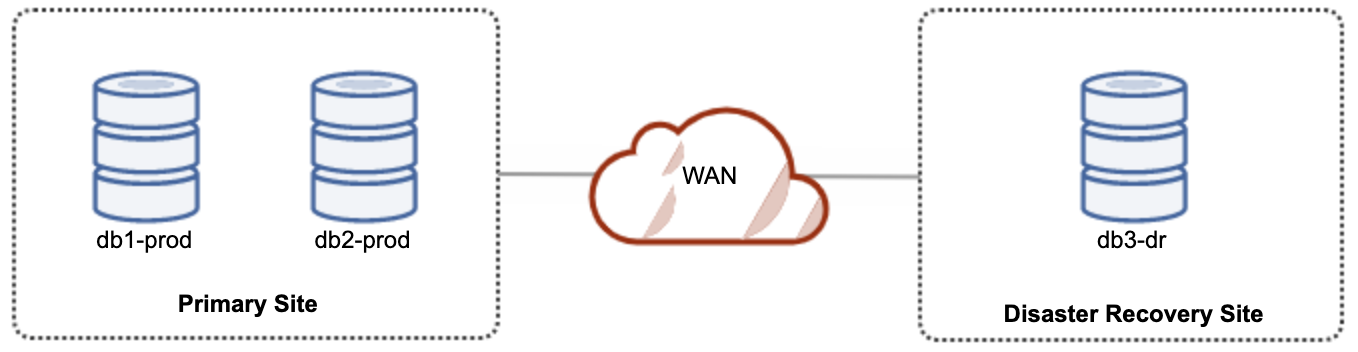
If the primary site is down, the cluster will fail as it is out of quorum. The Galera node on the disaster recovery site (db3-dr) will need to be bootstrapped manually as a single node primary component. Once the primary site comes back up, both nodes on the primary site (db1-prod and db2-prod) need to rejoin galera3 to get synced. Having a pretty large gcache should help to reduce the risk of SST over WAN. This architecture is easy to set up and administer and very cost-effective.
Failover is manual, as the administrator needs to promote the single node as the primary component (bootstrap db3-dr or use set pc.bootstrap=1 in the wsrep_provider_options parameter. There would be downtime in the meantime. Performance might be an issue, as the DR site will be running with a smaller number of nodes (since the DR site is always the minority) to run all the load. It may be possible to scale out with more nodes after switching to the DR site but beware of the additional load.
Note that Galera Cluster is sensitive to the network due to its virtually synchronous nature. The farther the Galera nodes are in a given cluster, the higher latency and its write capability to distribute and certify the writesets. Also, if the connectivity is not stable, cluster partitioning can easily happen, which could trigger cluster synchronization on the joiner nodes. In some cases, this can introduce instability to the cluster. This requires a bit of tuning on Galera parameters, as shown in this blog post, Deploying a Hybrid Infrastructure Environment for Percona XtraDB Cluster.
Final Thoughts
Galera Cluster is a great technology that can be deployed in different ways – one cluster stretched across multiple sites, multiple clusters kept in sync via asynchronous replication, a mixture of synchronous and asynchronous replication, and so on. The actual solution will be dictated by factors like WAN latency, eventual versus strong data consistency and budget.



