blog
A Developer’s Guide to MongoDB Replica Sets

MongoDB often involves working with a large set of data including embedded arrays and array objects. Therefore, it is always important to ensure your database processing rate is as fast as possible to enhance read and write operations. Besides, to avoid data anomalies that may arise due to data inconsistency, you need to ensure your data is in increased availability just in case you would like to have a recovery from an event of hardware failure or some service interruptions. MongoDB provides some 2 concepts for that purpose – ReplicaSets and Sharding.
Replication in MongoDB
Master-Slave Replication
This is one of the oldest techniques used to ensure data is always available to users even when one system failed. However, Master-Slave replication is deprecated in the latest versions of MongoDB as from 3.2 and was thus replaced with Replica sets.
To make this configuration, one starts 2 mongod instances while considering one is in master mode and the other is slave mode.
To start an instance in master mode, run:
mongod --master --port portNumberThe –master options instructs mongod to create a local.oplog.$main collection with which a list of operations are queued for the slaves to apply in replicating the data.
To start a mongod instance in slave mode, just run:
mongod --slave --source <:> Here you need to specify the hostname and the port of the master instance to the –source argument. This is a summarized overview of using the Master slave replication and since it is deprecated, our interest will be on the Replica sets.
Replica Sets
This is a group of MongoDB processes known as mongod instances that basically host the same data set. It is featured by one primary node and several secondary nodes for bearing data. The primary node receives all the write operations and records all other changes to its data set in its operation log. The secondary nodes, in the other end, replicate the primary’s operation log and apply the operations to their data set such that their data sets reflect the primary’s data set. In simple words, we can say we have machine A as the primary node and machine B and C as the secondary nodes. Machine A receives a write operation and makes changes to its data and then makes a list of the changes that have been made. Machines B and C will then copy operations from the list provided, in this case the oplog, and execute them so that the resulting data is same as in Machine A.
As mentioned before, it is always important to ensure high availability of data, especially in the production setting. Replication comes in to help by providing data redundancy in different Mongod instances. In case of data loss, since copies of same data are stored across different databases in multiple locations, it is easy to recover it in the existing one.
With many running instances, read and write operations from clients are sent to different servers and therefore the processing rate increases. The basic structure of the replication process is shown below.
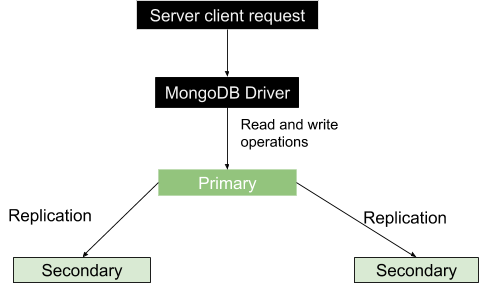
Sometimes the primary may not be available for example due to internet disconnection or service interruption. In this case, the replica set will nominate a secondary to be the primary node. As much as the read requests are basically made to the primary, some occasions the read requests can be sent to the secondaries but be careful since the returned data may not reflect what is in the primary or rather the data may not be up to date.
Arbiters
In the case of election of a primary, you will need an extra mongod instance to the replica set to add a vote in the election process. This instance is referred to as an arbiter and its salient features are:
- It does not have a copy of the dataset, hence does not require as powerful hardware as the data bearing nodes..
- Cannot be promoted to become the primary.
- They always have 1 electoral vote so as to allow replica set to have an uneven number of voting members without the overhead of an additional member that replicates data. Its crucial role is, therefore, to select a primary node when it is not available.
- It remains unchanged.
Contrary to the arbiter, other replica sets can be converted into primary from secondary and vise-versa.
Asynchronous Replication
The process of replication takes place in two forms of data synchronization. First, the members in the set are populated with full data in the initial sync. The subsequent replication takes place to apply advancing changes to the entire data set.
In the initial sync, data is copied from one member of the replica set into another. When the process is completed, the member transitions into the secondary node.
MongoDB Automatic Failover
There can be a service interruption like network disconnection which comes with a consequence of terminating the communication between the primary and the secondaries. If the disconnection is more than 10 seconds or fails completely, the remaining replica set will vote for a member to become the new primary. The secondary node that gets the majority of the votes becomes the new primary.
In version 3.0 of MongoDB, a replica set can have up to 50 members with 7 voting members.
Priority Zero Replica Set Members
These are secondary members that can neither transit to be primary nodes nor can they trigger an election. There crucial roles in the data set are to: maintain data set copies, elect a primary node and perform read operations. They act like a backup where a new member may fail to add immediately. It will thus store the updated data and can immediately replace an unavailable member.
MongoDB Hidden Replica Set Members
These are members with no connection to the client applications. They are used for workloads with different usage requirements from other secondary members. They only receive the basic replication traffic that is during the initial sync.
MongoDB Delayed Replica Set Members
These copy data from the primary node’s oplog file within some specified duration. They always reflect the delayed state or a previous form of the set. They are therefore important in detecting errors and give a hint on how one can recover from those errors, for example if there is a database that has been dropped. When choosing the amount of delay, this should be in consideration:
- The duration should be less than the capacity of the operation log, which for the WiredTiger, MMAPv1 and In-Memory storage engines is 50GB. Otherwise, the delayed member cannot successfully replicate operations.
- The delay duration should be equal or slightly greater than your expected maintenance window durations.
Configuration
This is a priority zero member, it is hidden hence not visible to applications and lastly can participate in the election process. Therefore to configure a priority, let’s say you have 10 members in your replica set, you can select a member at position n as member[n] and set its properties as:
{
“_id”: ,
“Host”: ,
“Priority”: 0,
“slaveDelay”: ,
“Hidden”: true
} Or using the mongo shell connected to the primary you can run this commands to set the first member of the replica set as a delayed:
cfg = rs.conf()
cfg.members[0].priority = 0
cfg.members[0].hidden = true
cfg.members[0].slaveDelay = 3600
rs.reconfig(cfg)After setting this configurations, the delayed secondary cannot become a primary and therefore hidden from applications. The Member will be delayed by 1 hour (3600 seconds) from the oplog operations.
How Start a Replica Set
In this guide, we shall see step by step how we can configure a replica set in MongoDB.
- Let’s say you have 3 mongodb you want to replicate and they are configured as follows:
- Mongod1.conf running at port 27017
- Mongod2.conf running at port 27018
- Mongod3.conf running at port 27019
Ensure to add the replica set name which will not change in each file. You can do so by adding or changing the option replSet value to a name of your choice.
-
We can start the first instance by running
sudo mongod --config /etc/mongo/mongod1.confThis is if, you have no mongod running instance. Then do the same for the other instances. To check for running instances in your machine run
ps -ax | grep mongoYou will get some list like this:
4328 ttys000 0:06.15 mongod 4950 ttys001 0:00.00 grep mongoThis means that the first instance in MongoDB by default runs at port 27017 hence we have it as the first one in the list. If you started the others, they will also be outlined in the list with their corresponding path urls. To connect to an instance in the mongo shell, run this command:
mongo --port port_number i.e mongo --port 27017.However in our case we need to connect with a replica set name so we have to add ithe name to the command:
mongod --replSet replicaSetName --dbpath /usr/local/var/mongo/mongod --port 27017In this case our replicaSetName = “testrep”
-
Let’s check if there is any replica set enabled by running rs.status()
If you get a result like:
{ "ok" : 0, "errmsg" : "not running with --replSet", "code" : 76, "codeName" : "NoReplicationEnabled" }Then it means there is no replica set enabled. Else if you get the result as
{ "operationTime" : Timestamp(0, 0), "ok" : 0, "errmsg" : "no replset config has been received", "code" : 94, "codeName" : "NotYetInitialized", "$clusterTime" : { "clusterTime" : Timestamp(0, 0), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } } }then it mean the replica is not yet initiated.
-
The rs.initiate()method will help us start a new replica set and the instance within which it is initiated becomes our primary node. So we can initiate one in our instance by running the initiate method. rs.initiate().
-
Check the replica set status again by running rs.status().members. You should now see something like
"members" : [ { "_id" : 0, "name" : "localhost:27018", "health" : 1, "state" : 1, "stateStr" : "PRIMARY", "uptime" : 577, "optime" : { "ts" : Timestamp(1535301271, 1), "t" : NumberLong(1) }, "optimeDate" : ISODate("2018-08-26T16:34:31Z"), "syncingTo" : "", "syncSourceHost" : "", "syncSourceId" : -1, "infoMessage" : "could not find member to sync from", "electionTime" : Timestamp(1535301265, 1), "electionDate" : ISODate("2018-08-26T16:34:25Z"), "configVersion" : 1, "self" : true, "lastHeartbeatMessage" : "" } ]Well, good to go. Our interest will be the members option, as we can see it is n array with 1 member in it. Checking the first member’s stateStr option in this case it is set to Primary which means that this will act as our primary node.
-
Add a new member to the replica set using its hostname. To check for the hostname of the connected instance you want to add run
db.serverStatus().hostYou will get something like
ervername.local:27019So from the PRIMARY yo can add another member by running this command in the mongo shell:
rs.add("servername.local:27019"); -
Run the status command
rs.status().membersTo check whether the changes have been made.
You should now have something looking like this:
[ { "_id" : 0, "name" : "localhost:27018", "health" : 1, "state" : 1, "stateStr" : "PRIMARY", "uptime" : 11479, "optime" : { "ts" : Timestamp(1535312183, 1), "t" : NumberLong(1) }, "optimeDate" : ISODate("2018-08-26T19:36:23Z"), "syncingTo" : "", "syncSourceHost" : "", "syncSourceId" : -1, "infoMessage" : "", "electionTime" : Timestamp(1535301265, 1), "electionDate" : ISODate("2018-08-26T16:34:25Z"), "configVersion" : 2, "self" : true, "lastHeartbeatMessage" : "" }, { "_id" : 1, "name" : "127.0.0.1:27019", "health" : 1, "state" : 2, "stateStr" : "SECONDARY", "uptime" : 15, "optime" : { "ts" : Timestamp(1535312183, 1), "t" : NumberLong(1) }, "optimeDurable" : { "ts" : Timestamp(1535312183, 1), "t" : NumberLong(1) }, "optimeDate" : ISODate("2018-08-26T19:36:23Z"), "optimeDurableDate" : ISODate("2018-08-26T19:36:23Z"), "lastHeartbeat" : ISODate("2018-08-26T19:36:26.302Z"), "lastHeartbeatRecv" : ISODate("2018-08-26T19:36:27.936Z"), "pingMs" : NumberLong(0), "lastHeartbeatMessage" : "", "syncingTo" : "localhost:27018", "syncSourceHost" : "localhost:27018", "syncSourceId" : 0, "infoMessage" : "", "configVersion" : 2 } ]We now have 2 members, one is a PRIMARY node and the other is a SECONDARY node. You can add more members but not exceeding 50. Now let us make a database in the instance at port 27018 as the primary.
If we disconnect the primary, a failover will happen and since we have only 1 primary it will automatically be transitioned into a secondary. Now if we connect to the one on port 27019 you should get the same databases and collections with their documents.

Now if the disconnected primary node is reconnected, it will be added as a secondary as it copies operations from the oplog of the existing primary.
MongoDB Replica Set Write Concern
If MongoDB returns a successful journaled write concern, the data will be stored to the disk hence becoming available after mongod restarts. However, for the write operations, the data is durable only after it gets replicated and committed to the journal in favour from the majority of the voting member of the replica set.
Some data may be too large to update or insert, hence may take longer than expected for the data to be replicated in other members. For this reason it is advisable to edit the writeConcern configurations to cater for the duration within which an operation is to be executed. The default writeConcern configurations dictate that the replica set require acknowledgement only from the primary member. A default write concern confirms write operations for the primary only but can be overridden to check write operations on some replica set members by specifying the write concern for a specific write operation. For example:
db.books.insert({name: “James”,place: “Beijing”},{writeConcern: {w: 3, wtimeout: 3600}})The write option in this case dictates that the operation should return a response only after the it has been spread to the primary and at least 2 secondaries or if it times out after 3.6 seconds.
Configuring the Write Concern for MongoDB
The MongoDB getLastErrorDefaults option gives us the parameters for altering the write concern default settings in the replica set configuration. This implies that the operation has to be complete in most of the voting members before returning the result.
cfg = rs.conf()
cfg.settings = {},
cfg.settings.getLastErrorDefaults = {w: “majority”, wtimeout: 3600}
rs.reconfig(cfg)The timeout value will prevent blocking write operations that is to say, if there are supposed to be 5 members to acknowledge the write concern but unfortunately there are 4 or less members in the replica set, the operation will block until all the members are available. By adding the timeout threshold, the operation blocking will be discarded after this duration.
Replication Blocking
Blocking an operation especially when all the members have been replicated ensures no more time will be wasted waiting for another replica set member to be available in order to return a response. MongoDB getLastError command option dictates how the replication update is done using the optional “w” attribute.
For example, this query
db.runCommand({getLastError: 1, w: N, “wtimeout”: 5000});requires that the blocking will occur until N number of members have replicated the last write operation. If N is available or is less than 2, the query will be returned. Else if the value for N is equal to 2, the master equivalent to the primary, will respond only after 1 of its slaves has been replicated to the last operation.
The wtimeout parameter is basically to set the time in milliseconds after which getLastError command will timeout and return an error before the last option has been replicated.
As much as blocking is somehow advantageous, sometimes it has a limitation. It significantly slows down the read operations especially if you set the “w” value to be too large. I would recommend you set the “w” value to either 2 or 3 for improved safety and efficiency.
Read Preference in MongoDB
This is basically the adjacent route with which the client read operations are made to the replica set. The default MongoDB setup configures the read operations to the primary because it is the one with the latest version of the document you are fetching. As mentioned before, the supreme advantage for exploiting the replica set is to improve performance of our database system. Thus, it is advisable to distribute the read operations to many secondary members to reduce latency for applications which do not necessarily require up to date data. However, there are more crucial reasons why you should also use the primary as you basic preference:
- Maintaining data availability during the failover.
- For geographically distributed applications, the primary will provide local reads for clients in the same datacenter.
- Not to affect the front-end applications, especially those running system operations.
Mongo.setReadPref() Method
This method is basically to define how the client will route all queries to members of the replica set. It takes 2 arguments, mode and tagSet.
The mode argument specifies the read preference which can either be primary, primaryPreferred, secondary, secondaryPreferred or nearest.
The tagSet mode specifies the custom read preference.You can also specify them as an array of objects. An example of the setup will be:
db.getMongo().setReadPref('primaryPreferred',
[ { "dc": "east", "use": "production" },
{ "dc": "east", "use": "reporting" },
{ "dc": "east" },
{}
] )What happens here is that, if the client tries to access the first tag and the request does not go through, they will be opted to the second read preference.
Read Preference Modes
- Primary: this defines that all read operations read from a given replica set are primary and is the default preference read mode.
- PrimaryPreferred: If only the primary is not available, then the read operations can be made from the secondaries.
- Secondary: all read operations are made from the secondary members of the replica set.
- SecondaryPreferred: if only there is no secondary available, the read operations can be made from the primary.
- Nearest: member with least network latency is selected for the read operation irrespective of its type.
Tag Sets and their Configuration
These are options that enable you to model the way you want your write concern and read preference to look like. They are stored within the replica set configuration object. If you run rs.conf().members, you will get this object returned:
[
{
"_id" : 0,
"host" : "localhost:27018",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 1,
"host" : "127.0.0.1:27019",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
}
]As you can see, each member has tags attribute.
The main difference between Read Preferences and Write Concern is that, the former considers the value of a tag when selecting a member to read from while the latter does not.
Let’s say a tag set for a read operation is set to:
{ "disk": "ssd", "use": "reporting" }A member in the replica set has to fulfill these tags for the read operation to go through. Therefore to say, a configuration like this
{ "disk": "ssd", "use": "reporting", "rack": "a" }will satisfy the query whereas this one
{ "disk": "ssd", "use": "production", "rack": "k" }will not satisfy the query.
Adding Tags to a Set Replica
For your selected member in a replica set, you can addtag sets using the rs.conf() method in MongoDB.
Let’s say you have selected a member in position 1 of your replica set array, you can add tag sets as follows.
conf = rs.conf()
conf.members[0].tags = { "dc": "NYK", "use": "production" }
conf.members[1].tags = { "dc": "LON", "use": "reporting" }
conf.members[2].tags = { "use": "production" }
rs.reconfig(conf)Deployment Patterns for MongoDB Replica Set
- Geographically distributed replica set – Enhances redundancy of data besides protecting data against faults such as power loss. The running instances are located in multiple locations.
- Three member Replica Set – the basic standard architecture for a replica set.
- Four or more member Replica Set – Enables a wider redundancy of data and also supports a wider distribution of read operations in the Replica Set.
MongoDB Replica Set Deployment Tuning Techniques
An ideal replica set will require a well laid out architecture with at least 3 members for a production system. These deployment strategies will help you enable a great replica set.
- Use delayed and hidden members to support dedicated functions such as reporting and backup.
- Always make the number of deployed members odd. As we have discussed above, an odd number of members will be required in electing a primary. Therefore ensure you have an odd number and if not, you can always add an arbiter.
- For read-heavy deployments, you will need to balance the load. You will therefore be required to distribute reads to the secondary in order to improve read performance. Besides, when the data grows with time, you can add more members and distribute them but put in mind that you have to configure it in such a way that the paramount design is to elect the primary.
- Always consider fault tolerance. This is basically determining how many members can be unavailable at a given time and how many will remain to sustain the election process of a primary. If you don’t have a primary, unfortunately the replica set will not accept any write operation.
- Add new members to the existing replica set before demand arises.
- Use replica set tag sets to ensure that all operations are replicated at specific data centers. You can also use these tags in routing for the read operations for specific deployment machines.
- Deploy most of your members in one location to shun the setback that will arise from network partitioning. Network partitioning can be the result of disconnected communication between data centers, consequently hindering the replication process and the process of electing a primary.
- For safety reasons, distribute your members geographically besides making some hidden. You can set at least 2 or 3 members’ priority to zero so as to prevent from making them primary.
- Employ journaling to protect data loss that may result to something like a power failure. This ensures that data is written to disk in case of sudden shutdown.
The Operation Log (Oplog)
The oplog maintains a record of the master operations that are to be applied to the slaves. It is stored in a database called local in oplog.$main collection. It is created when you start a replica set member for the first time. On the upper bound, the oplog is restricted to a size of 50GB for all storage engines. The oplog size can be changed from a default setting. If this size is reached for example in 24 hours of operation, the secondaries will not be able to copy from it during this duration comfortably and may end up not copying at all. You can change the size of the oplog using the option replSetResizeOplog i.e.
db.database({replSetResizeOplog:1, size: 16384})If you are to reduce the size of this oplog, it will result in some data being removed. The core impact of this in the replica set is that members synced to this node become stale. Thus, you will need to resync these members.
Workload Patterns that Would Require a Large Oplog Size
- Update to multiple documents at once. The multiple update operations must be translated to an individual operation for improving results across the nodes. This operation will use a vast space of the oplog space.
- Significant number of in-place updates. This generally happens when updating data of documents not necessarily increasing the size of this document. The database will record a large number of operation to the oplog hence increasing its size.
- Deletions equal the same amount of data as inserts. This happens when you try to delete an amount of data (almost) equal to the amount of data you insert. This operation will tend to increase the size of the oplog.
Conclusion
Replication is one important aspect of databases that developers need to understand. It ensures increased availability of data. Your MongoDB server may go down, for example, due to a power outage but you would still like your clients to access its data. If you have replicated data in another server, your clients will be able to continue accessing data from it if the primary server fails. Besides, there is increased load balancing so that instead of all users accessing one single server, we have seen the tradeoffs of serving traffic from secondary replicas.



