blog
Database High Availability Comparison – MySQL / MariaDB Replication vs Oracle Data Guard

In the “State of the Open-Source DBMS Market, 2018”, Gartner predicts that by 2022, 70 percent of new in-house applications will be developed on an open-source database. And 50% of existing commercial databases will have converted. So, Oracle DBAs, get ready to start deploying and managing new open source databases – along with your legacy Oracle instances. Unless you’re already doing it.
So how does MySQL or MariaDB replication stack up against Oracle Data Guard? In this blog, we’ll compare the two from the standpoint of a high availability database solution.
What To Look For
A modern data replication architecture is built upon flexible designs that enable unidirectional and bidirectional data replication, as well as quick, automated failover to secondary databases in the event of unplanned service break. Failover should be also easy to execute and reliable so no committed transactions would be lost. Moreover switchover or failover should ideally be transparent to applications.
Data replication solutions have to be capable to copy data with very low latency to avoid processing bottlenecks and guarantee real-time access to data. Real-time copies could be deployed on a different database running on low-cost hardware.
When used for disaster recovery, the system must be validated to ensure application access to the secondary system with minimal service interruption. The ideal solution should allow regular testing of the disaster recovery process.
Main Topics of Comparison
- Data availability and consistency
- Gtid, scm
- Mention Replication to multiple standby, async + sync models
- Isolation of standby from production faults (e.g. delayed replication for mysql)
- Avoid loss of data (sync replication)
- Standby systems utilization
- Usage of the standby
- Failover, Switchover and automatic recovery
- Database failover
- Transparent application failover (TAF vs ProxySQL, MaxScale)
- Security
- Ease of use and management (unified management of pre-integrated components)
Data Availability and Consistency
MySQL GTID
MySQL 5.5 replication was based on binary log events, where all a slave knew was the precise event and the exact position it just read from the master. Any single transaction from a master may have ended in various binary logs from different slaves, and the transaction would typically have different positions in these logs. It was a simple solution that came with limitations, topology changes could require an admin to stop replication on the instances involved. These changes could cause some other issues, e.g., a slave couldn’t be moved down the replication chain without a time-consuming rebuild. Fixing a broken replication link would require manually determining a new binary log file and position of the last transaction executed on the slave and resuming from there, or a total rebuild. We’ve all had to work around these limitations while dreaming about a global transaction identifier.
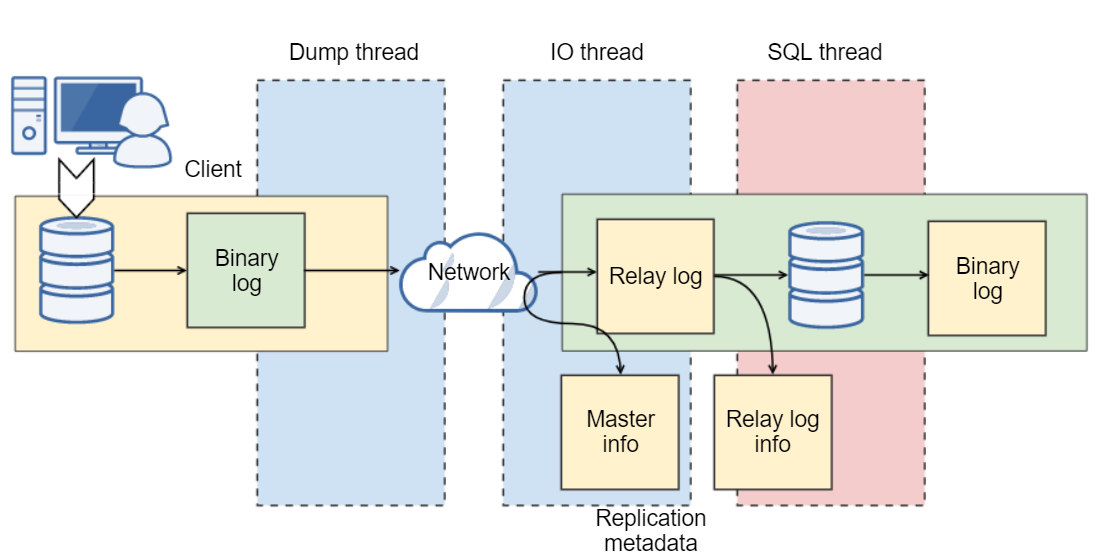
MySQL version 5.6 (and MariaDB version 10.0.2) introduced a mechanism to solve this problem. GTID (Global Transaction Identifier) provides better transactions mapping across nodes.
With GTID, slaves can see a unique transaction coming in from several masters and this can easily be mapped into the slave execution list if it needs to restart or resume replication. So, the advice is to always use GTID. Note that MySQL and MariaDB have different GTID implementations.
Oracle SCN
In 1992 with the release 7.3 Oracle introduced a solution to keep a synchronized copy of a database as standby, know as Data Guard from version 9i release 2. A Data Guard configuration consists of two main components, a single primary database, and a standby database (up to 30). Changes on the primary database are passed through the standby database, and these changes are applied to the standby database to keep it synchronized.
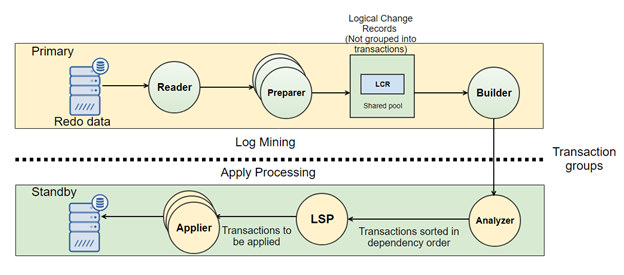
Oracle Data Guard is initially created from a backup of the primary database. Data Guard automatically synchronizes the primary database and all standby databases by transmitting primary database redo – the information used by every Oracle Database to protect transactions – and applying it to the standby database. Oracle uses an internal mechanism called SCN (System Change Number). The system change number (SCN) is Oracle’s clock, every time we commit, the clock increments. The SCN marks a consistent point in time in the database which is a checkpoint that is the act of writing dirty blocks (modified blocks from the buffer cache to disk). We can compare it to GTID in MySQL.
Data Guard transport services handle all aspects of transmitting redo from a primary to a standby database. As users commit transactions on the primary, redo records are generated and written to a local online log file. Data Guard transport services simultaneously transmit the same redo directly from the primary database log buffer (memory allocated within system global area) to the standby database(s) where it is written to a standby redo log file.
There are a few main differences between MySQL replication and Data Guard. Data Guard’s direct transmission from memory avoids disk I/O overhead on the primary database. It is different from how MySQL works – reading data from memory decreases I/O on a primary database.
Data Guard transmits only database redo. It is in stark contrast to storage remote-mirroring which must transmit every changed block in every file to maintain real-time synchronization.
Async + Sync Models
Oracle Data Guard offers three different models for the redo apply. Adaptive models dependent on available hardware, processes, and ultimately business needs.
- Maximum Performance – default mode of operation, allowing a transaction to commit as soon as the redo data needed to recover that transaction is written to the local redo log on the master.
- Maximum Protection – no data loss and the maximum level of protection. The redo data needed to improve each operation must be written to both the local online redo log on the master and standby redo log on at least one standby database before the transaction commits (Oracle recommends at least two standbys). The primary database will shut down if a fault blocks it from writing its redo stream to at least one synchronized standby database.
- Maximum Availability – similar to Maximum Protection but the primary database will not shut down if a fault prevents it from writing its redo stream.
When it comes to choosing your MySQL replication setup, you have the choice between Asynchronous replication or Semi-Synchronous replication.
- Asynchronous binlog apply is the default method for MySQL replication. The master writes events to its binary log and slaves request them when they are ready. There is no guarantee that any event will ever reach any slave.
- Semi-synchronous commit on primary is delayed until master receives an acknowledgment from the semi-synchronous slave that data is received and written by the slave. Please note that semi-synchronous replication requires an additional plugin to be installed.
Standby Systems Utilization
MySQL is well known for its replication simplicity and flexibility. By default, you can read or even write to your standby/slave servers. Luckily, MySQL 5.6 and 5.7 brought many significant enhancements to Replication, including Global Transaction IDs, event checksums, multi-threaded slaves and crash-safe slaves/masters to make it even better. DBAs accustomed to MySQL replication reads and writes would expect a similar or even simpler solution from it’s bigger brother, Oracle. Unfortunately not by default.
The standard physical standby implementation for Oracle is closed for any read-write operations. In fact, Oracle offers logical variation but it has many limitations, and it’s not designed for HA. The solution to this problem is an additional paid feature called Active Data Guard, which you can use to read data from the standby while you apply redo logs.
Active Data Guard is a paid add-on solution to Oracle’s free Data Guard disaster recovery software available only for Oracle Database Enterprise Edition (highest cost license). It delivers read-only access, while continuously applying changes sent from the primary database. As an active standby database, it helps offload read queries, reporting and incremental backups from the primary database. The product’s architecture is designed to allow standby databases to be isolated from failures that may occur at the primary database.
An exciting feature of Oracle database 12c and something that Oracle DBA would miss is the data corruption validation. Oracle Data Guard corruption checks are performed to ensure that data is in exact alignment before data is copied to a standby database. This mechanism can also be used to restore data blocks on the primary directly from the standby database.
Failover, Switchover, and Automatic Recovery
To keep your replication setup stable and running, it is crucial for the system to be resilient to failures. Failures are caused by either software bugs, configuration problems or hardware issues, and can happen at any time. In case a server goes down, you need an alarm notification about the degraded setup. Failover (promotion of a slave to master) can be performed by the admin, who needs to decide which slave to promote.
The admin needs information about the failure, the synchronization status in case any data will be lost, and finally, steps to perform the action. Ideally, all should be automated and visible from a single console.
There are two main approaches to MySQL failover, automatic and manual. Both options have its fans, we describe the concepts in another article.
With the GTID, the manual failover becomes much easier. It consists of steps like:
- Stop the receiver module (STOP SLAVE IO_THREAD)
- Switch master (CHANGE MASTER TO
) - Start the receiver module (START SLAVE IO_THREAD)
Oracle Data Guard comes with a dedicated failover/switchover solution – Data Guard Broker. The broker is a distributed management framework that automates and centralizes the creation, maintenance, and monitoring of Oracle Data Guard configurations. With the access to the DG broker tool, you can perform configuration changes, switchovers, failovers and even dry test of your high availability setup. The two main actions are:
- The command SWITCHOVER TO < standby database name > is used to perform the switchover operation. After the successful switchover operation, database instances switch places and replication continues. It’s not possible to switchover when standby is not responding or it’s down.
- The common FAILOVER TO
is used to perform the failover. After the failover operation, the previous primary server requires recreation but the new primary can take the database workload.
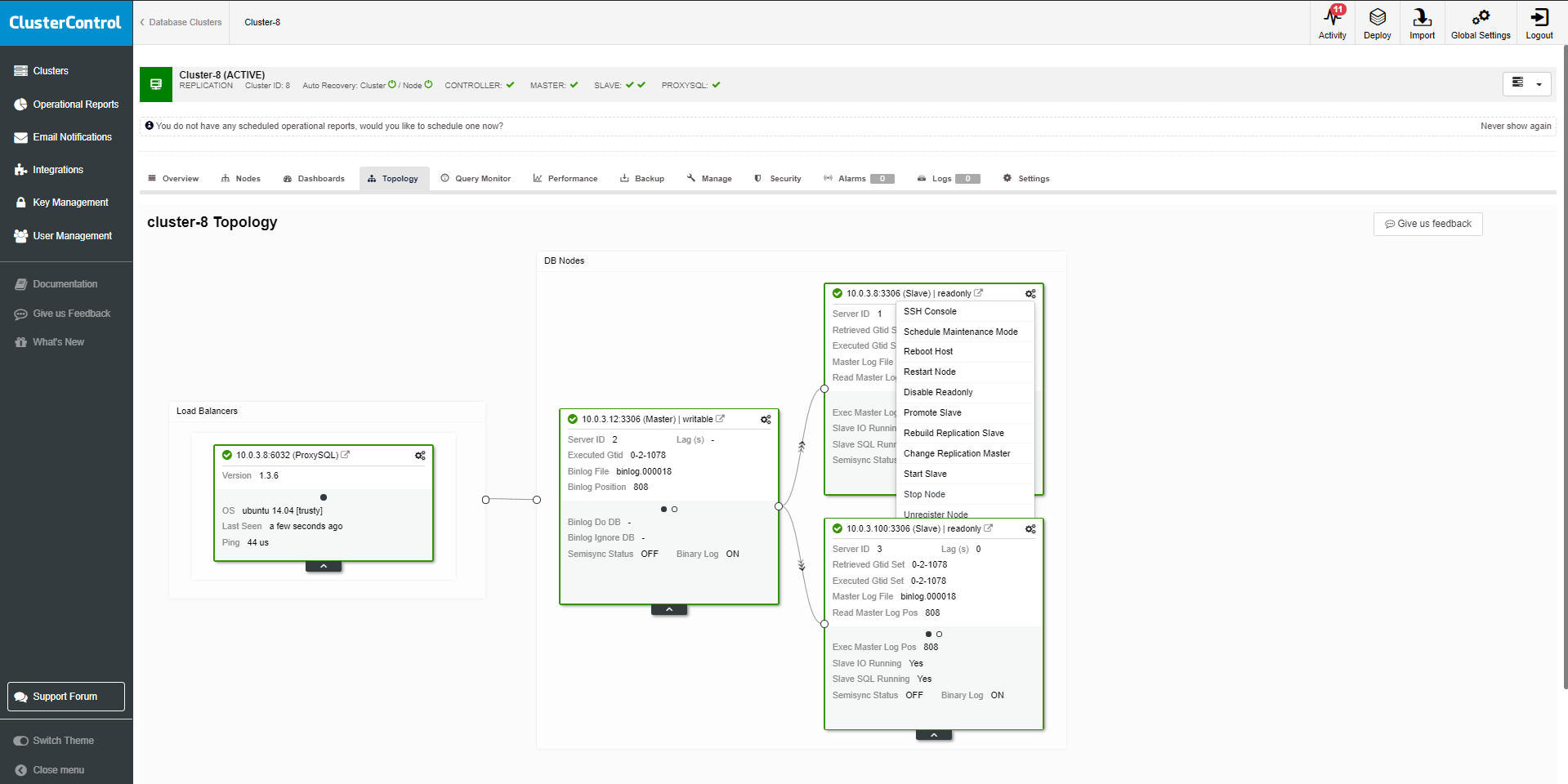
Speaking about failover, we need to consider how seamless your application failover can be. In the event of a planned/unplanned outage, how efficiently can user sessions be directed to a secondary site, with minimal business interruption.
The standard approach for MySQL would be to use one of the available Load Balancers. Starting from HAProxy which is widely used for HTTP or TCP/IP failover to database aware Maxscale or ProxySQL.
In Oracle, this problem is addressed by TAF (Transparent Application Failover). Once switchover or failover occurs, the application is automatically directed to the new primary. TAF enables the application to automatically and transparently reconnect to a new database, if the database instance to which the connection is made fails.
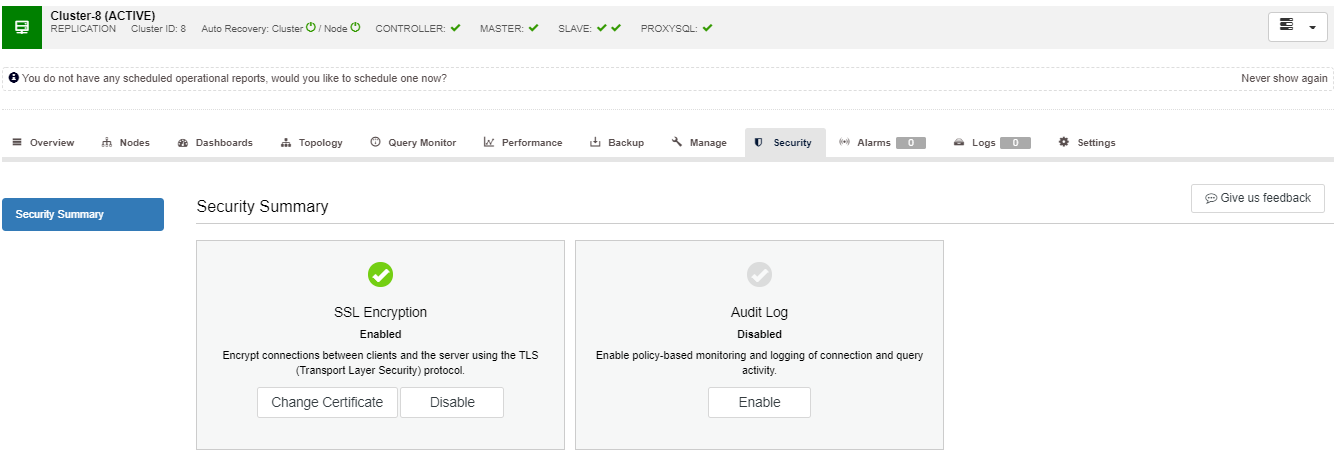
Security
Data security is a hot issue for many organizations these days. For those who need to implement standards like PCI DSS or HIPAA, database security is a must. The cross WAN environments might lead to concerns about data privacy and security especially as more businesses are having to comply with national and international regulations. MySQL binary logs used for replication may contain easy to read sensitive data. With the standard configuration, stealing data is a very easy process. MySQL supports SSL as a mechanism to encrypt traffic both between MySQL servers (replication) and between MySQL servers and clients. A typical way of implementing SSL encryption is to use self-signed certificates. Most of the time, it is not required to obtain an SSL certificate issued by the Certificate Authority. You can either use openssl to create certificates, example below:
$ openssl genrsa 2048 > ca-key.pem
$ openssl req -new -x509 -nodes -days 3600 -key ca-key.pem > ca-cert.pem
$ openssl req -newkey rsa:2048 -days 3600 -nodes -keyout client-key.pem > client-req.pem
$ openssl x509 -req -in client-req.pem -days 1000 -CA ca-cert.pem -CAkey ca-key.pem -set_serial 01 > client-cert.pem
$ openssl req -newkey rsa:2048 -days 3600 -nodes -keyout client-key.pem > client-req.pem
$ openssl x509 -req -in client-req.pem -days 1000 -CA ca-cert.pem -CAkey ca-key.pem -set_serial 01 > client-cert.pem
$ openssl rsa -in client-key.pem -out client-key.pem
$ openssl rsa -in server-key.pem -out server-key.pemThen modify replication with parameters for SSL.
….MASTER_SSL=1, MASTER_SSL_CA = '/etc/security/ca.pem', MASTER_SSL_CERT = '/etc/security/client-cert.pem', MASTER_SSL_KEY = '/etc/security/client-key.pem';For more automated option, you can use ClusterControl to enable encryption and manage SSL keys.
In Oracle 12c, Data Guard redo transport can be integrated with a set of dedicated security features called Oracle Advanced Security (OAS). Advanced Security can be used to enable encryption and authentication services between the primary and standby systems. For example, enabling Advanced Encryption Standard (AES) encryption algorithm requires only a few parameter changes in sqlnet.ora file to make redo (similar to MySQL binlog) encrypted. No external certificate setup is required and it only requires a restart of the standby database. The modification in sqlnet.ora and wallet are simple as:
Create a wallet directory
mkdir /u01/app/walletEdit sqlnet.ora
ENCRYPTION_WALLET_LOCATION=
(SOURCE=
(METHOD=file)
(METHOD_DATA=
(DIRECTORY=/u01/app/wallet)))Create a keystore
ADMINISTER KEY MANAGEMENT CREATE KEYSTORE '/u01/app/wallet' identified by root ;Open store
ADMINISTER KEY MANAGEMENT set KEYSTORE open identified by root ;Create a master key
ADMINISTER KEY MANAGEMENT SET KEY IDENTIFIED BY root WITH BACKUP;On standby
copy p12 and .sso files in the wallet directory and to update the sqlnet.ora file similar to the primary node.
For more information please follow Oracle’s TDE white paper, you can learn from the whitepaper how to encrypt datafile and make wallet always open.
Ease of Use and Management
When you manage or deploy Oracle Data Guard configuration, you may find out that there are many steps and parameters to look for. To answer that, Oracle created DG Broker.
You can certainly create a Data Guard configuration without implementing the DG Broker but it can make your life much more comfortable. When it’s implemented, the Broker’s command line utility – DGMGRL is probably the primary choice for the DBA. For those who prefer GUI, Cloud Control 13c has an option to access DG Broker via the web interface.
The tasks that Broker can help with are an automatic start of the managed recovery, one command for failover/switchover, monitoring of DG replication, configuration verification and many other.
DGMGRL> show configuration
Configuration - orcl_s9s_config
Protection Mode: MaxPerformance
Members:
s9sp - Primary database
s9ss - Physical standby database
Fast-Start Failover: DISABLED
Configuration Status:
SUCCESS (status updated 12 seconds agoMySQL does not offer a similar solution to Oracle DG Broker. However you can extend its functionality by using tools like Orchestrator, MHA and load balancers (ProxySQL, HAProxy or Maxscale). The solution to manage databases and load balancers is ClusterControl. The ClusterControl Enterprise Edition gives you will a full set of management and scaling features in addition to the deployment and monitoring functions offered as part of the free Community Edition.



