blog
MongoDB: How to Scale Reads

In previous posts of our “Become a MongoDB DBA” series, we covered Deployment, Configuration, Monitoring (part 1), Monitoring (part 2), backup and restore. From this blog post onwards, we shift our focus to the scaling aspects of MongoDB.
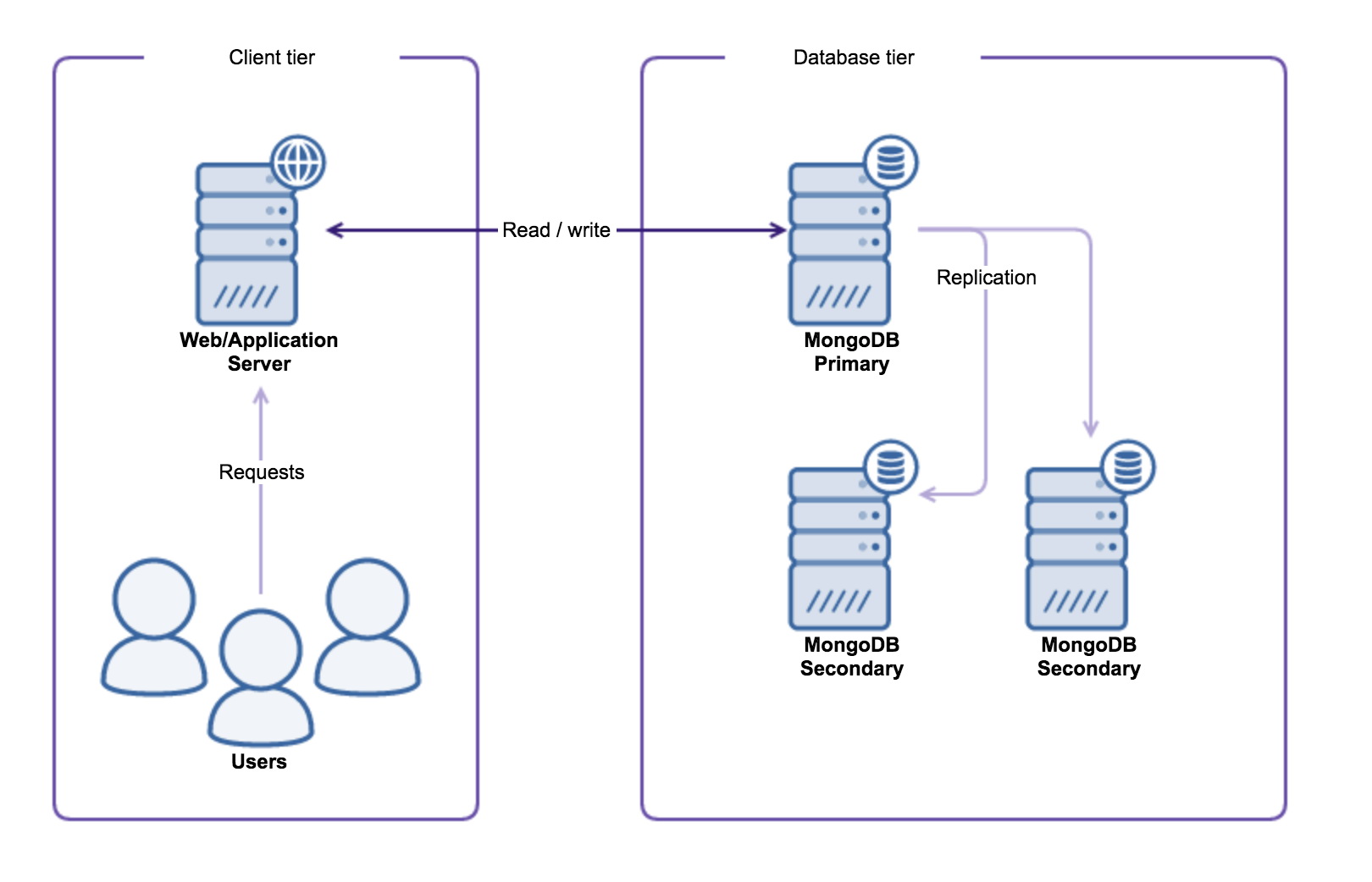
One of the cornerstones of MongoDB is that it is built with high availability and scaling in mind. Scaling can be done either vertically (bigger hardware) or horizontally (more nodes). Horizontal scaling is what MongoDB is good at, and it is not much more than spreading the workload to multiple machines. In effect, we’re making use of multiple low-cost commodity hardware boxes, rather than upgrading to a more expensive high performance server.
MongoDB offers both read- and write scaling, and we will uncover the differences of these two strategies for you. Whether to choose read- or write scaling all depends on the workload of your application: if your application tends to read more often than it writes data you will probably want to make use of the read scaling capabilities of MongoDB. Today we will cover MongoDB read scaling.
Read Scaling Considerations
With read scaling, we will scale out our read capacity. If you have used MongoDB before, or have followed this blog series, you may be aware that actually all reads end up on the primary by default. Regardless if your replicaSet contains nine nodes, your read requests still go to the primary. Why was this done deliberately?
In principle, there are a few considerations to make before you start reading from a secondary node directly. First of all: the replication is asynchronous, so not all secondaries will give the same results if you read the same data at the same point in time. Secondly: if you distribute read requests to all secondaries and use up too much of their capacity, if one of them becomes unavailable, the other secondaries may not be able to cope with the extra workload. Thirdly: on sharded clusters you should never bypass the shard router, as data may be out-of-date or data may have been moved to another shard. If you do use the shard router and set the read preference correctly, it may still return incorrect data due to incomplete or terminated chunk migrations.
As you have seen these are serious considerations you should make before scaling out your read queries on MongoDB. In general, unless your primary is not able to cope with the read workload it is receiving, we would advise against reading from secondaries. The price you pay for inconsistency is relatively high, compared to the benefits of offloading work from the master.
The main issue here seems to be the eventual consistency of MongoDB, so your application needs to be able to work around that. Also if you would have an application that is not bothered by stale data, analytics for instance, you could benefit greatly from using the secondaries.
Reading From a Secondary
There are two things that are necessary to make reading from a secondary possible: tell the MongoDB client driver that you actually wish to read from a secondary (if possible) and tell the MongoDB secondary server that it is okay to read from this node.
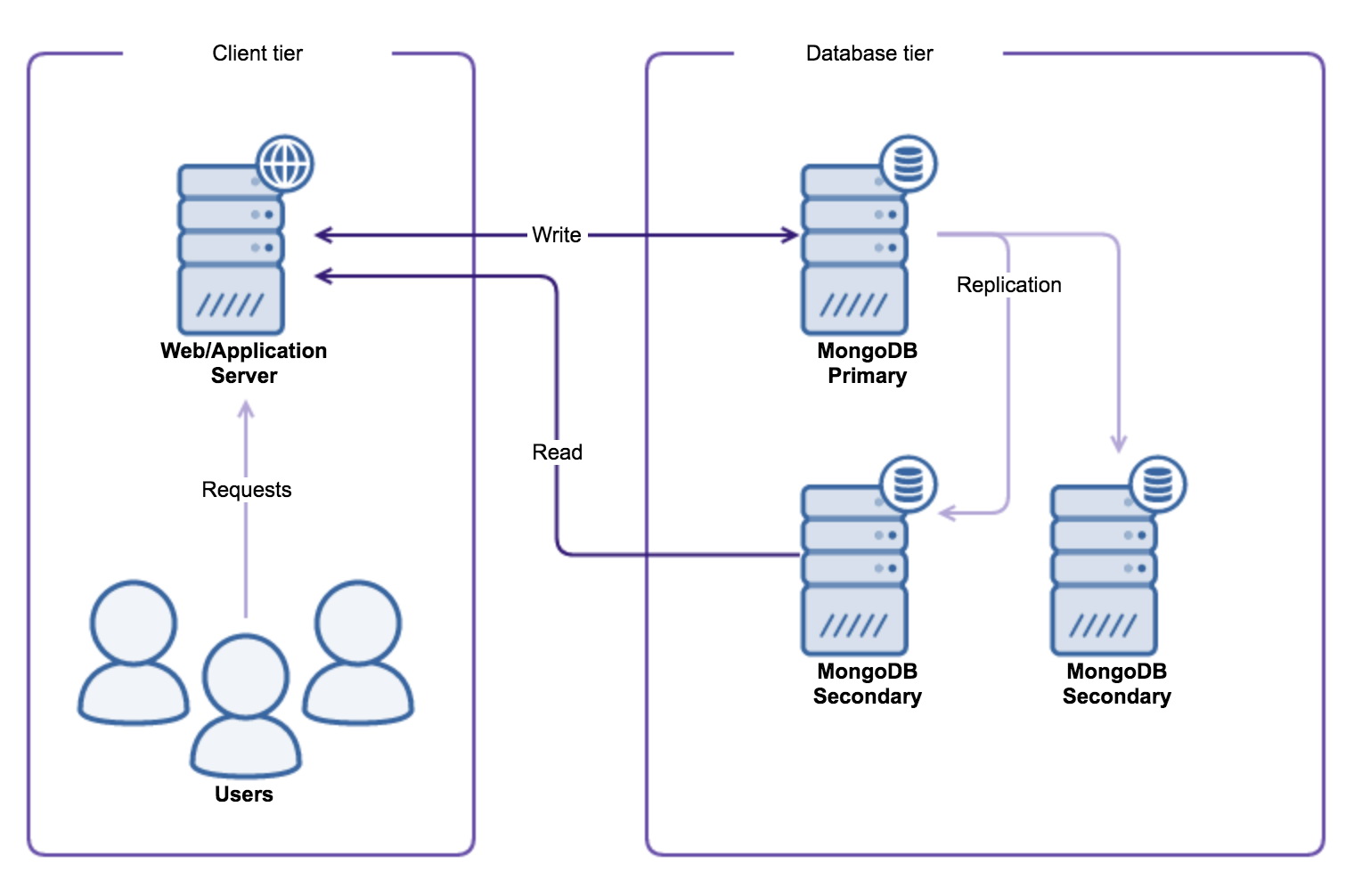
Setting read preference
For the driver, all you have to do is set the read preference. When reading data you simply set the read preference to read from a secondary. Let’s go over each and every read preference and explain what it does:
| primary | Always read from the primary (default) |
| primaryPreferred | Always read from the primary, read from secondary if the primary is unavailable |
| secondary | Always read from a secondary |
| secondaryPreferred | Always read from a secondary, read from the primary if no secondary is available |
| nearest | Always read from the node with the lowest network latency |
It is clear the default mode is the least preferred if you wish to scale out reads. PrimaryPreferred is not much better, as it will pick 99.999% of the time the primary. Still if the primary becomes unavailable you will have a fallback for read requests.
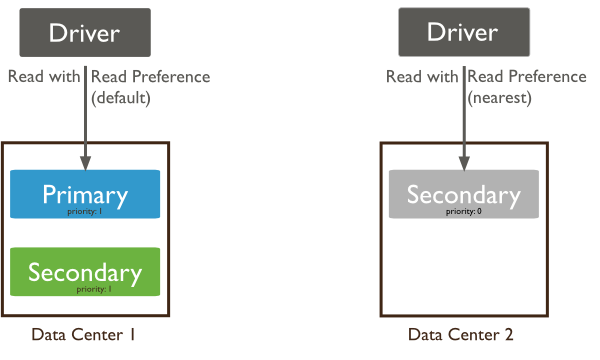
Secondary should work fine for scaling reads, but as you leave out the primary the reads will never have a fallback if no secondary is available. SecondaryPreferred is slightly better, but the reads will hit almost all of the time the secondaries, which still causes an uneven spread of reads. Also if no secondaries are available, in most cases there will be no longer a cluster and the primary will demote itself to a secondary. Only when an arbiter is part of the cluster, the secondaryPreferred mode makes sense.
Nearest should always pick the node with the lowest network latency. Even though this sounds great from an application perspective, this will not guarantee you get an even spread in read operations. But it will work very well in multi-regions where latency is high, and delays are noticeable. In such cases, reading from the nearest node means your application will be able to serve out data with the minimum latency.
Filtering Nodes with Tags
In MongoDB you can tag nodes in a replicaSet. This allows you to make groupings of nodes and use them for many purposes, including filtering them when reading from secondary nodes.
An example of a replicaSet with tagging can be:
{
"_id" : "myrs",
"version" : 2,
"members" : [
{
"_id" : 0,
"host" : "host1:27017",
"tags" : {
"dc": "1",
"rack": "e3"
}
}, {
"_id" : 1,
"host" : "host2:27017",
"tags" : {
"dc": "1",
"rack": "b2"
}
}, {
"_id" : 0,
"host" : "host3:27017",
"tags" : {
"dc": "2",
"rack": "q1"
}
}
]
}This tagging allows us to limit our secondary to exist, for instance, in our first datacenter:
db.getMongo().setReadPref(‘secondaryPreferred’, [ { "dc": "1" } ] )Naturally the tags can be used with all read preference modes, except Primary.
Enabling Secondary Queries
Apart from setting the read preference in the client driver, there is another limitation. By default MongoDB disables reads from a secondary server side, unless you specifically tell the host to allow read operations. Changing this is relatively easy, all you have to do is connect to the secondary and run this command:
myset:SECONDARY> rs.slaveOk()This will enable reads on this secondary for all incoming connections. You can also run this command in your application, but that would then imply your application is aware it could encounter a server that did not enable secondary reads.
Reading From a Secondary in a Shard
It is also possible to read from a secondary node in MongoDB sharded clusters. The MongoDB shard router (mongos) will obey the read preference set in the request and forward the request to a secondary in the shard(s). This also means you will have to enable reads from a secondary on all hosts in the sharded environment.
And as said earlier: an issue that may arise with reading from secondaries on a sharded environment, is that it might be possible to receive incorrect data from a secondary. Due to the migration of data between shards, data may be in transit from one shard to another. Reading from a secondary may then return incomplete data.
Adding More Secondary Nodes
Adding more secondary nodes to a MongoDB replicaSet would imply more overhead for replication. However unlike MySQL, syncing the oplog on secondaries is not only limited to the primary node. MongoDB can also sync the oplog from other secondaries, as long as they are up to date with the primary. This means oplog servicing is also possible from other secondaries, and we thus automatically have “intermediate” primaries. This means theoretically that if you add more secondaries, the performance impact will be limited. Keep in mind that this also means the data trickles down to the other nodes a bit slower, as the oplog entries have to pass at least two nodes now.
Conclusion
We have described what the impact is on MongoDB when reading from its secondaries, and what caveats to be aware of. If you don’t necessarily need to scale your reads, it is better not to perform this pre-emptive optimization. However if you think your setup would benefit from offloading the primary, better work around the issues described in this post.



