blog
MySQL vs MongoDB: Deployment & Provisioning


If you are a MySQL DBA you may ask yourself why you would install MongoDB? That is actually a very good question as MongoDB and MySQL have been in a flame-war a couple of years ago. But there are many cases where you simply have to.
One of these use cases may be that the project that your company is going to deploy in production relies on MongoDB. Or perhaps one of the developers on the project had a strong bias for using MongoDB. Couldn’t they have used MySQL instead?
In some cases, it might not be possible to use MySQL. MongoDB is a document store and is suitable for different use cases as compared to MySQL(even with the recently introduced MySQL document store feature). Therefore we are starting this blog series to give you an excellent starting point to get yourself prepared for MongoDB.
Differences and similarities
At first sight the differences between MySQL and MongoDB are quite apparent: MongoDB is a document store that stores data in JSON formatted text. You can either generate your own identifiers or have MongoDB generate one and then have the document stored alongside as a blob, quite generic like most key-value stores.
MongoDB can be either a single Mongo instance or live in a clustered and/or shared environment. With MongoDB the master is called the primary and the slaves the secondary. The naming is different but also the replication works differently.
This can best be explained in the way MongoDB handles transactions: MongoDB is not ACID compliant, instead it offers functionality that goes beyond this. MongoDB will ensure transactions will be written to the oplog (comparable with the MySQL binlog) in more than just the primary: also to secondary nodes. You can configure it to confirm the transaction after either writing to the primary, a set of secondaries, the majority of the secondaries or all members. The last one is obvious the safest option and would be similar to synchronous replication and this obviously has a performance penalty. Many choose to only have MongoDB confirm when it has written to at least one member or the majority in the topology and effectively this means the topology will reach an eventual consistency.
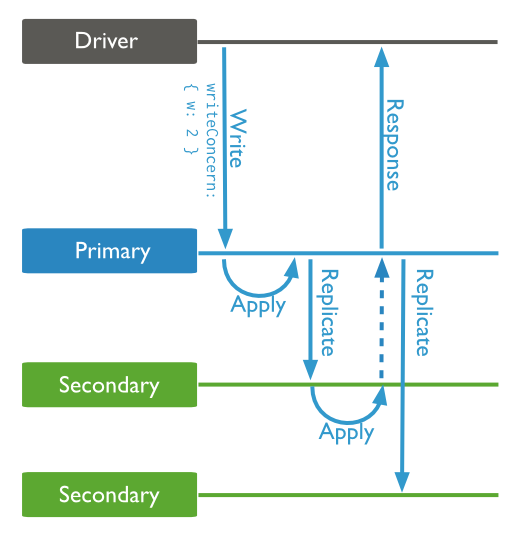
If this actually raises alarm bells for you: think about how MySQL Asynchronous replication keeps your topology consistent. Yes, MongoDB replication is actually a lot better than MySQL replication and in high level overview looks a bit like the Galera replicator.
Databases are still called databases, but tables are called collections. Collections do not need a strict structure like in MySQL so the schema can be changed at any time. This also means your application has to be designed in a way that data may either be missing or it will actually receive unexpected data.
Obviously MongoDB has also a lot of similarities with MySQL. You still are working with a database that needs to perform a certain workload on a limited set of CPU cores, a limited amount of RAM and a lot of (hopefully) fast storage. This also means you have to treat it in a similar way as MySQL: allocate enough diskspace, benchmark your system to know how much IO you can do with MongoDB and keep an eye out for memory usage.
Also even if MongoDB features a schemaless design it still needs indexes to find the data. Similar to MySQL, it features primary and secondary indexes and it can apply or remove them at runtime.
MongoDB isn’t that different from MySQL after all.
Deploying MongoDB
Installing MongoDB on a clean host isn’t that difficult: you simply download the necessary packages from MongoDB and install them or use the official MongoDB repository to install.
I CONTROL [initandlisten] MongoDB starting : pid=3071 port=27017 dbpath=/var/lib/mongo 64-bit host=n2
I CONTROL [initandlisten] db version v3.2.6After installing, you have a host that runs MongoDB and has no security enabled besides that it is configured to only listen on localhost. We must alter this default configuration to reflect our infrastructure: SSL, authentication and some other tuning parameters.
net:
port: 27017
bindIp: 172.16.0.30
ssl:
mode: requireSSL
PEMKeyFile: /etc/ssl/mongodb.pem
CAFile: /etc/ssl/ca.pem
http:
enabled: false
RESTInterfaceEnabled: false
security:
authorization: "enabled"Apart from the configuration we want to create a MongoDB replica set to ensure we have our data stored a bit more secure. That also means we have to do the installation three times in a row and then set up the replication. Three times may not sound as much, but imagine that we will eventually create a sharded cluster out of our replica set. That means we will have to repeat the installation even more often in the future. Perhaps time to automate this using a provisioning tool?
Provisioning
If you already have your provisioning tools in place: there are some great options available for the most used ones. If not, these tools can help you automate your infrastructure by provisioning hosts, deployment of applications and, if necessary, orchestration of many nodes. You may take the Ansible example as a good beginner starting point.
Ansible
For ansible there are two options possible: the Ansible MongoDB example and the Stouts MongoDB role. Both implementations will cover installation, configuration and replication. The Ansible MongoDB example is a simple example that can easily be extended for your needs while the Stouts MongoDB role is meant for more advanced usage with Ansible.
Puppet
If you are using Puppet the best option is to use the Puppetlabs MongoDB module. This module is created and maintained by Puppetlabs. Even though the module is still in beta the structure of the module is good. It supports, next to installation, configuration and replication, also crude user management.
Chef
For Chef there are many cookbooks available, but the only cookbook that is currently actively maintained is the Mongodb3 cookbook. The cookbook supports installation, configuration, replication and sharding. It also is able to setup in AWS.
Saltstack
The MongoDB formula for Saltstack supports installation, configuration, replication and sharding.
Conclusion
All four are great starting points for deploying MongoDB. Obviously we still need to do additional configuration tweaking after deploying our initial hosts and that will be the focus of our next blog post.



