blog
Automatic Failover of the Moodle PostgreSQL Database

One of the key aspects of high availability is the ability to quickly react to failures. It is not uncommon to manually manage databases, and have monitoring software keep an eye on database health. In case of failure, the monitoring software sends an alert to on-call staff. This means somebody may potentially need to wake up, get to a computer and log into systems and look at logs – that is, there is quite some lead time before remediation can start. Ideally, the whole process should be automated.
In this blog, we’ll look at how to deploy a fully automated system that detects when the primary database fails, and initiates failover procedures by promoting a secondary database. We will use ClusterControl to perform automatic failover of the Moodle PostgreSQL database.
Advantage of Automatic Failover
- Less time to recover the database service
- Higher system uptime
- Less reliance on the DBA or admin who set up high availability for the database
Architecture
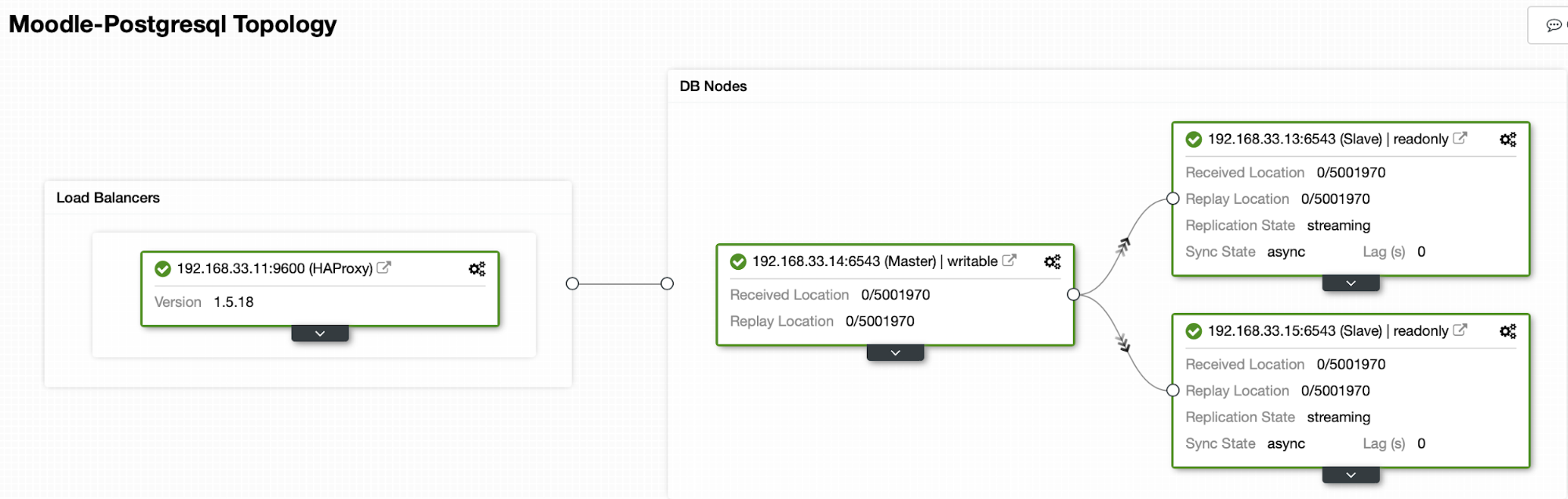
Currently we have one Postgres primary server and two secondary servers under HAProxy load balancer that sends the Moodle traffic to the primary PostgreSQL node. Cluster recovery and node auto recovery in ClusterControl are the important settings to perform the automatic failover process.

Controlling Which Server to Failover To
ClusterControl offers whitelisting and blacklisting of a set of servers that you want to participate in the failover, or exclude as a candidate.
There are two variables you can set in the cmon configuration,
- replication_failover_whitelist : it contains a list of IP’s or hostnames of secondary servers which should be used as potential primary candidates. If this variable is set, only those hosts will be considered.
- replication_failover_blacklist : it contains a list of hosts which will never be considered as a primary candidate. You can use it to list secondary servers that are used for backups or analytical queries. If the hardware varies between secondary servers, you may want to put here the servers which use slower hardware.
Auto Failover Process
Step 1
We have started the data loading on the primary server(192.168.33.14) using the sysbench tool.
[root@centos11 sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Step 2
We are going to stop Postgres primary server (192.168.33.14). In ClusterControl, the (enable_cluster_autorecovery) parameter is enabled so it will promote the next suitable primary.
# service postgresql-12 stopStep 3
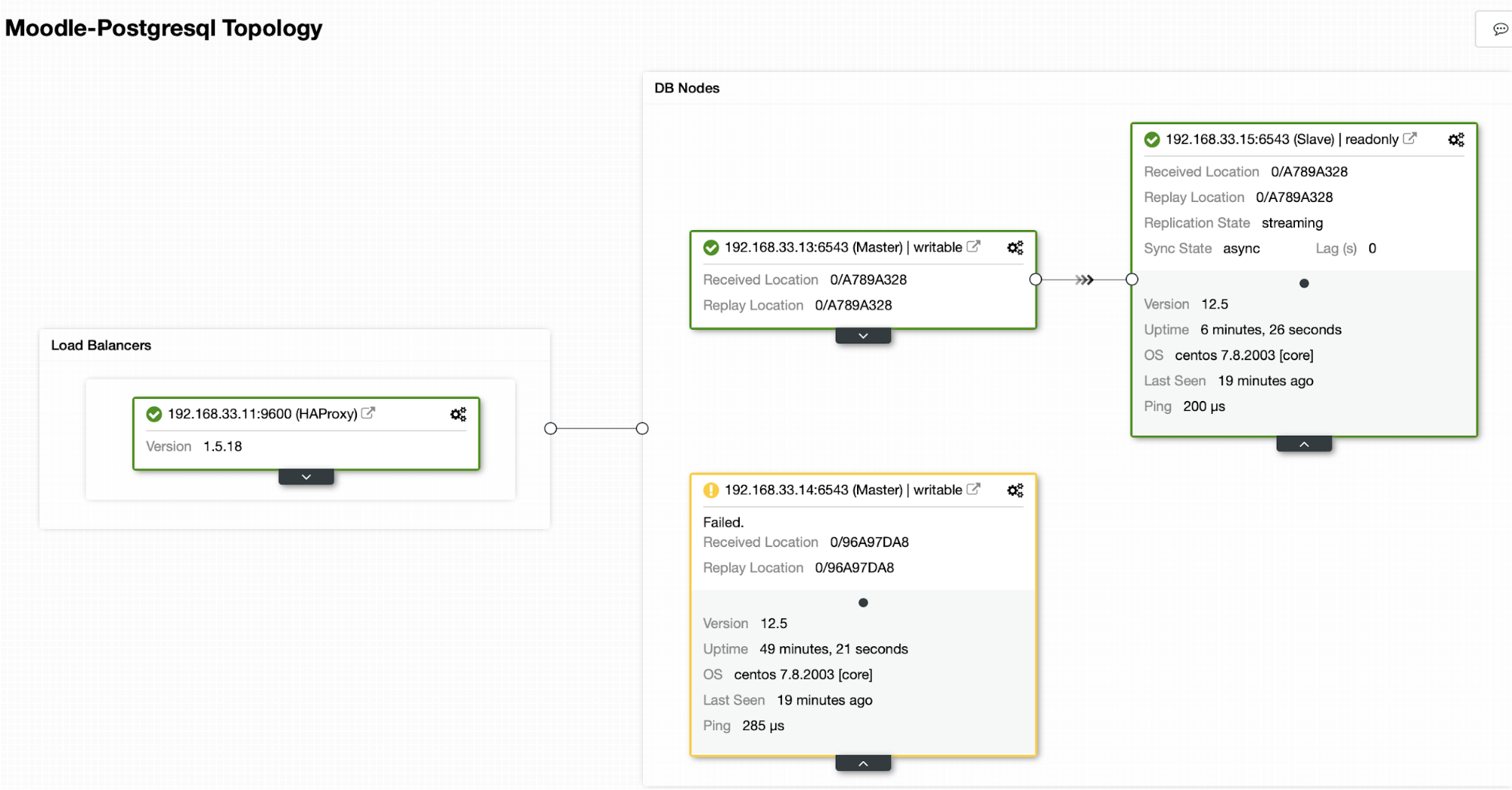
ClusterControl detects failures in the primary and promotes a secondary with the most current data as a new primary. It also works on the rest of the secondary servers to have them replicate from the new primary.

In our case the (192.168.33.13) is a new primary server and secondary servers now replicate from this new primary server. Now the HAProxy routes the database traffic from the Moodle servers to the latest primary server.
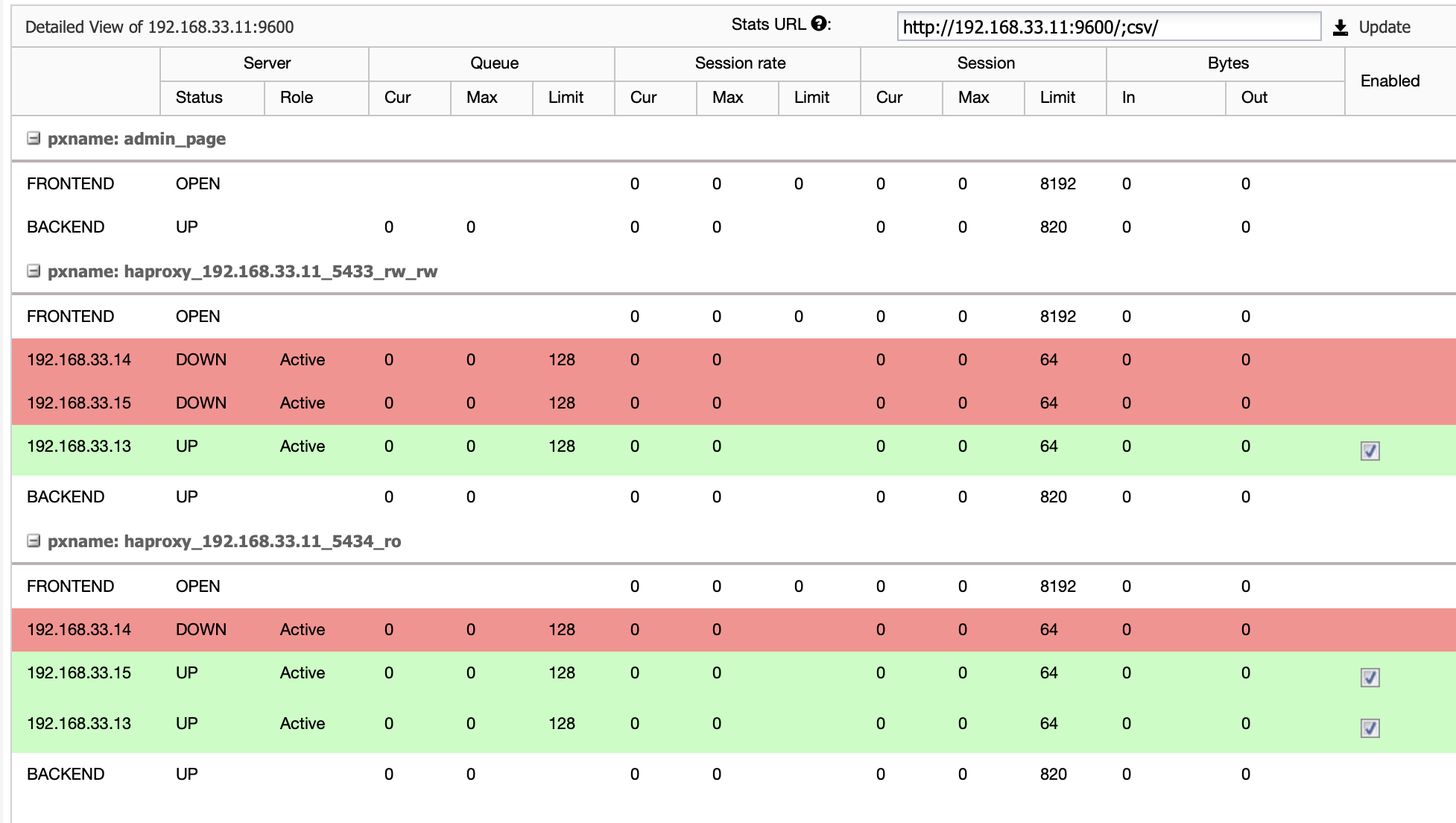
From (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)From (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Current Topology
When HAProxy detects that one of our nodes, either primary or replica, is not accessible, it automatically marks it as offline. HAProxy will not send any traffic from the Moodle application to it. This check is done by health check scripts that are configured by ClusterControl at the time of deployment.
Once ClusterControl promotes a replica server to primary, our HAProxy marks the old primary as offline and puts the promoted node online.
Once the old primary is back online, it will not automatically sync to the new primary server. We need to let it back into the topology, and it can be done via the ClusterControl interface. This will avoid the possibility of data loss or inconsistency, in case we want to investigate why that server failed in the first place.
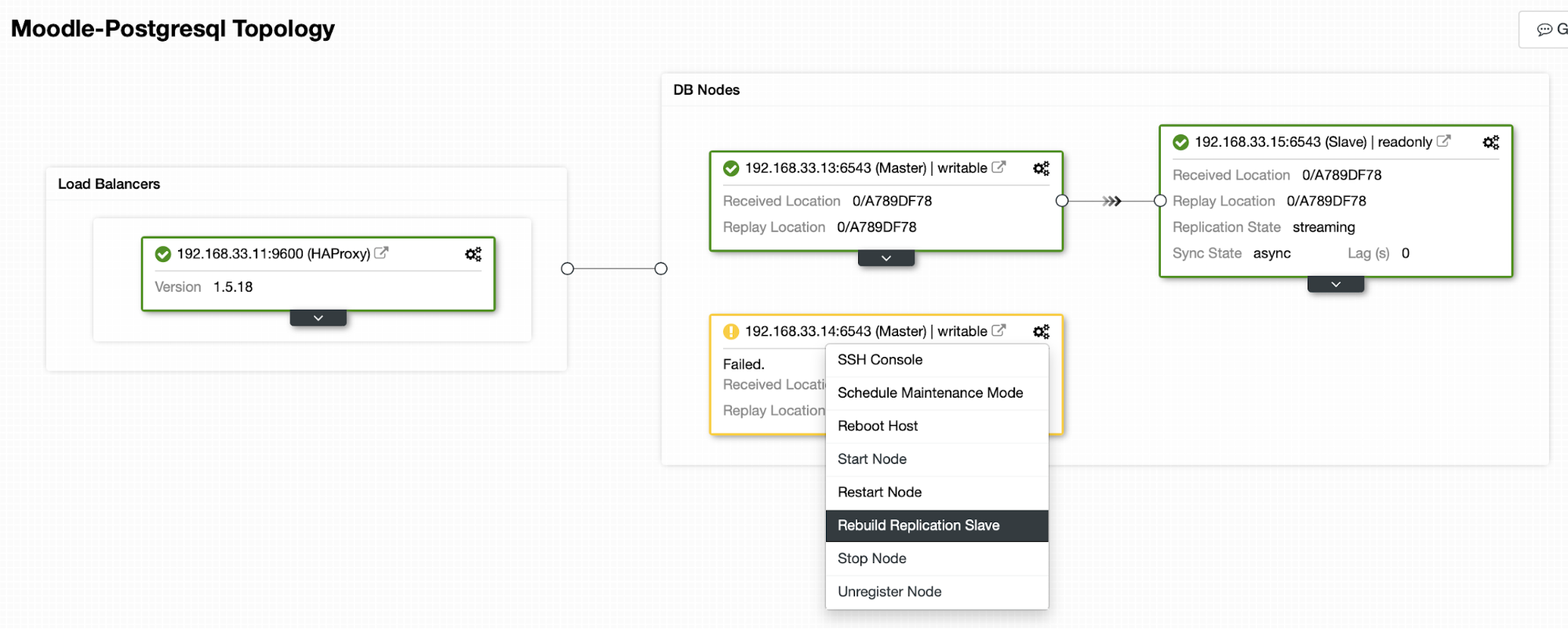
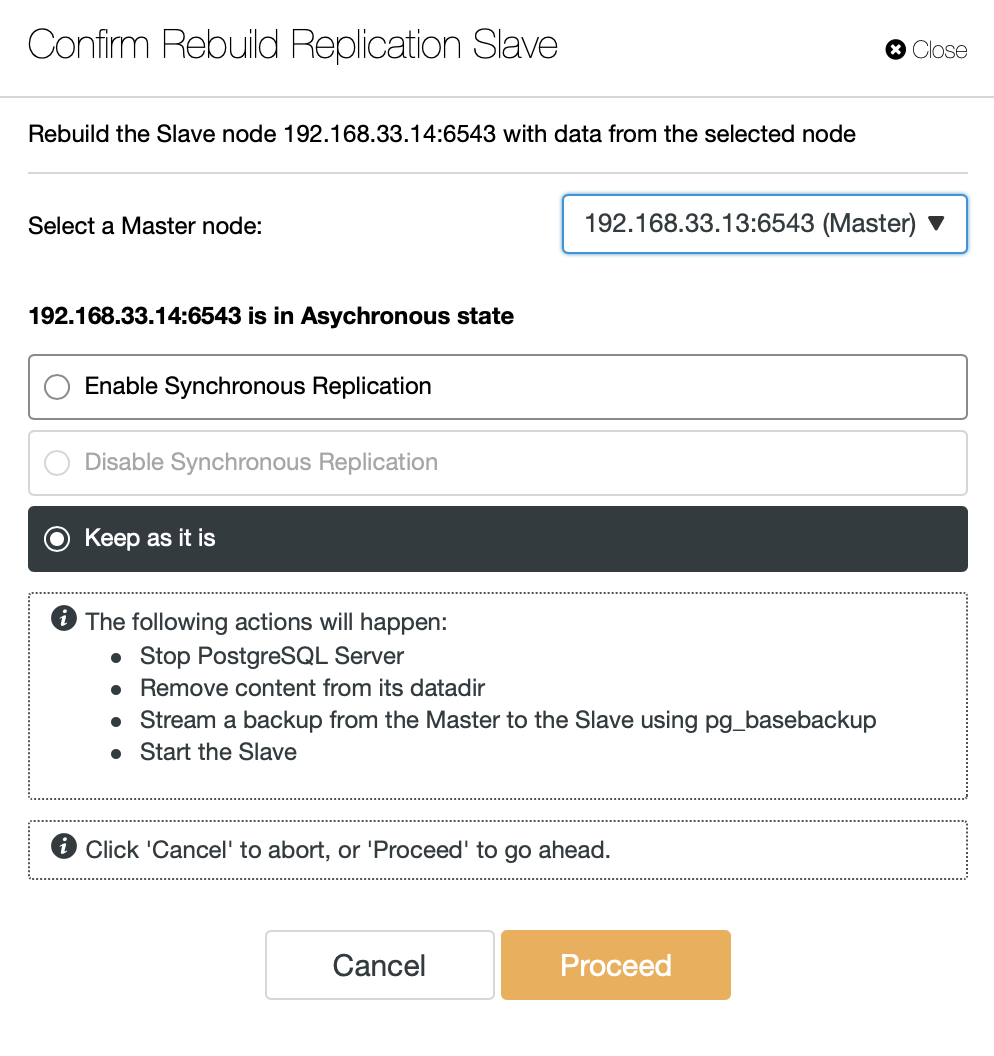
ClusterControl will stream backup from the new primary server and configure the replication.
Conclusion
Auto failover is an important part of any Moodle production database. It can reduce downtime when a server goes down, but also when performing common maintenance tasks or migrations. It is important to get it right, as it is important for the failover software to take the right decisions.



