blog
Architecture and Tuning of Memory in PostgreSQL Databases

Memory management in PostgreSQL is important for improving the performance of the database server. PostgreSQL configuration file (postgres.conf) manages the configuration of the database server. It uses default values of the parameters, but we can change these values to better reflect workload and operating environment.
In this blog, we’ll cover these memory related parameters. But before we start, let’s have a look at the memory architecture in PostgreSQL.
Memory Architecture
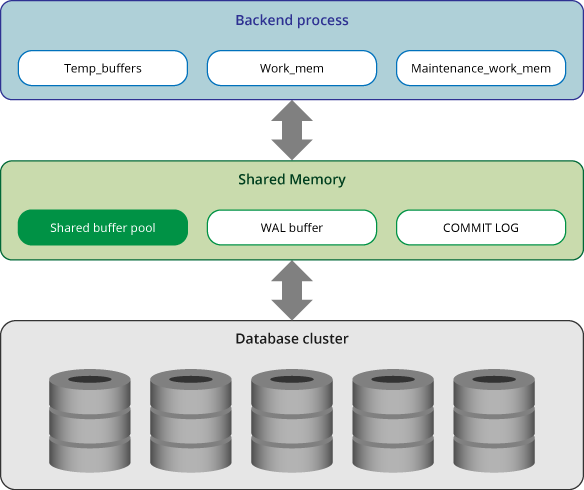
Memory in PostgreSQL can be classified into two categories:
- Local Memory area: It is allocated by each backend process for its own use.
- Shared memory area: It is used by all processes of a PostgreSQL server.
Local Memory Area
In PostgreSQL, each backend process allocates local memory for query processing; each area is divided into sub-areas whose sizes are either fixed or variable.
The sub-areas are as follow.
Work_mem
The executor uses this area for sorting tuples by ORDER BY and DISTINCT operations. It also uses it for joining tables by merge-join and hash-join operations.
Maintenance_work_mem
This parameter is used for some kinds of maintenance operations (VACUUM, REINDEX).
Temp_buffers
The executor uses this area for storing temporary tables.
Shared Memory Area
Shared memory area is allocated by PostgreSQL server when it starts up. This areas is divided into several fixed sized sub-areas.
Shared buffer pool
PostgreSQL loads pages within tables and indexes from persistent storage to a shared buffer pool, and then operates on them directly.
WAL buffer
PostgreSQL supports the WAL (Write ahead log) mechanism to ensure that no data is lost after a server failure. WAL data is really a transaction log in PostgreSQL and WAL buffer is a buffering area of the WAL data before writing it to a persistent storage.
Commit Log
The, commit log (CLOG) keeps the states of all transactions, and is part of the concurrency control mechanism. The commit log is allocated to the shared memory and used throughout transaction processing.
PostgreSQL defines the following four transaction states.
- IN_PROGRESS
- COMMITTED
- ABORTED
- SUB-COMMITTED
Tuning PostgreSQL Memory Parameters
There are some important parameters which are recommended for memory management in PostgreSQL. You should take into account the following.
Shared_buffers
This parameter designates the amount of memory used for shared memory buffers. The shared_buffers parameter determines how much memory is dedicated to to the server for caching data. The default value of shared_buffers is typically 128 megabytes (128MB).
The default value of this parameter is very low because on some platforms like older Solaris versions and SGI, having large values requires invasive action like recompiling the kernel. Even on the modern Linux systems, the kernel will likely not allow setting shared_buffers to over 32MB without adjusting kernel settings first.
The mechanism has changed in PostgreSQL 9.4 and later, so kernel settings will not have to be adjusted there.
If there is high load on the database server, then setting a high value will improve performance.
If you have a dedicated DB server with 1GB or more of RAM, a reasonable starting value for shared_buffer configuration parameter is 25% of the memory in your system.
Default value of shared_buffers = 128 MB. The change requires restart of PostgreSQL server.
General recommendation to set the shared_buffers is as follows.
- Below 2GB memory, set the value of shared_buffers to 20% of total system memory.
- Below 32GB memory, set the value of shared_buffers to 25% of total system memory.
- Above 32GB memory, set the value of shared_buffers to 8GB
Work_mem
This parameter specifies the amount of memory to be used by internal sort operations and hash tables before writing to temporary disk files. If a lot of complex sorts are happening, and you have enough memory, then increasing the work_mem parameter allows PostgreSQL to do larger in-memory sorts which will be faster than disk based equivalents.
Note that for a complex query, many sort or hash operations might be running in parallel. Each operation will be allowed to use as much memory as this value specifies before it starts to write data into the temporary files. There is one possibility that several sessions could be doing such operations concurrently. Therefore, the total memory used could be many times the value of work_mem parameter.
Please remember that when choosing the right value. Sort operations are used for ORDER BY, DISTINCT and merge joins. Hash tables are used in hash joins, hash based processing of IN subqueries and hash based aggregation.
The parameter log_temp_files can be used to log sorts, hashes and temp files which can be useful in figuring out if sorts are spilling to disk instead of fitting in memory. You can check the sorts spilling to disk using EXPLAIN ANALYZE plans. For example, in the output of EXPLAIN ANALYZE, if you see the line like: “Sort Method: external merge Disk: 7528kB”, a work_mem of at least 8MB would keep the intermediate data in memory and improve the query response time.
The default value of work_mem = 4MB.
General recommendation to set the work_mem is as follows.
- Start with low value: 32-64MB
- Then look for ‘temporary file’ lines in logs
- Set to 2-3 times the largest temp file
maintenance _work_mem
This parameter specifies the maximum amount of memory used by maintenance operations such as VACUUM, CREATE INDEX and ALTER TABLE ADD FOREIGN KEY. Since only one of these operations can be executed at a time by a database session and a PostgreSQL installation doesn’t have many of them running concurrently, it is safe to set the value of maintenance_work_mem significantly larger than work_mem.
Setting the larger value might improve performance for vacuuming and restoring database dumps.
It is necessary to remember that when autovacuum runs, up to autovacuum_max_workers times this memory may be allocated, so be careful not to set the default value too high.
The default value of maintenance_work_mem = 64MB.
General recommendation to set maintenance_work_mem is as follows.
- Set the value 10% of system memory, up to 1GB
- Maybe you can set it even higher if you are having VACUUM problems
Effective_cache_size
The effective_cache_size should be set to an estimate of how much memory is available for disk caching by the operating system and within the database itself. This is a guideline for how much memory you expect to be available in the operating system and PostgreSQL buffer caches, not an allocation.
PostgreSQL query planner uses this value to figure out whether the plans it’s considering would be expected to fit in RAM or not. If it is set too low, indexes may not be used for executing queries the way you would expect. As most Unix systems are fairly aggressive when caching, at least 50% of the available RAM on a dedicated database server will be full of cached data.
General recommendation for effective_cache_size is as follows.
- Set the value to the amount of file system cache available
- If you don’t know, set the value to the 50% of total system memory
The default value of effective_cache_size = 4GB.
Temp_buffers
This parameter sets the maximum number of temporary buffers used by each database session. The session local buffers are used only for access to temporary tables. The setting of this parameter can be changed within individual sessions but only before the first use of temporary tables within the session.
PostgreSQL database utilizes this memory area for holding the temporary tables of each session, these will be cleared when the connection is closed.
The default value of temp_buffer = 8MB.
Conclusion
Understanding the memory architecture and tuning the appropriate parameters is important to improve the performance. This is especially necessary for high workload systems. For more generic performance tuning tips, please review this performance cheat sheet for PostgreSQL.



