blog
How to Cluster Odoo 12 with PostgreSQL Streaming Replication for High Availability

Odoo (formerly known as OpenERP) is a suite of open-source business apps. It comes in two versions – community and enterprise. Some of the most popular apps (and free!) integrated within this platform are Discuss, CRM, Inventory, Website, Employee, Leaves, Recruitment, Expenses, Accounting, Invoicing, Point of Sale and many more.
In this blog post, we’ll look at how to cluster Odoo to achieve high availability and scalability. This post is similar to our previous posts on scaling Drupal, WordPress, Magento. The softwares used are Odoo 12, HAProxy 1.8.8, Keepalived 1.3.9, PostgreSQL 11 and OCFS2 (Oracle Cluster File System).
Our setup consists of 6 servers:
- lb1 (HAProxy) + keepalived + ClusterControl – 192.168.55.101
- lb2 (HAProxy) + keepalived + shared storage – 192.168.55.102
- odoo1 – 192.168.55.111
- odoo2 – 192.168.55.112
- postgresql1 (master) – 192.168.55.121
- postgresql2 (slave) – 192.168.55.122
All nodes are running on Ubuntu 18.04.2 LTS (Bionic). We will be using ClusterControl to deploy and manage PostgreSQL, Keepalived and HAProxy as it’ll save us a bunch of work. ClusterControl will be co-located with HAProxy on lb1 while we will add an additional disk to lb2 to be used as a shared storage provider. This disk will be mounted using a clustered file system called OCFS2 as a shared directory. A virtual IP address, 192.168.55.100 acts as the single endpoint for our database service.
The following diagram illustrates our overall system architecture:
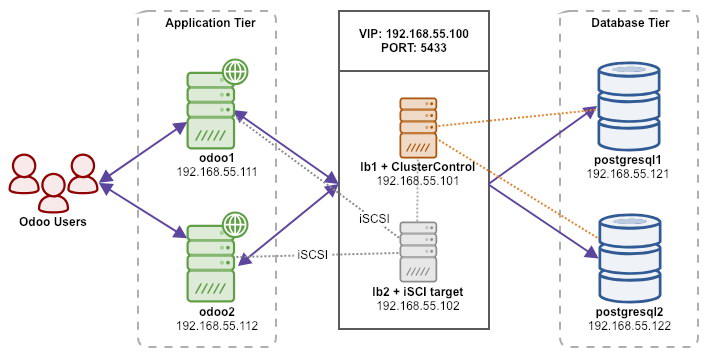
The following is the content of /etc/hosts on all nodes:
192.168.55.101 lb1.local lb1 cc.local cc
192.168.55.102 lb2.local lb2 storage.local storage
192.168.55.111 odoo1.local odoo1
192.168.55.112 odoo2.local odoo2
192.168.55.121 postgresql1.local postgresql1
192.168.55.122 postgresql2.local postgresql2Deploying PostgreSQL Streaming Replication
We will start by installing ClusterControl on lb1:
$ wget severalnines.com/downloads/cmon/install-cc
$ chmod 755 ./install-cc
$ sudo ./install-ccFollow the installation wizard, you will need to answer some questions during the process.
Setup passwordless SSH from ClusterControl node (lb1) to all nodes that will be managed by ClusterControl, which is lb1 (itself), lb2, postresql1 and postgresql2. But first, generate a SSH key:
$ whoami
ubuntu
$ ssh-keygen -t rsa # press Enter on all promptsThen copy the key to all target nodes using ssh-copy-id tool:
$ whoami
ubuntu
$ ssh-copy-id ubuntu@lb1
$ ssh-copy-id ubuntu@lb2
$ ssh-copy-id ubuntu@postgresql1
$ ssh-copy-id ubuntu@postgresql2Open ClusterControl UI at http://192.168.55.101/clustercontrol and create a super admin user with password. You will be redirected to the ClusterControl UI dashboard. Then, deploy a new PostgreSQL cluster by clicking on the “Deploy” button in the top menu. You will be presented with the following deployment dialog:
Here is what we typed in the next dialog, “Define PostgreSQL Servers”:
- Server Port: 5432
- User: postgres
- Password: s3cr3t
- Version: 11
- Datadir:
- Repository: Use Vendor Repositories
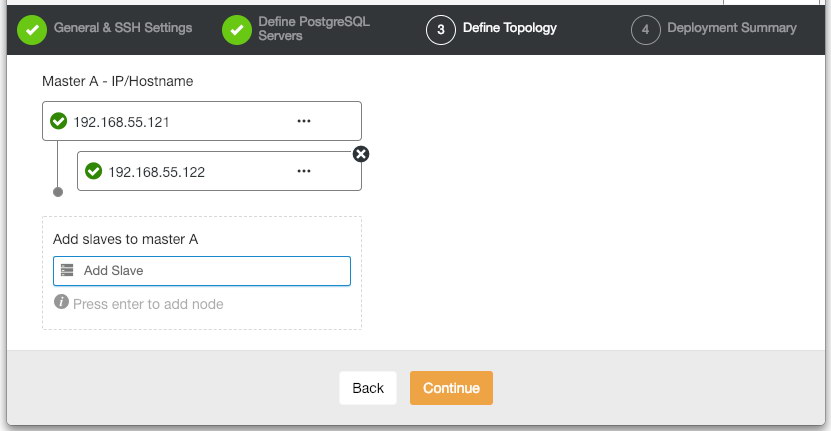
On the “Define Topology” section, specify the IP address of postgresql1 and postgresql2 accordingly:
Under the last section “Deployment Summary” you have an option to enable synchronous replication. Since we will use the slave only for failover purposes (the slave won’t serve any read operations), we just leave the default value as it is. Then, press “Deploy” to start the database cluster deployment. You may monitor the deployment progress by looking at Activity > Jobs > Create Cluster:
Meanwhile, grab some coffee and the cluster deployment should be completed within 10~15 minutes.
Deploying Load Balancers and Virtual IP for PostgreSQL Servers
At this point, we already have a two-node PostgreSQL Replication Cluster running in a master-slave setup:

The next step is to deploy the load balancer tier for our database, which allows us to tie it up virtual IP address and provide single endpoint for the application. We will configure the HAProxy deployment options as the below:
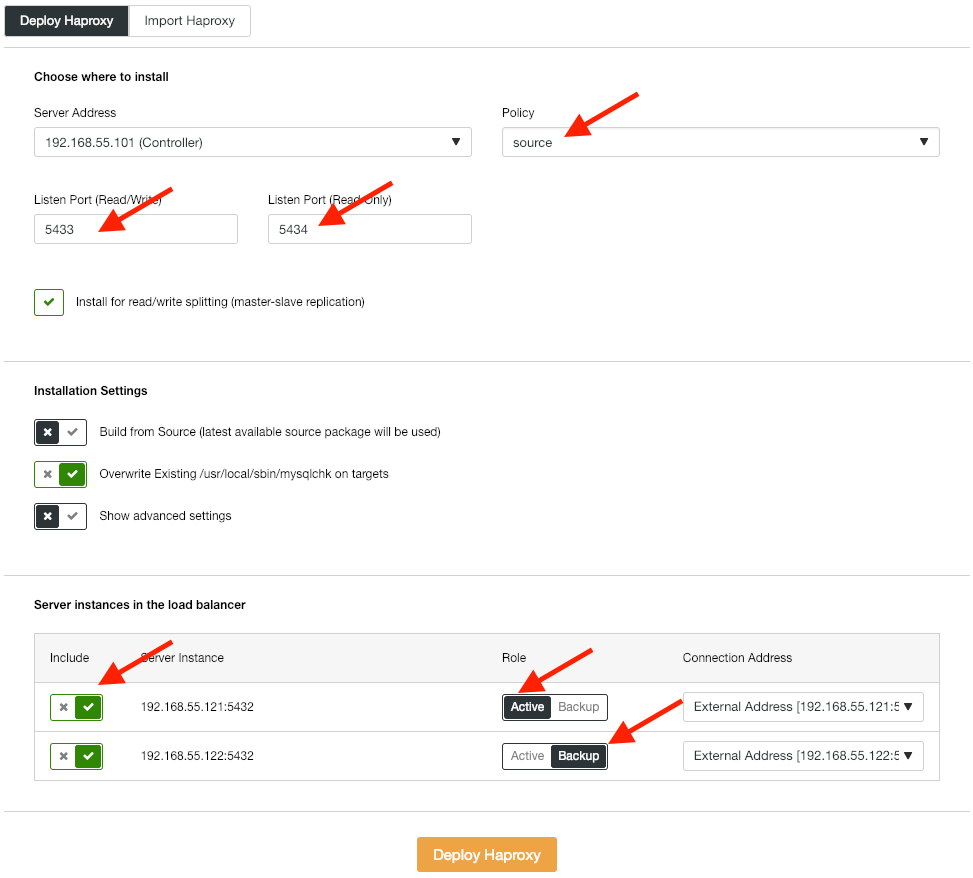
The application does not support read-write splitting natively so we will use active-passive method to achieve high availability. The best load balancing algorithm is the “source” policy, since we are only using one PostgreSQL node at a time.
Repeat the same step for the other load balancer, lb2. Change the “Server Address” to 192.168.55.102 instead. Here is what it looks like it after the deployment completes if you go under Nodes page:
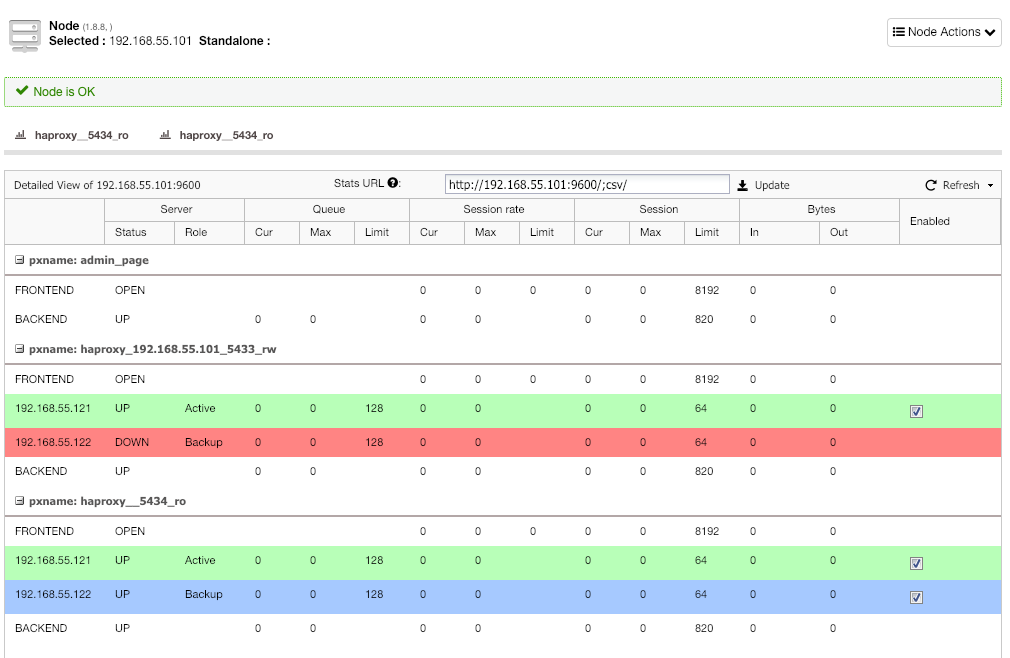
The red line on the first listener is expected where HAProxy shows postgresql2 (192.168.55.122) is down because the health check script returns the node is up but not a master. The second listener with blue line (haproxy_5434_ro) shows the node is UP but in “backup” state. This listener can be ignored though since the application does not support read-write splitting.
Next, we deploy Keepalived instances on top of these load balancers to tie them up with a single virtual IP address. Go to Manage -> Load Balancer -> Keepalived -> Deploy Keepalived and specify the first and second HAProxy instances, then the virtual IP address and network interface to listen to:
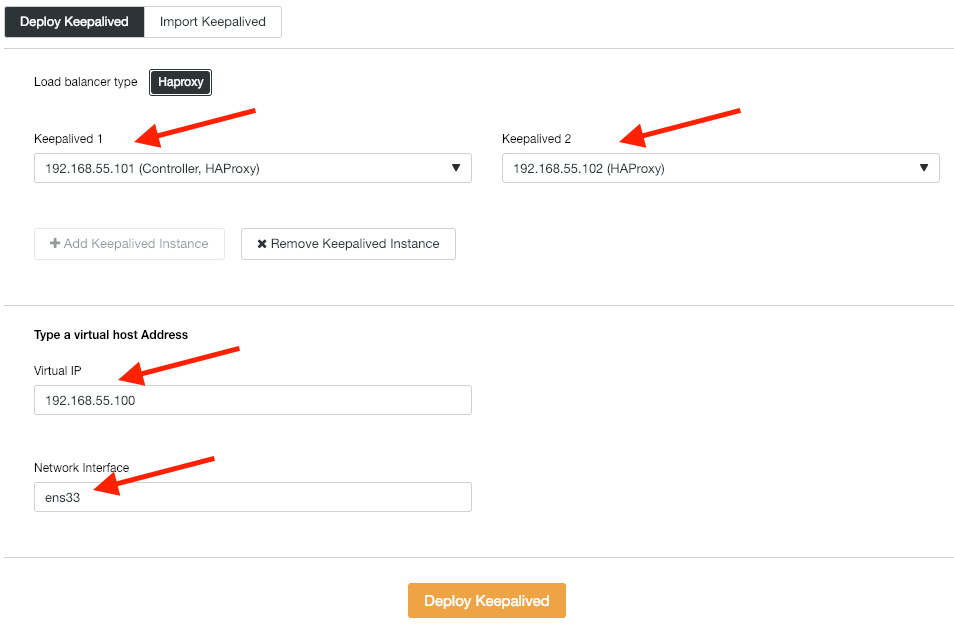
Click “Deploy Keepalived” to start the deployment. The PostgreSQL connection service is now load balanced to either of the database nodes and accessible via 192.168.55.100 port 5433.
Configuring iSCSI
The storage server (lb2) needs to export a disk through iSCSI so it can be mounted on both Odoo application servers (odoo1 and odoo2). iSCSI basically tells your kernel you have a SCSI disk, and it transports that access over IP. The “server” is called the “target” and the “client” that uses that iSCSI device is the “initiator”.
Firstly, install iSCSI target in lb2:
$ sudo apt install -y tgtEnable tgt on boot:
$ systemctl enable tgtIt is preferred to have a separate disk for file system clustering. Thus, we are going to use another disk mounted in lb2 (/dev/sdb) to be shared among application servers (odoo1 and odoo2). Firstly, create an iSCSI target using tgtadm tool:
$ sudo tgtadm --lld iscsi --op new --mode target --tid 1 -T iqn.2019-02.lb2:odcfs2Then, assign the block device /dev/sdb to logical unit number (LUN) 1 together with target ID 1:
$ sudo tgtadm --lld iscsi --op new --mode logicalunit --tid 1 --lun 1 -b /dev/sdbThen, allow the initiator nodes on the same network to access this target:
$ sudo tgtadm --lld iscsi --op bind --mode target --tid 1 --initiator-address 192.168.55.0/24Use tgt-admin tool to dump the iSCSI configuration lines and save it as a configuration file to make it persistent across restart:
$ sudo tgt-admin --dump > /etc/tgt/conf.d/shareddisk.confFinally, restart the iSCSI target service:
$ sudo systemctl restart tgt** The following steps should be performed on odoo1 and odoo2.
Install iSCSI initiator on the respective hosts:
$ sudo apt-get install -y open-iscsiSet the iSCSI initiator to automatically start:
$ sudo systemctl enable open-iscsiDiscover iSCSI targets that we have setup earlier:
$ sudo iscsiadm -m discovery -t sendtargets -p lb2
192.168.55.102:3260,1 iqn.2019-02.lb2:odcfs2If you see similar result as above, it means we can see and able to connect to the iSCSI target. Use the following command to connect to the iSCSI target on lb2:
$ sudo iscsiadm -m node --targetname iqn.2019-02.lb2:odcfs2 -p lb2 -l
Logging in to [iface: default, target: iqn.2019-02.lb2:odcfs2, portal: 192.168.55.102,3260] (multiple)
Login to [iface: default, target: iqn.2019-02.lb2:odcfs2, portal: 192.168.55.102,3260] successful.Make sure you can see the new hard disk (/dev/sdb) listed under /dev directory:
$ sudo ls -1 /dev/sd*
/dev/sda
/dev/sda1
/dev/sda2
/dev/sda3
/dev/sdbOur shared disk is now mounted on both application servers (odoo1 and odoo2).
Configuring OCFS2 for Odoo
** The following steps should be performed on odoo1 unless specified otherwise.
OCFS2 allows for file system to be mounted more than one place. Install OCFS2 tools on both odoo1 and odoo2 servers:
$ sudo apt install -y ocfs2-toolsCreate disk partition table for hard disk drive /dev/sdb:
$ sudo cfdisk /dev/sdbCreate a partition by using following sequences in the cfdisk wizard: New > Primary > accept Size > Write > yes > Quit.
Create an OCFS2 file system on /dev/sdb1:
$ sudo mkfs.ocfs2 -b 4K -C 128K -L "Odoo_Cluster" /dev/sdb1
mkfs.ocfs2 1.8.5
Cluster stack: classic o2cb
Label: Odoo_Cluster
Features: sparse extended-slotmap backup-super unwritten inline-data strict-journal-super xattr indexed-dirs refcount discontig-bg append-dio
Block size: 4096 (12 bits)
Cluster size: 131072 (17 bits)
Volume size: 21473656832 (163831 clusters) (5242592 blocks)
Cluster groups: 6 (tail covers 2551 clusters, rest cover 32256 clusters)
Extent allocator size: 4194304 (1 groups)
Journal size: 134217728
Node slots: 8
Creating bitmaps: done
Initializing superblock: done
Writing system files: done
Writing superblock: done
Writing backup superblock: 3 block(s)
Formatting Journals: done
Growing extent allocator: done
Formatting slot map: done
Formatting quota files: done
Writing lost+found: done
mkfs.ocfs2 successfulCreate a cluster configuration file at /etc/ocfs2/cluster.conf and define the node and cluster directives as below:
# /etc/ocfs2/cluster.conf
cluster:
node_count = 2
name = ocfs2
node:
ip_port = 7777
ip_address = 192.168.55.111
number = 1
name = odoo1
cluster = ocfs2
node:
ip_port = 7777
ip_address = 192.168.55.112
number = 2
name = odoo2
cluster = ocfs2Note that the attributes under the node or cluster clause need to be after a tab.
** The following steps should be performed on odoo1 and odoo2 unless specified otherwise.
Create the same configuration file (/etc/ocfs2/cluster.conf) on odoo2. This file should be the same across all nodes in the cluster, and changes made to this file must be propagated to the other nodes in the cluster.
Restart o2cb service to apply the changes we made in /etc/ocfs2/cluster.conf:
$ sudo systemctl restart o2cbCreate the Odoo files directory under /var/lib/odoo:
$ sudo mkdir -p /var/lib/odooGet the block ID for the /dev/sdb1 device. UUID is recommended in fstab if you use iSCSI device:
$ sudo blkid /dev/sdb1 | awk {'print $3'}
UUID="93a2b6c4-d800-4532-9a9b-2d2f2f1a726b"Use the UUID value when adding the following line into /etc/fstab:
UUID=93a2b6c4-d800-4532-9a9b-2d2f2f1a726b /var/lib/odoo ocfs2 defaults,_netdev 0 0Register the ocfs2 cluster and mount the filesystem from fstab:
$ sudo o2cb register-cluster ocfs2
$ sudo mount -aVerify with:
$ mount | grep odoo
/dev/sdb1 on /var/lib/odoo type ocfs2 (rw,relatime,_netdev,heartbeat=local,nointr,data=ordered,errors=remount-ro,atime_quantum=60,coherency=full,user_xattr,acl,_netdev)If you can see the above line on all application servers, we are a good to install Odoo.
Installing and Configuring Odoo 12
** The following steps should be performed on odoo1 and odoo2 unless specified otherwise.
Install Odoo 12 via package repository:
$ wget -O - https://nightly.odoo.com/odoo.key | sudo apt-key add -
$ echo "deb http://nightly.odoo.com/12.0/nightly/deb/ ./" | sudo tee -a /etc/apt/sources.list.d/odoo.list
$ sudo apt update && sudo apt install odooBy default, the above command will automatically install PostgreSQL server on the same host as part of Odoo dependencies. We probably want to stop it because we are not going to use the local server anyway:
$ sudo systemctl stop postgresql
$ sudo systemctl disable postgresqlOn postgresql1, create a database user called “odoo”:
$ sudo -i
$ su - postgres
$ createuser --createrole --createdb --pwprompt odooSpecify a password in the prompt. Then on both postgresql1 and postgresql2, add the following line inside pg_hba.conf to allow the application and load balancer nodes to connect. As in our case, it’s located at /etc/postgresql/11/main/pg_hba.conf:
host all all 192.168.55.0/24 md5Then reload the PostgreSQL server to load the changes:
$ su - postgres
$ /usr/lib/postgresql/11/bin/pg_ctl reload -D /var/lib/postgresql/11/main/Edit Odoo configuration file at /etc/odoo/odoo.conf and configure the admin_passwd, db_host and db_password parameters accordingly:
[options]
; This is the password that allows database operations:
admin_passwd = admins3cr3t
db_host = 192.168.55.100
db_port = 5433
db_user = odoo
db_password = odoopassword
;addons_path = /usr/lib/python3/dist-packages/odoo/addonsRestart Odoo on both servers to load the new changes:
$ sudo systemctl restart odooThe, open Odoo on one of the application servers via web browser. In this example, we connected to odoo1, thus the URL is http://192.168.55.111:8069/ and you should see the following initial page:
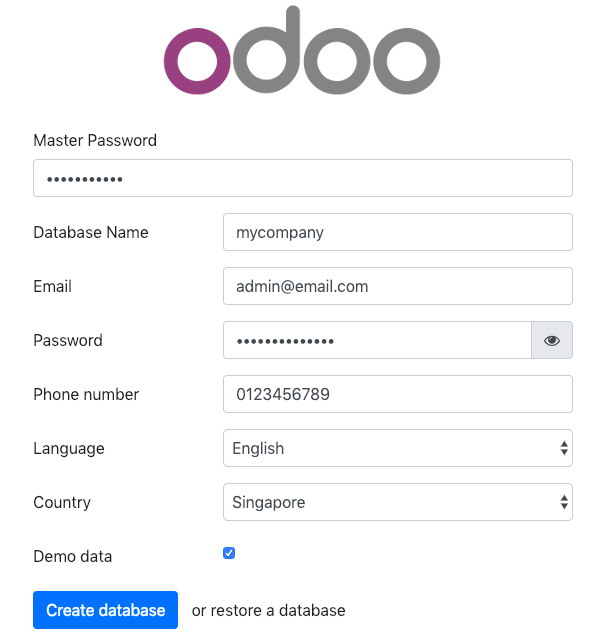
Specify the “Master Password” identical with the admin_passwd value defined in Odoo configuration file. Then fill up all the required information for the new company that going to use this platform.
Once done, wait for a moment until the initialization finishes. You will be redirected to the Odoo administration dashboard:

At this point, Odoo installation is complete and you can start configuring the business apps for this company. All the file changes made by this application server will be stored inside the clustered file system located at “/var/lib/odoo/.local” (which also mounted to another application server, odoo2), while changes to the database will be happening on the PostgreSQL master node.
Despite running on two different host, take note that Odoo application itself is not load-balanced in this writing. You may use the HAProxy instances deployed for the database cluster to achieve better availability just like the database service. Plus, the shared disk file system (OCFS2) used by both application servers is still exposed to single-point of failure, since they are all using the same iSCSI device on lb2 (imagine if lb2 is inaccessible).
Database Failover Operation
You might be wondering what would happen if the PostgreSQL master goes down. If it happens, ClusterControl will automatically promote the running slave to become a master, as shown in the screenshot below:
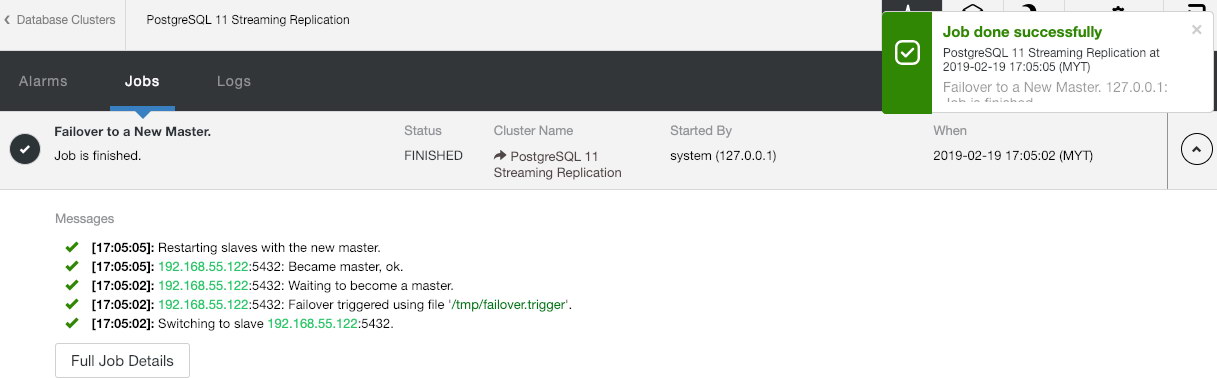
Nothing is required to be done from the end-user as the failover is performed automatically (after a 30-second grace period). After failover completes, the new topology will be reported by ClusterControl as:
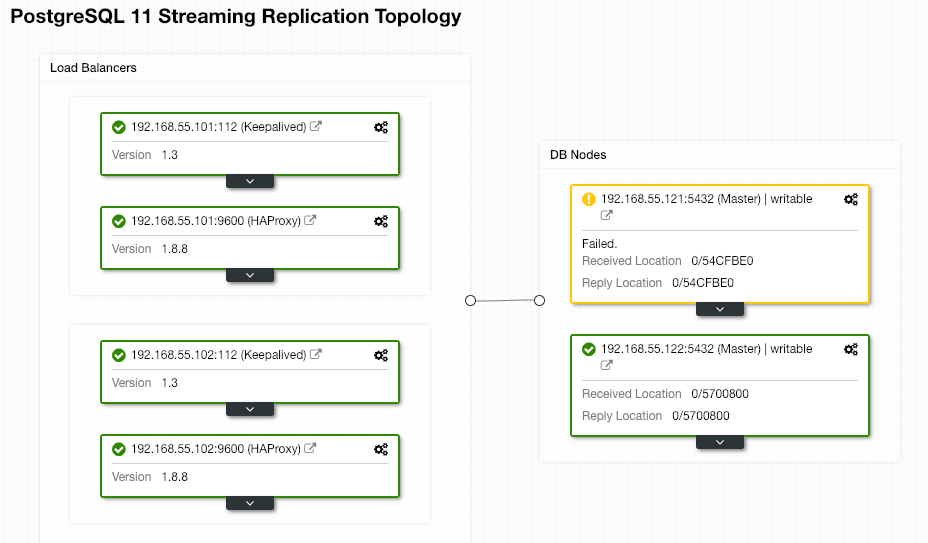
If the old master comes back up, the PostgreSQL service will be shut down automatically and the next thing user has to do is to resync the old master back from the new master by going to Node Actions > Rebuild Replication Slave:
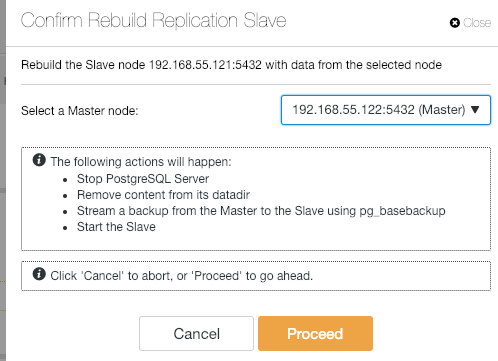
The old master will then become a slave to the new master after the syncing operation completes:
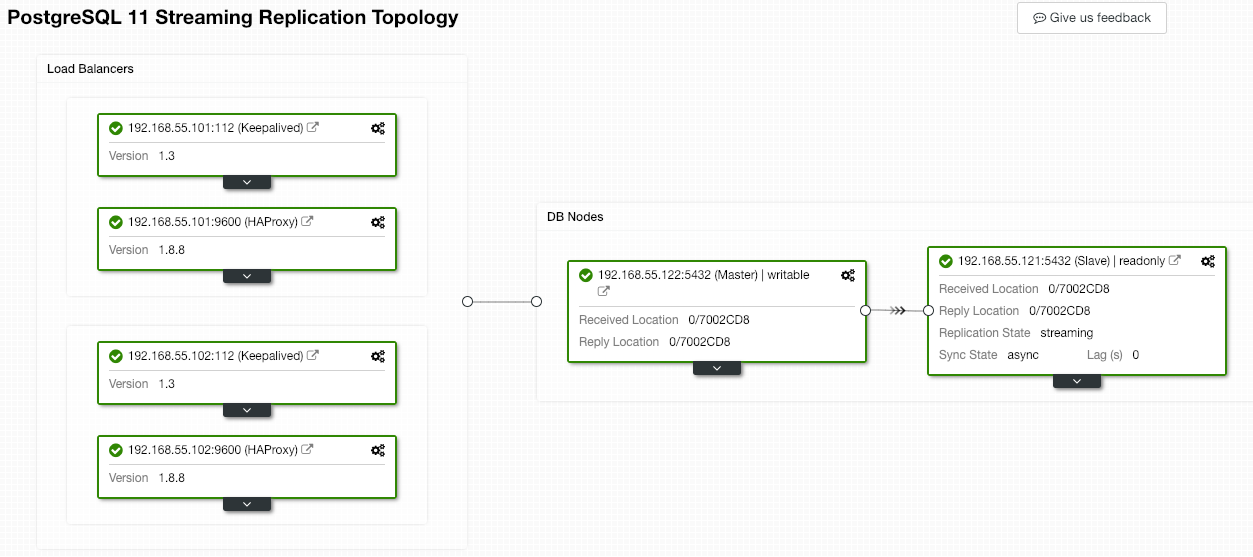
ClusterControl surely improves the database availability with its automatic recovery feature and resyncing a bad database node is simply just two clicks away. How simple is that after a catastrophic failure event?
That’s all for now folks. Happy clustering!



