blog
Cloud Vendor Deep-Dive: PostgreSQL on Google Cloud Platform (GCP)

Where to Start?
The best place I could find to start was none other than the official documentation. There is also a GCP Youtube channel for those who prefer multimedia. Once finding myself into the Cloud SQL documentation land I turned to Concepts where we are promised to “develop a deep understanding” of the product.
So let’s get started!
PostgreSQL Google Cloud Features
Google Cloud SQL for PostgreSQL offers all the standard features we’d expect from a managed solution: high availability with automatic failover, automatic backups, encryption at rest and in transit, advanced logging and monitoring, and of course a rich API to interact with all services.
And for a bit of history, PostgreSQL support started in March 2017, up to then the only supported database engine was MySQL.
Cloud SQL runs PostgreSQL on Google’s Second Generation computing platform. The full list of features is available here and also here. Reviewing the former it is apparent that there was never a First Generation platform for PostgreSQL.
Databases running on the Second Generation platform are expected to run at speeds 7x faster and benefit of 20x more storage capacity. The blog announcing the Second Generation platform goes into the details of running the sysbench test to compare Google Cloud SQL with the then main competitor AWS in both incarnations RDS, and Aurora. The results did surprise me as they show Cloud SQL performing better whereas the recent tests performed using the AWS Benchmark released about a year later concluded the opposite. That is around the same time PostgreSQL support was available. While I’m itching at the idea of running the benchmark myself, I’m guessing that there are two potential factors that could have influenced the results: Google’s sysbench benchmark used different parameters and AWS may have improved their products during that time.
GCP PostgreSQL Compatibility
As expected Google Cloud SQL for PostgreSQL is almost a drop-in replacement for the community version and supports all PL/pgSQL SQL procedural languages.
Some features are not available due to security reasons, for example SUPERUSER access. Other features were removed due to potential risks posed to product stability and performance. Lastly, some options and parameters cannot be changed, although requests to change that behavior can be made via the Cloud SQL Discussion Group.
Cloud SQL is also wire compatible with the PostgreSQL protocol.
When it comes to transaction isolation Cloud SQL follows the PostgreSQL default behavior, defaulting to Read Committed isolation level.
For some of the server configuration parameters, Cloud SQL implements different ranges for reasons unexplained in the documentation, still an important thing to remember.
Networking
There are multiple ways for connecting to the database, depending on whether the instance is on a private network or a public network (applications connecting from outside GCP). Common to both cases is the predefined VPC managed by Google where all Cloud SQL database instances reside.
Private IP
Clients connecting to a private IP address are routed via a peering connection between the VPCs hosting the client and respectively the database instance. Although not specific to PostgreSQL it is important to review the network requirements, in order to avoid connection issues. One gotcha: once enabled, the private IP capability cannot be removed.
Connecting from External Applications
Connections from applications hosted outside GCP, can, and should be encrypted. Additionally, in order to avoid the various attacks, client connections and application must install the provided client certificate. The procedure for generating and configuring the certificates it’s somewhat complicated, requiring custom tools to ensure that certificates are renewed periodically. That may be one of the reasons why Google offers the option of using the Cloud SQL Proxy.
Connecting Using Cloud SQL Proxy
The setup is fairly straightforward, which in fact, I’ve found to be the case for all instructions in the Google Cloud SQL documentation. On a related note, submitting documentation feedback is dead simple, and the screenshot feature was a first for me.
There are multiple ways to authorize proxy connections and I chose to configure a service account, just as outlined in the Cloud SQL Proxy documentation.
Once everything is in place it’s time to start the proxy:
~/usr/local/google $ ./cloud_sql_proxy -instances=omiday:us-west1:s9s201907141919=tcp:5432 -credential_file=omiday-427c34fce588.json
2019/07/14 21:22:43 failed to setup file descriptor limits: failed to set rlimit {&{8500 4096}} for max file descriptors: invalid argument
2019/07/14 21:22:43 using credential file for authentication; [email protected]
2019/07/14 21:22:43 Listening on 127.0.0.1:5432 for omiday:us-west1:s9s201907141919
2019/07/14 21:22:43 Ready for new connectionsTo connect to the remote instance we are now using the proxy by specifying localhost instead of the instance public IP address:
~ $ psql "user=postgres dbname=postgres password=postgres hostaddr=127.0.0.1"
Pager usage is off.
psql (11.4, server 9.6.11)
Type "help" for help.Note that there is no encryption since we are connecting locally and the proxy takes care of encrypting the traffic flowing into the cloud.
A common DBA task is viewing the connections to the database by querying pg_stat_activity. The documentation states that proxy connections will be displayed as cloudsqlproxy~1.2.3.4 so I wanted to verify that claim. I’ve opened two sessions as postgres, one via proxy and the other one from my home address, so the following query will do:
postgres@127:5432 postgres> select * from pg_stat_activity where usename = 'postgres';
-[ RECORD 1 ]----+-----------------------------------------------------------
datid | 12996
datname | postgres
pid | 924
usesysid | 16389
usename | postgres
application_name | psql
client_addr |
client_hostname |
client_port | -1
backend_start | 2019-07-15 04:25:37.614205+00
xact_start | 2019-07-15 04:28:43.477681+00
query_start | 2019-07-15 04:28:43.477681+00
state_change | 2019-07-15 04:28:43.477684+00
wait_event_type |
wait_event |
state | active
backend_xid |
backend_xmin | 8229
query | select * from pg_stat_activity where usename = 'postgres';
-[ RECORD 2 ]----+-----------------------------------------------------------
datid | 12996
datname | postgres
pid | 946
usesysid | 16389
usename | postgres
application_name | psql
client_addr |
client_hostname |
client_port | 60796
backend_start | 2019-07-15 04:27:50.378282+00
xact_start |
query_start |
state_change | 2019-07-15 04:27:50.45613+00
wait_event_type |
wait_event |
state | idle
backend_xid |
backend_xmin |
query |It appears that the proxy connections are instead identified as client_port == -1 and an empty client_addr. This can be additionally confirmed by comparing the timestamps for backend_start and proxy log below:
2019/07/14 21:25:37 New connection for "omiday:us-west1:s9s201907141919"PostgreSQL High Availability on Google Cloud
Google Cloud SQL for PostgreSQL ensures high availability using low level storage data synchronization by means of regional persistent disks. Failover is automatic, with a heartbeat check interval of one second, and a failover triggered after about 60 seconds.
Performance and Monitoring
The Performance section of the documentation points out general cloud rules of thumb: keep the database (both writer and read replicas) close to the application, and vertically scale the instance. What stands out is the recommendation to provisioning an instance with at least 60 GB of RAM when performance is important.
Stackdriver provides monitoring and logging, as well access to PostgreSQL logs:
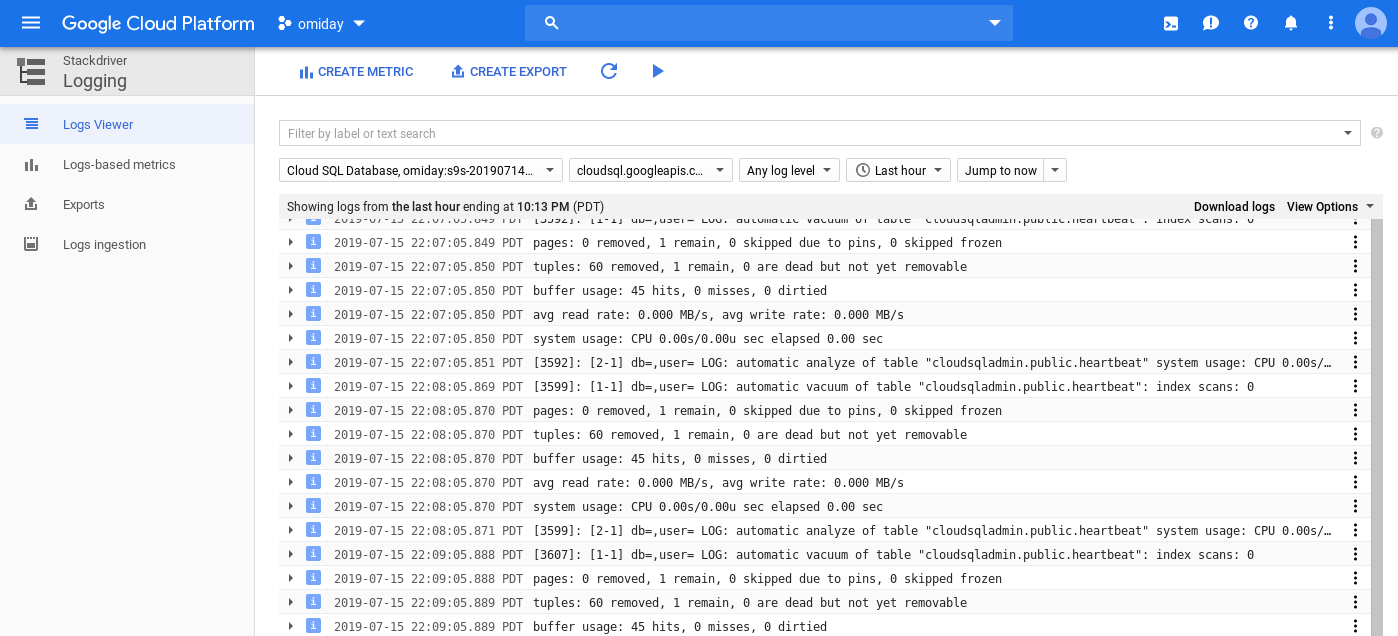
Access Control
This is implemented at project, instance and database level.
Project Access Control
Project access control is the cloud specific access control — it uses the concept of IAM roles in order to allow project members (users, groups, or service accounts) access to various Cloud SQL resources. The list of roles is somewhat self-explanatory, for a detailed description of each role and associated permissions refer to APIs Explorer, or Cloud SQL Admin API for one of the supported programming languages.
To demonstrate how IAM roles work let’s create a read-only (viewer) service account:
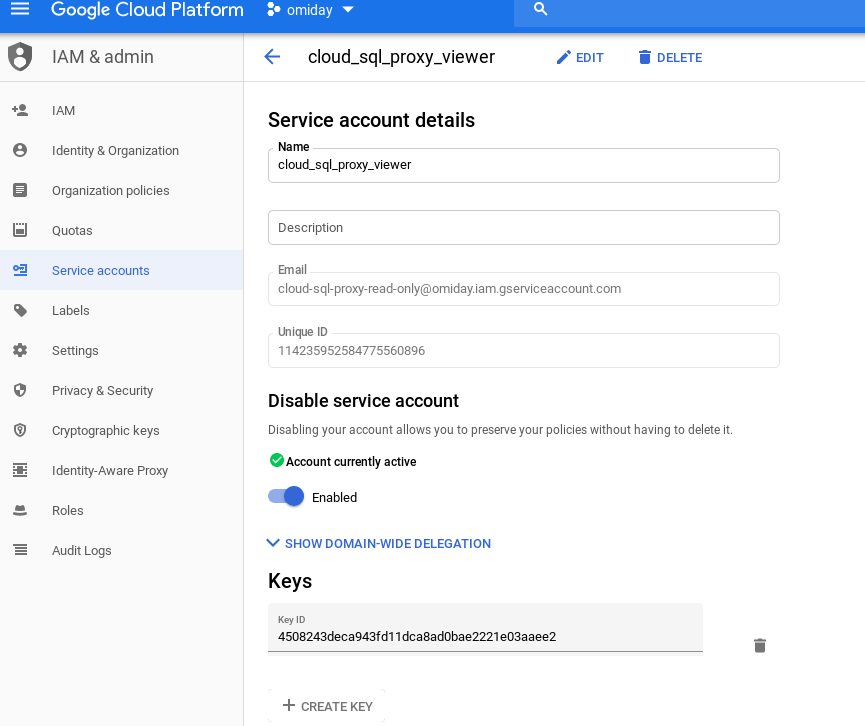
Start a new proxy instance on port 5433 using the service account associated with the viewer role:
~/usr/local/google $ ./cloud_sql_proxy -instances=omiday:us-west1:s9s201907141919=tcp:5433 -credential_file=omiday-4508243deca9.json
2019/07/14 21:49:56 failed to setup file descriptor limits: failed to set rlimit {&{8500 4096}} for max file descriptors: invalid argument
2019/07/14 21:49:56 using credential file for authentication; [email protected]
2019/07/14 21:49:56 Listening on 127.0.0.1:5433 for omiday:us-west1:s9s201907141919
2019/07/14 21:49:56 Ready for new connectionsOpen a psql connection to 127.0.0.1:5433:
~ $ psql "user=postgres dbname=postgres password=postgres hostaddr=127.0.0.1 port=5433"The command exits with:
psql: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.Oops! Let’s check the proxy logs:
2019/07/14 21:50:33 New connection for "omiday:us-west1:s9s201907141919"
2019/07/14 21:50:33 couldn't connect to "omiday:us-west1:s9s201907141919": ensure that the account has access to "omiday:us-west1:s9s201907141919" (and make sure there's no typo in that name). Error during createEphemeral for omiday:us-west1:s9s201907141919: googleapi: Error 403: The client is not authorized to make this request., notAuthorizedInstance Access Control
Instance-level access is dependent on the connection source:

The combination of authorization methods replaces the ubiquitous pg_hba.conf.
Backup and Recovery
By default automated backups are enabled:
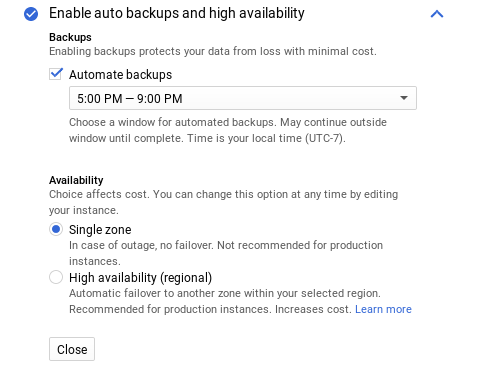
While backups do not affect database read and write operations they do impact the performance and therefore it is recommended that backups be scheduled during periods of lower activity.
For redundancy, backups can be stored in two regions (additional charges apply) with the option of selecting custom locations.
In order to save on storage space, use compression. .gz compressed files are transparently restored.
Cloud SQL also supports instance cloning. For the smallest dataset the operation took about 3 minutes:
Cloning start time 10:07:10:
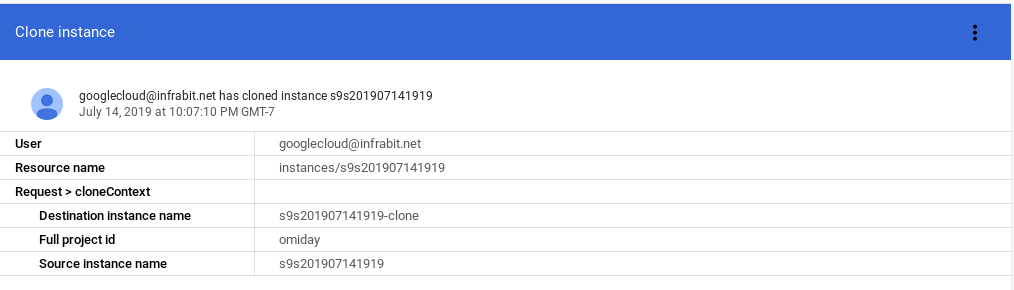
The PostgreSQL logs show that PostgreSQL became available on the cloned instance at 10:10:47:
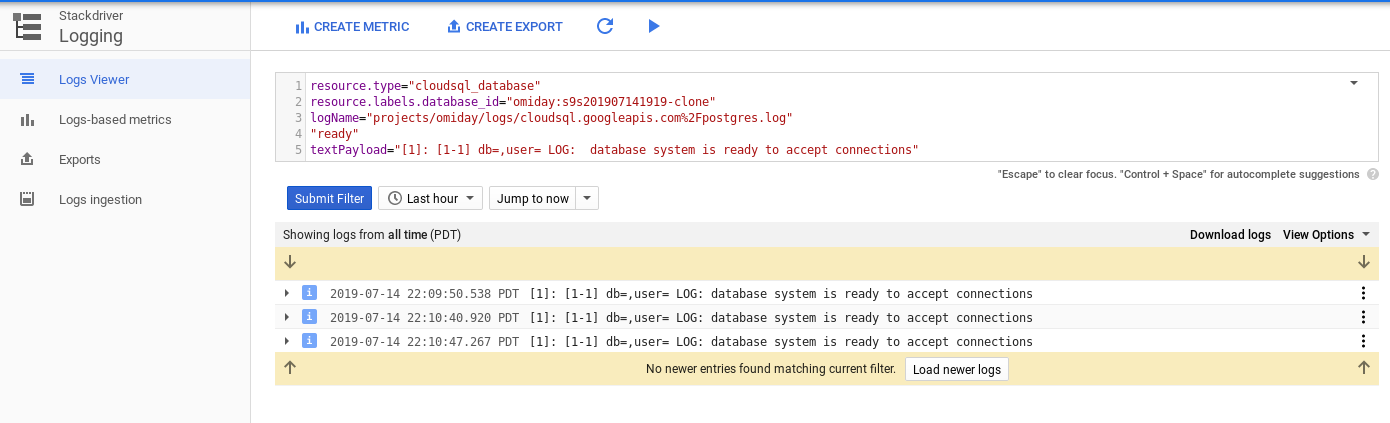
That is still an easier way than backup and restore, for creating a copy of an instance for testing, development or troubleshooting purposes.
Google Cloud Best Practices for PostgreSQL
- Configure an activation policy for instances that are not required to be running 24/7.
- Place the database instance in the same zone, or region, with the compute engine instances and App Engine applications in order to avoid network latency.
- Create the database instance in the same zone as the Compute Engine. If using any other connection type accept the default zone.
- Users created using Cloud SQL are by default cloud superusers. Use PostgreSQL ALTER ROLE to modify their permissions.
- Use the latest Cloud SQL Proxy version.
- Instance names should include a timestamp in order to be able to reuse the name when deleting and recreating instances.
- pg_dump defaults to including large objects. If the database contains BLOB-s perform the dump during periods of low activity to prevent the instance from becoming unresponsive.
- Use gcloud sql connect to quickly connect from an external client without the need to whitelist the client IP address.
- Subscribe to announce group in order to receive notifications on product updates and alerts such as issues when creating instances:
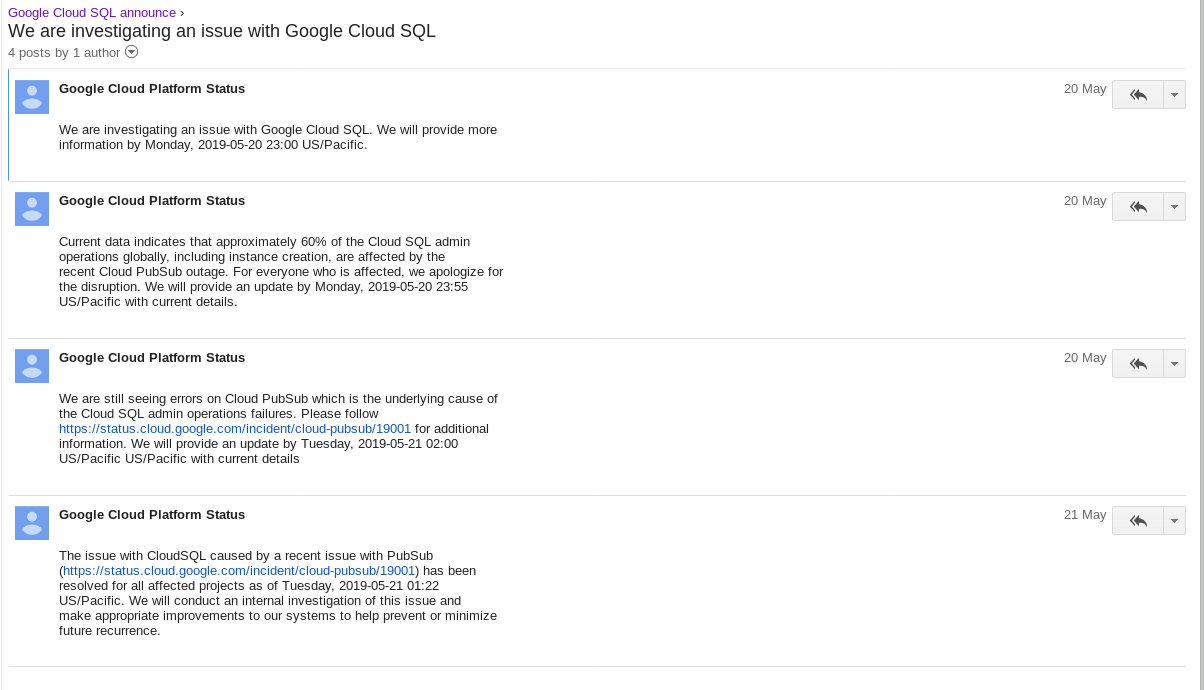
- Ensure that applications implement database connection management techniques.
- Instances stopped for more than 90 days will be deleted unless they are not in a suspended state.
- Perform a manual failover in order to test application behavior and downtime length.
- Use the default engine version.
- Storage space for instances configured to automatically increase the storage, will grow in increments of 25 GB. As storage space cannot be reclaimed set an increase limit to the estimated size of the database over the next budget cycle, and monitor runaway queries,
- Use the “earlier” maintenance timing for test instances:
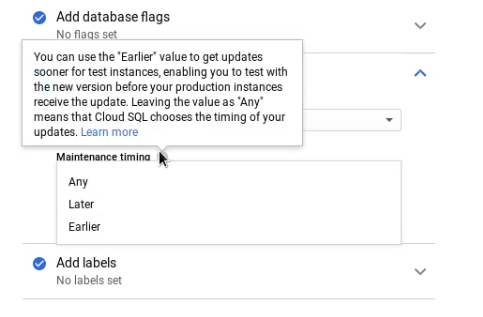
- Applications should use lived connections and exponential backoff in order to quickly recover after an instance restart.
- Application relying on read replicas should consider using 3 replicas in order to avoid issues caused by failing regional persistent disks leading to both replicas becoming unavailable.
- Configure read replicas in order to improve read performance.
- Instance restart is required when updating the list of IP addresses allowed to access a public instance in order to disconnect existing connections.
- Review the StackOverflow Cloud SQL dedicated group for additional information.
Launch Checklist for Cloud SQL
The checklist section in the documentation provides an overview of recommended activities when setting up a production ready Cloud SQL for PostgreSQL instance. In particular, applications must be designed to handle Cloud SQL restarts. Also, while there are no queries per second limits there are connection limits.
PostgreSQL GCP Extensions Support
Cloud SQL supports most of the PostgreSQL extensions. As of this writing out of 52 community extensions there are 22 unsupported extensions and 2 unsupported PostGIS extensions.
postgis_raster
postgis_sfcgalFor PostgreSQL extensions we can either review the PostgreSQL contrib repository, or better, diff the output of pg_available_extensions:
Upstream:
~ $ psql -U postgres -p 54396
Pager usage is off.
psql (11.4, server 9.6.14)
Type "help" for help.
postgres@[local]:54396 postgres# select * from pg_available_extensions order by name;
name | default_version | installed_version | comment
--------------------+-----------------+-------------------+----------------------------------------------------------------------
adminpack | 1.1 | | administrative functions for PostgreSQL
autoinc | 1.0 | | functions for autoincrementing fields
bloom | 1.0 | | bloom access method - signature file based index
btree_gin | 1.0 | | support for indexing common datatypes in GIN
btree_gist | 1.2 | | support for indexing common datatypes in GiST
chkpass | 1.0 | | data type for auto-encrypted passwords
citext | 1.3 | | data type for case-insensitive character strings
cube | 1.2 | | data type for multidimensional cubes
dblink | 1.2 | | connect to other PostgreSQL databases from within a database
dict_int | 1.0 | | text search dictionary template for integers
dict_xsyn | 1.0 | | text search dictionary template for extended synonym processing
earthdistance | 1.1 | | calculate great-circle distances on the surface of the Earth
file_fdw | 1.0 | | foreign-data wrapper for flat file access
fuzzystrmatch | 1.1 | | determine similarities and distance between strings
hstore | 1.4 | | data type for storing sets of (key, value) pairs
hstore_plperl | 1.0 | | transform between hstore and plperl
hstore_plperlu | 1.0 | | transform between hstore and plperlu
hstore_plpython2u | 1.0 | | transform between hstore and plpython2u
hstore_plpythonu | 1.0 | | transform between hstore and plpythonu
insert_username | 1.0 | | functions for tracking who changed a table
intagg | 1.1 | | integer aggregator and enumerator (obsolete)
intarray | 1.2 | | functions, operators, and index support for 1-D arrays of integers
isn | 1.1 | | data types for international product numbering standards
lo | 1.1 | | Large Object maintenance
ltree | 1.1 | | data type for hierarchical tree-like structures
ltree_plpython2u | 1.0 | | transform between ltree and plpython2u
ltree_plpythonu | 1.0 | | transform between ltree and plpythonu
moddatetime | 1.0 | | functions for tracking last modification time
pageinspect | 1.5 | | inspect the contents of database pages at a low level
pg_buffercache | 1.2 | | examine the shared buffer cache
pg_freespacemap | 1.1 | | examine the free space map (FSM)
pg_prewarm | 1.1 | | prewarm relation data
pg_stat_statements | 1.4 | | track execution statistics of all SQL statements executed
pg_trgm | 1.3 | | text similarity measurement and index searching based on trigrams
pg_visibility | 1.1 | | examine the visibility map (VM) and page-level visibility info
pgcrypto | 1.3 | | cryptographic functions
pgrowlocks | 1.2 | | show row-level locking information
pgstattuple | 1.4 | | show tuple-level statistics
plpgsql | 1.0 | 1.0 | PL/pgSQL procedural language
postgres_fdw | 1.0 | | foreign-data wrapper for remote PostgreSQL servers
refint | 1.0 | | functions for implementing referential integrity (obsolete)
seg | 1.1 | | data type for representing line segments or floating-point intervals
sslinfo | 1.2 | | information about SSL certificates
tablefunc | 1.0 | | functions that manipulate whole tables, including crosstab
tcn | 1.0 | | Triggered change notifications
timetravel | 1.0 | | functions for implementing time travel
tsearch2 | 1.0 | | compatibility package for pre-8.3 text search functions
tsm_system_rows | 1.0 | | TABLESAMPLE method which accepts number of rows as a limit
tsm_system_time | 1.0 | | TABLESAMPLE method which accepts time in milliseconds as a limit
unaccent | 1.1 | | text search dictionary that removes accents
uuid-ossp | 1.1 | | generate universally unique identifiers (UUIDs)
xml2 | 1.1 | | XPath querying and XSLTCloud SQL:
postgres@127:5432 postgres> select * from pg_available_extensions where name !~ '^postgis' order by name;
name | default_version | installed_version | comment
--------------------+-----------------+-------------------+--------------------------------------------------------------------
bloom | 1.0 | | bloom access method - signature file based index
btree_gin | 1.0 | | support for indexing common datatypes in GIN
btree_gist | 1.2 | | support for indexing common datatypes in GiST
chkpass | 1.0 | | data type for auto-encrypted passwords
citext | 1.3 | | data type for case-insensitive character strings
cube | 1.2 | | data type for multidimensional cubes
dict_int | 1.0 | | text search dictionary template for integers
dict_xsyn | 1.0 | | text search dictionary template for extended synonym processing
earthdistance | 1.1 | | calculate great-circle distances on the surface of the Earth
fuzzystrmatch | 1.1 | | determine similarities and distance between strings
hstore | 1.4 | | data type for storing sets of (key, value) pairs
intagg | 1.1 | | integer aggregator and enumerator (obsolete)
intarray | 1.2 | | functions, operators, and index support for 1-D arrays of integers
isn | 1.1 | | data types for international product numbering standards
lo | 1.1 | | Large Object maintenance
ltree | 1.1 | | data type for hierarchical tree-like structures
pg_buffercache | 1.2 | | examine the shared buffer cache
pg_prewarm | 1.1 | | prewarm relation data
pg_stat_statements | 1.4 | | track execution statistics of all SQL statements executed
pg_trgm | 1.3 | | text similarity measurement and index searching based on trigrams
pgcrypto | 1.3 | | cryptographic functions
pgrowlocks | 1.2 | | show row-level locking information
pgstattuple | 1.4 | | show tuple-level statistics
plpgsql | 1.0 | 1.0 | PL/pgSQL procedural language
sslinfo | 1.2 | | information about SSL certificates
tablefunc | 1.0 | | functions that manipulate whole tables, including crosstab
tsm_system_rows | 1.0 | | TABLESAMPLE method which accepts number of rows as a limit
tsm_system_time | 1.0 | | TABLESAMPLE method which accepts time in milliseconds as a limit
unaccent | 1.1 | | text search dictionary that removes accents
uuid-ossp | 1.1 | | generate universally unique identifiers (UUIDs)Unsupported extensions in Cloud SQL:
adminpack 1.1 administrative functions for PostgreSQL
autoinc 1.0 functions for autoincrementing fields
dblink 1.2 connect to other PostgreSQL databases from within a database
file_fdw 1.0 foreign-data wrapper for flat file access
hstore_plperl 1.0 transform between hstore and plperl
hstore_plperlu 1.0 transform between hstore and plperlu
hstore_plpython2u 1.0 transform between hstore and plpython2u
hstore_plpythonu 1.0 transform between hstore and plpythonu
insert_username 1.0 functions for tracking who changed a table
ltree_plpython2u 1.0 transform between ltree and plpython2u
ltree_plpythonu 1.0 transform between ltree and plpythonu
moddatetime 1.0 functions for tracking last modification time
pageinspect 1.5 inspect the contents of database pages at a low level
pg_freespacemap 1.1 examine the free space map (FSM)
pg_visibility 1.1 examine the visibility map (VM) and page-level visibility info
postgres_fdw 1.0 foreign-data wrapper for remote PostgreSQL servers
refint 1.0 functions for implementing referential integrity (obsolete)
seg 1.1 data type for representing line segments or floating-point intervals
tcn 1.0 Triggered change notifications
timetravel 1.0 functions for implementing time travel
tsearch2 1.0 compatibility package for pre-8.3 text search functions
xml2 1.1 XPath querying and XSLTLogging
Operations performed within Cloud SQL are logged under the Activity tab along with all the details. Example from creating an instance, showing all instance details:
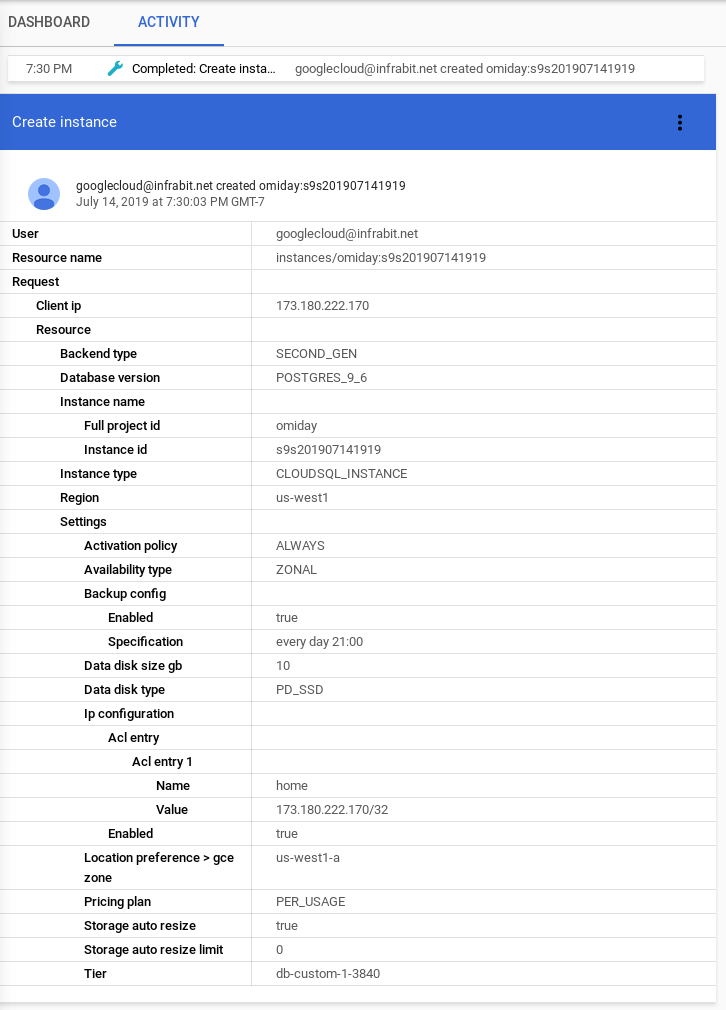
PostgreSQL Migration to GCP
In order to provide migration of on-premises PostgreSQL installations, Google takes advantage of pgBouncer.
Note that there is no GCP Console wizard for PostgreSQL migrations.
DBA Beware!
High Availability and Replication
A master node cannot failover to a read replica. The same section outlines other important aspects of read replicas:
- can be taken offline at any time for patching
- do not follow the master node in another zone following a failover — since the replication is synchronous this can affect the replication lag
- there is no load balancing between replicas, in other words, no single endpoint applications can be pointed to
- replica instance size must be at least the size of the master node
- no cross-region replication
- replicas cannot be backed up
- all replicas must be deleted before a master instance can be restored from backup or deleted
- cascading replication is not available
Users
By default, the “cloud superuser” is postgres which is a member of the cloudsqlsuperuser role. In turn, cloudsqlsuperuser inherits the default PostgreSQL roles:
postgres@35:5432 postgres> du+ postgres
List of roles
Role name | Attributes | Member of | Description
-----------+------------------------+---------------------+-------------
postgres | Create role, Create DB | {cloudsqlsuperuser} |
postgres@35:5432 postgres> du+ cloudsqlsuperuser
List of roles
Role name | Attributes | Member of | Description
-------------------+------------------------+--------------+-------------
cloudsqlsuperuser | Create role, Create DB | {pg_monitor} |Note that the roles SUPERUSER and REPLICATION are not available.
Backup and Recovery
Backups cannot be exported.
Backups cannot be used for upgrading an instance i.e. restoring into a different PostgreSQL engine.
Features such as PITR, Logical Replication, and JIT Compilation are not available. Feature requests can be filed in the Google’s Issue Tracker.
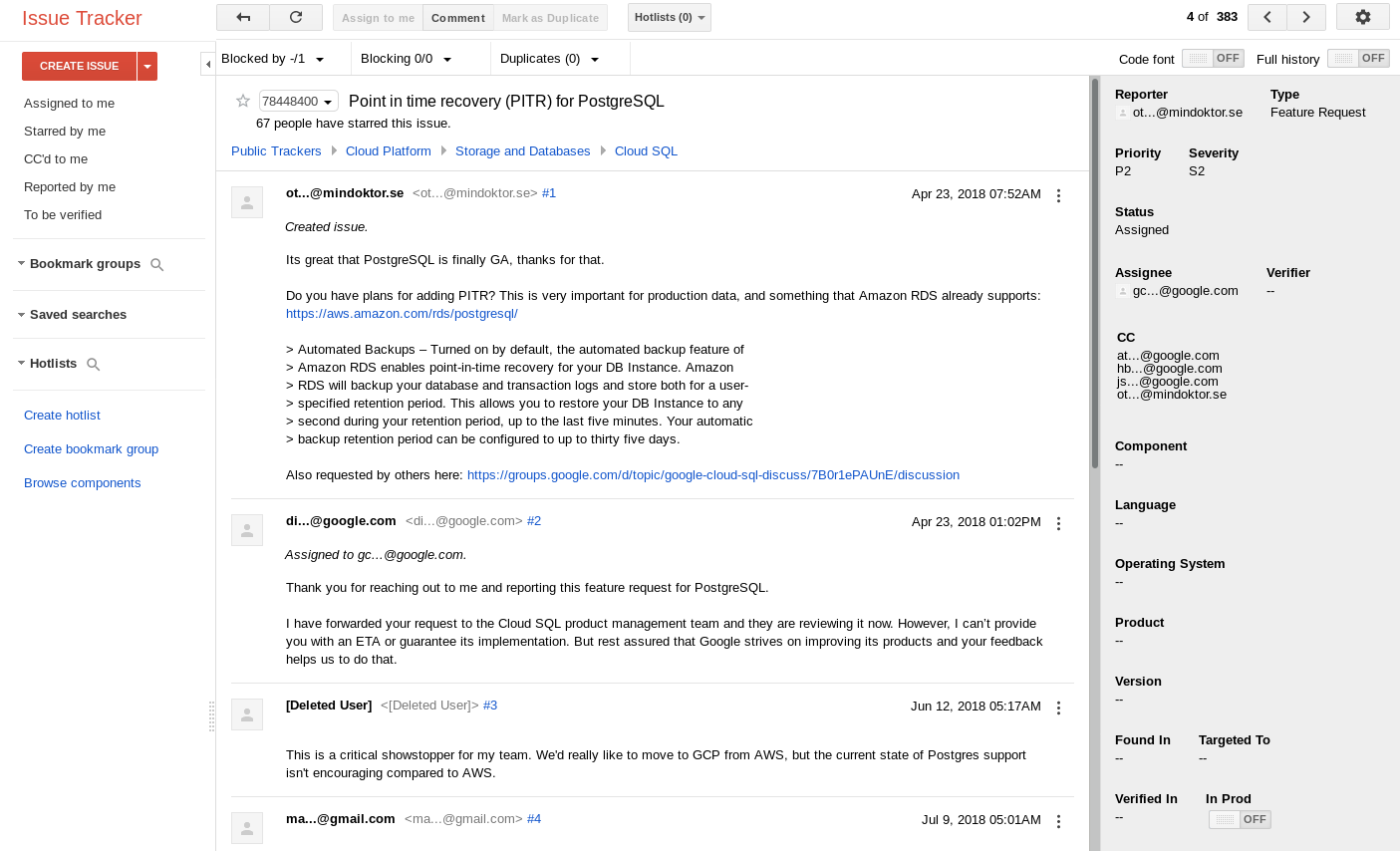
Encryption
At instance creation SSL/TLS is enabled but not enforced:
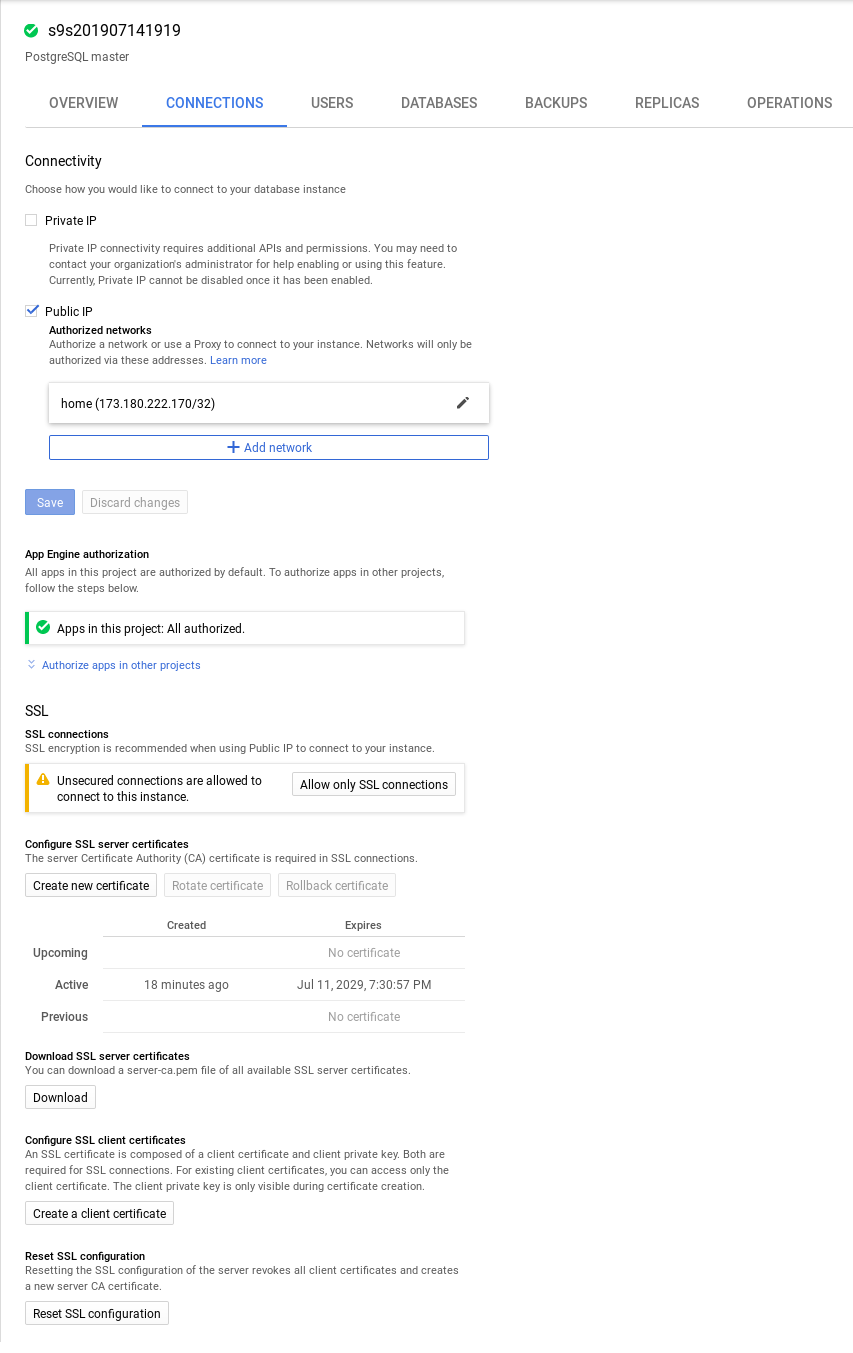
In this mode encryption can be requested, however certificate validation is not available.
~ $ psql "sslmode=verify-ca user=postgres dbname=postgres password=postgres hostaddr=35.233.149.65"
psql: root certificate file "/home/lelu/.postgresql/root.crt" does not exist
Either provide the file or change sslmode to disable server certificate verification.
~ $ psql "sslmode=require user=postgres dbname=postgres password=postgres hostaddr=35.233.149.65"
Pager usage is off.
psql (11.4, server 9.6.11)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES128-GCM-SHA256, bits: 128, compression: off)
Type "help" for help.Attempting to connect using psql to an SSL enforced instance will return a self-explanatory error:
~ $ psql "sslmode=require user=postgres dbname=postgres password=postgres hostaddr=35.233.149.65"
psql: FATAL: connection requires a valid client certificateStorage
- Storage can be increased after instance creation but never decreased so watch out for costs associated with the growing storage space, or configure the increase limit.
- Storage is limited to 30 TB.
CPU
Instances can be created with less than one core, however, the option isn’t available in the Cloud SQL Console as the instance must be created by specifying one of the sample machine types, in this case –tier:
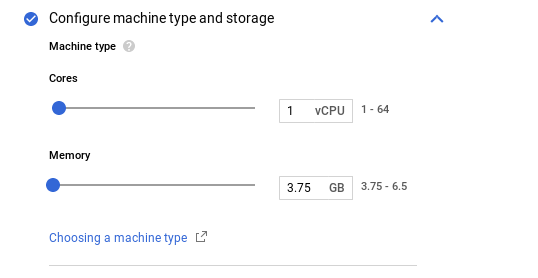
Example of creating a shared-code instance using gcloud inside Cloud Shell:

The number of CPUs is limited to 64, a relatively low limit for large installations, considering that back when 9.2 was benchmarked high-end servers started at 32 cores.
Instance Locations
Multi-regional location is only available for backups.
Access via Public IP
By default, the GCP Console Wizard enables only public IP address access, however, access is denied until the client’s network is configured:
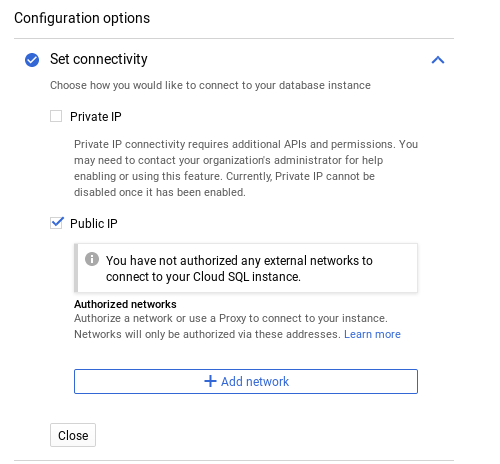
Maintenance
Updates may exceed the maintenance window and read replicas are updated at any time.
The documentation doesn’t specify how long the maintenance window duration is. The information is provided when creating the instance:
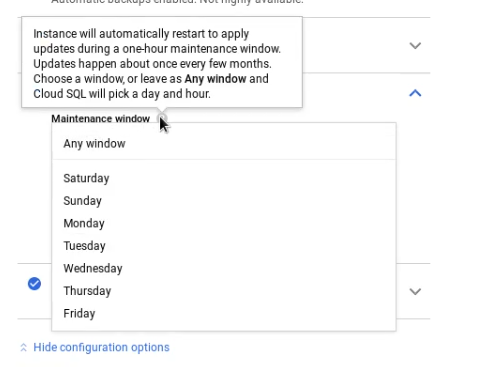
Changes to CPU count, memory size, or the zone where the instance is located requires the database to be offline for several minutes.
Users
Cloud SQL uses the terms “role” and “user” interchangebly.
High Availability
Cost in a highly available configuration is double the standalone instance, and that includes storage.
Automatic failover is initiated after about 60 seconds following the primary node becoming unavailable. According to Oracle MAA report, this translates into $5,800 per minute loss. Considering that it takes 2 to 3 minutes until the applications can reconnect the outage doubles to triples. Additionally, the 60 seconds heartbeat interval doesn’t appear to be a configurable option.
Replication
Read replicas cannot be accessed using a single endpoint, each receiving a new IP address:
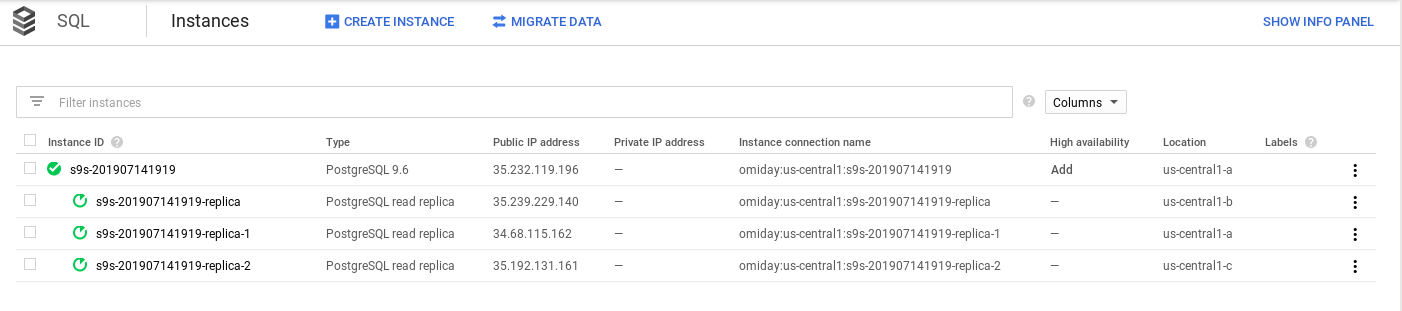
Regional persistent disks provide data redundancy at the cost of write performance.
Cloud SQL will not failover to read replicas, hence readers cannot be considered a high availability solution
External replicas and external masters are currently not supported.
Connecting to Instance
Google does not automatically renew the instance SSL certificates, however, both the initiation and rotation procedures can be automated.
If the application is built on the App Engine platform additional limits apply, such as 60 seconds for a database request to complete, 60 concurrent connections for PHP applications. The “App Engine Limits” section in Quotas and limits provides more details:

IP addresses in the range 172.17.0.0/16 are reserved.
Administration
Once started, operations cannot be canceled. Runaway queries can still be stopped by using the pg_terminate_backend and pg_cancel_backend PostgreSQL built-in functions.
A short demonstration using two psql sessions and starting a long running query in the second session:
postgres@35:5432 postgres> select now(); select pg_sleep(3600); select now();
now
-------------------------------
2019-07-16 02:08:18.739177+00
(1 row)In the first session, cancel the long running query:
postgres@35:5432 postgres> select pid, client_addr, client_port, query, backend_start from pg_stat_activity where usename = 'postgres';
-[ RECORD 1 ]-+-------------------------------------------------------------------------------------------------------------
pid | 2182
client_addr | 173.180.222.170
client_port | 56208
query | select pid, client_addr, client_port, query, backend_start from pg_stat_activity where usename = 'postgres';
backend_start | 2019-07-16 01:57:34.99011+00
-[ RECORD 2 ]-+-------------------------------------------------------------------------------------------------------------
pid | 2263
client_addr | 173.180.222.170
client_port | 56276
query | select pg_sleep(3600);
backend_start | 2019-07-16 02:07:43.860829+00
postgres@35:5432 postgres> select pg_cancel_backend(2263); select now();
-[ RECORD 1 ]-----+--
pg_cancel_backend | t
-[ RECORD 1 ]----------------------
now | 2019-07-16 02:09:09.600399+00Comparing the timestamps between the two sessions:
ERROR: canceling statement due to user request
now
-------------------------------
2019-07-16 02:09:09.602573+00
(1 row)It’s a match!
While restarting an instance is a recommended method when attempting to resolve database instance issues, avoid restarting before the first restart completed.
Data Import and Export
CSV import/export is limited to one database.
Exporting data as an SQL dump that can be imported later, requires a custom pg_dump command.
To quote from the documentation:
pg_dump -U [USERNAME] --format=plain --no-owner --no-acl [DATABASE_NAME]
| sed -E 's/(DROP|CREATE|COMMENT ON) EXTENSION/-- 1 EXTENSION/g' > [SQL_FILE].sqlPricing
|
Charge Type |
Instance ON |
Instance OFF |
|
Yes |
Yes |
|
|
No |
Yes |
Troubleshooting
Logging
All actions are recorded and can be viewed under the Activity tab.
Resources
Review the Diagnosing Issues with Cloud SQL instances and Known issues sections in the documentation.
Conclusion
Although missing some important features the PostgreSQL DBA is used to, namely PITR and Logical Replication, Google Cloud SQL provides out of the box high-availability, replication, encryption, and automatic storage increase, just to name a few, making manage PostgreSQL an appealing solution for organizations looking to quickly deploy their PostgreSQL workloads or even migrating from Oracle.
Developers can take advantage of cheap instances such as shared CPU (less than one CPU).
Google approaches the PostgreSQL engine adoption in a conservative manner, the stable offering lagging behind current upstream by 3 versions.
Just as with any solution provider consider getting support which can come in handy during edge scenarios such as when instances are suspended.
For professional support, Google maintains a list of partners which currently includes one of the PostgreSQL professional services , namely EDB.



