blog
Failover & Failback on Amazon RDS

Previously we posted a blog discussing Achieving MySQL Failover & Failback on Google Cloud Platform (GCP) and in this blog we’ll look at how it’s rival, Amazon Relational Database Service (RDS), handles failover. We will also look at how you can perform a failback of your former master node, bringing it back to its original order as a master.
When comparing the tech-giant public clouds which supports managed relational database services, Amazon is the only one that offers an alternative option (along with MySQL/MariaDB, PostgreSQL, Oracle, and SQL Server) to deliver its own kind of database management called Amazon Aurora. For those not familiar with Aurora, it is a fully managed relational database engine that’s compatible with MySQL and PostgreSQL. Aurora is part of the managed database service Amazon RDS, a web service that makes it easy to set up, operate, and scale a relational database in the cloud.
Why You Would Need to Failover or Failback?
Designing a large system that is fault-tolerant, highly-available, with no Single-Point-Of-Failure (SPOF) requires proper testing to determine how it would react when things go wrong.
If you are concerned about how your system would perform when responding to your system’s Fault Detection, Isolation, and Recovery (FDIR), then failover and failback should be of high importance.
Database Failover in Amazon RDS
Failover occurs automatically (as manual failover is called switchover). As discussed in a previous blog the need to failover occurs once your current database master experiences a network failure or abnormal termination of the host system. Failover switches it to a stable state of redundancy or to a standby computer server, system, hardware component, or network.
In Amazon RDS you don’t need to do this, nor are you required to monitor it yourself, as RDS is a managed database service (meaning Amazon handles the job for you). This service manages things such as hardware issues, backup and recovery, software updates, storage upgrades, and even software patching. We’ll talk about that later in this blog.
Database Failback in Amazon RDS
In the previous blog we also covered why you would need to failback. In a typical replicated environment the master must be powerful enough to carry a huge load, especially when the workload requirement is high. Your master setup requires adequate hardware specs to ensure it can process writes, generate replication events, process critical reads, etc, in a stable way. When failover is required during disaster recovery (or for maintenance) it’s not uncommon that when promoting a new master you might use inferior hardware. This situation might be okay temporarily, but in the long run, the designated master must be brought back to lead the replication after it is deemed healthy (or maintenance is completed).
Contrary to failover, failback operations usually happen in a controlled environment by using switchover. It is rarely done when in panic-mode. This approach provides your engineers enough time to plan carefully and rehearse the exercise to ensure a smooth transition. Its main objective is to simply bring back the good, old master to the latest state and restore the replication setup to its original topology. Since we are dealing with Amazon RDS, there’s really no need for you to be overly concerned about these type of issues since it’s a managed service with most jobs being handled by Amazon.
How Does Amazon RDS Handle Database Failover?
When deploying your Amazon RDS nodes, you can setup your database cluster with Multi-Availability Zone (AZ) or to a Single-Availability Zone. Let’s check each of them on how does failover being processed.
What is a Multi-AZ Setup?
When catastrophe or disaster occurs, such as unplanned outages or natural disasters where your database instances are affected, Amazon RDS automatically switches to a standby replica in another Availability Zone. This AZ is typically in another branch of the data center, often far from the current availability zone where instances are located. These AZ’s are highly-available, state-of-the-art facilities protecting your database instances. Failover times depend on the completion of the setup which is often based on the size and activity of the database as well as other conditions present at the time the primary DB instance became unavailable.
Failover times are typically 60-120 seconds. They can be longer though, as large transactions or a lengthy recovery process can increase failover time. When the failover is complete, it can also take additional time for the RDS Console (UI) to reflect the new Availability Zone.
What is a Single-AZ Setup?
Single-AZ setups should only be used for your database instances if your RTO (Recovery Time Objective) and RPO (Recovery Point Objective) are high enough to allow for it. There are risks involved with using a Single-AZ, such as large downtimes which could disrupt business operations.
Common RDS Failure Scenarios
The amount of downtime is dependent on the type of failure. Let’s go over what these are and how recovery of the instance is handled.
Recoverable Instance Failure
An Amazon RDS instance failure occurs when the underlying EC2 instance suffers a failure. Upon occurrence, AWS will trigger an event notification and send out an alert to you using Amazon RDS Event Notifications. This system uses AWS Simple Notification Service (SNS) as the alert processor.
RDS will automatically try to launch a new instance in the same Availability Zone, attach the EBS volume, and attempt recovery. In this scenario, RTO is typically under 30 minutes. RPO is zero because the EBS volume was able to be recovered. The EBS volume is in a single Availability Zone and this type of recovery occurs in the same Availability Zone as the original instance.
Non-Recoverable Instance Failures or EBS Volume Failures
For failed RDS instance recovery (or if the underlying EBS volume suffers a data loss failure) point-in-time recovery (PITR) is required. PITR is not automatically handled by Amazon, so you need to either create a script to automate it (using AWS Lambda) or do it manually.
The RTO timing requires starting up a new Amazon RDS instance, which will have a new DNS name once created, and then applying all changes since the last backup.
The RPO is typically 5 minutes, but you can find it by calling RDS:describe-db-instances:LatestRestorableTime. The time can vary from 10 minutes to hours depending on the number of logs which need to be applied. It can only be determined by testing as it depends on the size of the database, the number of changes made since the last backup, and the workload levels on the database. Since the backups and transaction logs are stored in Amazon S3, this recovery can occur in any supported Availability Zone in the Region.
Once the new instance is created, you will need to update your client’s endpoint name. You also have the option to rename it to the old DB instance’s endpoint name (but that requires you to delete the old failed instance) but that makes determining the root cause of the issue impossible.
Availability Zone Disruptions
Availability Zone disruptions can be temporary and are rare, however, if AZ failure is more permanent the instance will be set to a failed state. The recovery would work as described previously and a new instance could be created in a different AZ, using point-in-time recovery. This step has to be done manually or by scripting. The strategy for this type of recovery scenario should be part of your larger disaster recovery (DR) plans.
If the Availability Zone failure is temporary, the database will be down but remains in the available state. You are responsible for application-level monitoring (using either Amazon’s or third-party tools) to detect this type of scenario. If this occurs you could wait for the Availability Zone to recover, or you could choose to recover the instance to another Availability Zone with a point-in-time recovery.
The RTO would be the time it takes to start up a new RDS instance and then apply all the changes since the last backup. The RPO might be longer, up to the time the Availability Zone failure occurred.
Testing Failover and Failback on Amazon RDS
We created and setup an Amazon RDS Aurora using db.r4.large with a Multi-AZ deployment (which will create an Aurora replica/reader in a different AZ) which is only accessible via EC2. You will need to make sure to choose this option upon creation if you intend to have Amazon RDS as the failover mechanism.
During the provisioning of our RDS instance, it took about ~11 minutes before the instances became available and accessible. Below is a screenshot of the nodes available in RDS after the creation:
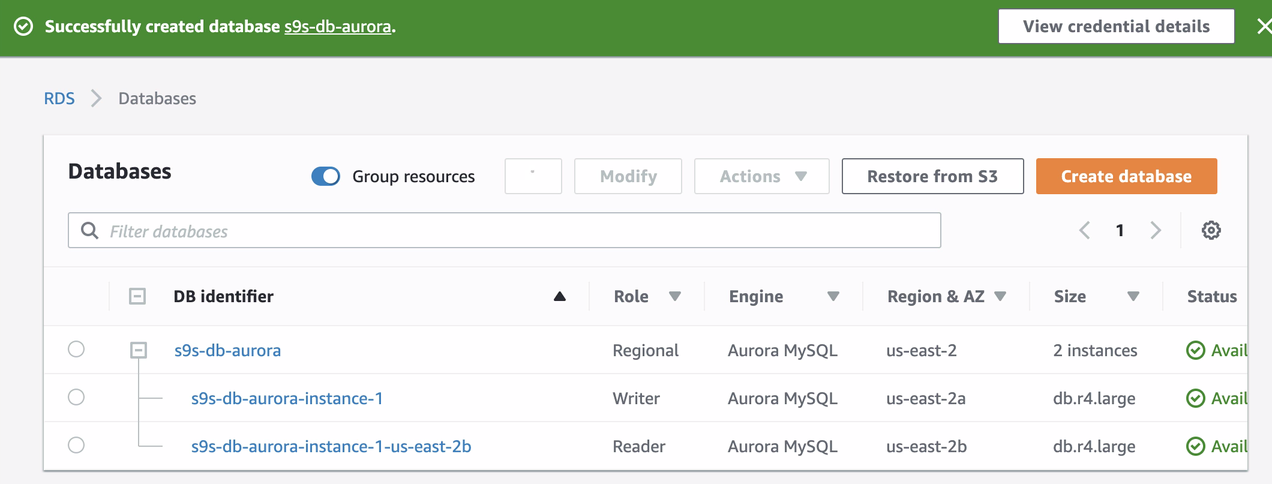
These two nodes will have their own designated endpoint names, which we’ll use to connect from the client’s perspective. Verify it first and check the underlying hostname for each of these nodes. To check, you can run this bash command below and just replace the hostnames/endpoint names accordingly:
root@ip-172-31-8-130:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+The result clarifies as follows,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Simulating Amazon RDS Failover
Now, let’s simulate a crash to simulate a failover for the Amazon RDS Aurora writer instance, which is s9s-db-aurora-instance-1 with endpoint s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com.
To do this, connect to your writer instance using the mysql client command prompt and then issue the syntax below:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];Issuing this command has its Amazon RDS recovery detection and acts pretty quick. Although the query is for testing purposes, it might differ when this occurrence happens in a factual event. You might be interested to know more about testing an instance crash in their documentation. See how we end up below:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Running the SQL command above means that it has to simulate disk failure for at least 3 minutes. I monitored the point in time to begin the simulation and it took about 18 seconds before the failover begins.
See below on how RDS handles the simulation failure and the failover,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+The results of this simulation are pretty interesting. Let’s take this one at a time.
- At around 10:06:29, I started to run the simulation query as stated above.
- At around 10:06:44, it shows that endpoint s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com with assigned hostname of ip-10-20-1-139 where in fact it’s the read-only instance, went inaccessible nevertheless that the simulation command was ran under the read-write instance.
- At around 10:06:51, it shows that endpoint s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com with assigned hostname of ip-10-20-1-139 is up but it has mark as read-write state. Take note that variable innodb_read_only, for Aurora MySQL managed instances, this is its identifier to determine if host is read-write or read-only node and Aurora also runs only on InnoDB storage engine for MySQL comptable instances.
- At around 10:07:13, the order has changed. This means that the failover was done and the instances have been assigned to its designated endpoints.
Checkout the result below which is shown in the RDS console:
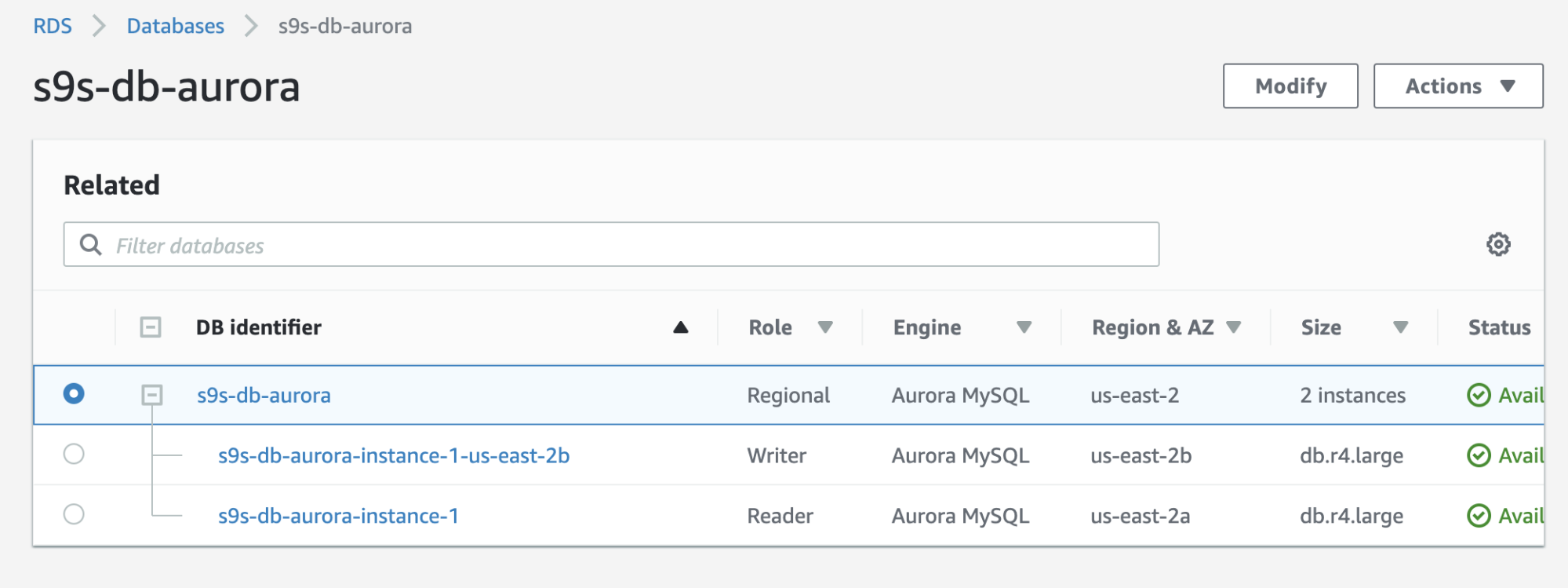
If you compare to the earlier one, the s9s-db-aurora-instance-1 was a reader, but then promoted as a writer after the failover. The process including the test took out some 44 seconds to complete the task, but the failover shows completed at almost 30 seconds. That’s impressive and fast for a failover, especially considering this is a managed service database; meaning you don’t need to worry about any hardware or maintenance issues.
Performing a Failback in Amazon RDS
Failback in Amazon RDS is pretty simple. Before going through it, let’s add a new reader replica. We need an option to test and identify what node AWS RDS would choose from when it tries failing-back to the desired master (or failback to the previous master) and to see if it selects the right node based on priority. The current list of instances as of now and its endpoints are shown below.
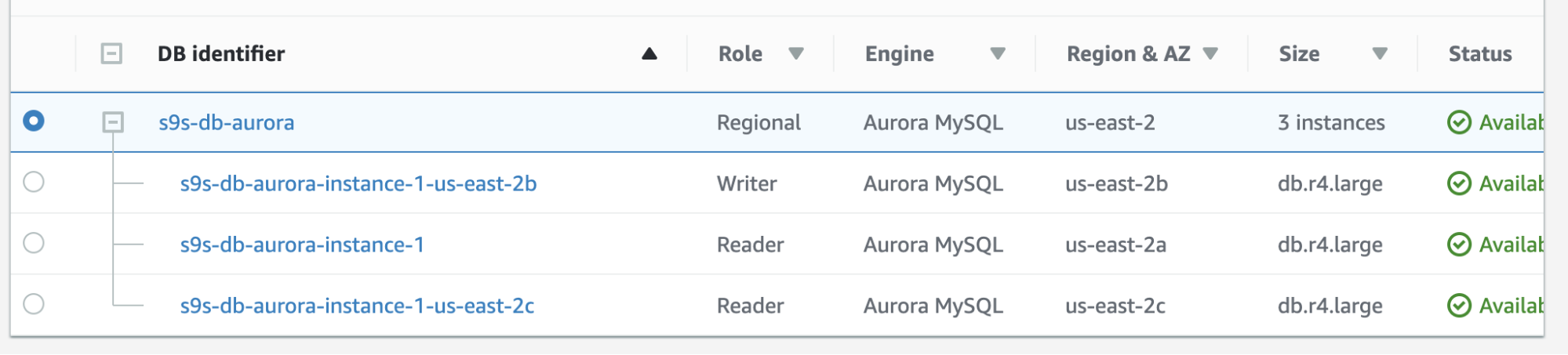

The new replica is located on us-east-2c AZ with db hostname of ip-10-20-2-239.
We’ll attempt to do a failback using the instance s9s-db-aurora-instance-1 as the desired failback target. In this setup we have two reader instances. In order to assure that the correct node is picked up during failover, you will need to establish whether priority or availability is on top (tier-0 > tier-1 > tier-2 and so on until tier-15). This can be done by modifying the instance or during the creation of the replica.
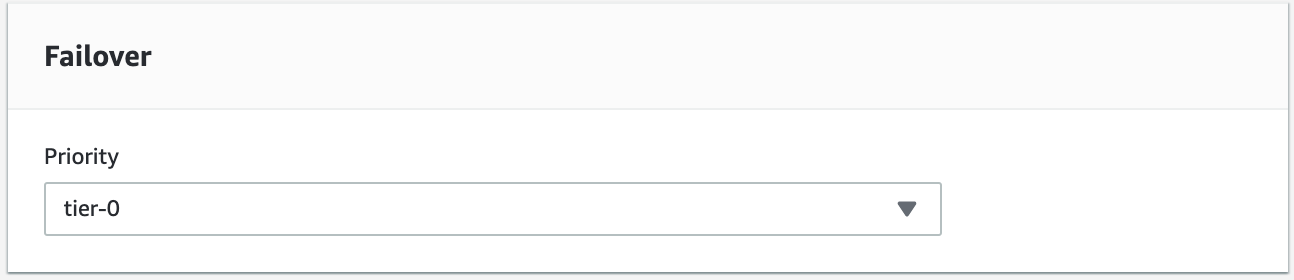
You can verify this in your RDS console.
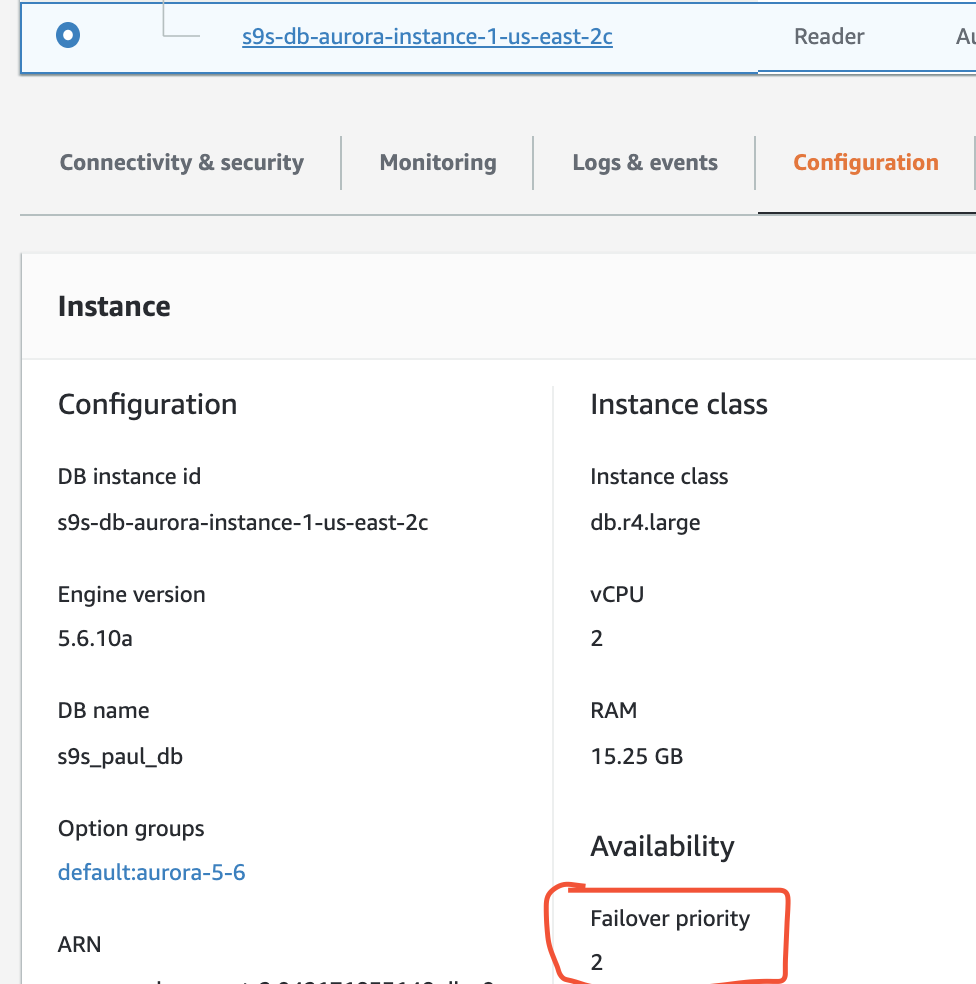
In this setup s9s-db-aurora-instance-1 has priority = 0 (and is a read-replica), s9s-db-aurora-instance-1-us-east-2b has priority = 1 (and is the current writer), and s9s-db-aurora-instance-1-us-east-2c has priority = 2 (and is also a read-replica). Let’s see what happens when we try to failback.
You can monitor the state by using this command.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "n==========================================="; date; echo -e "===========================================n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;After the failover has been triggered, it will failback to our desired target, which is the node s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+The failback attempt started at 13:30:59 and it completed around 13:31:38 (nearest 30 second mark). It ends up ~32 seconds on this test, which is still fast.
I have verified the failover/failback multiple times and it has been consistently exchanging its read-write state between instances s9s-db-aurora-instance-1 and s9s-db-aurora-instance-1-us-east-2b. This leaves s9s-db-aurora-instance-1-us-east-2c left unpicked unless both nodes are experiencing issues (which is very rare as they are all situated in different AZ’s).
During the failover/failback attempts, RDS goes at a rapid transition pace during the failover at around 15 – 25 seconds (which is very fast). Keep in mind, we don’t have huge data files stored on this instance, but it’s still quite impressive considering there is nothing further to manage.
Conclusion
Running a Single-AZ introduces danger when performing a failover. Amazon RDS allows you to modify and convert your Single-AZ to a Multi-AZ capable setup, though this will add some costs for you. Single-AZ may be fine if you are ok with a higher RTO and RPO time, but is definitely not recommended for high-traffic, mission-critical, business applications.
With Multi-AZ, you can automate failover and failback on Amazon RDS, spending your time focusing on query tuning or optimization. This eases many problems faced by DevOps or DBAs.
While Amazon RDS may cause a dilemma in some organizations (as it’s not platform agnostic), it’s still worthy of consideration; especially if your application requires a long term DR plan and you do not want to have to spend time worrying about hardware and capacity planning.



