blog
Automatic Scaling with Amazon Aurora Serverless

Amazon Aurora Serverless provides an on-demand, auto-scalable, highly-available, relational database which only charges you when it’s in use. It provides a relatively simple, cost-effective option for infrequent, intermittent, or unpredictable workloads. What makes this possible is that it automatically starts up, scales compute capacity to match your application’s usage, and then shuts down when it’s no longer needed.
The following diagram shows Aurora Serverless high-level architecture.
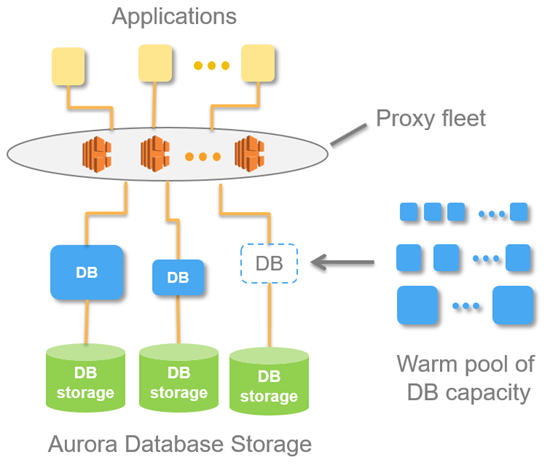
With Aurora Serverless, you get one endpoint (as opposed to two endpoints for the standard Aurora provisioned DB). This is basically a DNS record consisting of a fleet of proxies which sits on top of the database instance. From a MySQL server point it means that the connections are always coming from the proxy fleet.
Aurora Serverless Auto-Scaling
Aurora Serverless is currently only available for MySQL 5.6. You basically have to set the minimum and maximum capacity unit for the DB cluster. Each capacity unit is equivalent to a specific compute and memory configuration. Aurora Serverless reduces the resources for the DB cluster when its workload is below these thresholds. Aurora Serverless can reduce capacity down to the minimum or increase capacity to maximum capacity unit.
The cluster will automatically scale up if either of the following conditions are met:
- CPU utilization is above 70% OR
- More than 90% of connections are being used
The cluster will automatically scale down if both of the following conditions are met:
- CPU utilization drops below 30% AND
- Less than 40% of connections are being used.
Some of the notable things to know about Aurora automatic scaling flow:
- It only scales up when it detects performance issues that can be resolved by scaling up.
- After scaling up, the cooldown period for scaling down is 15 minutes.
- After scaling down, the cooldown period for the next scaling down again is 310 seconds.
- It scales to zero capacity when there are no connections for a 5-minute period.
By default, Aurora Serverless performs the automatic scaling seamlessly, without cutting off any active database connections to the server. It is capable of determining a scaling point (a point in time at which the database can safely initiate the scaling operation). Under the following conditions, however, Aurora Serverless might not be able to find a scaling point:
- Long-running queries or transactions are in progress.
- Temporary tables or table locks are in use.
If either of the above cases happens, Aurora Serverless continues to try to find a scaling point so that it can initiate the scaling operation (unless “Force Scaling” is enabled). It does this for as long as it determines that the DB cluster should be scaled.
Observing Aurora Auto Scaling Behaviour
Note that in Aurora Serverless, only a small number of parameters can be modified and max_connections is not one of them. For all other configuration parameters, Aurora MySQL Serverless clusters use the default values. For max_connections, it is dynamically controlled by Aurora Serverless using the following formula:
max_connections = GREATEST({log(DBInstanceClassMemory/805306368)*45},{log(DBInstanceClassMemory/8187281408)*1000})
Where, log is log2 (log base-2) and “DBInstanceClassMemory” is the number of bytes of memory allocated to the DB instance class associated with the current DB instance, less the memory used by the Amazon RDS processes that manage the instance. It’s pretty hard to predetermine the value that Aurora will use, thus it’s good to put some tests to understand how this value is scaled accordingly.
Here is our Aurora Serverless deployment summary for this test:
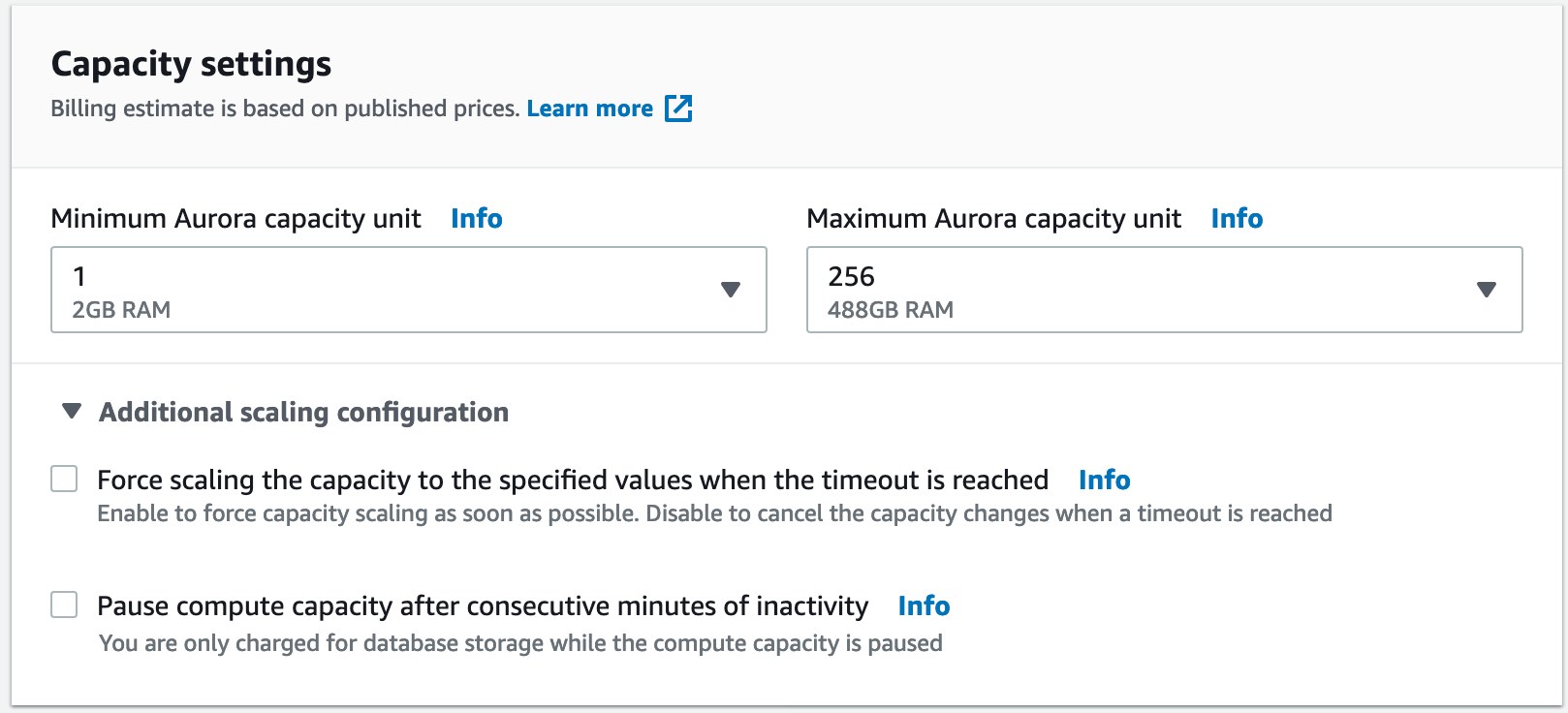
For this example I’ve selected a minimum of 1 Aurora capacity unit, which is equal to 2GB of RAM up until the maximum 256 capacity unit with 488GB of RAM.
Tests were performed using sysbench, by simply sending out multiple threads until it reaches the limit of MySQL database connections. Our first attempt to send out 128 simultaneous database connections at once got into a straight failure:
$ sysbench
/usr/share/sysbench/oltp_read_write.lua
--report-interval=2
--threads=128
--delete_inserts=5
--time=360
--max-requests=0
--db-driver=mysql
--db-ps-mode=disable
--mysql-host=${_HOST}
--mysql-user=sbtest
--mysql-db=sbtest
--mysql-password=password
--tables=20
--table-size=100000
runThe above command immediately returned the ‘Too many connections’ error:
FATAL: unable to connect to MySQL server on host 'aurora-sysbench.cluster-cdw9q2wnb00s.ap-southeast-1.rds.amazonaws.com', port 3306, aborting...
FATAL: error 1040: Too many connectionsWhen looking at the max_connection settings, we got the following:
mysql> SELECT @@hostname, @@max_connections;
+----------------+-------------------+
| @@hostname | @@max_connections |
+----------------+-------------------+
| ip-10-2-56-105 | 90 |
+----------------+-------------------+It turns out, the starting value of max_connections for our Aurora instance with one DB capacity (2GB RAM) is 90. This is actually way lower than our anticipated value if calculated using the provided formula to estimate the max_connections value:
mysql> SELECT GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000});
+------------------------------------------------------------------------------+
| GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000}) |
+------------------------------------------------------------------------------+
| 262.2951 |
+------------------------------------------------------------------------------+This simply means the DBInstanceClassMemory is not equal to the actual memory for Aurora instance. It must be way lower. According to this discussion thread, the variable’s value is adjusted to account for memory already in use for OS services and RDS management daemon.
Nevertheless, changing the default max_connections value to something higher won’t help us either since this value is dynamically controlled by Aurora Serverless cluster. Thus, we had to reduce the sysbench starting threads value to 84 because Aurora internal threads already reserved around 4 to 5 connections via ‘rdsadmin’@’localhost’. Plus, we also need an extra connection for our management and monitoring purposes.
So we executed the following command instead (with –threads=84):
$ sysbench
/usr/share/sysbench/oltp_read_write.lua
--report-interval=2
--threads=84
--delete_inserts=5
--time=600
--max-requests=0
--db-driver=mysql
--db-ps-mode=disable
--mysql-host=${_HOST}
--mysql-user=sbtest
--mysql-db=sbtest
--mysql-password=password
--tables=20
--table-size=100000
runAfter the above test was completed in 10 minutes (–time=600), we ran the same command again and at this time, some of the notable variables and status had changed as shown below:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+--------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+--------------+-----------------+-------------------+--------+
| ip-10-2-34-7 | 180 | 179 | 157 |
+--------------+-----------------+-------------------+--------+Notice that the max_connections has now doubled up to 180, with a different hostname and small uptime like the server was just getting started. From the application point-of-view, it looks like another “bigger database instance” has taken over the endpoint and configured with a different max_connections variable. Looking at the Aurora event, the following has happened:
Wed, 04 Sep 2019 08:50:56 GMT The DB cluster has scaled from 1 capacity unit to 2 capacity units.Then, we fired up the same sysbench command, creating another 84 connections to the database endpoint. After the generated stress test completed, the server automatically scales up to 4 DB capacity, as shown below:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-12-75 | 270 | 6 | 300 |
+---------------+-----------------+-------------------+--------+You can tell by looking at the different hostname, max_connection and uptime value if compared to the previous one. Another bigger instances has “taken over” the role from the previous instance, where DB capacity was equal to 2. The actual scaling point is when the server load was dropping and almost hitting the floor. In our test, if we kept the connection full and the database load consistently high, automatic scaling wouldn’t take place.
By looking at both screenshots below, we can tell the scaling only happens when our Sysbench has completed its stress test for 600 seconds because that is the safest point to perform automatic scaling.
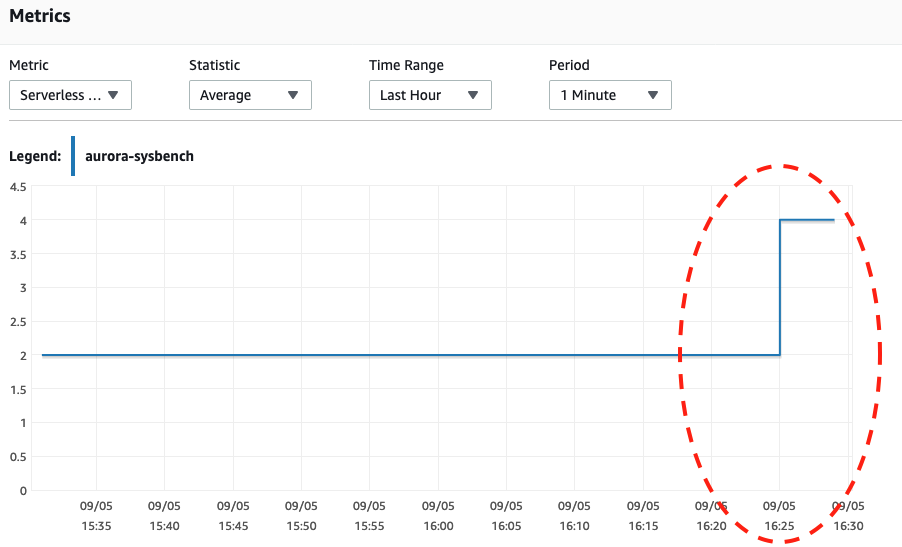 Serverless DB Capacity
Serverless DB Capacity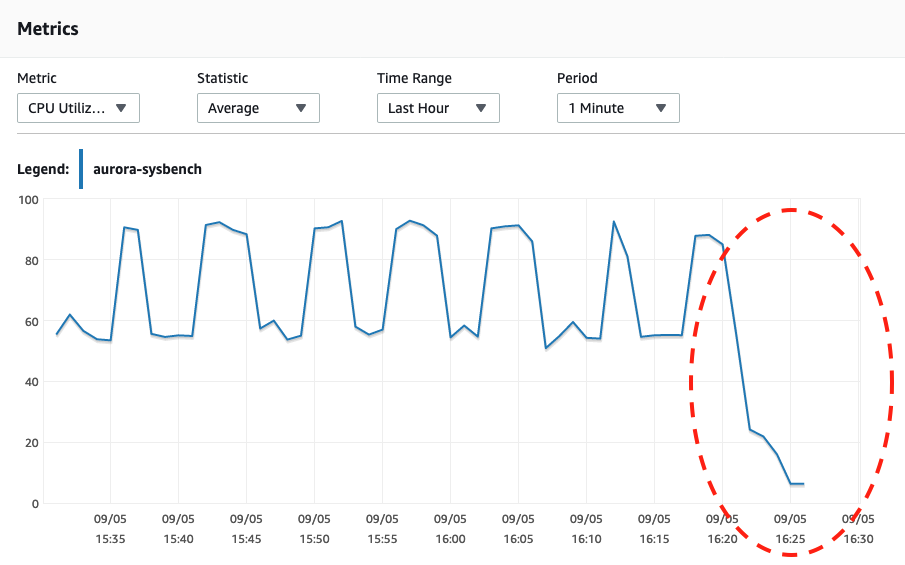 CPU Utilization
CPU UtilizationWhen looking at Aurora events, the following events happened:
Wed, 04 Sep 2019 16:25:00 GMT Scaling DB cluster from 4 capacity units to 2 capacity units for this reason: Autoscaling.
Wed, 04 Sep 2019 16:25:05 GMT The DB cluster has scaled from 4 capacity units to 2 capacity units.Finally, we generated much more connections until almost 270 and wait until it finished, to get into the 8 DB capacity:
mysql> SELECT @@hostname as hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-72-12 | 1000 | 144 | 230 |
+---------------+-----------------+-------------------+--------+In the 8 capacity unit instance, MySQL max_connections value is now 1000. We repeated similar steps by maxing out the database connections and up until the limit of 256 capacity unit. The following table summarizes overall DB capacity unit versus max_connections value in our testing up to the maximum DB capacity:
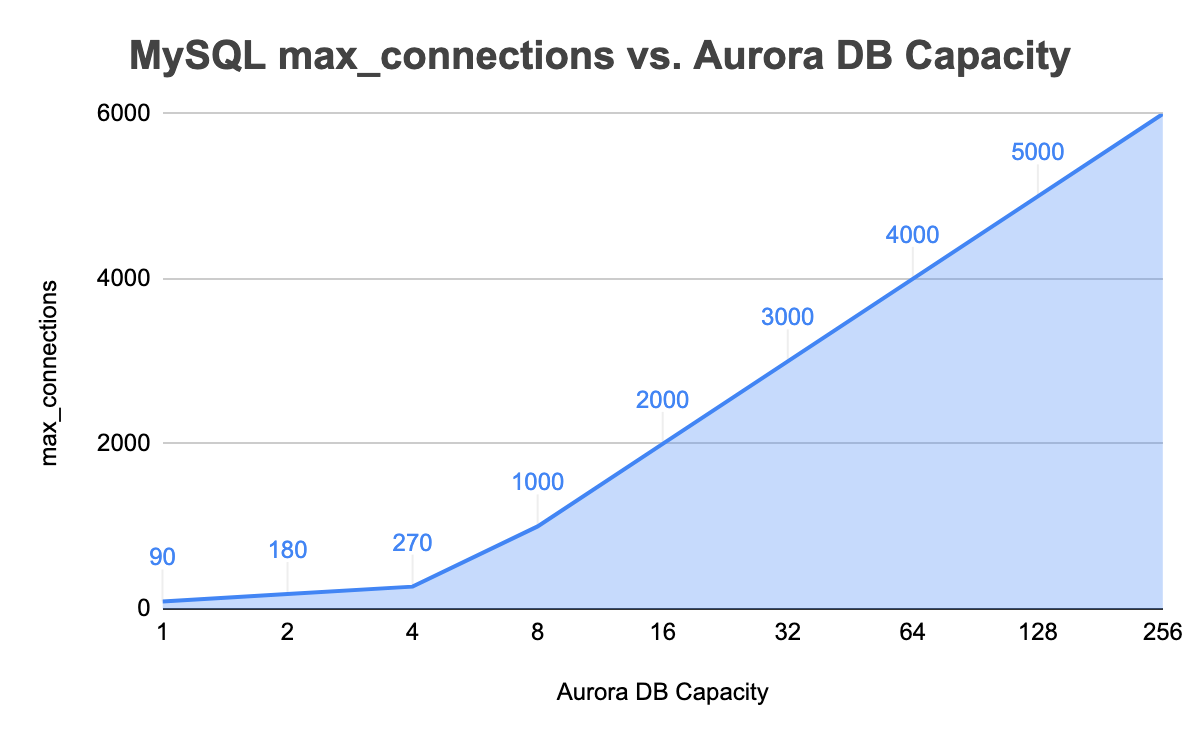
Forced Scaling
As mentioned above, Aurora Serverless will only perform automatic scaling when it’s safe to do so. However, the user has the option to force the DB capacity scaling to happen immediately by ticking on the Force scaling checkbox under ‘Additional scaling configuration’ option:
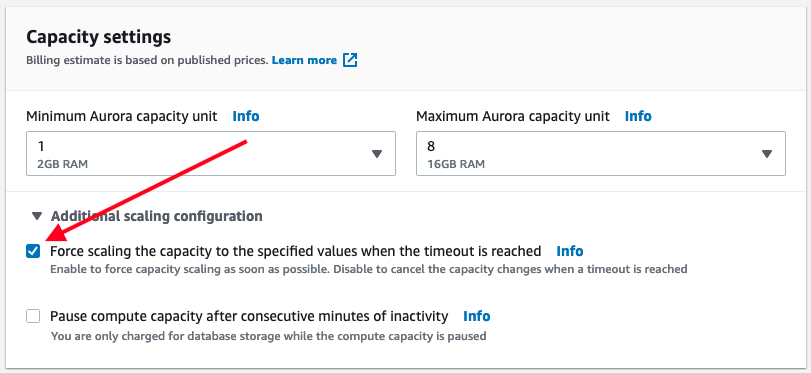
When forced scaling is enabled, the scaling happens as soon as the timeout is reached which is 300 seconds. This behaviour may cause database interruption from your application where active connections to the database may get dropped. We observed the following error when force automatic scaling happened after it reaches timeout:
FATAL: mysql_drv_query() returned error 1105 (The last transaction was aborted due to an unknown error. Please retry.) for query 'SELECT c FROM sbtest19 WHERE id=52824'
FATAL: `thread_run' function failed: /usr/share/sysbench/oltp_common.lua:419: SQL error, errno = 1105, state = 'HY000': The last transaction was aborted due to an unknown error. Please retry.The above simply means, instead of finding the right time to scale up, Aurora Serverless forces the instance replacement to take place immediately after reaches its timeout, which cause transactions being aborted and roll backed. Retrying the aborted query for the second time will likely solve the problem. This configuration could be used if your application is resilient to connection drops.
Summary
Amazon Aurora Serverless auto scaling is a vertical scaling solution, where a more powerful instance takes over an inferior instance, utilizing the underlying Aurora shared storage technology efficiently. By default, the auto scaling operation is performed seamlessly, whereby Aurora finds a safe scaling point to perform the instance switching. One has the option to force for automatic scaling with risks of active database connections get dropped.



