blog
An Overview of MongoDB and Load Balancing

Database load balancing distributes concurrent client requests to multiple database servers to reduce the amount of load on any single server. This can improve the performance of your database drastically. Fortunately, MongoDB can handle multiple client’s requests to read and write the same data simultaneously by default. It uses some concurrency control mechanisms and locking protocols to ensure data consistency at all times.
In this way, MongoDB also ensures that all the clients get a consistent view of data at any time. Because of this built-in feature of handling requests from multiple clients, you don’t have to worry about adding an external load balancer on top of your MongoDB servers. Although, if you still want to improve the performance of your database using load balancing, here are some ways to achieve that.
MongoDB Vertical Scaling
In simple terms, Vertical scaling means adding more resources to your server to handle to load. Like all the database systems, MongoDB prefers more RAM and IO capacity. This is the simplest way to boost MongoDB performance without spreading the load across multiple servers. Vertical scaling of the MongoDB database typically includes increasing CPU capacity or disk capacity and increasing throughput(I/O operations). By adding more resources, your mongo server becomes more capable of handling multiple client’s requests. Thus, better load balancing for your database.
The downside of using this approach is the technical limitation of adding resources to any single system. Also, all the cloud providers have the limitations on adding new hardware configurations. The other disadvantage of this approach is a single point of failure. In this approach, all your data is being stored in a single system, which can lead to permanent loss of your data.
MongoDB Horizontal Scaling
Horizontal scaling refers to dividing your database into chunks and stores them on multiple servers. The main advantage of this approach is that you can add additional servers on the fly to increase your database performance with zero downtime. MongoDB provides horizontal scaling through sharding. MongoDB sharding gives additional capacity to distribute the write load across multiple servers(shards). Here, each shard can be seen as one independent database and the collection of all the shards can be viewed as one big logical database. Sharding enables your MongoDB to distribute the data across multiple servers to handle concurrent client requests efficiently. Hence, it increases your database’s read and writes throughput.
MongoDB Sharding
A shard can be a single mongod instance or a replica set that holds the subset of the mongo sharded database. You can convert shard in replica set to ensure high availability of data and redundancy.
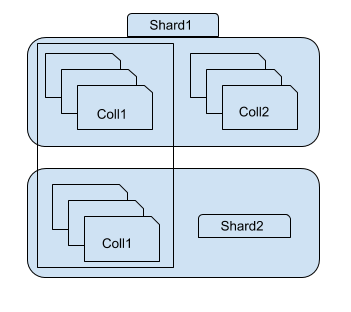
As you can see in the above image, shard 1 holds a subset of collection 1 and whole collection2, whereas shard 2 contains only other subset of collection1. You can access each shard using the mongos instance. For example, if you connect to shard1 instance, you will be able to see/access only a subset of collection1.
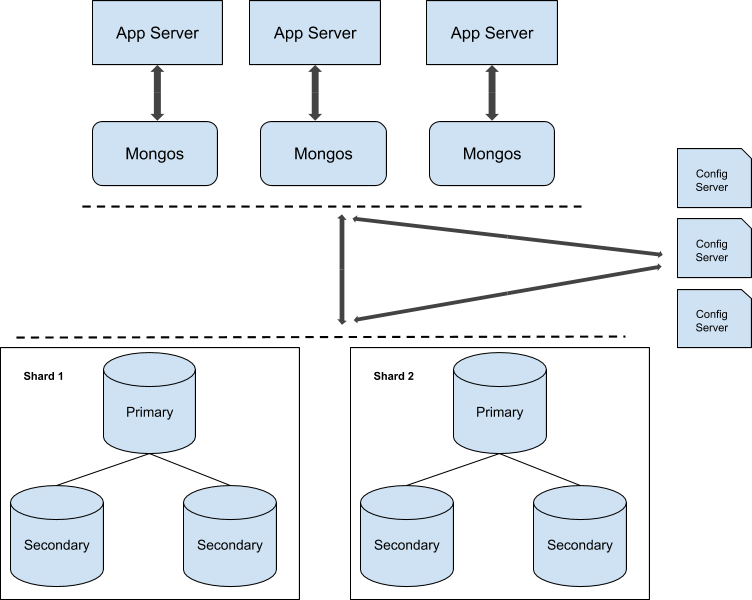
Mongos
Mongos is the query router which provides access to sharded cluster for client applications. You can have multiple mongos instances for better load balancing. For example, in your production cluster, you can have one mongos instance for each application server. Now here you can use an external load balancer, which will redirect your application server’s request to appropriate mongos instance. While adding such configurations to your production server, make sure that connection from any client always connects to the same mongos instance every time as some mongo resources such as cursors are specific to mongos instance.
Config Servers
Config servers store the configuration settings and metadata about your cluster. From MongoDB version 3.4, you have to deploy config servers as a replica set. If you are enabling sharding in a production environment, then it is mandatory to use three separate config servers, each on different machines.
You can follow this guide to convert your replica set cluster into a sharded cluster. Here is the sample illustration of sharded production cluster:
MongoDB Load Balancing Using Replication
Sometimes MongoDB replication can be used to handle more traffic from clients and to reduce the load on the primary server. To do so, you can instruct clients to read from secondaries instead of the primary server. This can reduce the amount of load on the primary server as all the read requests coming from clients will be handled by secondary servers, and the primary server will only take care of write requests.
Following is the command to set the read preference to secondary:
db.getMongo().setReadPref('secondary')You can also specify some tags to target specific secondaries while handling the read queries.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Here, MongoDB will try to find the secondary node with the datacenter tag value as APAC. If found, then Mongo will serve the read requests from all the secondaries with tag datacenter: “APAC”. If not found, then Mongo will try to find secondaries with tag region: “East”. If still no secondaries found, then {} will work as the default case, and Mongo will serve the requests from any eligible secondaries.
However, this approach for load balancing is not advisable to use for increasing read throughput. Because any read preference mode other than primary can return old data in case of recent write updates on the primary server. Usually, primary server will take some time to handle the write requests and propagates the changes to secondary servers. During this time, if someone requests read operation on the same data, the secondary server will return stale data as it is not in sync with the primary server. You can use this approach if your application is read operations heavy in comparison to write operations.
Conclusion
As MongoDB can handle concurrent requests by itself, there is no need to add a load balancer in your MongoDB cluster. For load balancing the client requests, you can choose either vertical scaling or horizontal scaling as it is not advisable to use secondaries to scale out your read and write operations. Vertical scaling can hit the technical limits, as discussed above. Therefore, it is suitable for small scale applications. For big applications, horizontal scaling through sharding is the best approach for load balancing the read and write operations.



