blog
NoSQL Data Streaming with MongoDB & Kafka

Developers describe Kafka as a “Distributed, fault-tolerant, high throughput, pub-sub, messaging system.” Kafka is well-known as a partitioned, distributed, and replicated commit log service. It also provides the functionality of a messaging system, but with a unique design. On the other hand, MongoDB is known as “The database for giant ideas.” MongoDB is capable of storing data in JSON-like documents that can vary in structure, offering a dynamic, flexible schema. MongoDB is designed for high availability and scalability, with built-in replication and auto-sharding.
MongoDB is classified under “Databases”, while Kafka belongs to the “Message Queue” category of the tech stack. Developers consider Kafka “High-throughput”, “Distributed” and “Scalable” as the key factors; whereas “Document-oriented storage”, “No SQL” and “Ease of use” is considered as the primary reasons why MongoDB is favored.
Data Streaming in Kafka
In today’s data ecosystem, there is no single system that can provide all of the required perspectives to deliver real insight of the data. Deriving better visualization of data insights from data requires mixing a huge volume of information from multiple data sources. As such, we are eager to get answers immediately; if the time taken to analyze data insights exceeds 10s of milliseconds, then the value is lost or irrelevant. Applications such as fraud detection, high-frequency trading, and recommendation engines cannot afford to wait. This operation also is known as analyzing the inflow of data before it gets updated as the database of record with zero tolerance for data loss, and the challenge gets even more daunting.
Kafka helps you ingest and quickly move reliably large amounts of data from multiple data sources and then redirect it to the systems that need it by filtering, aggregating, and analyzing en-route. Kafka has a higher throughput, reliability, and replication characteristics, a scalable method to communicate streams of event data from one or more Kafka producers to one or more Kafka consumers. Examples of events include:
- Air pollution data captured based on periodical basis
- A consumer adding an item to the shopping cart in an online store
- A Tweet posted with a specific hashtag
Streams of Kafka events are captured and organized into predefined topics. The Kafka producer chooses a topic to send a given event to, and consumers select which topics they pull events from. For example, a stock market financial application could pull stock trades from one topic and company financial information from another in order to look for trading opportunities.
MongoDB and Kafka collaboration make up the heart of many modern data architectures today. Kafka is designed for boundless streams of data that sequentially write events into commit logs, allowing real-time data movement between MongoDB and Kafka done through the use of Kafka Connect.
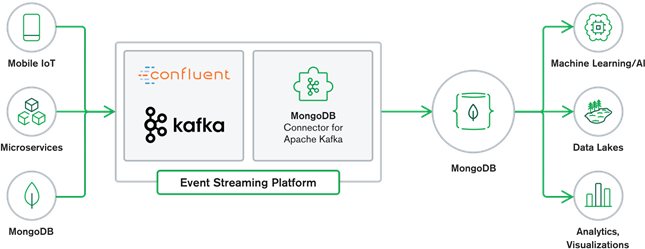
The official MongoDB Connector for Kafka was developed and is supported by MongoDB Inc. engineers. It is also verified by Confluent (who pioneered the enterprise-ready event streaming platform), conforming to the guidelines which were set forth by Confluent’s Verified Integrations Program. The connector enables MongoDB to be configured as both a sink and a source for Kafka. Easily build robust, reactive data pipelines that stream events between applications and services in real-time.
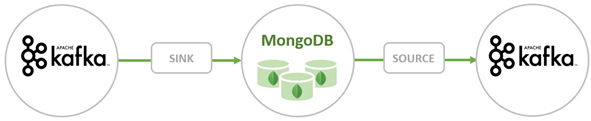
MongoDB Sink Connector
The MongoDB Sink allows us to write events from Kafka to our MongoDB instance. The Sink connector converts the value from the Kafka Connect SinkRecords into a MongoDB Document and will do an insert or upsert depending on the configuration you chose. It expected the database created upfront, the targeted MongoDB collections created if they don’t exist.
MongoDB Kafka Source Connector
The MongoDB Kafka Source Connector moves data from a MongoDB replica set into a Kafka cluster. The connector configures and consumes change stream event documents and publishes them to a topic. Change streams, a feature introduced in MongoDB 3.6, generate event documents that contain changes to data stored in MongoDB in real-time and provide guarantees of durability, security, and idempotency. You can configure change streams to observe changes at the collection, database, or deployment level. It uses the following settings to create change streams and customize the output to save to the Kafka cluster. It will publish the changed data events to a Kafka topic that consists of the database and collection name from which the change originated.
MongoDB & Kafka Use Cases
eCommerce Websites
Use case of an eCommerce website whereby the inventory data is stored into MongoDB. When the stock inventory of the product goes below a certain threshold, the company would like to place an automatic order to increase the stock. The ordering process is done by other systems outside of MongoDB, and using Kafka as the platform for such event-driven systems are a great example of the power of MongoDB and Kafka when used together.
Website Activity Tracking
Site activity such as pages visited or adverts rendered are captured into Kafka topics – one topic per data type. Those topics can then be consumed by multiple functions such as monitoring, real-time analysis, or archiving for offline analysis. Insights from the data stored in an operational database such as MongoDB, where they can be analyzed alongside data from other sources.
Internet of Things (IoT)
IoT applications must cope with massive numbers of events that are generated by a multitude of devices. Kafka plays a vital role in providing the fan-in and real-time collection of all of that sensor data. A common use case is telematics, where diagnostics from a vehicle’s sensors must be received and processed back at base. Once captured in Kafka topics, the data can be processed in multiple ways, including stream processing or Lambda architectures. It is also likely to be stored in an operational database such as MongoDB, where it can be combined with other stored data to perform real-time analytics and support operational applications such as triggering personalized offers.
Conclusion
MongoDB is well-known as non-relational databases, which published under a free-and-open-source license, MongoDB is primarily a document-oriented database, intended for use with semi-structured data like text documents. It is the most popular modern database built for handling huge and massive volumes of heterogeneous data.
Kafka is a widely popular distributed streaming platform that thousands of companies like New Relic, Uber, and Square use to build scalable, high-throughput, and reliable real-time streaming systems.
Together MongoDB and Kafka play vital roles in our data ecosystem and many modern data architectures.



