blog
An Introduction to Couchbase

Relational database systems are falling short in recent years generally due to exponential rise of web applications and drastic growth of the internet. The new generation of enterprise requirements justified the need to establish database systems which are more dynamic, hence the Non-relational DBMS. With the fixed data model of relational databases, it is quite difficult to make major adjustments that could lead to a fast performing database. To be seccant, mobile and modern web applications evolve more rapidly than legacy applications such as enterprise planning applications, hence need to consider speed and agility.
Due to future change expectations in data structure for a given application, it is also advisable to perform the changes in data models within a database in an easy and secure manner. With relational databases, this is very expensive basically because it involves a fixed data model. On the other hand, Non-relational databases offer some flexibility to changes in the data models and schema design and therefore accommodate the rising changes to application needs.
The major reasons to use a Non-Relational DBM include:
- More users are joining the platform hence need to scale out to support thousands of them and maintain high availability of data so as to improve on data integrity
- Expectations for data changes and differences. Users have different interests hence your platform need to support different data structures and continuous streams of real-time data.
- Data is getting bigger. With time you will have to store a lot of customer data and data from different sources.
- Cloud computing. As the number of customers rises you need to come up with techniques such as scaling on demand, replicating data but at the same time minimize on resources cost.
Couchbase Architecture
Couchbase database is a NoSQL DBMS that has come to rise due to its high performing power as well as integrating the most essential features of a Non-relational database. It achieves this through 2 major technologies that are:
- CouchDB a concept that supports storage of data in JSON format hence supporting document-oriented model.
- Membase technique that enhances high data availability through replication and sharding thus improving on performance.
CouchDB has a highly tuned storage engine designed to handle update transactions and query processing in real-time.
Couchbase Storage Mechanism
CouchDB storage structure supports SQLite DB and CouchDB through a defined data server interface from which these storage structures can be connected. CouchDB is most preferred since it provides a very powerful storage mechanism as far as the Couchbase technology is concerned.
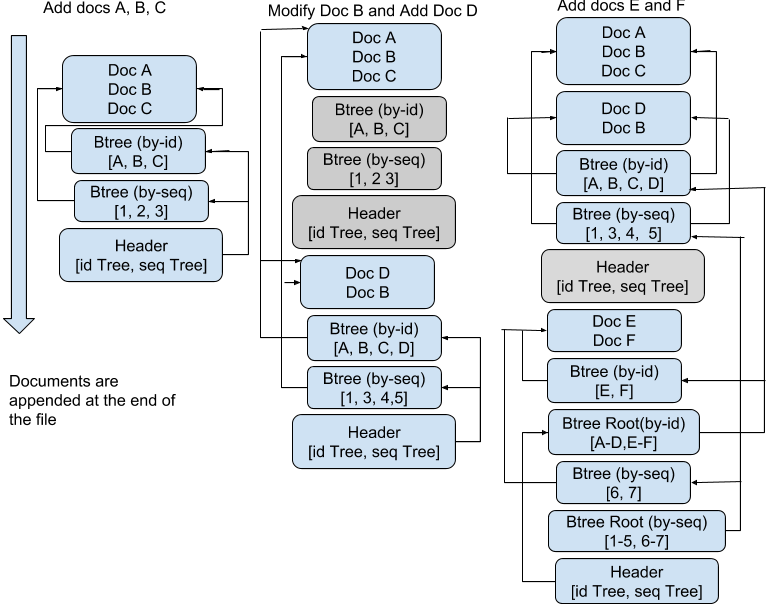
Unlike other storage technologies whereby an update has to be altered for a selected document, with CouchDB data are written to a file in an append-only manner. This enables sequential writes for updates besides providing an optimized access pattern for inputs and outputs.
Data management in Couchbase server is achieved through buckets which are isolated virtual containers for data. The write file mentioned above is provided by this bucket generally known as vBucket. A bucket in Couchbase can be defined as a logical grouping of physical resources within a cluster of Couchbase servers. Buckets play an important role in ensuring a secure mechanism for managing, organizing and analyzing data storage resources.
Flusher Thread
Updates in Couchbase are asynchronous hence carried out in 3 steps. The update is done by a flusher thread in batches and this is how it works:
- All pending write requests are picked from a dirty queue and de-duplicated multiple update requests to the same document.
- The requests are sorted by key into corresponding vBucket after opening the corresponding file.
- The following is appended to the vBucket file in the same contiguous sequence.
- All document contents in such write request batch. I.e. [length, crc, content] in a sequential manner.
- BTree by-id which is an index that stores the mapping from document id to the document’s position on the disk.
- BTree by-seq which is an index that stores the mapping from sequence number to the document’s position on the disk.
The by-id index enables fast lookup of the document by its id in the file. The lookup starts from the header that is the end of the file then transferred to the root BTree node of the by-id index and then traversed to the leaf BTree node that contains a pointer to the actual document position on the disk.
The by-seq index is used to keep track of the update sequence of lived documents and is used for asynchronous catch-up purposes. Whenever a document is created, modified or deleted, a sequence number is added to the by-seq BTree while the previous seq node is deleted. With this, there is cross-site replication, view index update and compaction that enables quick location of all lived documents in the order of their updates.
When the vBucket replicator inquiries for the list of an update since a particular time, the last sequence number in the previous update is provided and a scan through the by-seq BTree node is triggered to locate all documents with larger sequence number than that.
In the illustration below, there is a greyed out data. This is termed as garbage data which often becomes unreachable within the file. A garbage collection mechanism needs to be in place for clean up. This is done by analyzing the data size of lived documents by the use of the by-id and by-seq BTree nodes. If the ratio of the actual size and vBucket file size fall below a certain threshold, a compaction process is initiated whose job is to open the vBucket file and copy data that had not been cleaned up to another file. It does so by tracing the BTree all the way to the leaf node and copy the corresponding document content to the new file and this happens every time the vBucket is being updated. At the end of the compaction process, the system copies the data that was appended since the beginning of the compaction to the new file.
The flusher process is as illustrated below.
Couchbase Buckets
Buckets are logical groupings of physical resources within a Couchbase Servers cluster that provide a secure mechanism for organizing, managing and analyzing the data storage resources. There are 2 types of data buckets in Couchbase DB so far that is, Memcached and Couchbase. They enable store data in-memory or both in memory and on disk.
When setting up a Couchbase Server, consider these tips when selecting a bucket for your data:
Memcached bucket: These are often designed to be used alongside relational database technology. Frequently used data is cached to reduce the number of queries the database server must perform hence reducing the latency of a request.
Couchbase bucket: This is a more dynamic and highly-available distributed data storage with persistence and replication services. They operate through RAM that is, data is kept in RAM and persisted down to disk. These data is cached within the RAM until the configured RAM is exhausted and data is ejected from RAM. Otherwise, if the data currently requested is absent in RAM, it is automatically loaded from disk.
Major Merits of Couchbase Database
- Easy replication and improved high availability: A large number of replica servers can be configured to receive copies of all data objects in the Couchbase-type bucket. Failure of the host machine triggers a promotion of one of the replica servers to be host server hence providing high availability cluster operations via failover.
- Caching. Data is kept in the RAM for quick access until the RAM size is exhausted then it is ejected. This generally reduces the latency of a query request.
- Persistence of data. Data objects are persisted asynchronously to hard-disk resources from memory to provide protection from server restarts or minor failures.
- Rebalancing: according to resources provision, rebalancing enables load distribution through adding or removing buckets and servers in the cluster.
- Fully featured SQL for JSON database. With the Memcached bucket, one can easily manipulate data with SQL queries.
- Flexible schema to accommodate changes in data structures and ensure continuous delivery.
- No hassle to scale out and consistent performance at any scale.
- Global deployment at low write latency and full stack security. Working with distributed databases at some point is very hectic. Couchbase provides a single platform of maintenance that is easy in terms of storage, access, transport and enterprise-grade security on premises and across multiple clouds.
Conclusion
User experience has led to technological changes around database management system. Many technologies have been innovated to ascertain comfortability in the usage of mobile and web application in terms of serving speeding. It is thus important to employ a database system that is quite flexible to any future changes in terms of data structure and scaling. Couchbase database comes with these merits more especially with its flexible schema and little maintenance hassles. Besides, it has a capability to support fully feature SQL for JSON database. It also guarantees consistent performance thus creating a seamless user experience.



