blog
Fixing Page Faults in MongoDB

Page faults are a prevalent error that mostly occurs in a large application involving large data. It takes place when MongoDB database reads data from physical memory rather than from virtual memory. Page fault errors occur at the moment MongoDB wants to get data that is not available in active memory of the database hence forced to read from disk. This creates a large latency for throughput operations making queries look like they are lagging.
Adjusting the performance of MongoDB by tuning is a vital component that optimizes execution of an application. Databases are enhanced to work with information kept on the disk, however it habitually cache large amounts of data in the RAM in an attempt to access the disk. It is expensive to store and access data from the database, therefore the information must be first stored in the disk before allowing applications to access it. Due to the fact that disks are slower as compared to RAM data cache consequently the process consumes a significant amount of time. Therefore, MongoDB is designed to report occurence of page faults as a summary of all incidents in one second
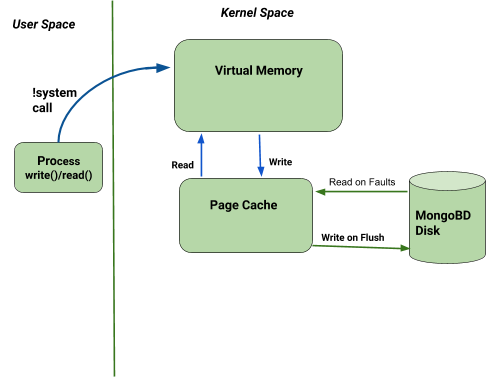
The Data Movement Topology in MongoDB
Data from the client moves to the virtual memory where page cache reads it as it is written, data is then stored in the disk as shown in the diagram below.
How to Find MongoDB Page Faults
Page faults can be detected through locking performance that ensure data consistency in MongoDB. When a given operation queues or runs for a long time then MongoDB performance degrades and the operation slows down as it waits for lock. This leads to a slowdown since lock-related delays are sporadic and sometimes affects performance of the application. Lock influences the performance of an application when locks are divided (locks.timeAcquiringMicros by locks.acquireWaitCount), this gives the average time to wait for a given lock mode. Locks.deadLockCount gives the total of all the lock acquisitions impasse experienced. Given that the globalLock.totalTime is harmoniously high then there are numerous requests expecting a lock. As more requests wait for lock more RAM is consumed and this leads to page Faults.
You can also use mem.mapped which enables developers to scrutinize the total memory that mongod is utilizing. Mem.mapped is a server operator for checking the amount of memory in megabyte (MB) in a MMAPv1 storage engine. If mem.mapped operator shows A value greater than the total amount of system memory then a page fault will result because such a large amount of memory usage will lead to a page fault in the database.
How Page Faults Occur in MongoDB
Loading pages in MongoDB depends on the availability of free memory, in an event that it lacks free memory then operating system has to:
- Look for a page that the database has ceased using and write the page on the memory disk.
- Load the requested page into memory after reading it from the disk.
These two activities take place when pages are loading and thus consumes a lot of time as compared to reading in an active memory leading to occurence of page faults.
Solving MongoDB Page Faults
The following are some ways through which one can solve page faults:
- Scaling vertically to devices with sufficient RAM or scaling Horizontally: When there is insufficient RAM for a given dataset then the correct approach is to increase RAM memory by scaling vertically to devices with more RAM so as to add more resources to the server. Vertical scaling is one of the best and effortless ways of boosting MongoDB performance by not spreading the load among multiple servers. Inasmuch as scaling vertically adds more RAM, scaling horizontally enables addition of more shards to a sharded cluster. In simple terms, horizontal scaling is where the database is divided into various chunks and stored in multiple servers. Horizontal scaling enables the developer to add more servers to the fly and this boosts database performance greatly as it does not incur zero downtime thus. Vertical scaling and horizontal scaling reduces solve occurence of page fault by increasing the memory that one works while working with the database.
- Index data properly: Use of appropriate indexes so as to ensure that there are efficient queries that do not cause collection scans. Proper indexing ensures that the database does not iterate over each document in a collection and thus solving possible occurrence of page fault error. Collection scan causes a page fault error because the whole collection is inspected by the query engine as it is read into the RAM. Most of the documents in the collection scan are not returned in the app and thus causes unnecessary page faults for each subsequent query that is not easy to evade. In addition, excess indexes can also lead to inefficient use of RAM this can lead to page fault error. Therefore, proper indexing is paramount if a developer intends to solve page fault errors. MongoDB offers assistance in determining the indexes that one should deploy when using the database. They offer both Slow Query Analyzer that give needed information on how to index for users and shared users.
- Migrating to the latest version of MongoDB then moving the application to WiredTiger. This is necessary if you intend to avoid experiencing page fault error since page faults are only common in MMAPv1 storage engines as opposed to newer versions and WiredTiger. MMAPv1 storage engine has been deprecated and MongoDB no longer supports it. WiredTiger is the current default storage engine in MongoDB and it has MultiVersion Concurrency Control which makes it much better in comparison to MMAPv1 storage engine. With WiredTiger MongoDB can use both filesystem cache and WiredTiger internal cache which has a very large size of either 1GB (50% 0f ( RAM – 1GB)) or 256 MB.
- Keep track of the total RAM available for use in your system. This can be done by using services like New Relic monitoring Google Cloud Monitoring. Moreover, BindPlane can be utilized with the mentioned cloud monitoring services. Using a monitoring system is a proactive measure that enables one to counter page faults before they happen rather than react to occuring page faults. BindPlane allows the monitor to set up constant alerts for occurence of page faults, the alerts also makes one aware of the number of indexes, index size and file size.
- Ensuring that data is configured into the prevailing working set and will not use more RAM than the recommended. MongoDB is a database system that works best when frequently accessed data and indexes can fit perfectly in The assigned memory. RAM size is a vital aspect when optimizing the performance of the database therefore one must ensure that there is always enough RAM memory before deploying the app.
- Distributing load between mongod instances by adding shards or deploying a sharded cluster. It is of vital significance to enable shading where the targeted collection is located. First, connect to mongos in the mongo shell and use the method below.
-
sh.shardCollection()Then create an index by this method.
db.collection.createIndex(keys, options)The created index supports the shard key, that is if the collection created had already received or stored some data. However, if the collection has no data (empty) then use the method below to index it as part of the ssh.shardCollection: sh.shardCollection()
- This is followed by either of the two strategies provided by mongoDB.
- Hashed shading
sh.shardCollection(". ", { : "hashed" } ) - Range-based shading
sh.shardCollection(". ", { : 1, ... } )
- Hashed shading
-
How to Prevent MongoDB Page Faults
- Add shards or deploy sharded cluster to distribute load
- Have enough RAM for your application before deploying it
- Move to MongoDB newer versions then proceeds to WiredTiger
- Scale vertically or Horizontally for a device with more RAM
- Use Recommended RAM and keep track of used RAM space
Conclusion
A few number of page faults (Alone) take a short time however, in a situation where there are numerous page faults (aggregate), it’s an indication that the database is reading a large number of data in the disk. When aggregate happens there will be more MongoBD read locks that will lead to a page fault .
When using MongoDB, the size of RAM for the system and number of queries can greatly influence the application performance. The performance of an application in MongoDB relies greatly on available RAM on the physical memory which impacts on the time it takes for the application to make a single query. With sufficient RAM occurence of page faults are reduced and application performance is enhanced.



