blog
Database Load Balancing in a Multi-Cloud Environment

Multi-cloud environments are a very good solution to implement disaster recovery and very high level of high availability. They help to ensure that even a full outage of a whole region of one cloud provider will not impact your operations because you can easily switch your workload to another cloud.
Utilizing multi-cloud setups also allows you to avoid vendor lock-in, as you are building your environment using common building blocks that can be reused in every environment (cloud or on-prem) and not something strictly tied to the particular cloud provider.
Load Balancers are one of the building blocks for any highly available environment, database clusters are no different. Designing load balancing in a multi-cloud environment might be tricky, in this blog post we will try to share some suggestions about how to do that.
Designing a Load Balancing Tier for Multi-Cloud Database Clusters
For starters, what’s important to keep in mind is that there will be differences in how you want to design your load balancer based on the type of the database cluster. We will discuss two major types: clusters with one writer and clusters with multiple writers.
Clusters with one writer are, typically, replication clusters where, by design, you have only one writable node, the master. We can also put here multi-writer clusters when we want to use just one writer at the same time. Clusters with multiple writers are multi-master setups like Galera Cluster for MySQL, MySQL Group Replication or Postgres-BDR. The database type may make some small differences but they are not as significant as the type of the cluster, thus we’ll stick to the more generic approach and try to keep the broader picture.
The most important thing we have to keep in mind while designing the load balancing tier is its high availability. This may be especially tricky for the multi-cloud clusters. We should ensure that the loss of the connectivity between the cloud providers will be handled properly.
Multi-Cloud Load Balancing – Multi-Writer Clusters
Let’s start with multi-writer clusters. The fact that we have multiple writers makes it easier for us to design load balancers. Write conflicts are typically handled by the database itself therefore, from the load balancing standpoint, all we need to do is fire and forget – send the traffic to one of the available nodes and that’s pretty much it. What’s also great about multi-writer clusters is that they, typically, are quorum-based and any kind of a network partitioning should be handled pretty much automatically. Thanks to that we don’t have to be worried about split brain scenarios – that makes our lives really easy.
What we have to focus on is the high availability of the load balancers. We can achieve that by leveraging highly available load balancing options. Again, we’ll try to keep this blog post generic but we are talking here about tools like Elastic Load Balancing in AWS or Cloud Load Balancing in GCP. Those products are designed to be highly available and scalable and while they are not designed to work with databases, we can quite easily use them to provide load balancing in front of our loadbalancer tier. What’s needed is a couple of scripts to ensure that cloud load balancers will be able to run health checks against database load balancers of our choosing. An example setup may look like this:
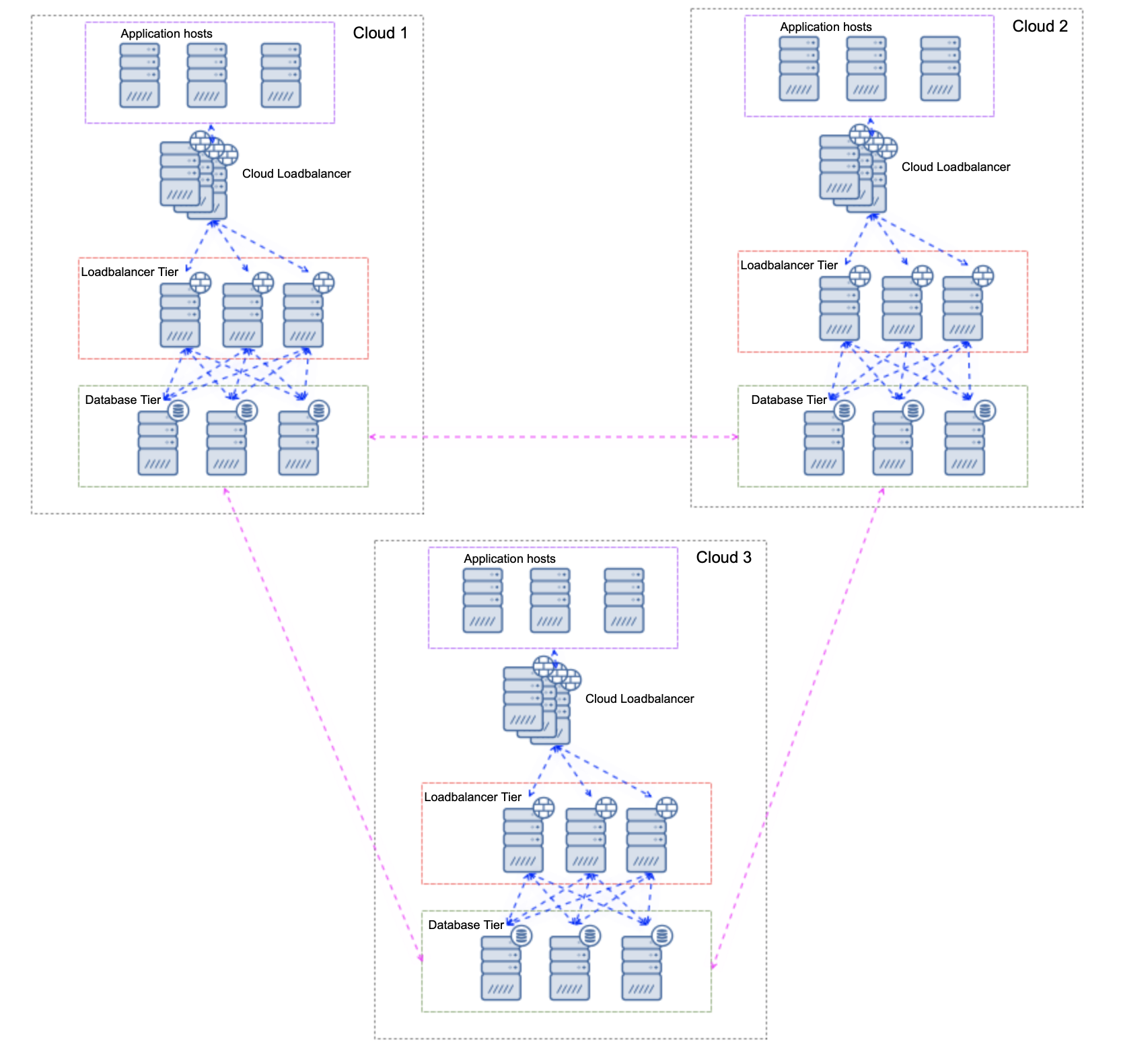
What we see here is an environment that consists of three clouds (it can be multiple regions from the same cloud provider, multiple cloud providers for multi-cloud environment or even hybrid cloud that connects multiple cloud providers and on-prem data centers. Each environment is built in a similar way. There are application hosts that connect to the first layer of the load balancers. As we mentioned earlier, those have to be highly available load balancers like those provided by GCP or AWS. For on-prem this can be delivered by one of Virtual IP-based solutions like Keepalived. Traffic then is sent to the dedicated database load balancing tier – ProxySQL, MySQL Router, MaxScale, pgbouncer, HAProxy or similar. That tier is tracking the state of the databases colocated in the same segment and sends the traffic towards them.
Multi-Cloud Load Balancing – Single Writer Setups
This kind of setup is definitely more complex to design given that we have to keep in mind that we can have only one writer in the mix. Main challenge would be to be able to consistently keep track of the writer, ensuring that all of the load balancers will send the writes to the correct destination. There are several ways of doing this and we’ll give you some examples. For starters good old DNS. DNS can be used to store the hostname that is pointing to the writer. Load Balancers then can be configured to send their writes to, for example, writer.databases.mywebsite.com. Then it will be up to the failover automation to ensure that the ‘writer.databases.mywebsite.com’ will be updated after the failover and that it points towards the correct database node. This has pros and cons, as you may expect. DNS is not really designed with low latency in mind therefore changing the records comes with a delay. TTL can be reduced, sure, but will never be real-time.
Another option is to use service discovery tools. Solutions like etc.d or Consul can be used to store information about the infrastructure and, among others, information which node performs the role of the writer. This information can be utilized by load balancers, helping them to point write traffic to the correct destination. Some of the service discovery tools can expose infrastructure information as DNS records, which allows you to combine both solutions if you feel that’s needed.
Let’s take a look at an example of an environment where we have a single writer in one of the cloud providers.
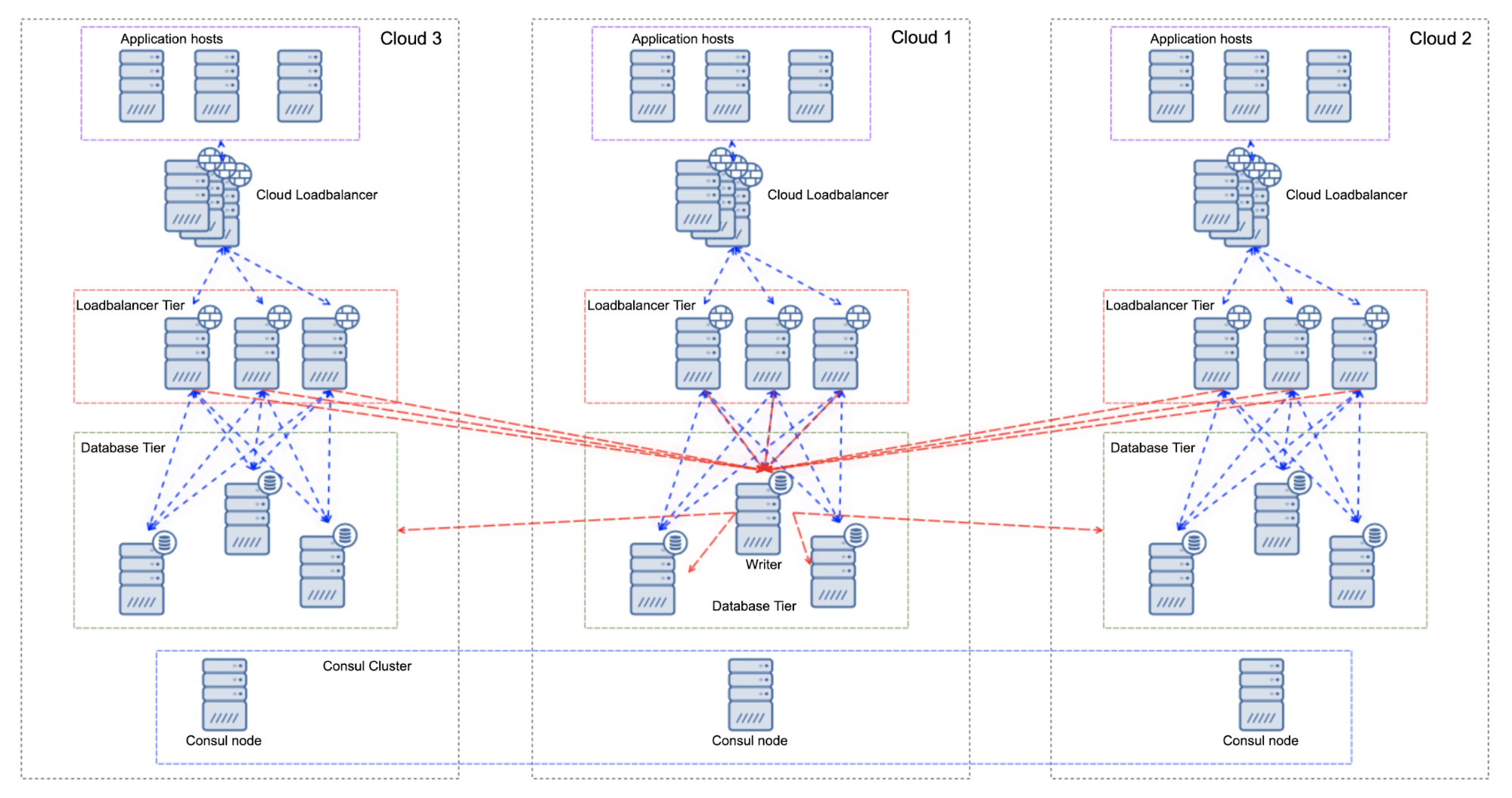
What we have here are three data centers, cloud providers or regions. In one of them we have a writer and all of the writes coming from all load balancers in all cloud providers will be directed to that writer node. Reads are being distributed across other database nodes in the same location. The Consul cluster has been deployed across the whole infrastructure, storing the information about the writer node. Consul cluster can, eventually, be also used to reduce the risk that comes with a split-brain. Scripts can be prepared to track the state of Consul nodes and, should the node lost connectivity with the rest of the Consul cluster, it may assume that the network partitioning has happened and take some actions as needed (or, even more importantly, do not take some actions like promoting new writer). Should the writer fail, an automated failover solution should check the state of the Consul node to make sure that network is working properly. If yes, a new writer should be promoted among all the nodes. Up to you is to decide if it is feasible to failover to nodes from multiple clouds or would you prefer to promote one of the nodes colocated with the failed writer. Once failover is completed, the Consul should be updated with information about the new location to send writes to. Load Balancers will pick it up and the regular flow of traffic will be restored.
Conclusion
As you can see, designing a proper load balancing solution for databases in a multi-cloud environment, even if not trivial, it is definitely possible. This blog post should give you an overview of the challenges you will face and solutions to them. We hope it will make your job in implementing such a setup way easier.



