blog
Database Automation Best Practices in the Healthcare Industry

Database management at scale can’t be done without proper automation techniques. Long gone are the days when database administrators were naming their database servers, spend days tuning and tweaking the configuration, ensuring that everything works smoothly. Now, clusters are spun every minute, and data is provisioned automatically at scale. The Healthcare industry has its own set of problems and requirements to deal with. Let’s take a look at some of these and discuss some of the best practices to handle them.
First of all, a bit of a disclaimer. We are not discussing any particular environment or setup; we acknowledge that the exact requirements may differ and are dependent on those factors we’ve just mentioned. Therefore, we may be missing some important considerations relevant to your specific setup. We’ll try our best to cover as much as we can, though.
Database High Availability in Healthcare
As usual, how high the availability should be depends on the requirements. For the healthcare industry this typically is quite a must-have. Whatever service databases are backing up, they are usually quite important. It can be anything from administrative data through personal records or even applications dealing with data coming from the equipment. In all of such cases it is paramount to be able to respond to the failure in a timely manner and be able to recover the services as soon as possible, ensuring that no data loss has happened. This pretty much means the process of recovering from node failure has to be automated.
There are two main types of database setup you may want to consider: replication (one writer, multiple replicas to read from) and multi-master (theoretically all nodes can handle the writes). Both setups have their pros and cons, both will have different performance characteristics. Regarding the high availability, though, the most important difference is the way failover works in both cases.
Let’s take a look at the asynchronous replication.
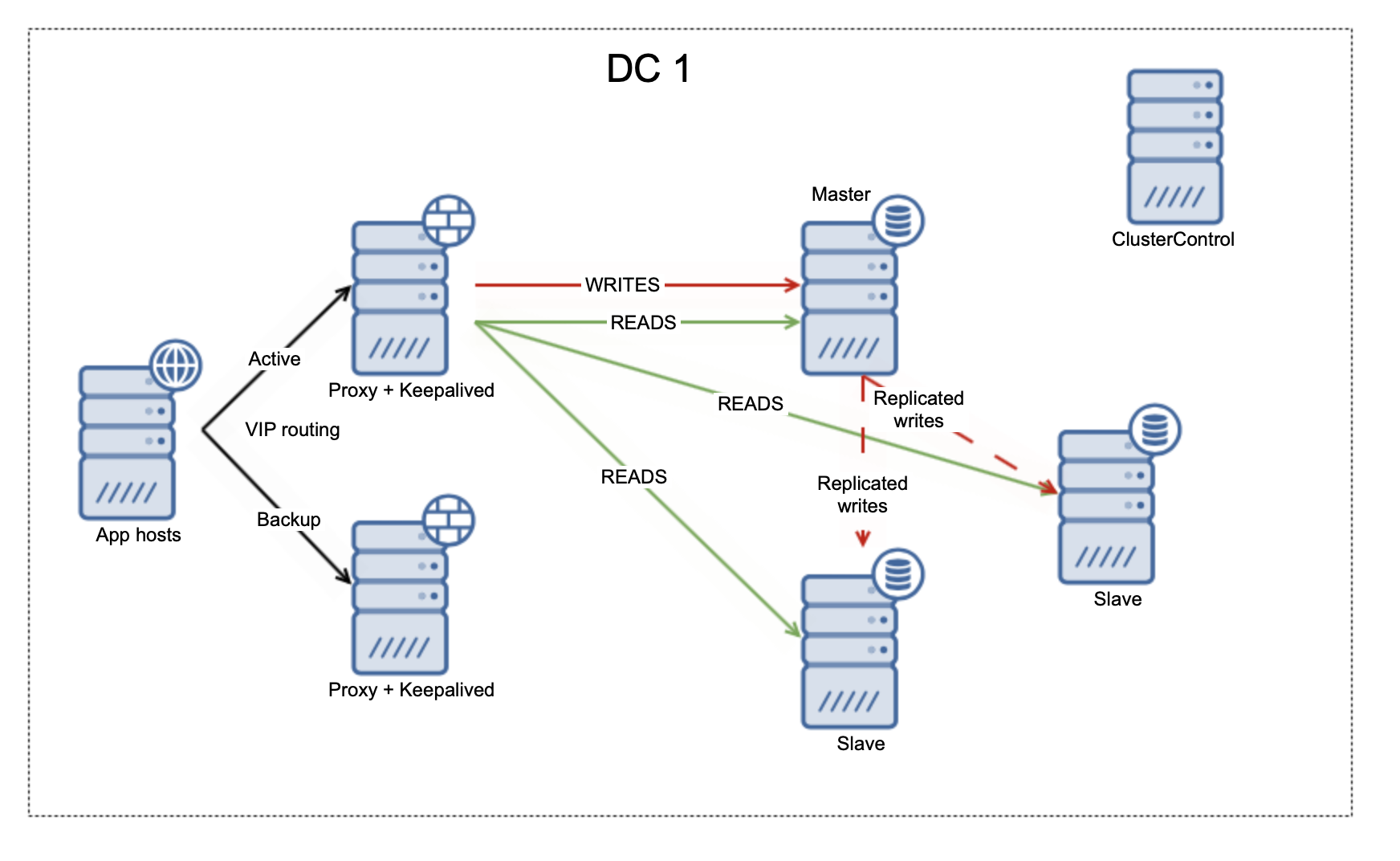
We have here a single writer (master) and one or more replicas that can be used to read the data.
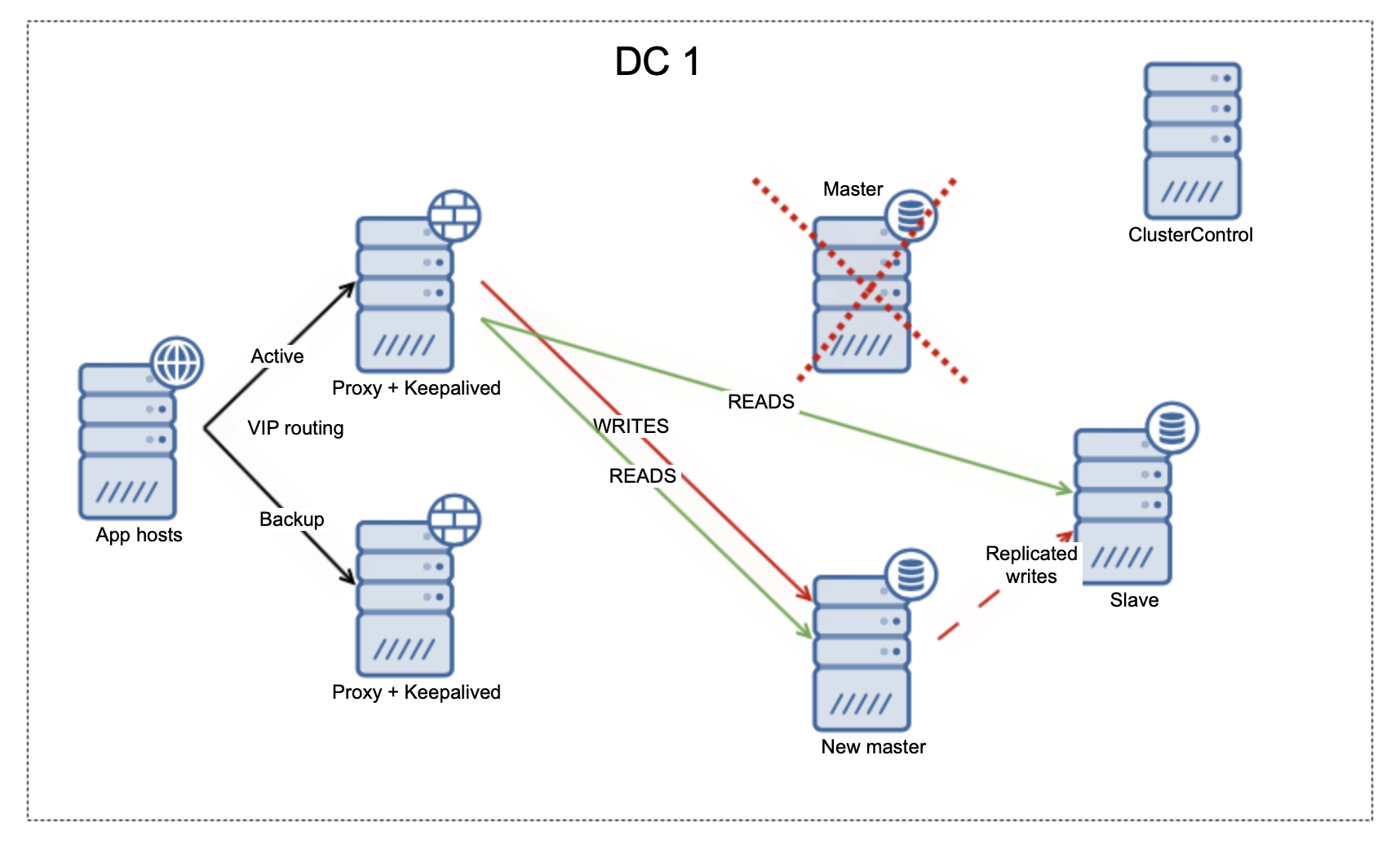
Should the master go down, the automated scripts should ensure that the rest of the nodes in the topology will catch up and replay any missing transactions. Then replicas should be examined to determine the best master candidate. Finally, a new master should be promoted and new replication topology should emerge.
For the multi-master environment things are simpler.
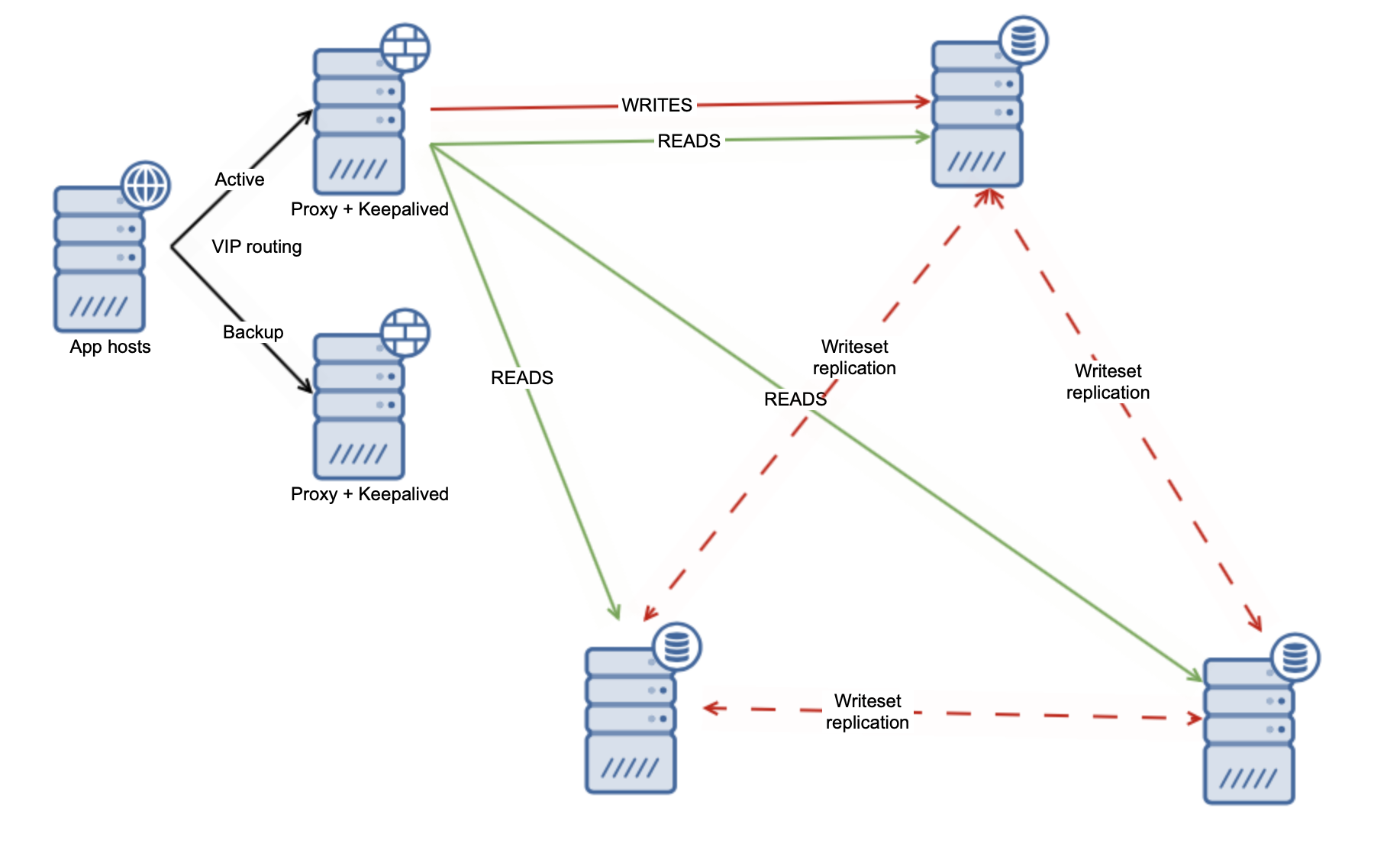 First of all, theoretically speaking all of the nodes should be able to execute writes. It doesn’t mean they all should, but the option is there. Additionally, all nodes should be at the same point regarding the state of the data – replication is synchronous. This makes it very easy to deal with the failure of one node. Let’s assume that we have as well one writer node, (it is a common way of ensuring there will be no write conflicts to solve across the cluster).
First of all, theoretically speaking all of the nodes should be able to execute writes. It doesn’t mean they all should, but the option is there. Additionally, all nodes should be at the same point regarding the state of the data – replication is synchronous. This makes it very easy to deal with the failure of one node. Let’s assume that we have as well one writer node, (it is a common way of ensuring there will be no write conflicts to solve across the cluster).
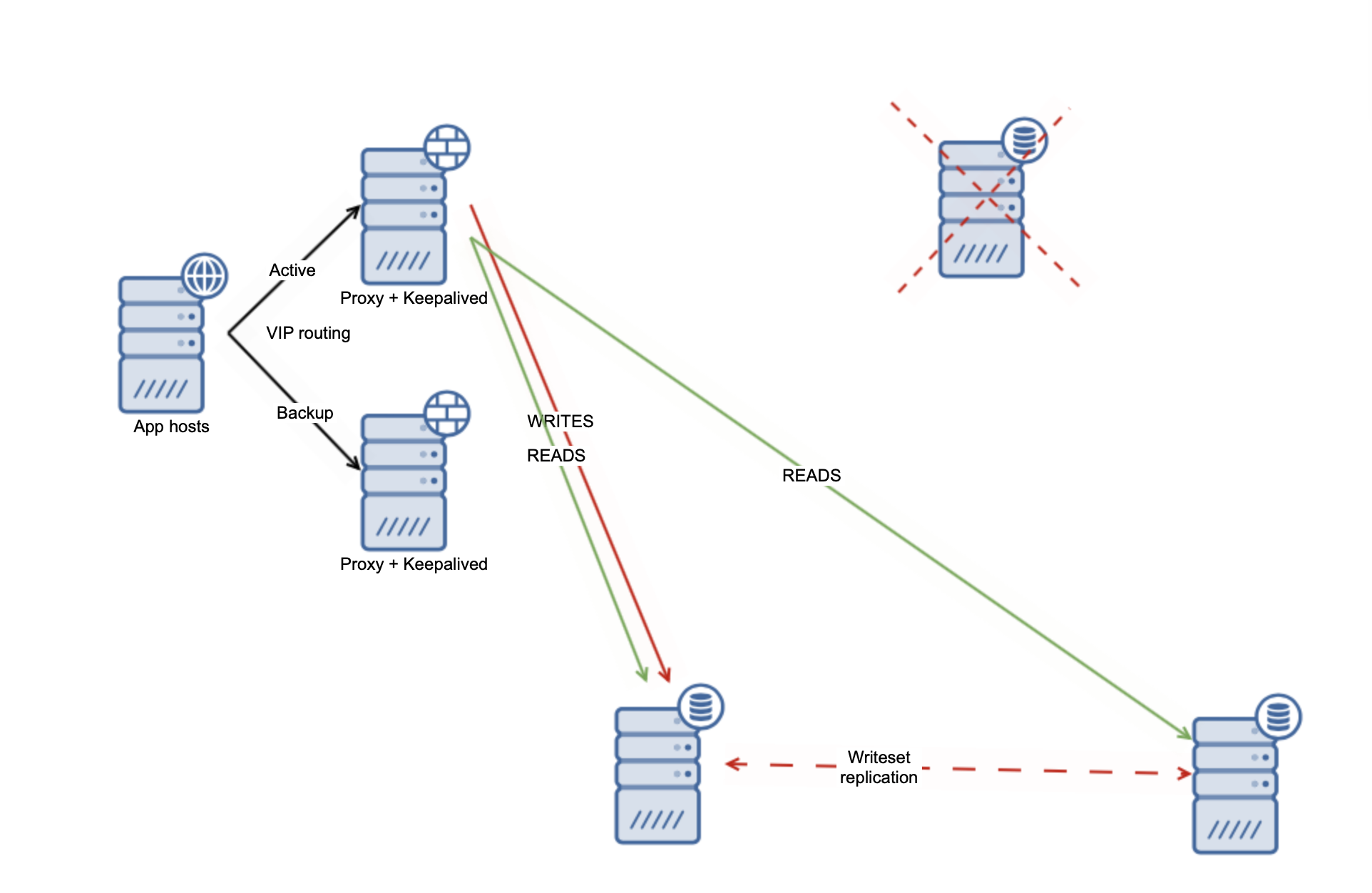
In that case, pretty much all that has to be done is to move the writes to another node in the cluster. It will take over the writer role and cluster should be able to commence operations. Here we even don’t need a specific mechanism to handle the writer failure as most of the loadbalancers will be able to deal with such scenarios on their own.
Automated Backups
Backups are boring. Majority of the people will just write a backup script, run it from a cron and that’s just that. What is more to automate you may ask? Sure, writing automated scripts that run backups is an obvious choice but there’s more to backup automation than that. Backup itself is useless if it doesn’t work. The problem is that you don’t really know if it is going to work unless you actually try to restore it. Only then you can confirm if the backup is reliable or not. Sure, you can just assume your backups will work but if the reality will be different and you will learn it the hard way, when you will actually have to restore your backup, you will be in deep trouble.
Backup verification is a must-have for every production deployment. Ideally, every backup will be tested. It can be done in a process of deploying or rebuilding nodes but if you don’t do it on a regular basis, you should come up with a separate process. Take the last backup. Have one separate node that you can use for backup verification. Restore the backup on that node. Start the database, bring the node into the replication topology. See if the database can be started and if it can catch up with the rest of the nodes of the cluster. If yes, your backup works just fine. If not, you need to see what went wrong.
When working on a backup verification, please make sure you include all the steps that you have to perform for the normal backup restore process. If you have backup encrypted and the key to decrypt it is stored in a safe spot, make sure it is actually used for the backup verification as well. See if you can encrypt the backup, decompress it. It is crucial to test the backup after every change in the backup process. If you add a new step, if you change the configuration of the backup tool, make sure you tested at least a couple of backups before you sign it off as a properly working backup process.
Deployment and Scaling
Deployment is another area where one may want to implement automation. Being able to deal with fluctuating load requires database nodes to be added and removed on the fly – you cannot leave it for users to handle. What should be done instead is to create a set of scripts that can be used to quickly and efficiently spin up new nodes in the cluster. This is of utmost importance – you want to be able to act quickly when your application generates more load on the database tier. To reduce the load on the existing nodes, most of the time you will use backups to provision the data. Thanks to them only a minimal set of data (especially if you use a Point In Time Recovery) will be accessed on the failed node. As we mentioned before, deployment is a great way of verifying your backups – if you can properly scale up while provisioning data from backup, your backups are good to go.
Having the automated way of deploying the new database nodes can also be very useful in a disaster recovery scenario. Obviously, you should not allow for the disaster to happen but if it happened anyway, having a proper plan how to recover from scratch and having scripts that will help you to accomplish this task is something great.
Database Security
Healthcare industry is all about security as the databases store huge amounts of personal information, starting from the address, through financial data and other PII up to the medical records. Different security standards that you have to comply with require you to enable additional logs, perform security audits and so on. Not all can be automated but the majority of the actions should be done in an automated manner. Have you tested the users and their credentials in the database? Do all of them have properly set role-based access control? Do all of the users have proper passwords defined? This is something that you should be able to audit using automated scripts and tools.
Logs – are there any errors that would point towards a potential security issue? What about the access to the data. When you build a staging environment, do you use existing data? Do you obscure any PII and other data that should be kept safe?
Final Thoughts
As you can imagine, there’s alot going on when it comes to databases and automation.Please refer to our case study on how The Royal National Orthopaedic Hospital (RNOH) achieved database high availability with ClusterControl. We hope you found this blog informative and useful.



