blog
Comparing Data Stores for PostgreSQL – MVCC vs InnoDB

One of the primary requirements for any database is to achieve scalability. It can only be achieved if the contention (locking) is minimized as much as possible, if not removed all together. As read / write / update / delete being some of the major frequent operations happening in the database so it is very important for these operations to go on concurrently without getting blocked. In order to achieve this, most of the major databases employ a concurrency model called Multi-Version Concurrency Control, which reduces contention to a bare minimum level.
What is MVCC
Multi Version Concurrency Control (here onwards MVCC) is an algorithm to provide fine concurrency control by maintaining multiple versions of the same object so that READ and WRITE operation do not conflict. Here WRITE means UPDATE and DELETE, as newly INSERTed record anyway will be protected as per isolation level. Each WRITE operation produces a new version of the object and each concurrent read operation reads a different version of the object depending on the isolation level. Since read and write both operating on different versions of the same object so none of these operations required to completely lock and hence both can operate concurrently. The only case where the contention can still exist is when two concurrent transaction tries to WRITE the same record.
Most of the current major database supports MVCC. The intention of this algorithm is maintaining multiple versions of the same object so the implementation of MVCC differs from database to database only in terms of how multiple versions are created and maintained. Accordingly, corresponding database operation and storage of data changes.
Most recognized approach to implements MVCC is the one used by PostgreSQL and Firebird/Interbase and another one is used by InnoDB and Oracle. In subsequent sections, we will discuss in detail how it has been implemented in PostgreSQL and InnoDB.
MVCC In PostgreSQL
In order to support multiple versions, PostgreSQL maintains additional fields for each object (Tuple in PostgreSQL terminology) as mentioned below:
- xmin – Transaction ID of the transaction which inserted or updated the tuple. In case of UPDATE, a newer version of the tuple gets assigned with this transaction ID.
- xmax – Transaction ID of the transaction which deleted or updated the tuple. In case of UPDATE, a currently existing version of tuple gets assigned this transaction ID. On a newly created tuple, the default value of this field is null.
PostgreSQL stores all data in a primary storage called HEAP (page of by default size 8KB). All the new tuple gets xmin as a transaction which created it and and older version tuple (which got updated or deleted) gets assigned with xmax. There is always a link from the older version tuple to the new version. The older version tuple can be used to recreate the tuple in case of rollback and for reading an older version of a tuple by READ statement depending on the isolation level.
Consider there are two tuples, T1 (with value 1) and T2 (with value 2) for a table, the creation of new rows can be demonstrated in below 3 steps:
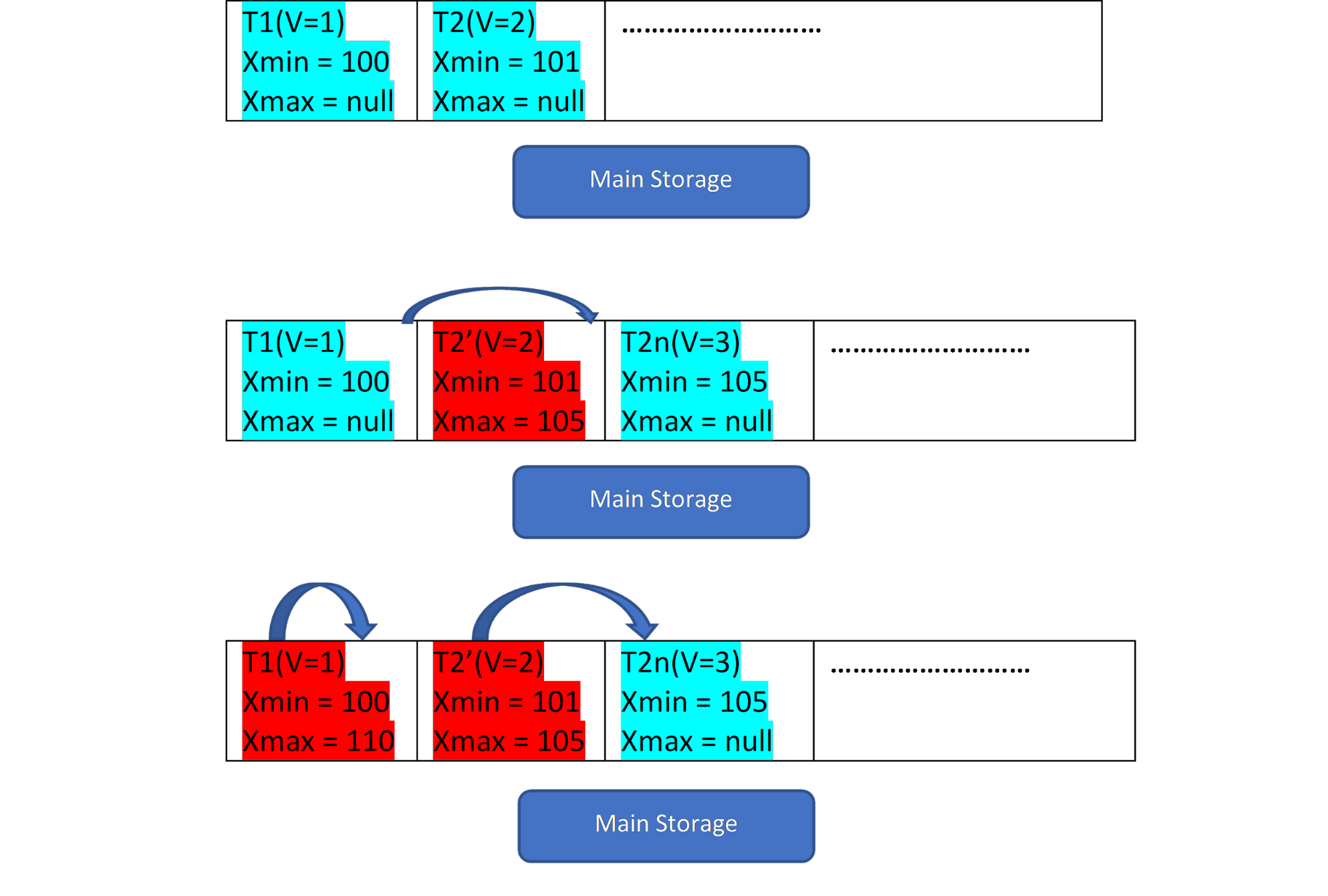
As seen from the picture, initially there are two tuples in the database with values 1 and 2.
Then, in as per second step, the row T2 with value 2 gets updated with the value 3. At this point, a new version is created with the new value and it just gets stored as next to the existing tuple in the same storage area. Before that, the older version gets assigned with xmax and points to latest version tuple.
Similarly, in the third step, when the row T1 with value 1 gets deleted, then, the existing row gets virtually deleted (i.e. it just assigned xmax with the current transaction) in the same place. No new version gets created for this.
Next, let’s see how each operation creates multiple versions and how the transaction isolation level maintained without locking with some real examples. In all the below example by default “READ COMMITTED” isolation is used.
INSERT
Every time a record gets inserted, it will create a new tuple, which gets added to one of the pages belonging to the corresponding table.
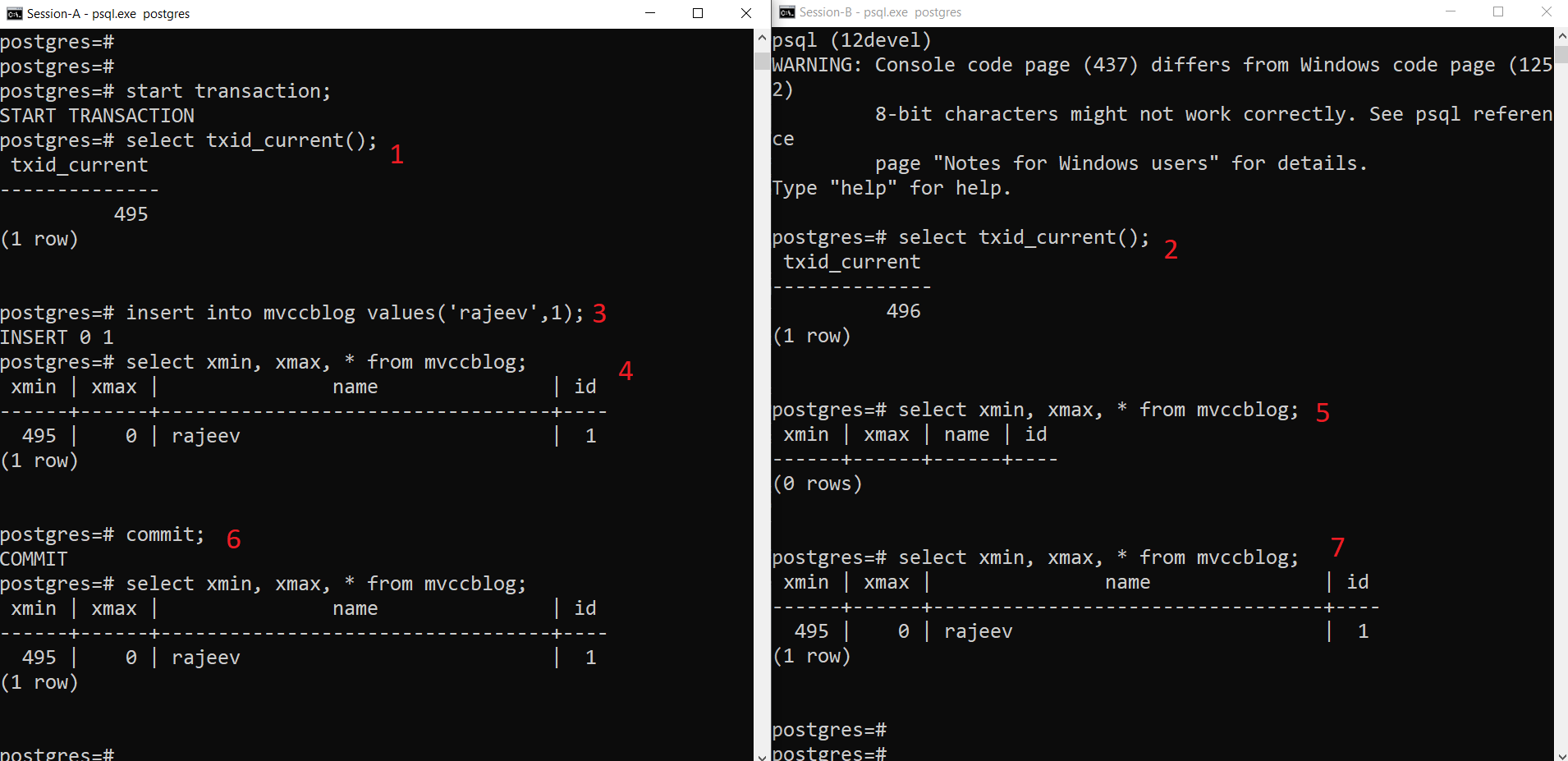
As we can see here stepwise:
- Session-A starts a transaction and gets the transaction ID 495.
- Session-B starts a transaction and gets the transaction ID 496.
- Session-A insert a new tuple (gets stored in HEAP)
- Now, the new tuple with xmin set to current transact ID 495 gets added.
- But the same is not visible from Session-B as xmin (i.e. 495) still not committed.
- Once Committed.
- Data is visible to both sessions.
UPDATE
PostgreSQL UPDATE is not “IN-PLACE” update i.e. it does not modify the existing object with the required new value. Instead, it creates a new version of the object. So, UPDATE broadly involves the steps below:
- It marks the current object as deleted.
- Then it adds a new version of the object.
- Redirect the older version of the object to a new version.
So even though a number of records remain the same, HEAP takes space as if one more record got inserted.
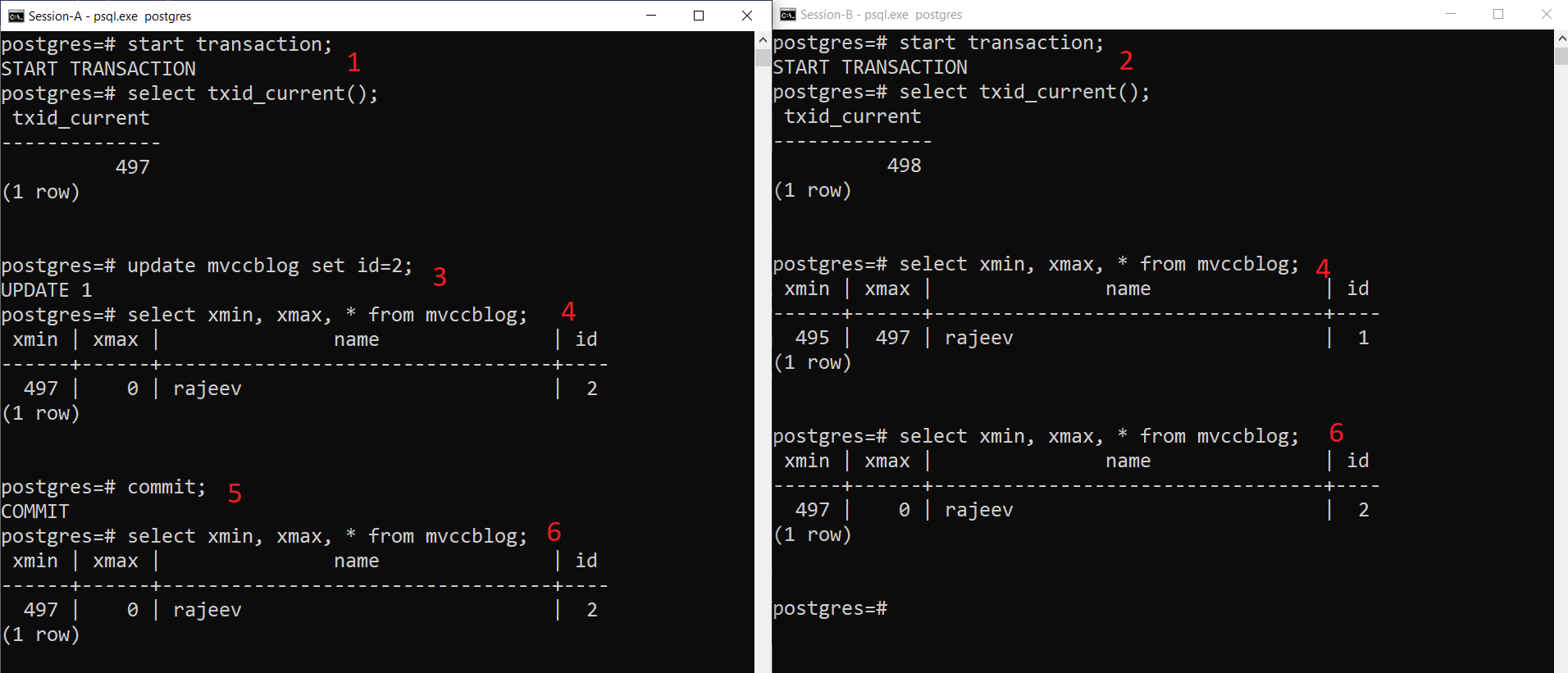
As we can see here stepwise:
- Session-A starts a transaction and gets the transaction ID 497.
- Session-B starts a transaction and gets the transaction ID 498.
- Session-A updates the existing record.
- Here Session-A sees one version of the tuple (updated tuple) whereas Session-B sees another version (older tuple but xmax set to 497). Both tuple version gets stored in the HEAP storage (even the same page depending on the space availability)
- Once Session-A commits the transaction, the older tuple gets expired as xmax of the older tuple is committed.
- Now both sessions see the same version of the record.
DELETE
Delete is almost like UPDATE operation except it does not have to add a new version. It just marks the current object as DELETED as explain in UPDATE case.
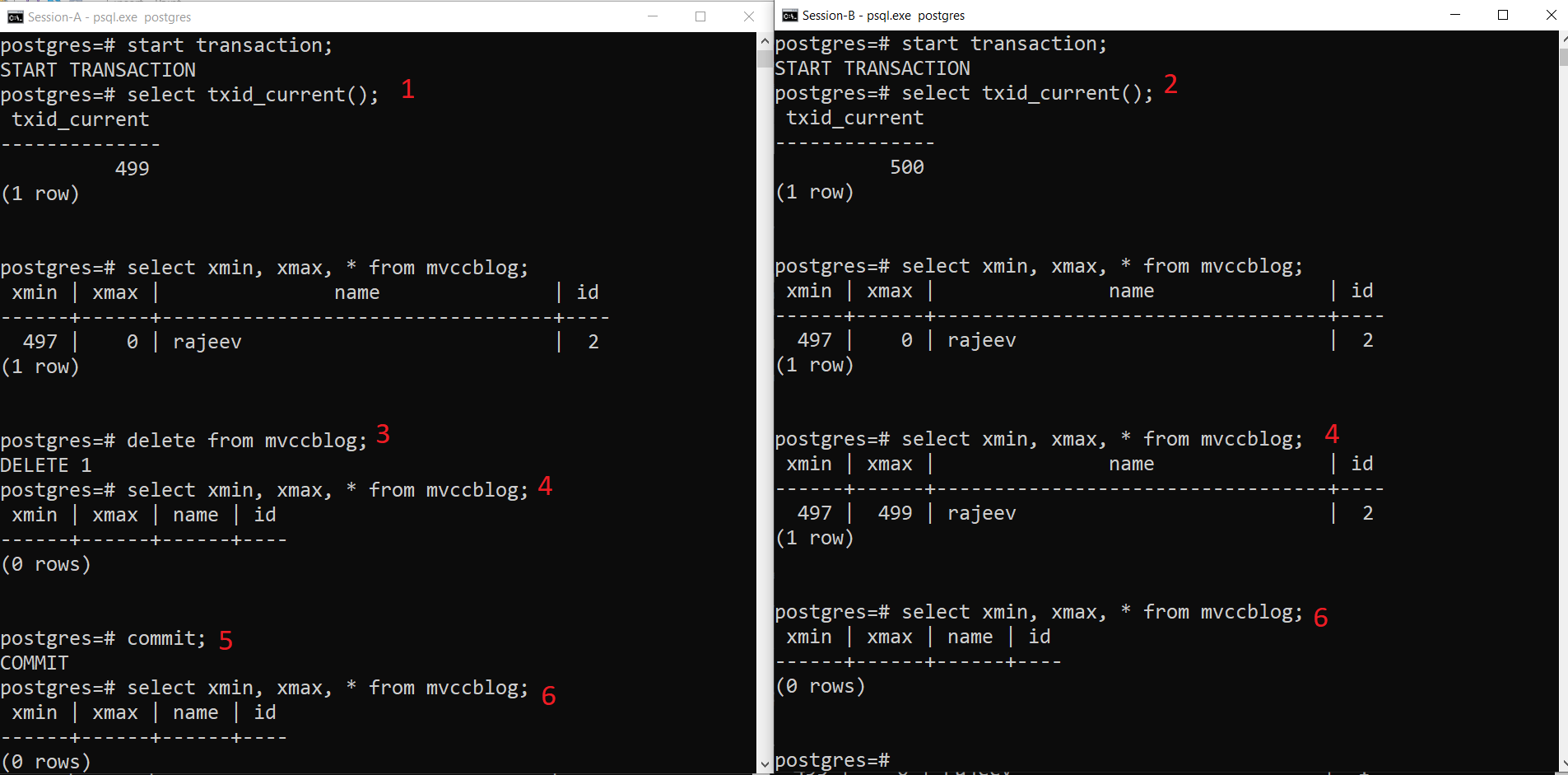
- Session-A starts a transaction and gets the transaction ID 499.
- Session-B starts a transaction and gets the transaction ID 500.
- Session-A deletes the existing record.
- Here Session-A does not see any tuple as deleted from the current transaction. Whereas Session-B sees an older version of the tuple (with xmax as 499; the transaction which deleted this record).
- Once Session-A commits the transaction, the older tuple gets expired as xmax of the older tuple is committed.
- Now both sessions do not see deleted tuple.
As we can see, none of the operations removes the existing version of the object directly and wherever needed it adds an additional version of the object.
Now, let’s see how SELECT query gets executed on a tuple having multiple versions: SELECT needs to read all versions of tuple till it finds the appropriate tuple as per isolation level. Suppose there was tuple T1, which got updated and created new version T1’ and which in turn created T1’’ on update:
- SELECT operation will go through heap storage for this table and first check T1. If T1 xmax transaction committed, then it moves to the next version of this tuple.
- Suppose now T1’ tuple xmax is also committed, then again it moves to next version of this tuple.
- Finally, it finds T1’’ and see that xmax is not committed (or null) and T1’’ xmin is visible to the current transaction as per isolation level. Finally, it will read T1’’ tuple.
As we can see, it needs to traverse through all 3 versions of the tuple in order to find the appropriate visible tuple till expired tuple gets deleted by the garbage collector (VACUUM).
MVCC In InnoDB
In order to support multiple versions, InnoDB maintains additional fields for each row as mentioned below:
- DB_TRX_ID: Transaction ID of the transaction which inserted or updated the row.
- DB_ROLL_PTR: It is also called the roll pointer and it points to undo log record written to the rollback segment (more on this next).
Like PostgreSQL, InnoDB also creates multiple versions of the row as part of all operation but the storage of the older version is different.
In case of InnoDB, the old version of the changed row is kept in a separate tablespace/storage (called undo segment). So unlike PostgreSQL, InnoDB keeps only the latest version of rows in the main storage area and the older version is kept in the undo segment. Row versions from the undo segment are used to undo operation in case of rollback and for reading an older version of rows by READ statement depending on the isolation level.
Consider there are two rows, T1 (with value 1) and T2 (with value 2) for a table, the creation of new rows can be demonstrated in below 3 steps:
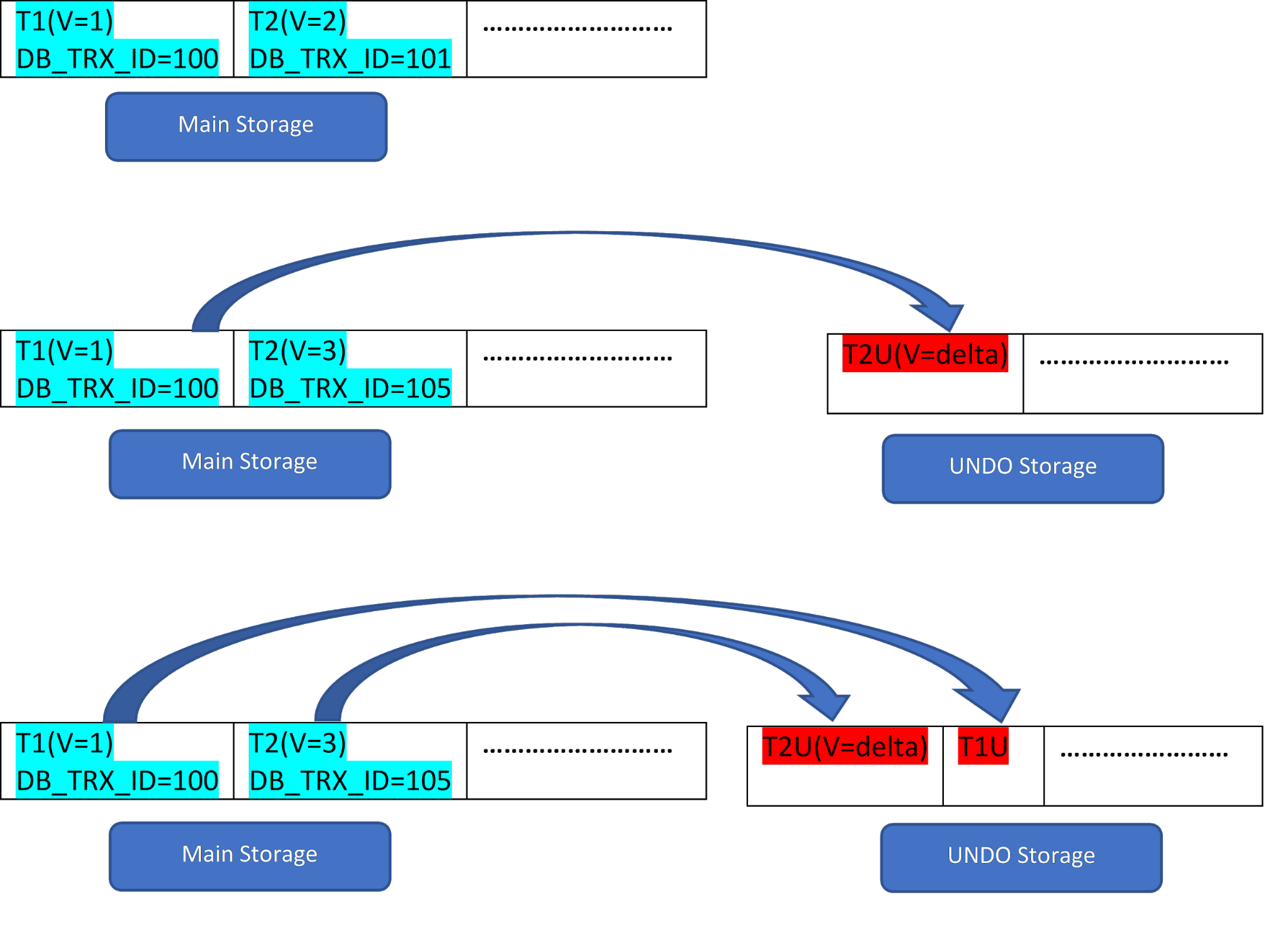
As seen from the figure, initially there are two rows in the database with values 1 and 2.
Then in as per second stage, the row T2 with value 2 gets updated with the value 3. At this point, a new version is created with the new value and it replaces the older version. Before that, the older version gets stored in the undo segment (notice the UNDO segment version has only a delta value). Also, note that there is one pointer from the new version to the older version in the rollback segment. So unlike PostgreSQL, InnoDB update is “IN-PLACE”.
Similarly, in the third step, when row T1 with value 1 gets deleted, then the existing row gets virtually deleted (i.e. it just marks a special bit in the row) in the main storage area and a new version corresponding to this gets added in the Undo segment. Again, there is one roll pointer from the main storage to the undo segment.
All operations behave in the same way as in the case of PostgreSQL when seen from outside. Just internal storage of multiple version differs.
MVCC: PostgreSQL vs InnoDB
Now, let’s analyze what are the major differences between PostgreSQL and InnoDB in terms of their MVCC implementation:
-
Size of an older version
PostgreSQL just updates xmax on the older version of the tuple, so the size of the older version remains the same to the corresponding inserted record. This means if you have 3 versions of an older tuple then all of them will have the same size (except the difference in actual data size if any at each update).
Whereas in case of InnoDB, the object version stored in the Undo segment is typically smaller than the corresponding inserted record. This is because only the changed values (i.e. differential) are written to UNDO log.
-
INSERT operation
InnoDB needs to write one additional record in the UNDO segment even for INSERT whereas PostgreSQL creates new version only in case of UPDATE.
-
Restoring an older version in case of rollback
PostgreSQL does not need to anything specific in order to restore an older version in case of rollback. Remember the older version has xmax equal to the transaction which updated this tuple. So, till this transaction id gets committed, it is considered to be alive tuple for a concurrent snapshot. Once the transaction is rollbacked, the corresponding transaction will be automatically considered alive for all transaction as it will be an aborted transaction.
Whereas in case of InnoDB, it is explicitly required to rebuild the older version of the object once rollback happens.
-
Reclaiming space occupied by an older version
In case of PostgreSQL, the space occupied by an older version can be considered dead only when there is no parallel snapshot to read this version. Once the older version is dead, then the VACUUM operation can reclaim the space occupied by them. VACUUM can be triggered manually or as a background task depending on the configuration.
InnoDB UNDO logs are primarily divided into INSERT UNDO and UPDATE UNDO. The first one gets discarded as soon as the corresponding transaction commits. The second one needs to preserve till it is parallel to any other snapshot. InnoDB does not have explicit VACUUM operation but on a similar line it has asynchronous PURGE to discard UNDO logs which runs as a background task.
-
Impact of delayed vacuum
As discussed in a previous point, there is a huge impact of delayed vacuum in case of PostgreSQL. It causes the table to start bloating and causing storage space to increase even though records are constantly deleted. It may also reach a point where VACUUM FULL needs to be done which is very costly operations.
-
Sequential scan in case of bloated table
PostgreSQL sequential scan must traverse through all older version of an object even though all of them are dead (till they are removed using vacuum). This is the typical and most talked about problem in PostgreSQL. Remember PostgreSQL stores all versions of a tuple in the same storage.
Whereas in case of InnoDB, it does not need to read Undo record unless it is required. In case all undo records are dead, then it will be only enough to read through all the latest version of the objects.
-
Index
PostgreSQL stores index in a separate storage which keeps one link to actual data in HEAP. So PostgreSQL has to update INDEX part also even though there was no change in INDEX. Though later this issue was fixed by implementing HOT (Heap Only Tuple) update but still it has the limitation that if a new heap tuple can’t be accommodated in the same page, then it fallback to normal UPDATE.
InnoDB does not have this problem as they use clustered index.
Conclusion
PostgreSQL MVCC has got few drawbacks especially in terms of bloated storage if your workload has frequent UPDATE/DELETE. So if you decide to use PostgreSQL you should be very careful to configure VACUUM wisely.
PostgreSQL community has also acknowledged this as a major issue and they have already started working on UNDO based MVCC approach (tentative name as ZHEAP) and we might see the same in a future release.



