blog
ClusterControl – Advanced Backup Management – mariabackup Part II

In the previous part we have tested backup time and effectiveness of the compression for different backup compression levels and methods. In this blog we will continue our efforts and we will talk about more settings that, probably, most of the users do not really change yet they may have a visible effect on the backup process.
The setup is the same as in the previous part: we will use MariaDB master-slave replication cluster with ProxySQL and Keepalived.
We have generated 7.6GB of data using sysbench:
sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --mysql-host=10.0.0.111 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=6033 --tables=32 --table-size=1000000 prepareUsing PIGZ
This time we are going to enable Use PIGZ for parallel gzip for our backups. As before, we will test every compression level to see how it performs.
We are storing the backup locally on the instance, the instance is configured with 4 vCPUs.
The outcome is sort of expected. The backup process was significantly faster than when we used just a single CPU core. The size of the backup remains pretty much the same, there is no real reason for it to change significantly. It is clear that using pigz improves the backup time. There is a dark side of using parallel gzip though, and it is CPU utilization:
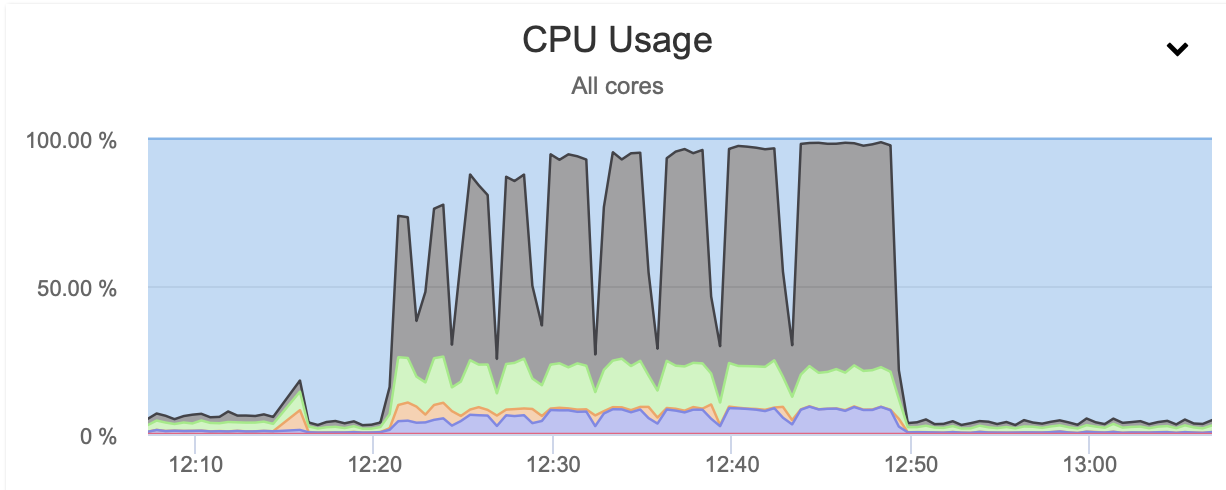
As you can see, the CPU utilization skyrockets and it reaches almost 100% for higher compression levels. Increasing CPU utilization on the database server is not necessarily the best idea as, typically, we want CPU to be available for the database. On the other hand, if we happen to have a replica that is dedicated to taking backups and, let’s say, heavier queries – a node that is not used for serving an OLTP type of traffic, we can enable parallel gzip to greatly reduce the backup time. As can be clearly seen, it is not an option for everyone but it is definitely something that you can find useful in some particular scenarios. Just keep in mind that CPU utilization is something you need to track as it will impact the latency of the queries and, as through it, it will impact the user experience – something we always should consider when working with the databases.
Xtrabackup Parallel Copy Threads
Another setting we want to highlight is Xtrabackup Parallel Copy Threads. To understand what it is, let’s talk a bit about the way Xtrabackup (or MariaBackup) works. In short, those tools perform two actions at the same time. They copy the data, physical files, from the database server to the backup location while monitoring the InnoDB redo logs for any updates. The backup consists of the files and the record of all changes to InnoDB that happened during the backup process. This, with backup locks or FLUSH TABLES WITH READ LOCK, allows to create backup that is consistent at the point of time when the data transfer has been finished. Xtrabackup Parallel Copy Threads define the number of threads that will perform the data transfer. If we set it to 1, one file will be copied at the same time. If we’ll set it to 8, theoretically up to 8 files can be transferred at once. Of course, there has to be fast enough storage to actually benefit from such a setting. We are going to perform several tests, changing Xtrabackup Parallel Copy Threads from 1 through 2 and 4 to 8. We will run tests on compression level of 6 (default one) with and without parallel gzip enabled.
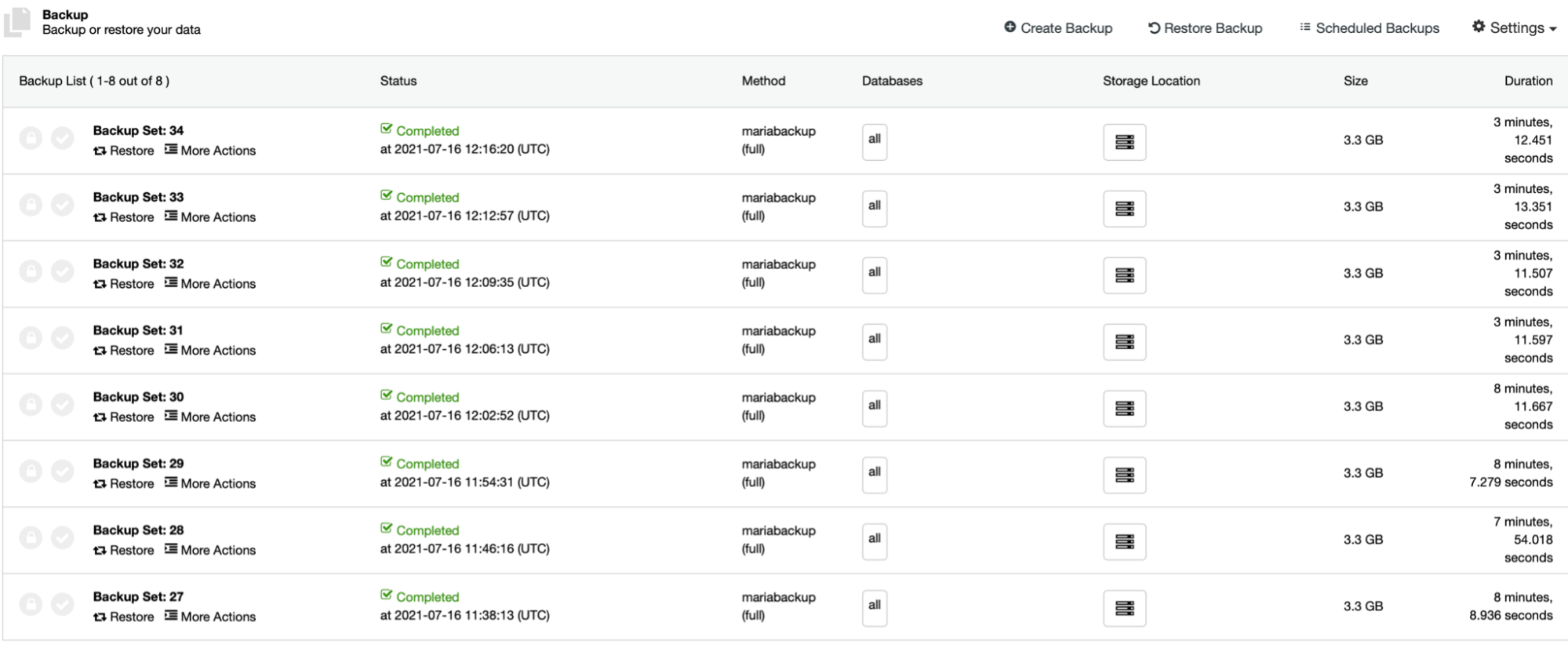
First four backups (27 – 30) have been created without parallel gzip, starting from 1 through 2, 4 and 8 parallel copy threads. Then we repeated the same process for backups 31 to 34, this time using parallel gzip. As you can see, in our case there is hardly a difference between the parallel copy threads. This will most likely be more impactful if we would increase the size of the data set. It also would improve the backup performance if we would use faster, more reliable storage. As usual, your mileage will vary and in different environments this setting may affect the backup process more than what we see here.
Network throttling
Finally, in this part of our short series we would like to talk about the ability to throttle the network usage.
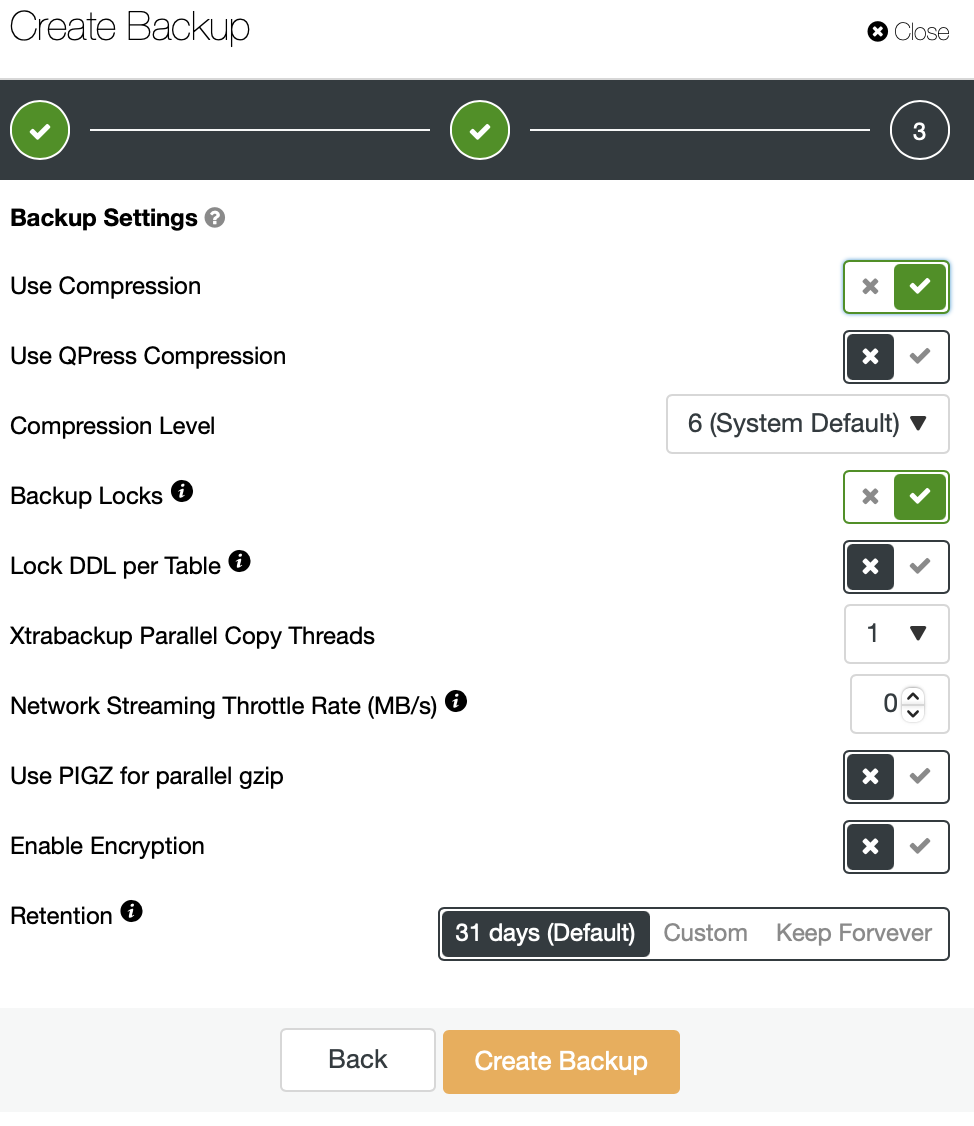
As you may have seen, backups can be stored locally on the node or it can also be streamed to the controller host. This happens over the network and, by default, it will be done “as fast as possible”.
In some cases, where your network throughput is limited (cloud instances, for example), you may want to reduce the network usage caused by the MariaBackup by setting a limit on the network transfer. When you do that, ClusterControl will use ‘pv’ tool to limit the bandwidth available for the process.
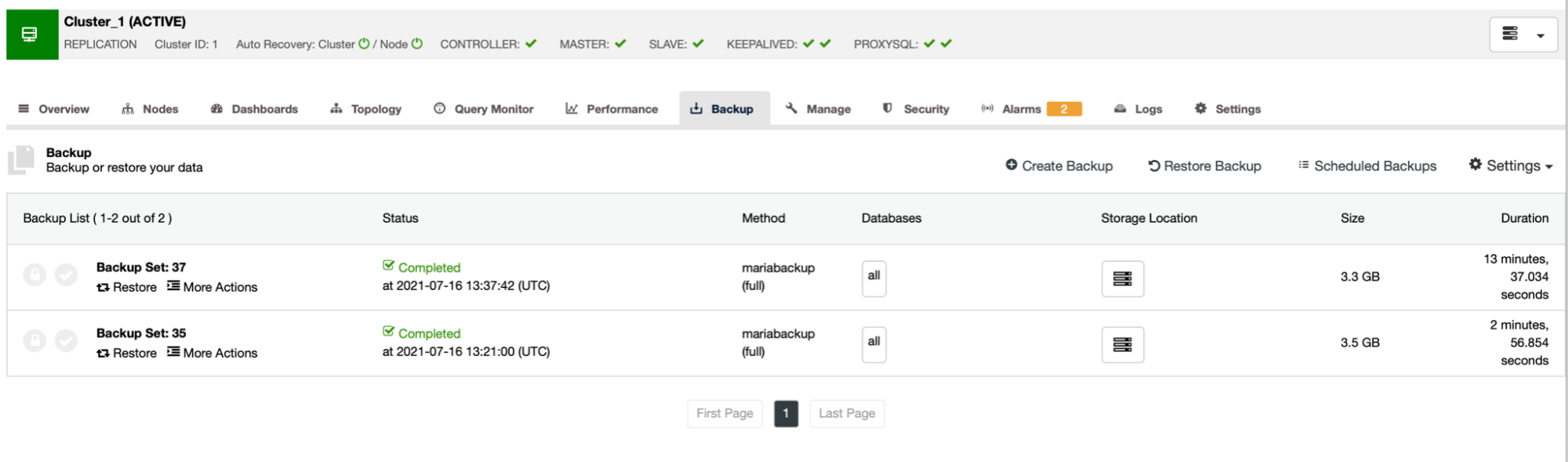
As you can see, the first backup took around 3 minutes but when we throttled the network throughput, backup took 13 minutes and 37 seconds.
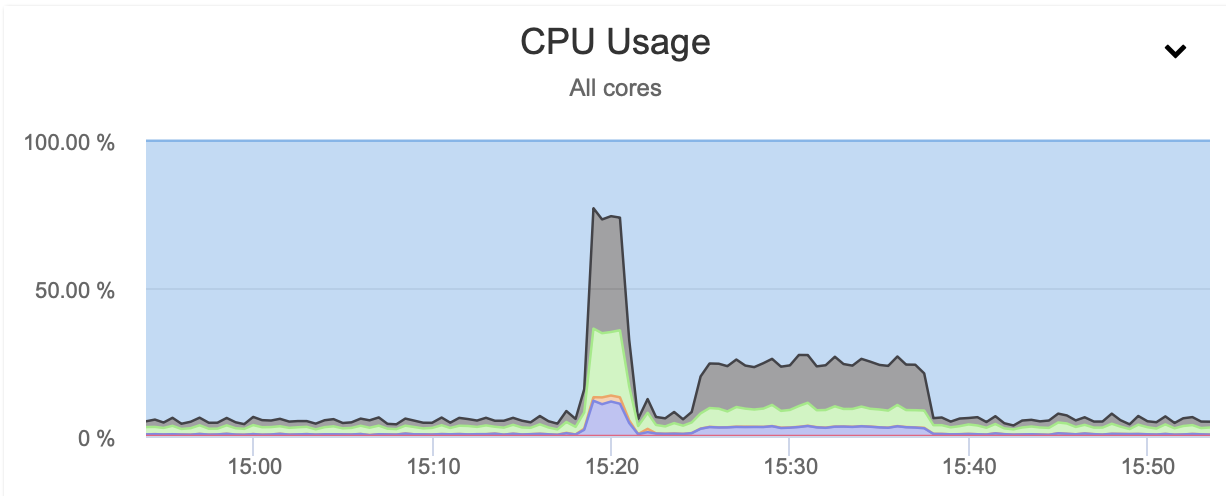
In both cases we used pigz and the compression level 1. The graph above shows that throttling the network also reduced the CPU utilization. It makes sense, if pigz has to wait for the network to transfer the data, it doesn’t have to push hard on the CPU as it has to idle most of the time.
Hopefully you found this short blog interesting and maybe it will encourage you to experiment with some of the not-so-commonly-used features and options of MariaBackup. If you would like to share some of your experience, we would like to hear from you in the comments below.



