blog
Benchmarking MongoDB – Driving NoSQL Performance

Database systems are crucial components in the cycle of any successful running application. Every organization involving them therefore has the mandate to ensure smooth performance of these DBMs through consistent monitoring and handling minor setbacks before they escalate into enormous complications that may result in an application downtime or slow performance.
You may ask how can you tell if the database is really going to have an issue while it is working normally? Well, that is what we are going to discuss in this article and we term it as benchmarking. Benchmarking is basically running some set of queries with some test data along with some resource provision to determine whether these parameters meet the expected performance level.
MongoDB does not have a standard benchmarking methodology thereby we need to resolve in testing queries on own hardware. As much as you may also get impressive figures from the benchmark process, you need to be cautious as this may be a different case when running your database with real queries.
The idea behind benchmarking is to get a general idea on how different configuration options affect performance, how you can tweak some of these configurations to get maximum performance and estimate the cost of improving this implementation. Besides, applications grow with time in terms of users and probably the amount of data that is to be served hence need to do some capacity planning before this time. After realizing a rising trend of data, you need to do some benchmarking on how you will meet the requirements of this vast growing data.
Considerations in Benchmarking MongoDB
- Select workloads that are a typical representation of today’ modern applications. Modern applications are becoming more complex every day and this is transmitted down to the data structures. This is to say, data presentation has also changed with time for example storing simple fields to objects and arrays. It is not quite easy to work with this data with default or rather sub-standard database configurations as it may escalate to issues like poor latency and poor throughput operations involving the complex data. When running a benchmark you should therefore use data which is a clear presentation of your application.
- Double check on writes. Always ensure that all data writes were done in a manner that allowed no data loss. This is to improve on data integrity by ensuring the data is consistent and is most applicable especially in the production environment.
- Employ data volumes that are a representation of “big data” datasets which will certainly exceed the RAM capacity for an individual node. When the test workload is large, it will help you predict future expectations of your database performance hence start some capacity planning early enough.
Methodology
Our benchmark test will involve some big location data which can be downloaded from here and we will be using Robo3t software to manipulate our data and collect the information we need. The file has got more than 500 documents which are quite enough for our test. We are using MongoDB version 4.0 on an Ubuntu Linux 12.04 Intel Xeon-SandyBridge E3-1270-Quadcore 3.4GHz dedicated server with 32GB RAM, Western Digital WD Caviar RE4 1TB spinning disk and Smart XceedIOPS 256GB SSD. We inserted the first 500 documents.
We ran the insert commands below
db.getCollection('location').insertMany([…],{w:0})
db.getCollection('location').insertMany([…],{w:1}) Write Concern
Write concern describes acknowledgment level requested from MongoDB for write operations in this case to a standalone MongoDB. For a high throughput operation, if this value is set to low then the write calls will be so fast thus reduce the latency of the request. On the other hand, if the value is set high, then the write calls are slow and consequently increase on the query latency. A simple explanation for this is that when the value is low then you are not concerned about the possibility of losing some writes in an event of mongod crash, network error or anonymous system failure. A limitation in this case will be, you won’t be sure if these writes were successful. On the other hand, if the write concern is high, there is an error handling prompt and thus the writes will be acknowledged. An acknowledgment is simply a receipt that the server accepted the write to process.


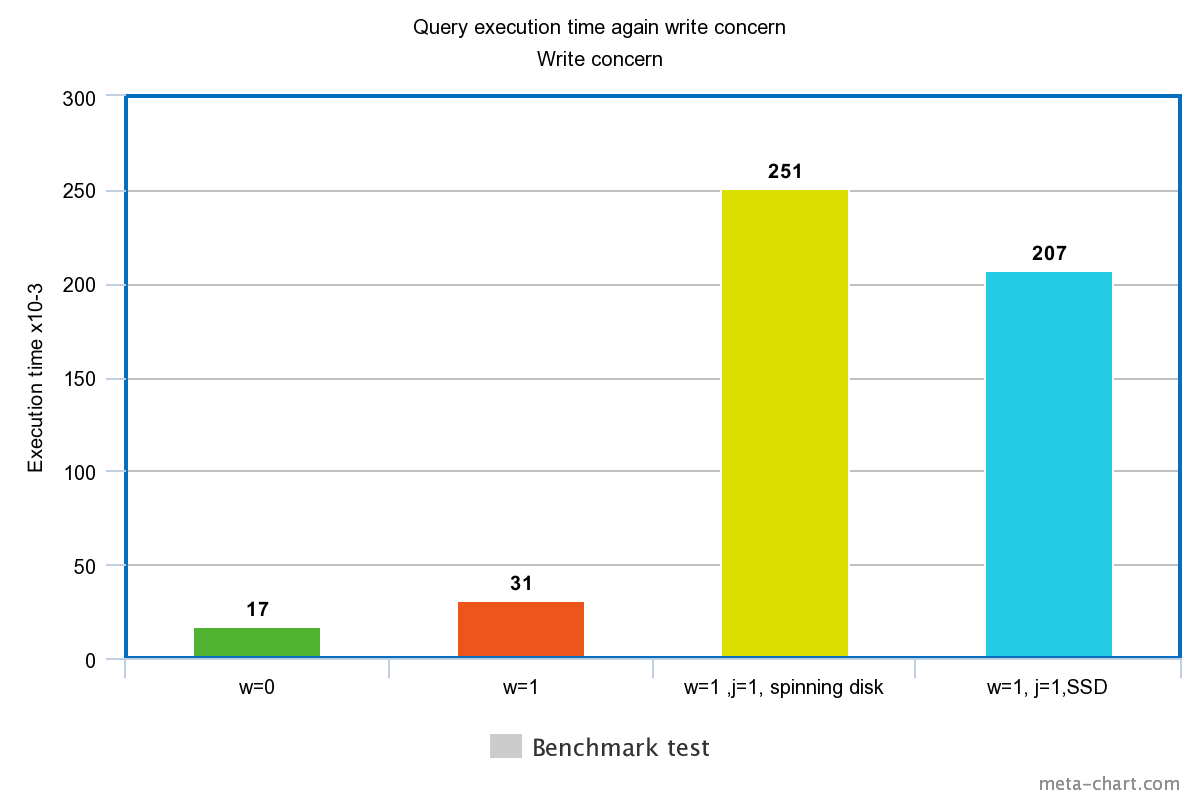
In our test, the write concern set to low resulted in the query being executed in min of 0.013ms and max of 0.017ms. In this case, the basic acknowledgment of write is disabled but one can still get information regarding socket exceptions and any network error that may have been triggered.
When the write concern is set high, it almost takes double the time to return with the execution time being 0.027ms min and 0.031ms max. The acknowledgment in this case is guaranteed but not 100% it has reached disk journal. In this case, chances of a write loss are thus 50% due to the 100ms window where the journal might not be flushed to disk.
Journaling
This is a technique of ensuring no data loss by providing durability in an event of failure. This is achieved through a write-ahead logging to on-disk journal files. It is most efficient when the write concern is set high.
For a spinning disk, the execution time with journaling enabled is a bit high, for instance in our test it was about 0.251ms for the same operation above.

The execution time for an SSD however is a bit lower for the same command. In our test, it was about 0.207ms but depending on the nature of data sometimes this could be 3 times faster than a spinning disk.

When journaling is enabled, it confirms that writes have been made to the journal and hence ensuring data durability. Consequently, the write operation will survive a mongod shutdown and ensures that the write operation is durable.
For a high throughput operation, you can half query times by setting w=0. Otherwise, if you need to be sure that data has been recorded or rather will be in case of a back-to-life after failure, then you need to set the w=1.
Replication
Acknowledgment of a write concern can be enabled for more than one node that is the primary and some secondary within a replica set. This will be characterized by what integer is valued to the write parameter. For example, if w = 3, Mongod must ensure that the query receives an acknowledgment from the main node and 2 slaves. If you try to set a value greater than one and the node is not yet replicated, it will throw an error that the host must be replicated.
Replication comes with a latency setback such that the execution time will be increased. For the simple query above if w=3, then average execution time increases to 270ms. A driving factor for this is the range in response time between nodes affected by network latency, communication overhead between the 3 nodes and congestion. Besides, all three nodes wait for each other to finish before returning the result. In a production deployment, you will therefore not need to involve so many nodes if you want to improve on performance. MongoDB is responsible for selecting which nodes are to be acknowledged unless there is a specification in the configuration file using tags.
Spinning Disk vs Solid State Disk
As mentioned above, SSD disk is quite fast than spinning disk depending on the data involved. Sometimes it could be 3 times faster hence worthy paying for if need be. However, it will be more expensive to use an SSD especially when dealing with vast data. MongoDB has got merit that it supports storing databases in directories which can be mounted hence a chance to use an SSD. Employing an SSD and enabling journaling is a great optimization.
Conclusion
The experiment was certain that write concern disabled results in reduced execution time of a query at the expense of data loss chances. On the other hand, when the write concern is enabled, the execution time is almost 2 times when it is disabled but there is an assurability that data won’t be lost. Besides, we are able to justify that SSD is faster than a Spinning disk. However, to ensure data durability in an event of a system failure, it is advisable to enable the write concern. When enabling the write concern for a replica set, don’t set the number too large such that it may result in some degraded performance from the application end.



