blog
Vector Similarity Search with PostgreSQL’s pgvector – A Deep Dive

As the AI revolution surges forward, promising significant innovations, it also introduced new types of vector databases. A vector database stores data as high-dimensional vectors called embeddings, which are mathematical representations of features or attributes of the data. These vectors are generated by applying an embedding function to the raw data, such as text, images, audio, video, etc. The embedding function can be machine learning models, feature extraction algorithms, etc.
We all know PostgreSQL as a relational database for transactional workloads. But, at the same time, with the pgvector extension, you can turn PostgreSQL into a complete vector database to power your AI applications.
This blog will provide a high-level overview of vector search and its application before going in-depth on pgvector, delving into its creation, features, use cases, and how to enable it into your PostgreSQL database manually and using ClusterControl (CC).
The what, why and how of vector similarity search in PostgreSQL
Vector similarity search is a fundamental building block in various AI, ML, and data-driven applications. It enables efficient exploration, analysis, and retrieval of information similar to a given query.
Vector similarity search works by comparing the similarity between vector embeddings using various distance metrics, such as Euclidean distance, Cosine similarity, or inner product, depending on the nature of the data and the application’s specific requirements.
According to Gartner, unstructured data, such as social media posts, images, videos, audio, etc. represents 80% to 90% of all new data. Unlike structured data, you cannot easily store the contents of unstructured data within PostgreSQL.
Let’s take an image, for example. Imagine searching for similar shoes given a collection of shoe images. If you have the right keywords and / or tags (often the result of manual input), then vanilla PostgreSQL will do. But what if you wanted to find similar shoes according to shots from various angles? This would be impossible since understanding shoe style, size, color, etc., purely from the image’s raw pixel values is impossible.
The growing prevalence of unstructured data resulted in the utilization of embedding functions/models specifically trained to comprehend and analyze this type of data. Image models like VGGNet can turn images into a list of floating point values, called vectors, which are then stored in a vector database. Vectors close to each other represent images that are similar to each other.
The addition of pgvector to PostgreSQL makes it easier for organizations that already use PostgreSQL to efficiently store, retrieve, and manipulate vector data within their existing or new database — this eliminates the need for separate vector databases or complex workarounds.
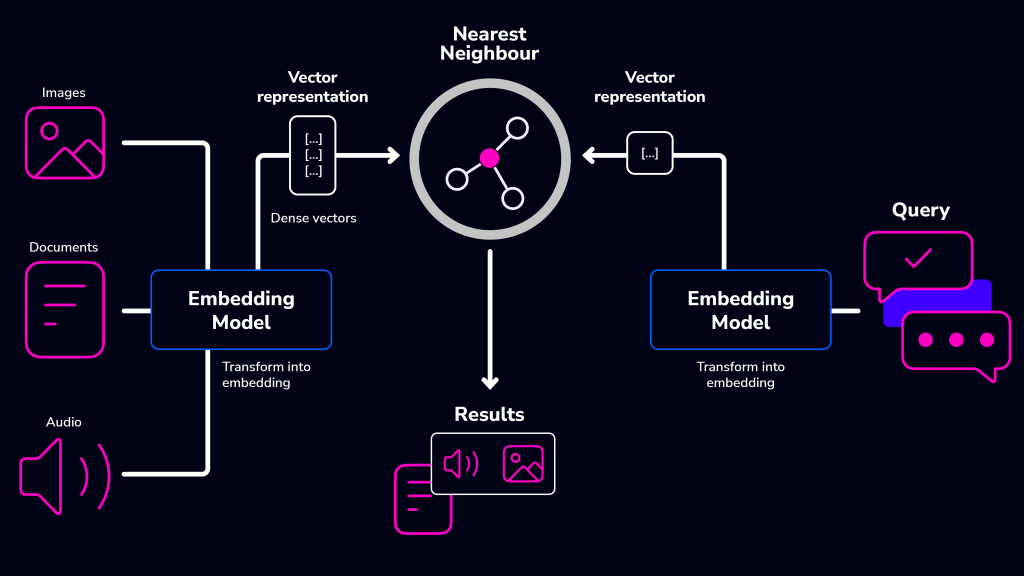
pgvector: PostgreSQL as a vector database
pgvector is an open-source extension for vector similarity search in PostgreSQL. pgvector enables you to store, query, and index machine learning-generated embeddings in PostgreSQL alongside the rest of your data.
Using pgvector, you get not only vector similarity search but also ACID compliance, replication, point-in-time recovery, JOINs, and other great features of PostgreSQL.
Key features of pgvector
pgvector provides several capabilities that allow users to identify both exact and approximate nearest neighbors of vectors, making it a powerful tool for applications such as search, recommendation, and anomaly detection.
The following are key features of pgvector:
Support for various vector embedding types
With pgvector, you can store and search over embeddings of different dimensions and data types, including text, images, and audio. You can index vectors with up to 2,000 dimensions. If your vector has more than 2000 dimensions, to enable indexing, you can reduce it using dimensionality reduction methods like Principal Component Analysis (PCA).
If pgvector’s default data type for the vectors does not capture all the decimal places you need, you can use the double precision[] or numeric[] types to store vectors with more precision.
Efficient nearest neighbor search
Pgvector provides efficient algorithms for finding the nearest neighbors of a given query embedding, both exact and approximate.
By default, pgvector performs exact nearest neighbor search, which provides perfect recall. While this is the most accurate way, it is resource intensive and leads to slow query response time.
pgvector allows you to trade some of the accuracy with performance by adding any supported index — HNSW or IVFFlat — to use approximate nearest neighbor search. Adding an index trades some recall for speed. This article will discuss HNSW and IVFFlat in detail later on.
Integration with SQL queries
pgvector seamlessly integrates with SQL queries, allowing you to combine vector similarity search with other SQL filtering or aggregation operations. This enables more complex data analysis. For instance, you can easily join vector data to other structured data in a single SQL query rather than doing an application-level join.
Also, you can use pgvector from any language (C, Go, Dart, etc.) with a Postgres client. You can even generate and store vectors in one language and query them in another. This makes it easier to manage and manipulate vector data across various applications.
Seamless Scalability
pgvector isn’t just convenient due to its PostgreSQL integration; it’s also built to handle the demands of real-world applications. pgvector is designed to ingest and manage large datasets, efficiently handling millions of vectors without sacrificing performance. This means you don’t have to worry about your database struggling as your data volume increases.
Also, pgvector uses PostgreSQL’s write-ahead (WAL), which allows for replication and point-in-time recovery.
Use Cases of pgvector
The versatility and efficiency of pgvector make it valuable for a wide range of applications across various industries.
Let’s explore some of the more prominent use cases:
Natural Language Processing (NLP) and text analysis
While not directly an NLP tool, pgvector complements NLPs by allowing PostgreSQL to store and search word embeddings or document vectors. This enables tasks like sentiment analysis, document classification, and keyword extraction, helping organizations make sense of massive volumes of textual data from various sources like social media, forums, customer interactions – and most recently prompt inputs from Large language models (LLM) like Open AI’s GPT-4.
Image search and recognition
As discussed earlier, image search benefits immensely from the vector representation. pgvector can effectively serve as the powerhouse to handle tasks such as reverse image search, object detection, and facial recognition, due to its ability to identify similarities and patterns across high-dimensional data.
Recommendation systems
One of the critical components of modern e-commerce and content platforms like Netflix is a robust recommendation engine. You can use pgvector to generate recommendations for users based on their past behavior or preferences.
Accurate recommendation translates to a more engaging user experience, increased customer satisfaction, and ultimately, improved business outcomes.
Anomaly detection and fraud prevention
You can use pgvector to detect anomalies in data by identifying points that are significantly different from the rest of the data. For instance, in financial transactions, if a bank has a customer who typically makes small, everyday purchases, any sudden vector representing a large transaction would be dissimilar to their usual pattern and could be flagged as an anomaly.
Beyond the use cases outlined above, there are countless ways pgvector can be used in any industry today. As more organizations recognize the possibilities with vector databases, their adoption and exploration will persistently push the boundaries of data management and analysis.
How to use pgvector in PostgreSQL
Just like regular PostgreSQL, you can install pgvector on your database with Linux, Mac, and Windows operating systems (OS) using various methods:
- Cloning the pgvector repository and running
make install - Docker
- OS specific package managers like Homebrew, APT, Yum, pkg,etc.
- and through providers like ClusterControl.
pgvector only supports PostgreSQL version 12 and above. Refer to the installation guide on the pgvector repository for your choice instructions.
After installation, you can enable the pgvector extension with the following query:
CREATE EXTENSION vector;To create a table to store you vectors, create a vector column with a specific dimension like in the following query:
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));The embedding vector in the above query has a dimension of 3.
You can also add a vector column to an existing table with the following query:
ALTER TABLE items ADD COLUMN embedding vector(3);Adding vectors is straightforward as:
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');Or load vectors in bulk using the COPY command like below (example):
COPY items (embedding) FROM STDIN WITH (FORMAT BINARY);Since pgvector builds on top of PostgreSQL, a lot of its DML (Data Manipulation Language) is available. For example, to delete vectors, the query would be:
DELETE FROM items WHERE id = 1;Query operators in pgvector
pgvector provides various query operators to perform different operations on vector data. These operators typically focus on calculating the similarity or distance between vectors, with some operators using different similarity metrics.
This section will discuss the commonly used operators in pgvector:
1.<->: This pgvector query operator calculates the Euclidean (L2) distance between two vectors. L2 distance is the straight-line distance between two vectors in a multidimensional space. If the Euclidean distance between two vectors is small, that indicates greater similarity between vectors, making this operator useful in finding and ranking similar items.
SELECT id, name, embedding, embedding <-> '[0.32, 0.1, 0.95]' as distance
FROM items
ORDER BY embedding <-> '[0.32, 0.1, 0.95]';The above query retrieves three columns id, name, embedding about items from the “items” table, calculates their distances to a specific reference vector '[0.32, 0.1, 0.95]', and then orders the results based on these distances.
2. <=>: This operator computes the cosine similarity between two vectors. Cosine similarity compares the angle orientation of two vectors rather than their magnitude. This means that vectors with large or small values will have the same cosine similarity as long as they point in the same direction.
Cosine similarity ranges between -1 to 1, with 1 indicating that the vectors are identical, 0 implying orthogonal (independent and have no correlation), and -1 meaning that the vectors point in opposite directions.
SELECT id, name, embedding, embedding <=> '[0.32, 0.1, 0.95]' as similarity
FROM items
ORDER BY embedding <=> '[0.32, 0.1, 0.95]' DESC;Unlike the previous query, the above orders the results in descending order with the most similar items appearing first rather than simply finding the closest items in terms of Euclidean distance.
3. <#>: This operator computes the inner product between two vectors. The inner product denotes the magnitude of an orthogonal projection of one vector onto another one. It determines whether the vectors point in the same or opposite directions. Two vectors are orthogonal to each other if their inner product is zero. It’s important to note that <#> returns the negative inner product since PostgreSQL only supports ASC order index scans on operators.
SELECT id, name, features, features <#> '[0.32, 0.1, 0.95]' as distance
FROM items
ORDER BY features <#> '[0.32, 0.1, 0.95]';Your choice of query operator depends on your application’s goals and the nature of your data. Some factors to consider include maintaining relative distances, focusing on magnitude or direction, and prioritizing specific dimensions over others.
You can experiment with each operator to see which produces a better result for your needs.
Note: Additionally to query operators, pgvector offers functions to calculate L2 distances, inner product, and cosine similarity which you will see below.
Indexing in pgvector
As mentioned earlier in this article, pgvector supports indexing with HNSW or IVFFlat. HNSW and IVFFlat are two distinctive indexing algorithms with different requirements and results. HNSW stands for “Hierarchical Navigable Small World,” and IVFFlat for “Inverted File with Flat Compression.”
HNSW
An HNSW index constructs a multilayer graph where a path between any pair of vertices can be traversed in a small number of steps. HNSW has better query performance than IVFFlat (in terms of speed-recall tradeoff), but has slower build times and uses more memory.
Also, an HNSW index can be created without any data in the table since there isn’t a training step required, unlike in IVFFlat.
To add an index for each distance function you want to use in HNSW. The following would be the queries.
Euclidean distance:
CREATE INDEX ON movies USING hnsw (embedding vector_l2_ops);Inner product (negative):
CREATE INDEX ON movies USING hnsw (embedding vector_ip_ops);Cosine distance:
CREATE INDEX ON movies USING hnsw (embedding vector_cosine_ops);For more HNSW parameters and query options, refer to the pgvector documentation. To learn more about how HNSW works under the hood, check out this article on Towards Data Science.
IVFFlat
An IVFFlat index divides vectors into lists and then searches a subset of those lists that are closest to the query vector. It has faster build times than HNSW and uses less memory but has lower query performance (in terms of speed-recall tradeoff).
When working with IVFFlat, there are 3 steps to achieving good recall:
Step 1: Create the index after the table has some data
Step 2: Choose a suitable number of lists – a recommended starting point is rows / 1000 for up to 1M rows and sqrt(rows) for over 1M rows
Step 3: When querying, specify an adequate number of probes (higher is better for recall, lower is better for speed) – a good place to start is sqrt(lists).
To add an index for each distance function you want to use in IVFFlat. The following would be the queries.
L2 distance:
CREATE INDEX ON movies USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);Inner product (negative):
CREATE INDEX ON movies USING ivfflat (embedding vector_ip_ops) WITH (lists = 100);Cosine distance:
CREATE INDEX ON movies USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);ClusterControl now supports pgvector!
Instead of manually installing and enabling pgvector, you have the option to use a pgvector provider such as ClusterControl.
ClusterControl supports pgvector by enabling this extension with its PostgreSQL deployment wizard. To enable pgvector from the ClusterControl GUI, you simply:
- Click on Deploy a cluster
- Select the pgvector extension
- Connect to your PostgreSQL database node
- Preview your setup and click Finish
Conclusion
With pgvector, you can confidently store, manage, and query your valuable vector data at scale, all within the trusted and familiar environment of your PostgreSQL database.
Now that you know the ins and outs, the next step is try out a practical use case.
Check out our blog post on building a Retrieval Augmented Generation (RAG) pipeline using OpenAI, LangChain, and pgvector. And if you want to make it easier to work with PostgreSQL and pgvector while building your pipeline, try ClusterControl free for 30-days.



