blog
Using the Galera Replication Window Advisor to Avoid SST

Galera clustering replicates data between nodes synchronously. This way, all nodes in the cluster ensure data is consistent between each other. But what happens if one of those nodes leaves the cluster for a short period of time? This could happen for instance if you are taking a node down for maintenance, have a power outage in one rack or if network partitioning happens.
Galera provides a mechanism for this: once the node joins the cluster it will request an Incremental State Transfer (IST) from the cluster. This IST contains all transactions that were executed during the time the node wasn’t part of the cluster. If the node was away for too long, the IST will not contain all necessary transactions and the node will request a State Snapshot Transfer (SST). A SST is basically a full synchronization of the dataset of one of the nodes in the cluster. In ClusterControl, we configure the SST to be provided by Xtrabackup, but you could also use mysqldump or rsync as method.
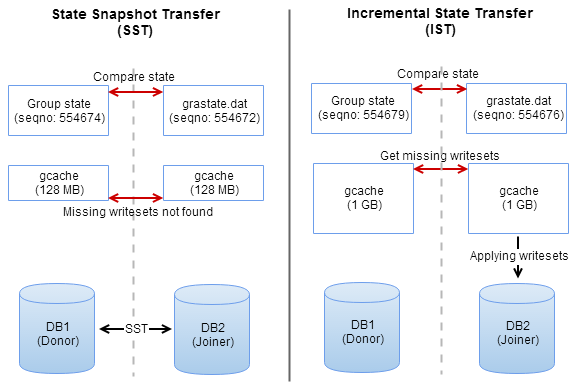
During the SST the joining node will be unavailable for queries. Naturally the larger your dataset, the longer it takes to send the SST from one node to another. This means your cluster will not be in sync for a longer period of time, so avoiding the SST is one of the most important things in a Galera cluster!
Galera gcache and the Replication Window
The IST is provided by entries in the Galera gcache. The gcache is a circular buffer file (ringbuffer) acting as a temporary storage for all transactions executed on the Galera node. Once the ringbuffer is full, Galera will evict the oldest transactions from this file. The time between the first and last entry in the gcache can be referred to as the replication window. Also transactions that are too large to store in the file will be stored in a separate file on disk.
You can configure the size of the gcache using the gcache.size directive inside the wsrep_provider_options, and this is set to 128MB by default. You can read our Galera gcache blog post if you wish to know more about it and how to configure it. You can also read our blog post about determining the optimal size for the gcache setting.
If you are familiar with the MongoDB, you may have noticed a similarity between the Galera gcache and the MongoDB oplog. Similar to the gcache, the oplog is a circular buffer that contains all transactions executed on the master. There is a major difference though: in contrary to the persistence of the oplog, the gcache file will be removed and recreated everytime MySQL starts. Also the oplog facilitates a method of determining the replication window, while gcache does not.
ClusterControl Advisor for Galera Replication Window
With this blog post we want to bring to your attention our new Galera replication window advisor. This advisor, which we created in the developer studio, will constantly analyze your write workload and determine if the Galera gcache is still sufficient to sustain a desired replication window. We can only make an estimation of the replication window, as the gcache file does not give us information of the actual contents of the gcache file.
Instead of this we calculate the write rate per second of Galera in short and long term:
write_rate = (received_bytes + replicated_bytes) / time;With the write rate per second, we can calculate how much storage we would need to satisfy a certain replication window. If the current write rate does not sustain the desired replication window, we can now preemptively warn the user.
Conclusion
In the past, someone determined the gcache size of their Galera cluster. Even though this gcache size might have been valid when the cluster was initially deployed, this may not be valid anymore for their current write workload. With this new advisor, we can give our users the benefit of continuously reviewing their gcache size.
You can download our new advisor directly from our advisors repository on Github, or wait for it to be included in the next version of ClusterControl. Let us know if you would like any assistance on how to write these advisors using our developer studio, we’d be happy to help!



