blog
Tracking High Availability for PostgreSQL With Heartbeat

When deploying a database cluster in different servers you will have achieved the replication advantage of improving data availability. However there is need to keep track of processes, and see whether they are running or not. One of the programs used in this process is Heartbeat which has the capability of checking and verifying presence of resources on one or more systems in a given cluster. Besides the PostgreSQL and the files systems for which PostgreSQL data is stored, the DRBD is one of the resources we are going to discuss in this article on how Heartbeat program can be used.
HA Heartbeat
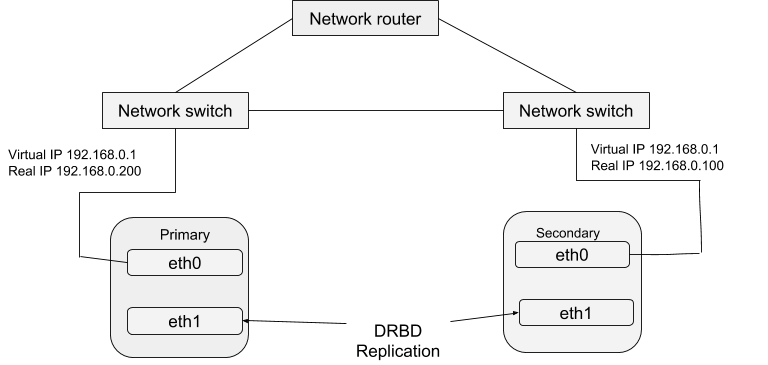
As discussed earlier in the DRBD blog, having a high availability of data is achieved through running different instances of the server but serving the same data. These running server instances can be defined as a cluster in relation to a Heartbeat. Basically, each of the server instance is physically capable of providing the same service as the others within that cluster. However, only one instance can be actively providing service at a time for the purpose of ensuring high-availability of data. We can therefore define the other instances as ‘hot-spares’ which can be brought into service in the event of failure of the master. The Heartbeat package can be downloaded from this link. After installing this package, you can configure it to work with your system with the procedure below. A simple structure of the Heartbeat configuration is:
Configuration of Heartbeat
Looking into this directory /etc/ha.d you will find some files which are used in the configuration process. The ha.cf file forms the main heartbeat configuration. It includes the list of all the nodes and times for identifying failure besides directing the heartbeat on which type of media paths to use and how to configure them. Security information for the cluster is recorded in the authkeys file. Recorded information in these files should be identical for all hosts in the cluster and this can be easily achieved through syncing across all the hosts. This is to say any change of information in one host should be copied to all the others.
Ha.cf file
The basic outline of the ha.cf file is
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacility: this one is used to direct the Heartbeat on which syslog logging facility it should use for recording messages. The most commonly used value are auth, authpriv, user, local0, syslog and daemon. You can also decide not to have any logs so you can set the value to none .i.e
logfacility none - Keepalive: this is the time between heartbeats that is, the frequency with which heartbeat signal is sent to the other hosts. In the sample code above it is set to 3 seconds.
- Deadtime: it is the delay in seconds after which a node is pronounced to have failed.
- Warntime: is the delay in seconds after which a warning is recorded to a log indicating that a node can no longer be contacted.
- Initdead: this is the time in seconds to wait during system startup before the other host is considered to be down.
- Mcast: it is a defined method procedure for sending a heartbeat signal. For the sample code above, the multicast network address is being used over a bounded network device. For a multiple cluster, the multicast address must be unique for each cluster. You can also choose a serial connection over the multicast or if you set up is in a such a way that there are multiple network interfaces, use both for the heartbeat connection like the example. The advantage using both is to overcome the chances of transient failure which consequently may cause an invalid failure event.
- Auto_failback: this reconnects a server which had failed back to the cluster if it becomes available. However it may cause a confusion if the server is switched on and then comes online at a different time. In relation to the DRBD, if it is not well configured, you might end up with more than one data set in the same server. Therefore, it is advisable to always set it to off.
- Node: outlines the node within the Heartbeat cluster group. You should at least have 1 node for each.
Additional Configurations
You can also set additional configuration information like:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping: this is important in ensuring you have connectivity on the public interface for the servers and connection to another host. It is important to consider the IP address rather than the host name for the destination machine.
- Respawn: this is the command to run when a failure occurs.
- Apiauth: is the authority for the failure. You need to configure user and group ID with which the command will be executed. The authkeys file holds the authorization information for the Heartbeat cluster and this key is very unique for verifying machines within a given Heartbeat cluster.
- Deadping: defines the timeout before a nonresponse triggers a failure.
Integration of Heartbeat With Postgres and DRBD
As mentioned before, when a master server fails, another server with a given cluster will jump into action to provide the same service. Heartbeat helps in the configuration of resources that enhance the selection of a server in the event of failure. It for example defines which individual servers should be brought up or discarded at the event of failure. Checking in to the haresources file in the /etc/ha.d directory, we get an outline of the resources that can be managed. The resource file path is /etc/ha.d/resource.d and resource definition is in one line that is:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(note the whitespaces).
- Drbd1: refers to the name of the preferred host to be more secant the server that is normally used as the default master for handling the service. As mentioned in the DRBD blog, we need resources for our server and these are defined in the line as the drbddisk, filesystem and postgres. The last field is a virtual IP address that should be used to share the service i.e connecting to the Postgres server. By default, it will be allocated to the server that is active when the Heartbeat commences. When a failure occurs, these resources will be started on the backup server in order of arrangement when the correspondent script is called. In the setting, the script will switch the DRBD disk on the secondary host into primary mode, making the device read/write.
- Filesystem: this will manage the file system resources and in this case the DRBD has been selected so it will be mounted during the call of the resources script.
- Postgres: this will either start or manage the Postgres server
Sometimes you would want to get notifications through email. To do so, add this line to the resources file with your email for receiving the warning texts:
MailTo:: [email protected]::DRBDFailureTo start the heartbeat, you can run the command
/etc/ha.d/heartbeat startor reboot both the primary and secondary servers. Now if you run the command
$ /usr/lib64/heartbeat/hb_standbyThe current node will be triggered to relinquish its resources cleanly to the other node.
Handling System Level Errors
Sometimes the server kernel may be corrupted hence indicating a potential problem with your server. You will need to configure the server to remove itself from the cluster during the event of a problem. This problem is often referred to as kernel panic and it consequently triggers a hard reboot on your machine. You can force a reboot by setting the kernel.panic and kernel.panic_on_oop of the kernel control file /etc/sysctl.conf. I.e
kernel.panic_on_oops = 1
kernel.panic = 1Another option is to do it from the command line using the sysctl command i.e:
$ sysctl -w kernel.panic=1You can also edit the sysctl.conf file an reload the configuration information using this command.
sysctl -pThe value indicates the number of seconds to wait before rebooting. The second heartbeat node should then detect that the server is down and then switch over the failover host.
Conclusion
Heartbeat is a subsystem which allows selection of a secondary server into primary and a back-up system when an active server fails. It also determines if all the other servers are alive. It also ensures transfer of resources to the new primary node



