blog
Tips for Storing MongoDB Backups in the Cloud

When it comes to backups and data archiving, IT departments are under pressure to meet stricter service level agreements, deliver more custom reports, and adhere to expanding compliance requirements while continuing to manage daily archive and backup tasks. With no doubt, database server stores some of your enterprise’s most valuable information. Guaranteeing reliable database backups to prevent data loss in the event of an accident or hardware failure is a critical checkbox.
But how to make it truly DR when all of your data is in the single data center or even data centers that are in the near geolocation? Moreover, whether it is a 24×7 highly loaded server or a low-transaction-volume environment, you will be in the need of making backups a seamless procedure without disrupting the performance of the server in a production environment.
In this blog, we are going to review MongoDB backup to the cloud. The cloud has changed the data backup industry. Because of its affordable price point, smaller businesses have an offsite solution that backs up all of their data.
We will show you how to perform safe MongoDB backups using mongo services as well as other methods that you can use to extend your database disaster recovery options.
If your server or backup destination is located in an exposed infrastructure like a public cloud, hosting provider or connected through an untrusted WAN network, you need to think about additional actions in your backup policy. There are a few different ways to perform database backups for MongoDB, and depending on the type of backup, recovery time, size, and infrastructure options will vary. Since many of the cloud storage solutions are simply storage with different API front ends, any backup solution can be performed with a bit of scripting. So what are the options we have to make the process smooth and secure?
MongoDB Backup Encryption
Security should be in the center of every action IT teams do. It is always a good idea to enforce encryption to enhance the security of backup data. A simple use case to implement encryption is where you want to push the backup to offsite backup storage located in the public cloud.
When creating an encrypted backup, one thing to keep in mind is that it usually takes more time to recover. The backup has to be decrypted before any recovery activities. With a big dataset, this could introduce some delays to the RTO.
On the other hand, if you are using the private keys for encryption, make sure to store the key in a safe place. If the private key is missing, the backup will be useless and unrecoverable. If the key is stolen, all created backups that use the same key would be compromised as they are no longer secured. You can use popular GnuPG or OpenSSL to generate private or public keys.
To perform MongoDBdump encryption using GnuPG, generate a private key and follow the wizard accordingly:
$ gpg --gen-keyCreate a plain MongoDBdump backup as usual:
$ mongodump –db db1 –gzip –archive=/tmp/db1.tar.gz$ gpg --encrypt -r ‘[email protected]’ db1.tar.gz
$ rm -f db1.tar.gzsimply run the gpg command with –decrypt flag:
$ gpg --output db1.tar.gz --decrypt db1.tar.gz.gpgOpenSSL req -x509 -nodes -newkey rsa:2048 -keyout dump.priv.pem -out dump.pub.pemThis private key (dump.priv.pem) must be kept in a safe place for future decryption. For Mongodump, an encrypted backup can be created by piping the content to openssl, for example
mongodump –db db1 –gzip –archive=/tmp/db1.tar.gz | openssl smime -encrypt -binary -text -aes256
-out database.sql.enc -outform DER dump.pub.pemopenssl smime -decrypt -in database.sql.enc -binary -inform
DEM -inkey dump.priv.pem -out db1.tar.gzMongoDB Backup Compression
Within the database cloud backup world, compression is one of your best friends. It can not only save storage space, but it can also significantly reduce the time required to download/upload data.
In addition to archiving, we’ve also added support for compression using gzip. This is exposed by the introduction of a new command-line option “–gzip” in both mongodump and mongorestore. Compression works both for backups created using the directory and the archive mode and reduces disk space usage.
Normally, MongoDB dump can have the best compression rates as it is a flat text file. Depending on the compression tool and ratio, a compressed MongoDBdump can be up to 6 times smaller than the original backup size. To compress the backup, you can pipe the MongoDBdump output to a compression tool and redirect it to a destination file
Having a compressed backup could save you up to 50% of the original backup size, depending on the dataset.
mongodump --db country --gzip --archive=country.archiveLimiting Network Throughput
A great option for cloud backups is to limit network streaming bandwidth (Mb/s) when doing a backup. You can achieve that with pv tool. The pv utility comes with data modifiers option -L RATE, –rate-limit RATE which limit the transfer to a maximum of RATE bytes per second. Below example will restrict it to 2MB/s.
$ pv -q -L 2mTransferring MongoDB Backups to the Cloud
Now when your backup is compressed and secured (encrypted), it is ready for transfer.
Google Cloud
The gsutil command-line tool is used to manage, monitor and use your storage buckets on Google Cloud Storage. If you already installed the gcloud util, you already have the gsutil installed. Otherwise, follow the instructions for your Linux distribution from here.
To install the gcloud CLI you can follow the below procedure:
curl https://sdk.cloud.google.com | bashexec -l $SHELLgcloud initgsutil mb -c regional -l europe-west1 gs://severalnines-storage/
Creating gs://MongoDB-backups-storage/Amazon S3
If you are not using RDS to host your databases, it is very probable that you are doing your own backups. Amazon’s AWS platform, S3 (Amazon Simple Storage Service) is a data storage service that can be used to store database backups or other business-critical files. Either it’s Amazon EC2 instance or your on-prem environment you can use the service to secure your data.
While backups can be uploaded through the web interface, the dedicated s3 command line interface can be used to do it from the command line and through backup automation scripts. If backups are to be kept for a very long time, and recovery time isn’t a concern, backups can be transferred to Amazon Glacier service, providing much cheaper long-term storage. Files (amazon objects) are logically stored in a huge flat container named bucket. S3 presents a REST interface to its internals. You can use this API to perform CRUD operations on buckets and objects, as well as to change permissions and configurations on both.
The primary distribution method for the AWS CLI on Linux, Windows, and macOS is pip, a package manager for Python. Instructions can be found here.
aws s3 cp severalnines.sql s3://severalnine-sbucket/MongoDB_backupsMicrosoft Azure Storage
Microsoft’s public cloud platform, Azure, has storage options with its control line interface. Information can be found here. The open-source, cross-platform Azure CLI provides a set of commands for working with the Azure platform. It gives much of the functionality seen in the Azure portal, including rich data access.
The installation of Azure CLI is fairly simple, you can find instructions here. Below you can find how to transfer your backup to Microsoft storage.
az storage blob upload --container-name severalnines --file severalnines.gz.tar --name severalnines_backupHybrid Storage for MongoDB Backups
With the growing public and private cloud storage industry, we have a new category called hybrid storage. The typical approach is to keep data on local disk drives for a shorter period while cloud backup storage would be held for a longer time. Many times the requirement for longer backup retention comes from legal obligations for different industries (like telecoms having to store connection metadata).This technology allows the files to be stored locally, with changes automatically synced to remote in the cloud. Such an approach is coming from the need of having recent backups stored locally for fast restore (lower RTO), as well as business continuity objectives.
The important aspect of efficient resource usage is to have separate backup retentions. Data that is stored locally, on redundant disk drives would be kept for a shorter period while cloud backup storage would be held for a longer time. Many times the requirement for longer backup retention comes from legal obligations for different industries (like telecoms having to store connection metadata).
Cloud providers like Google Cloud Services, Microsoft Azure and Amazon S3 each offer virtually unlimited storage, decreasing local space needs. It allows you to retain your backup files longer, for as long as you would like and not have concerns around local disk space.
ClusterControl Backup Management – Hybrid Storage
When scheduling backup with ClusterControl, each of the backup methods are configurable with a set of options on how you want the backup to be executed. The most important for the hybrid cloud storage would be:
- Network throttling
- Encryption with the built-in key management
- Compression
- The retention period for the local backups
- The retention period for the cloud backups
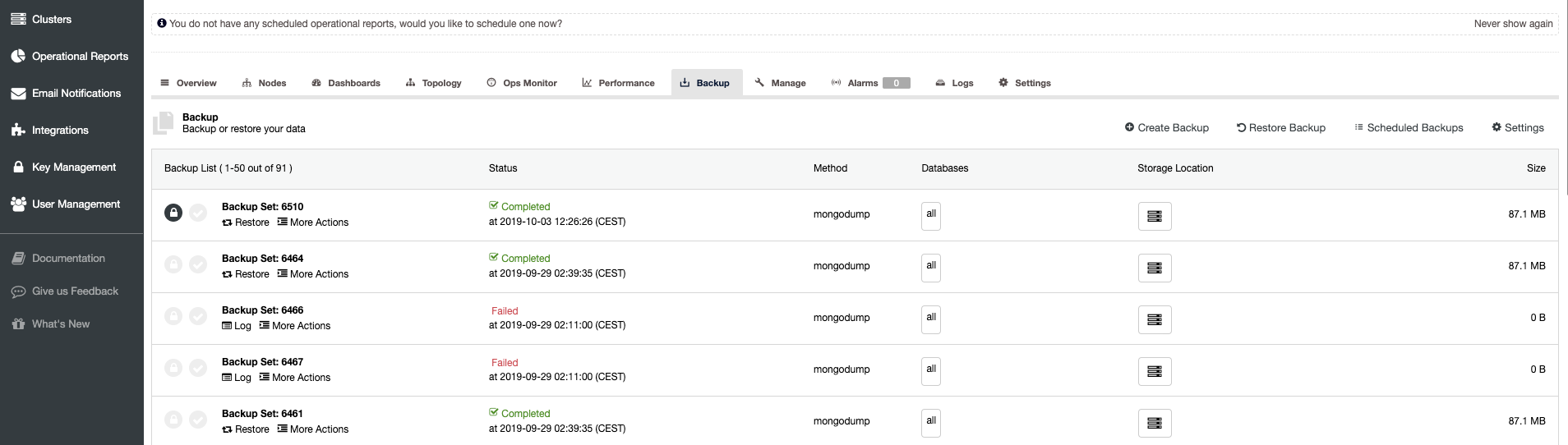
ClusterControl advanced backup features for cloud, parallel compression, network bandwidth limit, encryption, etc. Your company can take advantage of cloud scalability and pay-as-you-go pricing for growing storage needs. You can design a backup strategy to provide both local copies in the datacenter for immediate restoration, and a seamless gateway to cloud storage services from AWS, Google and Azure.
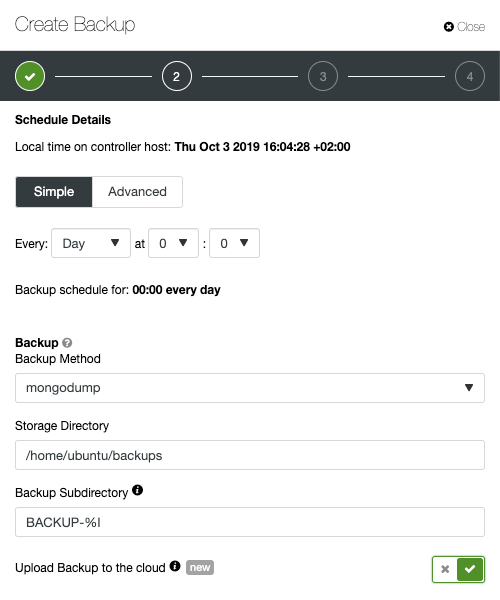
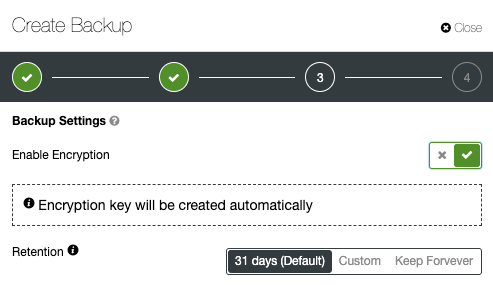
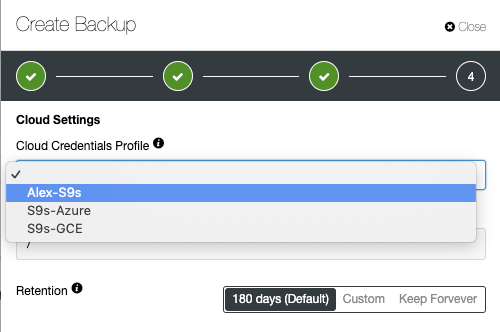
Advanced TLS and AES 256-bit encryption and compression features support secure backups that take up significantly less space in the cloud.



