blog
Running a Data Warehouse on PostgreSQL

When you need to implement an analytics system for a company there is often the question of where the data should be stored. There is not always a perfect option for all the requirements and it depends on the budget, the amount of data, and the needs of the company.
PostgreSQL, as the most advanced open source database, is so flexible that can serve as a simple relational database, a time-series data database, and even as an efficient, low-cost, data warehousing solution. You can also integrate it with several analytics tools.
If you’re looking for a widely compatible, low cost, and performant data warehouse, the best database option could be PostgreSQL, but why? In this blog, we’ll see what a data warehouse is, why is it needed, and why PostgreSQL could be the best option here.
What is a Data Warehouse
A Data Warehouse is a system of standardized, consistent, and integrated which contains current or historical data from one or more sources that is used for reporting and data analysis. It’s considered a core component of business intelligence, which is the strategy and technology used by a company for a better understanding of its commercial context.
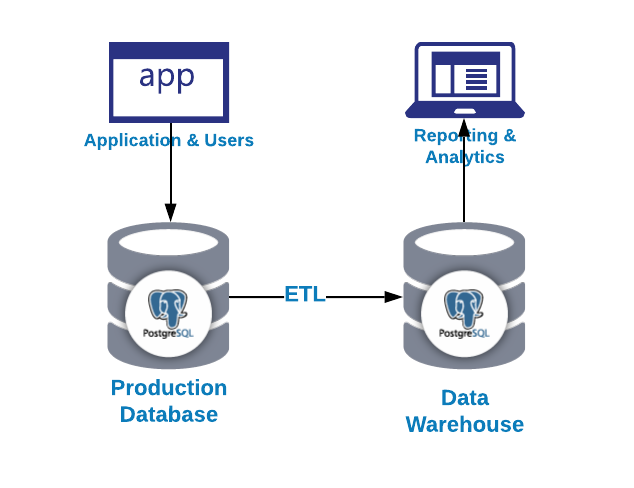
The first question you may ask is why do I need a data warehouse?
- Integration: Integrate/centralize data from multiple systems/databases
- Standardize: Standardize all the data in the same format
- Analytics: Analyze data in a historical context
Some of the benefits of a data warehouse can be…
- Integrate data from multiple sources into a single database
- Avoid production locking or load due to long-running queries
- Store Historical Information
- Restructure the data to fit the analytics requirements
As we could see in the previous image, we can use PostgreSQL for both OLAP and OLTP proposes. Let’s see the difference.
- OLTP: Online transaction processing. In general, it has a large number of short on-line transactions (INSERT, UPDATE, DELETE) generated by user activity. These systems emphasize very fast query processing and maintaining data integrity in multi-access environments. Here, effectiveness is measured by the number of transactions per second. OLTP databases contain detailed and current data.
- OLAP: Online analytical processing. In general, it has a low volume of complex transactions generated by large reports. The response time is an effectiveness measure. These databases store aggregated, historical data in multi-dimensional schemas. OLAP databases are used to analyze multidimensional data from multiple sources and perspectives.
We have two ways to load data into our analytics database:
- ETL: Extract, transform and load. This is the way to generate our data warehouse. First, extract the data from the production database, transform the data according to our requirement, and then, load the data into our data warehouse.
- ELT: Extract, load and transform. First, extract the data from the production database, load it into the database and then transform the data. This way is called Data Lake and it’s a new concept to manage our big data.
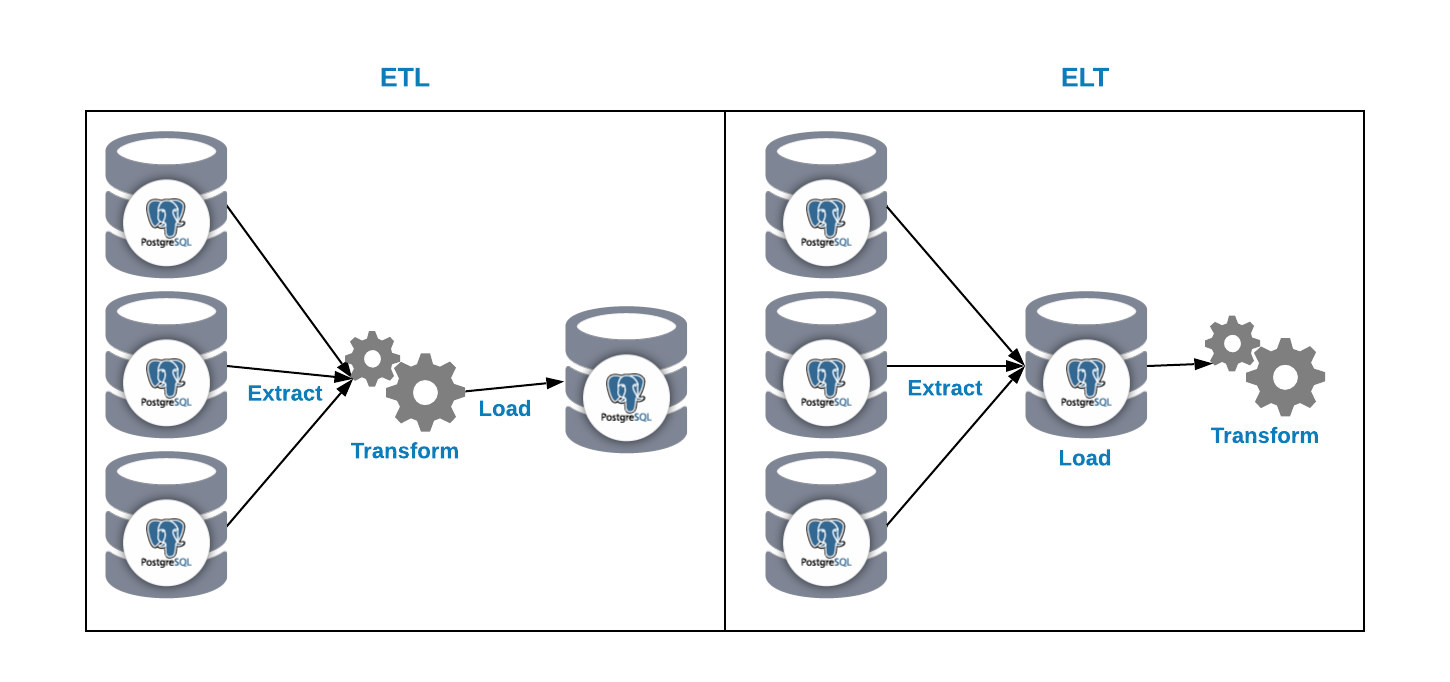
And now, the second question i, why should I use PostgreSQL for my data warehouse?
Benefits of PostgreSQL as a Data Warehouse
Let’s look at some of the benefits of using PostgreSQL as a data warehouse…
- Cost: If you’re using an on-prem environment, the cost for the product itself will be $0, even if you’re using some product in the cloud, probably the cost of a PostgreSQL based product will be less than the rest of the products.
- Scale: You can scale reads it in a simple way by adding as many replica nodes as you want.
- Performance: With a correct configuration, PostgreSQL has a really good performance on different escenarios.
- Compatibility: You can integrate PostgreSQL with external tools or applications for data mining, OLAP and reporting.
- Extensibility: PostgreSQL has user-defined data types and functions.
There are also some PostgreSQL features that can help us to manage our data warehouse information…
- Temporary tables: It’s a short-lived table that exists for the duration of a database session. PostgreSQL automatically drops the temporary tables at the end of a session or a transaction.
- Stored procedures: You can use it to create procedures or function on multiple languages (PL/pgSQL, PL/Perl, PL/Python, etc).
- Partitioning: This is really useful for database maintenance, queries using partition key and INSERT performance.
- Materialized view: The query results are shown as a table.
- Tablespaces: You can change the data location to a different disk. In this way, you’ll have parallelized disk access.
- PITR compatible: You can create backups Point-in-time-recovery compatible, so in case of failure, you can restore the database state on a specific period of time.
- Huge community: And last but not least, PostgreSQL has a huge community where you can find support on many different issues.
Configuring PostgreSQL for Data Warehouse Usage
There is no best configuration to use in all cases and in all database technologies. It depends on many factors such as hardware, usage, and system requirements. Below are some tips to configure your PostgreSQL database to work as a data warehouse in the correct way.
Memory Based
- max_connections: As a data warehouse database, you don’t need a high amount of connections because this will be used for reporting and analytics work, so you can limit the max connections numbers using this parameter.
- shared_buffers: Sets the amount of memory that the database server uses for shared memory buffers. A reasonable value can be from 15% to 25% of the RAM memory.
- effective_cache_size: This value is used by the query planner to take into account plans that may or may not fit in memory. This is taken into account in the cost estimates of using an index; a high value makes it more likely that index scans are used and a low value makes it more likely that sequential scans will be used. A reasonable value would be around 75% of the RAM memory.
- work mem: Specifies the amount of memory that will be used by the internal operations of ORDER BY, DISTINCT, JOIN, and hash tables before writing to the temporary files on disk. When configuring this value we must take into account that several sessions are executing these operations at the same time and each operation will be allowed to use as much memory as specified by this value before it starts to write data in temporary files. A reasonable value can be around 2% of the RAM Memory.
- maintenance_work_mem: Specifies the maximum amount of memory that maintenance operations will use, such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY. A reasonable value can be around 15% of the RAM Memory.
CPU Based
- Max_worker_processes: Sets the maximum number of background processes that the system can support. A reasonable value can be the number of CPUs.
- Max_parallel_workers_per_gather: Sets the maximum number of workers that can be started by a single Gather or Gather Merge node. A reasonable value can be 50% of the number of CPU.
- Max_parallel_workers: Sets the maximum number of workers that the system can support for parallel queries. A reasonable value can be the number of CPUs.
As the data loaded into our data warehouse shouldn’t change, we can also set the Autovacuum in off to avoid an extra load on your PostgreSQL database. The Vacuum and Analyze processes can be part of the batch load process.
Conclusion
If you’re looking for widely compatible, low cost, and high-performance data warehouse you should definitely consider PostgreSQL as an option for your data warehouse database. PostgreSQL has many benefits and features useful to manage our data warehouse like partitioning, or stored procedures, and even more.



