blog
An Overview of PostgreSQL Query Caching & Load Balancing

PostgreSQL Bi-Directional Replication Demystified — From Theory to Operations

The topic of caching appeared in PostgreSQL as far back as 22 years ago, and at that time the focus was on database reliability.
Fast forward to 2020, the disk platters are hidden even deeper into virtualized environments, hypervisors, and associated storage appliances. Furthermore, interconnected, distributed applications operating at global scale are screaming for low latency connections and all of a sudden tuning server caches, and SQL queries compete with ensuring the results are returned to clients within milliseconds. Application level and in-memory caches are born, and read queries are now saved close to the application servers. As a result, I/O operations are reduced to writes only, and network latency is dramatically improved. With one catch. Implementations are responsible for their own cache management which sometimes leads to performance degradation.
Caching writes is a much more complicated matter, as explained in the PostgreSQL wiki.
This blog is an overview of the in-memory query caches and load balancers that are being used with PostgreSQL.
PostgreSQL Load Balancing
The idea of load balancing was brought up about at the same time as caching, in 1999, when Bruce Momjiam wrote:
[…] it is possible we may be _very_ popular in the near future.
The foundation for implementing load balancing in PostgreSQL is provided by the built-in Hot Standby feature. The only requirement is for the application to handle the failover and this is where 3rd party solutions come in. We’ll look at some of those solutions in the next sections.
Load balanced queries can only return consistent results so long as the synchronous replication lag is kept low. In practice, even state of the art network infrastructure such as AWS may exhibit tens of milliseconds delays:
We typically observe lag times in the 10s of milliseconds. […] However, under typical conditions, under a minute of replication lag is common. […]
Cross-region replicas using logical replication will be influenced by the change/apply rate and delays in network communication between the specific regions selected. Cross-region replicas using Aurora Global Database will have a typical lag of under a second.
As stated earlier the 3rd party solutions rely on core PostgreSQL features. For example, load balancing of read queries is achieved using multiple synchronous standbys.
Solutions
pgpool-II
pgpool-II is a feature-rich product providing both load balancing and in-memory query caching. It is a drop-in replacement, no changes on the application side are required.
As a load balancer, pgpool-II examines each SQL query — in order to be load balanced, SELECT queries must meet several conditions.
The setup can be as simple as one node, shown below is a dual-node cluster:
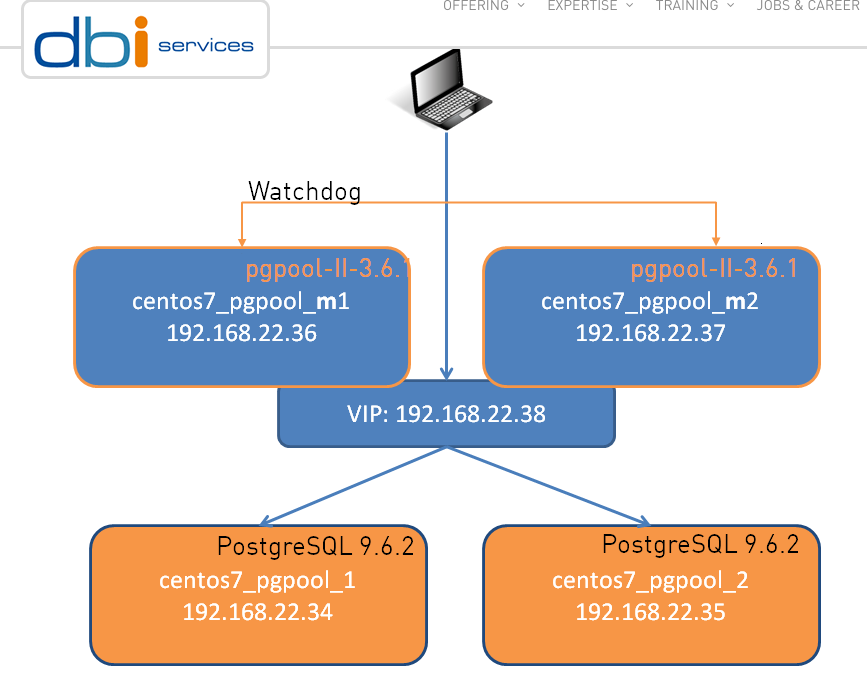
As it’s the case with any great piece of software, there are certain limitations, and pgpool-II makes no exception:
- It does not handle multi-statement queries.
- SELECT queries on temporary tables require the /*NO LOAD BALANCE*/ SQL comment.
Applications running in high performance environments will benefit from a mixed configuration where pgBouncer is the connection pooler and pgpool-II handles load balancing and caching. The result is an impressive 4 times throughput increase and 40 percent latency reduction:
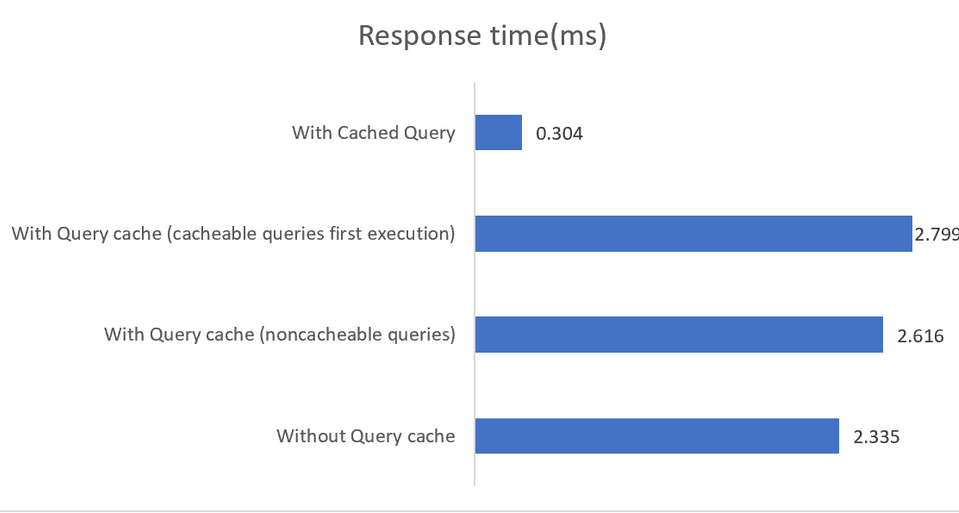
In-memory caching works, again, only on read queries, with cached data being saved either into the shared memory or into an external memcached installation. While the documentation is pretty good at explaining the various configuration options, it indirectly suggests that implementations must monitor SHOW POOL CACHE output in order to alert on hit ratios falling below the 70% mark, at which point the performance gain provided by caching is lost.
Bucardo
Bucardo is a PostgreSQL replication tool written in Perl and PL/Perl.
I have mentioned Bucardo, because load balancing is one of its features, according to PostgreSQL wiki, however, an internet search comes up with no relevant results. To clarify I headed over to the official documentation which goes into the details of how the software actually works:

That makes it pretty clear, Bucardo is not a load balancer, just as was pointed by the folks at Database Soup.
HAProxy
HAProxy is a general purpose load balancer that operates at the TCP level (for the purpose of database connections). Health checks ensure that queries are only sent to alive nodes.
Compared to pgpool-II, applications using HAProxy as a load balancer, must be made aware of the endpoint dispatching requests to reader nodes.
Apache Ignite
Apache Ignite is a second-level cache that understands ANSI-99 SQL and provides support for ACID transactions. Apache Ignite does not understand the PostgreSQL Frontend/Backend Protocol and therefore applications must use either a persistence layer such as Hibernate ORM. As an alternative to modifying applications, Apache Ignite provides `memcached integration`_ which requires the memcached PostgreSQL extension. Unfortunately, this latter option is not compatible with recent versions of PostgreSQL, as the pgmemcache extension was last updated in 2017.
Heimdall Data
As a commercial product, Heimdall Data checks both boxes: load balancing and caching. It’s a mature product, having been showcased at PostgreSQL conferences as far back as PGCon 2017:

More details and a product demo can be found on the Azure for PostgreSQL blog.
Conclusion
In today’s distributed computing, Query Caching and Load Balancing are as important to PostgreSQL performance tuning as the well-known GUCs, OS kernel, storage, and query optimization. While pgpool-II and Heimdall Data are the open source and respectively, the commercial preferred solutions, there are cases where purposely made tools can be used as building blocks to achieve similar results.



