blog
An Overview of Job Scheduling Tools for PostgreSQL

Unlike other database management systems that have their own built-in scheduler (like Oracle, MSSQL or MySQL), PostgreSQL still doesn’t have this kind of feature.
In order to provide scheduling functionality in PostgreSQL you will need to use an external tool like…
- Linux crontab
- Agent pgAgent
- Extension pg_cron
In this blog we will explore these tools and highlight how to operate them and their main features.
Linux crontab
It’s the oldest one, however, an efficient and useful way to execute scheduling tasks. This program is based on a daemon (cron) that allows tasks to be automatically run in the background periodically and regularly verifies the configuration files ( called crontab files) on which are defined the script/command to be executed and its scheduling.
Each user can have his own crontab file and for the newest Ubuntu releases are located in:
/var/spool/cron/crontabs (for other linux distributions the location could be different):
root@severalnines:/var/spool/cron/crontabs# ls -ltr
total 12
-rw------- 1 dbmaster crontab 1128 Jan 12 12:18 dbmaster
-rw------- 1 slonik crontab 1126 Jan 12 12:22 slonik
-rw------- 1 nines crontab 1125 Jan 12 12:23 ninesThe syntax of the configuration file is the following:
mm hh dd mm day <A few operators could be used with this syntax to streamline the scheduling definition and these symbols allow to specify multiple values in a field:
Asterisk (*) – it means all possible values for a field
The comma (,) – used to define a list of values
Dash (-) – used to define a range of values
Separator (/) – specifies a step value
The script all_db_backup.sh will be executed according each scheduling expression:
|
0 6 * * * /home/backup/all_db_backup.sh |
At 6 am every day |
|
20 22 * * Mon, Tue, Wed, Thu, Fri /home/backup/all_db_backup.sh |
At 10:20 PM, every weekday |
|
0 23 * * 1-5 /home/backup/all_db_backup.sh |
At 11 pm during the week |
|
0 0/5 14 * * /home/backup/all_db_backup.sh |
Every five hours starting at 2:00 p.m. and ending at 2:55 p.m., every day |
If the crontab file doesn’t exist for a user it can be created by the following command:
slonik@severalnines:~$ crontab -eor presented it using the -l parameter:
slonik@severalnines:~$ crontab -lIf necessary to remove this file, the appropriate parameter is -r:
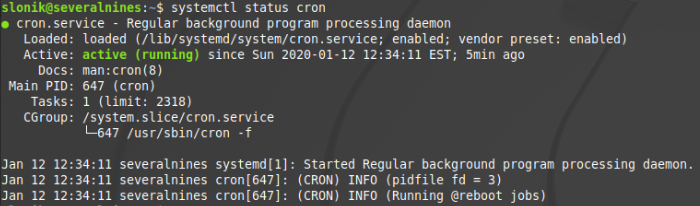
slonik@severalnines:~$ crontab -rThe cron daemon status is shown by the execution of the following command:
Agent pgAgent
The pgAgent is a job scheduling agent available for PostgreSQL that allows the execution of stored procedures, SQL statements, and shell scripts. Its configuration is stored on the postgres database in the cluster.
The purpose is to have this agent running as a daemon on Linux systems and periodically does a connection to the database to check if there are any jobs to execute.
This scheduling is easily managed by PgAdmin 4, but it’s not installed by default once the pgAdmin installed, it’s necessary to download and install it on your own.
Hereafter are described all the necessary steps to have the pgAgent working properly:
Step One
Installation of pgAdmin 4
$ sudo apt install pgadmin4 pgadmin4-apacheStep Two
Creation of plpgsql procedural language if not defined
CREATE TRUSTED PROCEDURAL LANGUAGE ‘plpgsql’
HANDLER plpgsql_call_handler
HANDLER plpgsql_validator;Step Three
Installation of pgAgent
$ sudo apt-get install pgagentStep Four
Creation of the pgagent extension
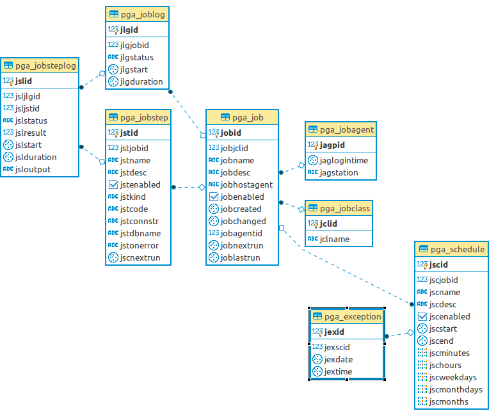
CREATE EXTENSION pageant This extension will create all the tables and functions for the pgAgent operation and hereafter is showed the data model used by this extension:
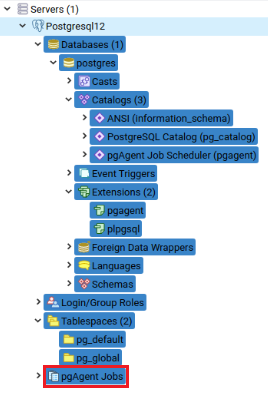
Now the pgAdmin interface already has the option “pgAgent Jobs” in order to manage the pgAgent:
In order to define a new job, it’s only necessary select “Create” using the right button on “pgAgent Jobs”, and it’ll insert a designation for this job and define the steps to execute it:
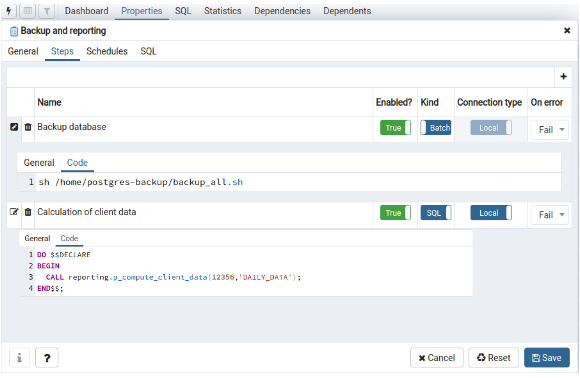
In the tab “Schedules” must be defined the scheduling for this new job:
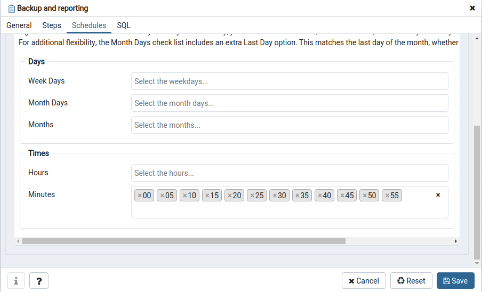
Finally, to have the agent running in the background it’s necessary to launch the following process manually:
/usr/bin/pgagent host=localhost dbname=postgres user=postgres port=5432 -l 1Nevertheless, the best option for this agent is to create a daemon with the previous command.
Extension pg_cron
The pg_cron is a cron-based job scheduler for PostgreSQL that runs inside the database as an extension (similar to the DBMS_SCHEDULER in Oracle) and allows the execution of database tasks directly from the database, due to a background worker.
The tasks to perform can be any of the following ones:
- stored procedures
- SQL statements
- PostgreSQL commands (as VACUUM, or VACUUM ANALYZE)
pg_cron can run several jobs in parallel, but only one instance of a program can be running at a time.
If a second run should be started before the first one finishes, then it is queued and will be started as soon as the first run completes.
This extension was defined for the version 9.5 or higher of PostgreSQL.
Installation of pg_cron
The installation of this extension only requires the following command:
slonik@sveralnines:~$ sudo apt-get -y install postgresql-10-cronUpdating of Configuration Files
In order to start the pg_cron background worker once PostgreSQL server starts, it’s necessary to set pg_cron to shared_preload_libraries parameter in postgresql.conf:
shared_preload_libraries = ‘pg_cron’It’s also necessary to define in this file, the database on which the pg_cron extension will be created, by adding the following parameter:
cron.database_name= ‘postgres’On the other hand, in pg_hba.conf file that manages the authentication, it’s necessary to define the postgres login as trust for the IPV4 connections, because pg_cron requires such user to be able to connect to the database without providing any password, so the following line needs to be added to this file:
host postgres postgres 192.168.100.53/32 trustThe trust method of authentication allows anyone to connect to the database(s) specified in the pg_hba.conf file, in this case the postgres database. It’s a method used often to allow connection using Unix domain socket on a single user machine to access the database and should only be used when there isan adequate operating system-level protection on connections to the server.
Both changes require a PostgreSQL service restart:
slonik@sveralnines:~$ sudo system restart postgresql.serviceIt’s important to take into account that pg_cron does not run any jobs as long as the server is in hot standby mode, but it automatically starts when the server is promoted.
Creation of pg_cron extension
This extension will create the meta-data and the procedures to manage it, so the following command should be executed on psql:
postgres=#CREATE EXTENSION pg_cron;
CREATE EXTENSION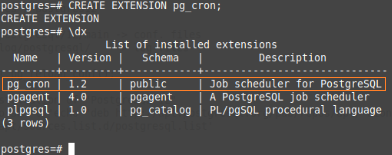
Now, the needed objects to schedule jobs are already defined on the cron schema:
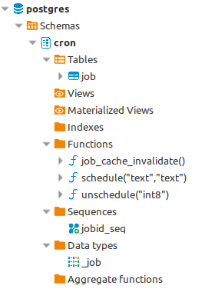
This extension is very simple, only the job table is enough to manage all this functionality:

Definition of New Jobs
The scheduling syntax to define jobs on pg_cron is the same one used on the cron tool, and the definition of new jobs is very simple, it’s only necessary to call the function cron.schedule:
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(12356,''DAILY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(998934,''WEEKLY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(45678,''DAILY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(1010,''WEEKLY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(1001,''MONTHLY_DATA'');')
select cron.schedule('*/5 * * * *','select reporting.f_reset_client_data(0,''DATA'')')
select cron.schedule('*/5 * * * *','VACUUM')
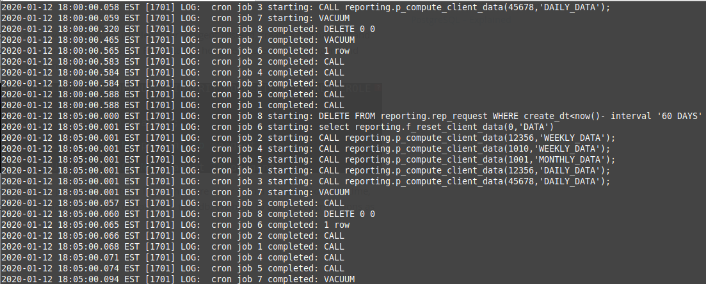
select cron.schedule('*/5 * * * *','$DELETE FROM reporting.rep_request WHERE create_dt<now()- interval '60 DAYS'$)The job setup is stored on the job table:
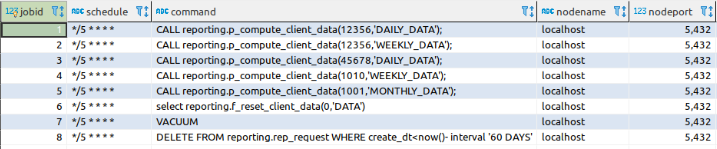
Another way to define a job is by inserting the data directly on the cron.job table:
INSERT INTO cron.job (schedule, command, nodename, nodeport, database, username)
VALUES ('0 11 * * *','call loader.load_data();','postgresql-pgcron',5442,'staging', 'loader');and use custom values for nodename and nodeport to connect to a different machine (as well as other databases).
Deactivation of a Jobs
On the other hand, to deactivate a job it’s only necessary to execute the following function:
select cron.schedule(8)Jobs Logging
The logging of these jobs can be found on the PostgreSQL log file /var/log/postgresql/postgresql-12-main.log: