blog
An Overview of Database Indexing for MongoDB

What is Indexing?
Indexing is an important concept in database world. Main advantage of creating index on any field is faster access of data . It optimizes the process of database searching and accessing. Consider this example to understand this.
When any user asks for a specific row from the database, what will DB system do? It will start from the first row and check whether this is the row that the user wants? If yes, then return that row, otherwise continue searching for the row till the end.
Generally, when you define an index on a particular field, the DB system will create a ordered list of that field’s value and store it in a different table. Each entry of this table will point to the corresponding values in the original table. So when the user tries to search for any row, it will first search for the value in the index table using binary search algorithm and return the corresponding value from the original table. This process will take less time because we are using binary search instead of linear search.
In this article, we will focus in MongoDB Indexing and understand how to create and use indexes in MongoDB.
How to Create an Index in MongoDB Collection?
To create index using Mongo shell, you can use this syntax:
db.collection.createIndex( , ) Example:
To create index on name field in myColl collection:
db.myColl.createIndex( { name: -1 } )Types of MongoDB Indexes
-
Default _id Index
This is the default index which will be created by MongoDB when you create a new collection. If you don’t specify any value for this field, then _id will be primary key by default for your collection so that a user can’t insert two documents with same _id field values. You can’t remove this index from the _id field.
-
Single Field Index
You can use this index type when you want to create a new index on any field other than _id field.
Example:
db.myColl.createIndex( { name: 1 } )This will create a single key ascending index on name field in myColl collection
-
Compound Index
You can also create an index on multiple fields using Compound indexes. For this index, order of the fields in which they are defined in the index matters. Consider this example:
db.myColl.createIndex({ name: 1, score: -1 })This index will first sort the collection by name in ascending order and then for each name value, it will sort by score values in descending order.
-
Multikey Index
This index can be used to index array data. If any field in a collection has an array as its value then you can use this index which will create separate index entries for each elements in array. If the indexed field is an array, then MongoDB will automatically create Multikey index on it.
Consider this example:
{ ‘userid’: 1, ‘name’: ‘mongo’, ‘addr’: [ {zip: 12345, ...}, {zip: 34567, ...} ] }You can create a Multikey index on addr field by issuing this command in Mongo shell.
db.myColl.createIndex({ addr.zip: 1 }) -
Geospatial Index
Suppose you have stored some coordinates in MongoDB collection. To create index on this type fields(which has geospatial data), you can use a Geospatial index. MongoDB supports two types of geospatial indexes.
-
2d Index: You can use this index for data which is stored as points on 2D plane.
db.collection.createIndex( {: "2d" } ) -
2dsphere Index: Use this index when your data is stored as GeoJson format or coordinate pairs(longitude, latitude)
db.collection.createIndex( {: "2dsphere" } ) -
-
Text Index
To support queries which includes searching for some text in the collection, you can use Text index.
Example:
db.myColl.createIndex( { address: "text" } ) -
Hashed Index
MongoDB supports hash-based sharding. Hashed index computes the hash of the values of the indexed field. Hashed index supports sharding using hashed sharded keys. Hashed sharding uses this index as shard key to partition the data across your cluster.
Example:
db.myColl.createIndex( { _id: "hashed" } )
-
Unique Index
This property ensures that there are no duplicate values in the indexed field. If any duplicates are found while creating the index, then it will discard those entries.
-
Sparse Index
This property ensures that all queries search documents with indexed field. If any document doesn’t have an indexed field, then it will be discarded from the result set.
-
TTL Index
This index is used to automatically delete documents from a collection after specific time interval(TTL) . This is ideal for removing documents of event logs or user sessions.
Performance Analysis
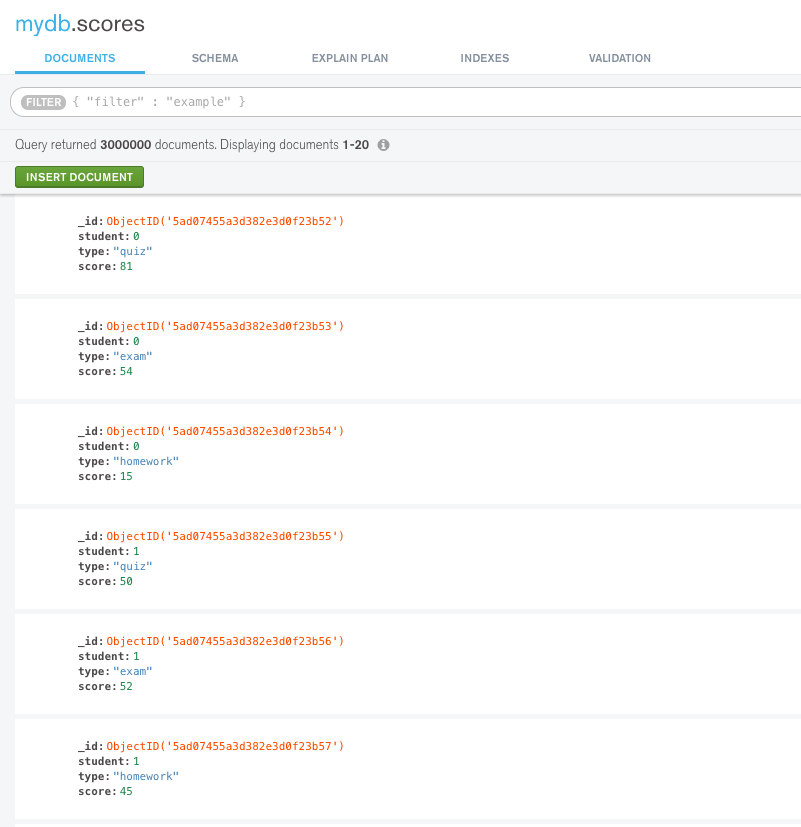
Consider a collection of student scores. It has exactly 3000000 documents in it. We haven’t created any indexes in this collection. See this image below to understand the schema.
Now, consider this query without any indexes:
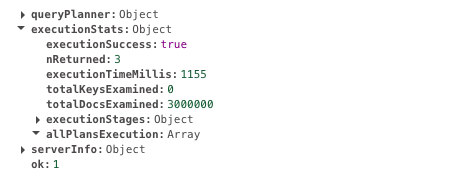
db.scores.find({ student: 585534 }).explain("executionStats")This query takes 1155ms to execute. Here is the output. Search for executionTimeMillis field for the result.
Now let’s create index on student field. To create the index run this query.
db.scores.createIndex({ student: 1 })Now the same query takes 0ms.
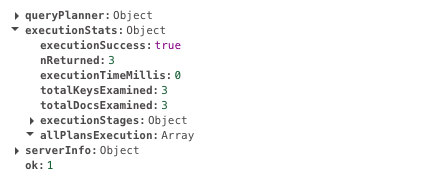
You can clearly see the difference in execution time. It’s almost instantaneous. That’s the power of indexing.
Conclusion
One obvious takeaway is: Create indexes. Based on your queries, you can define different types of indexes on your collections. If you don’t create indexes, then each query will scan the full collections which takes a lot of time making your application very slow and it uses lots of resources of your server. On the other hand, don’t create too many indexes either because creating unnecessary indexes will cause extra time overhead for all insert, delete and update. When you perform any of these operations on an indexed field, then you have to perform the same operation on index tree as well which takes time. Indexes are stored in RAM so creating irrelevant indexes can eat up your RAM space, and slow down your server.



