blog
MongoDB features in ClusterControl 1.4

Our latest release of ClusterControl turns some of the most troublesome MongoDB tasks into a mere 15 second job. New features have been added to give you more control over your cluster and perform topology changes:
- Convert a MongoDB replicaSet to a sharded MongoDB Cluster
- Add and remove shards
- Add shard routers to a sharded MongoDB cluster
- Step down or freeze a node
- New MongoDB advisors
We will describe these added features in depth below.
Convert a MongoDB ReplicaSet to a Sharded MongoDB Cluster
As most MongoDB users will start off with a replicaSet to store their database, this is the most frequently used type of cluster. If you happen to run into scaling issues you can scale this replicaSet by either adding more secondaries or scaling out by sharding. You can convert an existing replicaSet into a sharded cluster, however this is a long process where you could easily make errors. In ClusterControl we have automated this process, where we automatically add the Configservers, shard routers and enable sharding.
To convert a replicaSet into a sharded cluster, you can simply trigger it via the actions drop down:

This will open up a two step dialogue on how to convert this into a shard. The first step is to define where to deploy the Configserver and shard routers to:
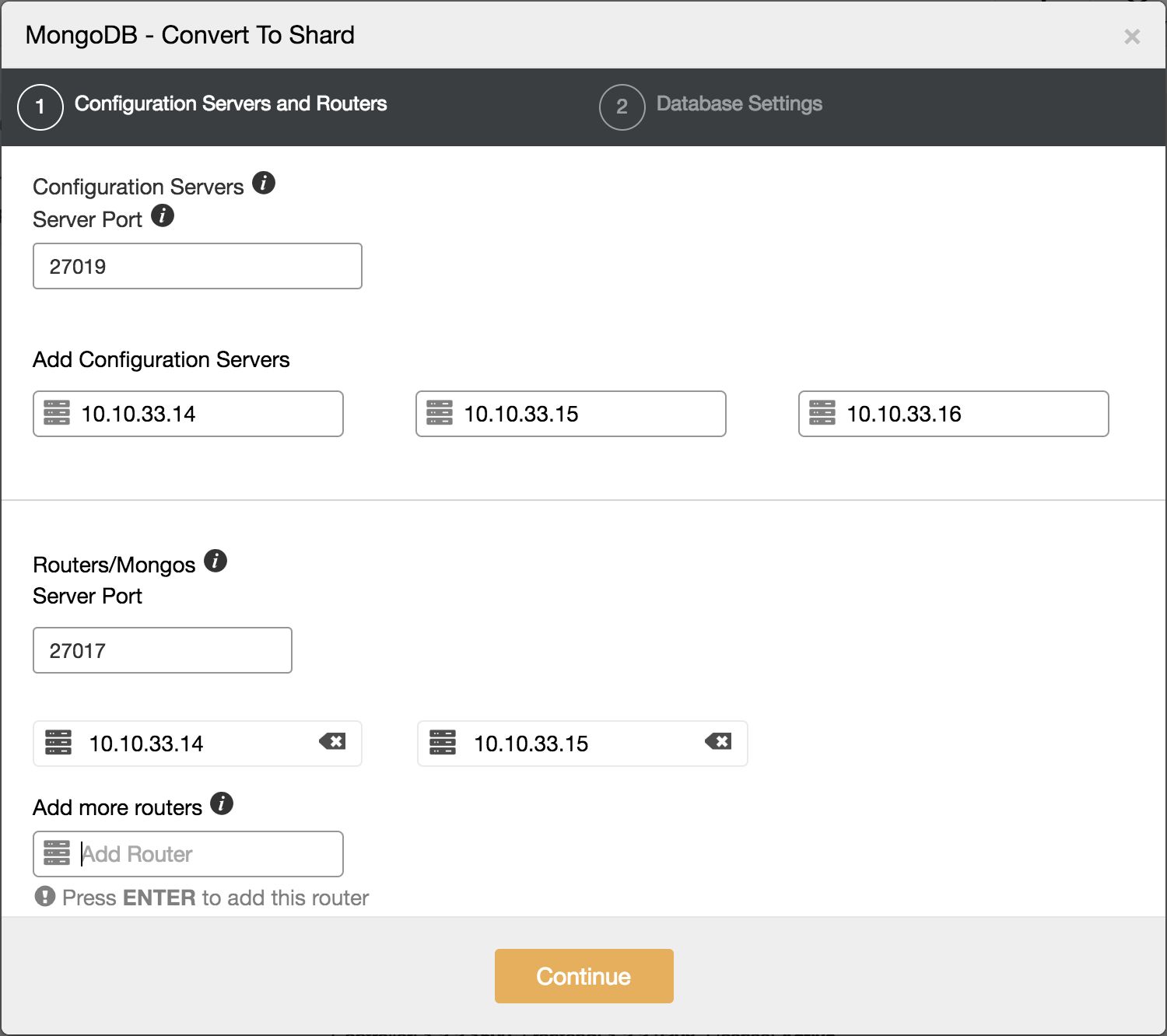
The second step is where to store the data and which config files should be used for the Configserver and shard router.
After the shard migration job has finished, the cluster overview now displays shards instead of replicaSet instances:

After converting to a sharded cluster, new shards can be added.
Add or Remove Shards from a Sharded MongoDB Cluster
Adding Shards
As a MongoDB shard is technically a replicaSet, adding a new shard involves the deployment of a new replicaSet as well. Within ClusterControl we first deploy a new replicaSet and then add it to the sharded cluster.
From the ClusterControl UI, you can easily add new shards with a two step wizard, opened from the actions drop down:

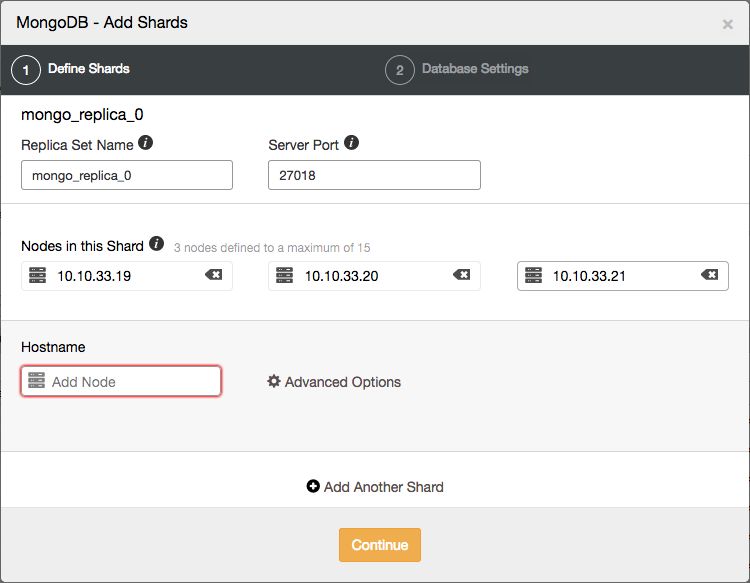
Here you can define the topology of the new shard.
Once the new shard has been added to the cluster, the MongoDB shard router will start to assign new chunks to it, and the balancer will automatically balance all chunks over all the shards.
Removing Shards
Removing shards is a bit harder than to add a shard, as this involves moving the data to the other shards before removing the shard itself. For all data that has been sharded over all shards, this will be a job performed by the MongoDB balancer.
However any non-sharded database/collection, that was assigned this shard as its primary shard, needs to be moved to another shard and made its new primary shard. For this process, MongoDB needs to know where to move these non-sharded databases/collections to.
In ClusterControl you can simply remove them via the actions drop down:

This will allow you to select the shard that you wish to remove, and the shard you wish to migrate any primary databases to:
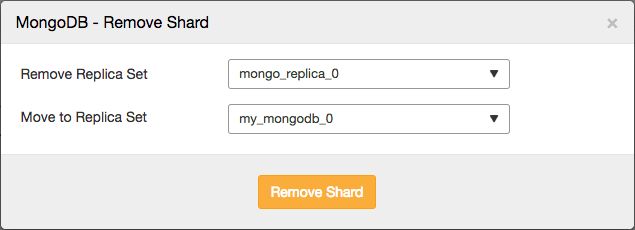
The job that removes the shard will then perform similar actions as described earlier: it will move any primary databases to the designated shard, enable the balancer and then wait for it to move all data from the shard.
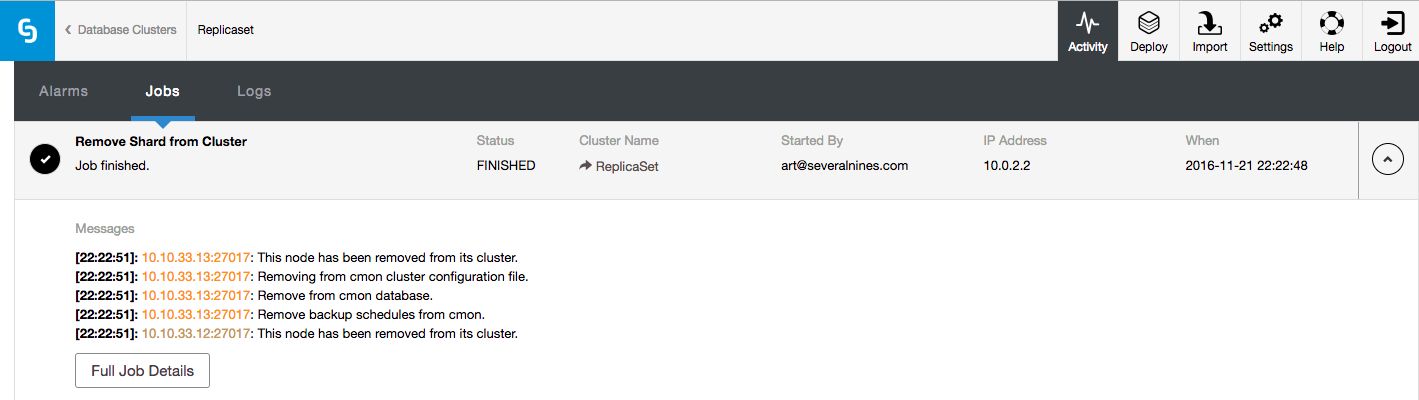
Once all the data has been removed, it will remove the shard from the UI.
Adding Additional MongoDB Shard Routers
Once you start to scale out your application using a MongoDB sharded cluster, you may find you are in need of additional shard routers.
Adding additional MongoDB shard routers is a very simple process with ClusterControl, just open the Add Node dialogue from the actions drop down:
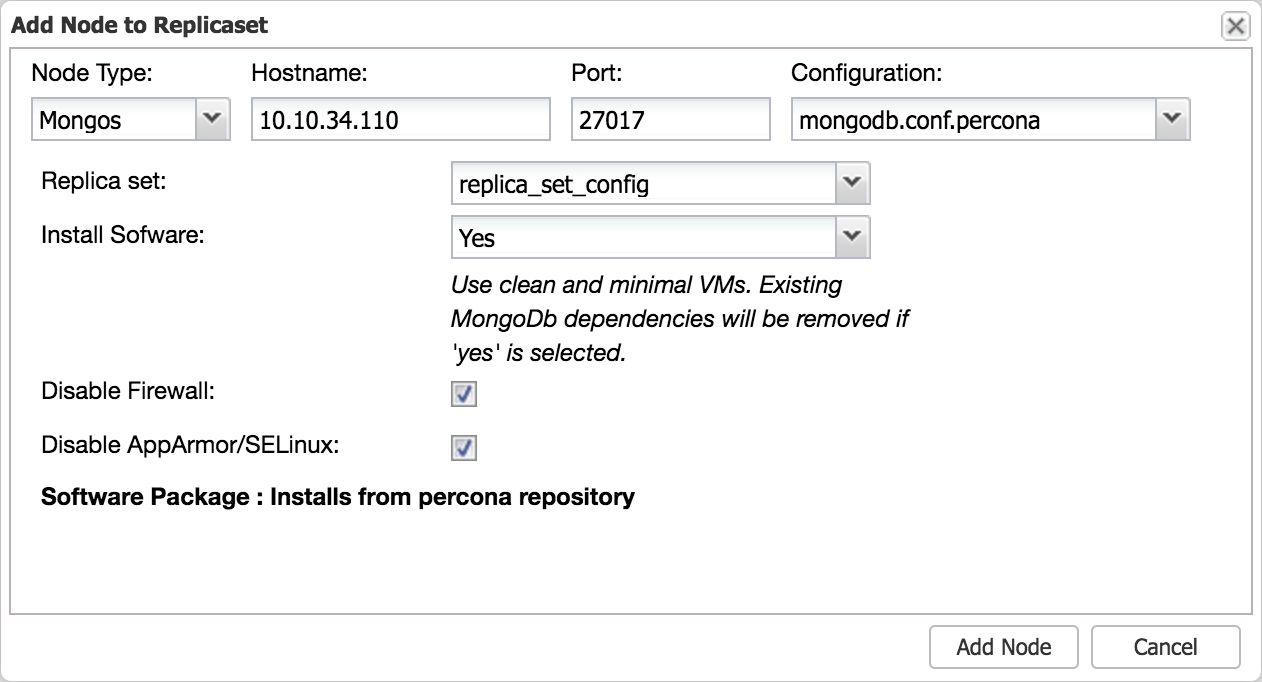
This will add a new shard router to the cluster. Don’t forget to set the proper default port (27017) on the router.
Step Down Server
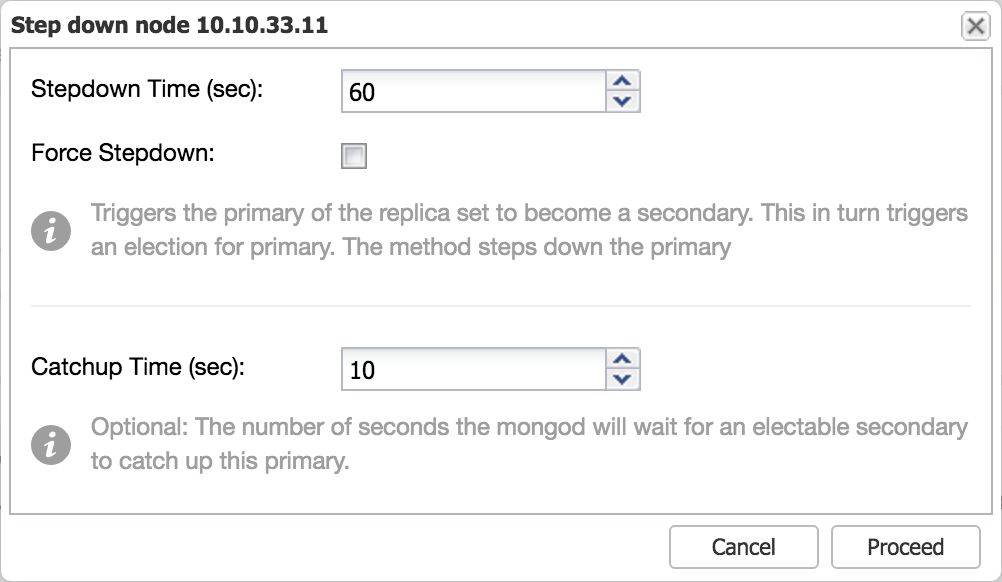
In case you wish to perform maintenance on the primary node in a replicaSet, it is better to have it first “step down” in a graceful manner before taking it offline. Stepping down a primary basically means the host stops being a primary and becomes a secondary and is not eligible to become a primary for a set number of seconds. The nodes in the MongoDB replicaSet with voting power, will elect a new primary with the stepped down primary excluded for the set number of seconds.
In ClusterControl we have added the step down functionality as an action on the Nodes page. To step down, simply select this as an action from the drop down:
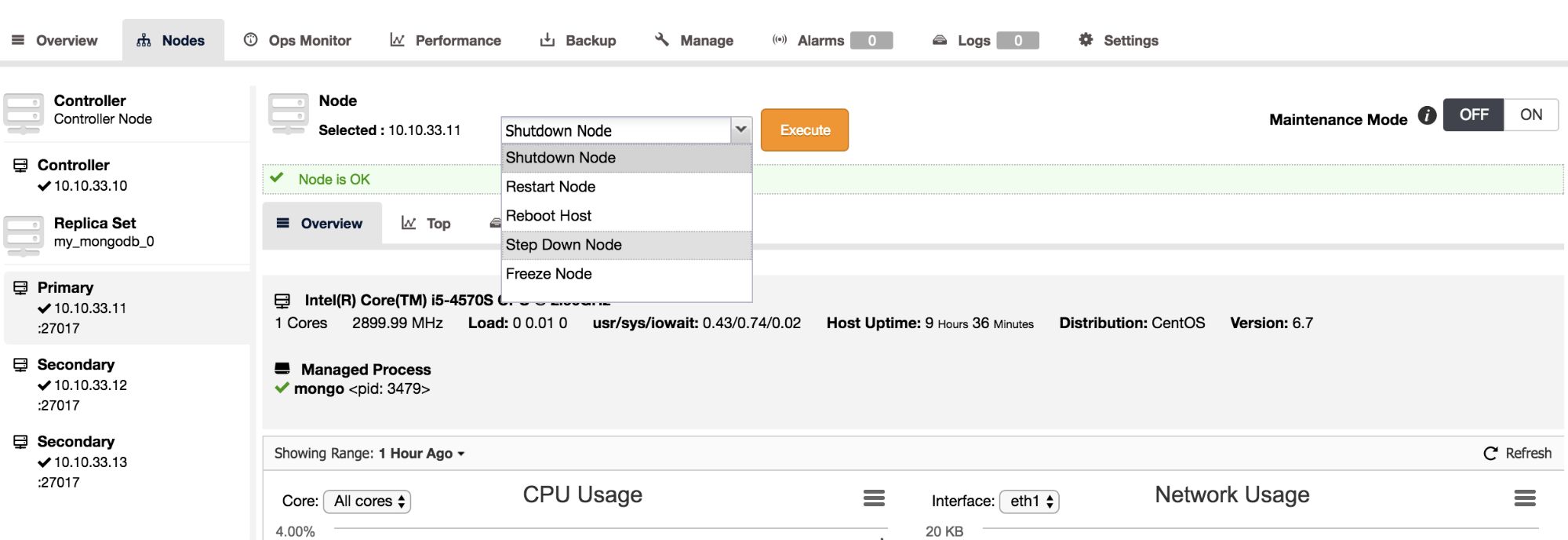
After setting the number of seconds for stepdown and confirming, the primary will step down and a new primary will be elected.
Freeze a Node
This functionality is similar to the step down command: this makes a certain node ineligible to become a primary for a set number of seconds. This means you could prevent one or more secondary nodes to become a primary when stepping down the primary, and force a certain node to become the new primary this way.
In ClusterControl we have added the freeze node functionality as an action on the Nodes page. To freeze a node, simply select this as an action from the drop down:
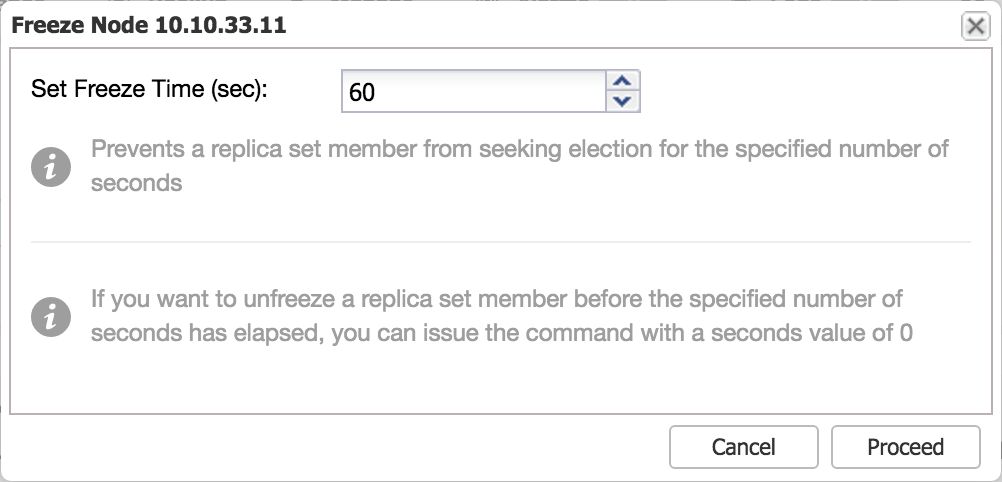
After setting the number of seconds and confirming, the node will not be eligible as primary for the set number of seconds.
New MongoDB Advisors
Advisors are mini programs that provide advice on specific database issues. We’ve added three new advisors for MongoDB. The first one calculates the replication window, the second watches over the replication window, and the third checks for un-sharded databases/collections.
MongoDB Replication Lag Advisor
Replication lag is very important to keep an eye on, if you are scaling out reads via adding more secondaries. MongoDB will only use these secondaries if they don’t lag too far behind. If the secondary has replication lag, you risk serving out stale data that already has been overwritten on the primary.
To check the replication lag, it suffices to connect to the primary and retrieve this data using the replSetGetStatus command. In contrary to MySQL, the primary keeps track of the replication status of its secondaries.
We have implemented this check into an advisor in ClusterControl, to ensure your replication lag will always be watched over.
MongoDB Replication Window Advisor
Just like the replication lag, the replication window is an equally important metric to look at. The lag advisor already informs us of the number of seconds a secondary node is behind the primary/master. As the oplog is limited in size, having slave lag imposes the following risks:
- If a node lags too far behind, it may not be able to catch up anymore as the transactions necessary to catch up are no longer in the oplog of the primary.
- A lagging secondary node is less favoured in a MongoDB election for a new primary. If all secondaries are lagging behind in replication, you will have a problem and one with the least lag will be made primary.
- Secondaries lagging behind are less favoured by the MongoDB driver when scaling out reads with MongoDB, it also adds a higher workload on the remaining secondaries.
If we would have a secondary node lagging behind by a few minutes (or hours), it would be useful to have an advisor that informs us how much time we have left before our next transaction will be dropped from the oplog. The time difference between the first and last entry in the oplog is called the Replication Window. This metric can be created by fetching the first and last items from the oplog, and calculating the difference of their timestamps.
In the MongoDB shell, there is already a function available that calculates the replication window for you. However this function is built into the command line shell, so any outside connection not using the command line shell will not have this built-in function. Therefore we have made an advisor that will watch over the replication window and alerts you if you exceed a pre-set threshold.
MongoDB un-sharded Databases and Collections Advisor
Non-sharded databases and collections will be assigned to a default primary shard by the MongoDB shard router. This means the database or collection is limited to the size of this primary shard, and if written to in large volumes, could use up all remaining disk space of a shard. Once this happens the shard will obviously no longer function. Therefore it is important to watch over all existing databases and collections, and scan the config database to validate that they have been enabled for sharding.
To prevent this from happening, we have created an un-sharded database and collection advisor. This advisor will scan every database and collection, and warn you if it has not been sharded.
ClusterControl improved the MongoDB maintainability
We have made a big step by adding all the improvements to ClusterControl for MongoDB replicaSets and sharded clusters. This improves the usability for MongoDB greatly, and allows DBAs, sysops and devops to maintain their clusters even better!



