blog
Deploying & Managing MySQL NDB Cluster with ClusterControl

In ClusterControl 1.5 we added a support for the MySQL NDB Cluster 7.5. In this blog post, we’ll look at some of the features that make ClusterControl a great tool to manage MySQL NDB Cluster. First and foremost, as there are numerous products with “Cluster” in their name, we’d like to say couple of words about MySQL NDB Cluster itself and how it differentiates from other solutions.
MySQL NDB Cluster
MySQL NDB Cluster is a shared-nothing synchronous cluster for MySQL, based on the NDB engine. It is a product with its own list of features, and quite different from Galera Cluster or MySQL InnoDB Cluster. One main difference is the use of NDB engine, not InnoDB, which is the default engine for MySQL. In NDB cluster, data is partitioned across multiple data nodes while Galera Cluster or MySQL InnoDB Cluster contain the full data set on each of the nodes. This has serious repercussions in the way MySQL NDB Cluster deals with queries which use JOINs and large chunks of the dataset.
When it comes to architecture, MySQL NDB Cluster consists of three different node types. Data nodes stores the data using NDB engine. Data is mirrored for redundancy, with up to 4 replicas of data. Note that ClusterControl will deploy 2 replicas per node group, as this is the most tested and stable configuration. Management nodes are intended to control the cluster – for high availability reasons, typically, you have two such nodes. SQL nodes are used as the entry points to the cluster. They parse SQL, ask for data from the data nodes and aggregate result sets when needed.
ClusterControl features for MySQL NDB Cluster
Deployment
ClusterControl 1.5 supports deployment of MySQL NDB Cluster 7.5. It’s done through the same deployment wizard like with the remaining cluster types.
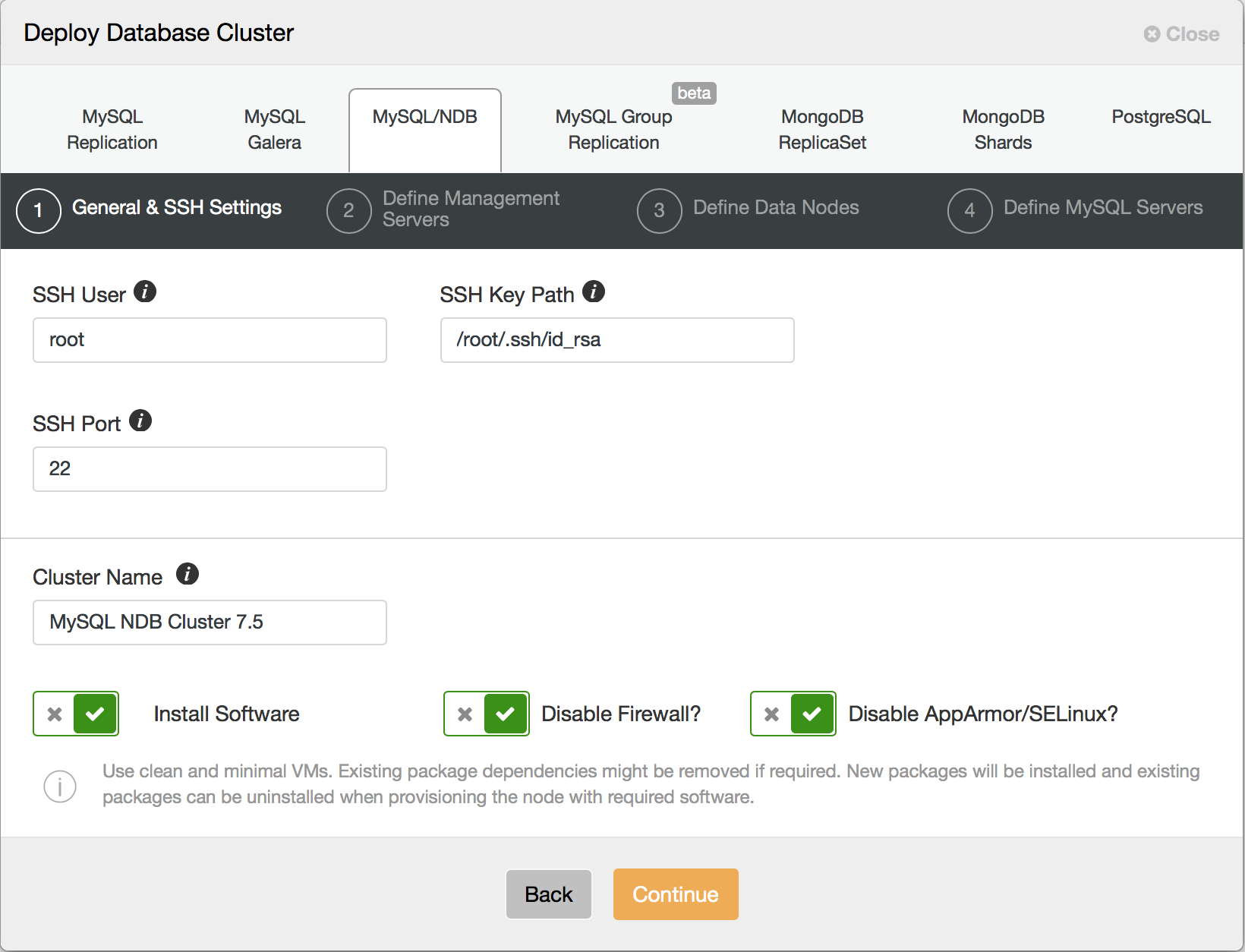
In the first step, you need to configure how ClusterControl can login via SSH to the hosts – this is a standard requirement for ClusterControl – it is agentless so it requires root SSH access either directly, to the root account or via (password or passwordless) sudo.
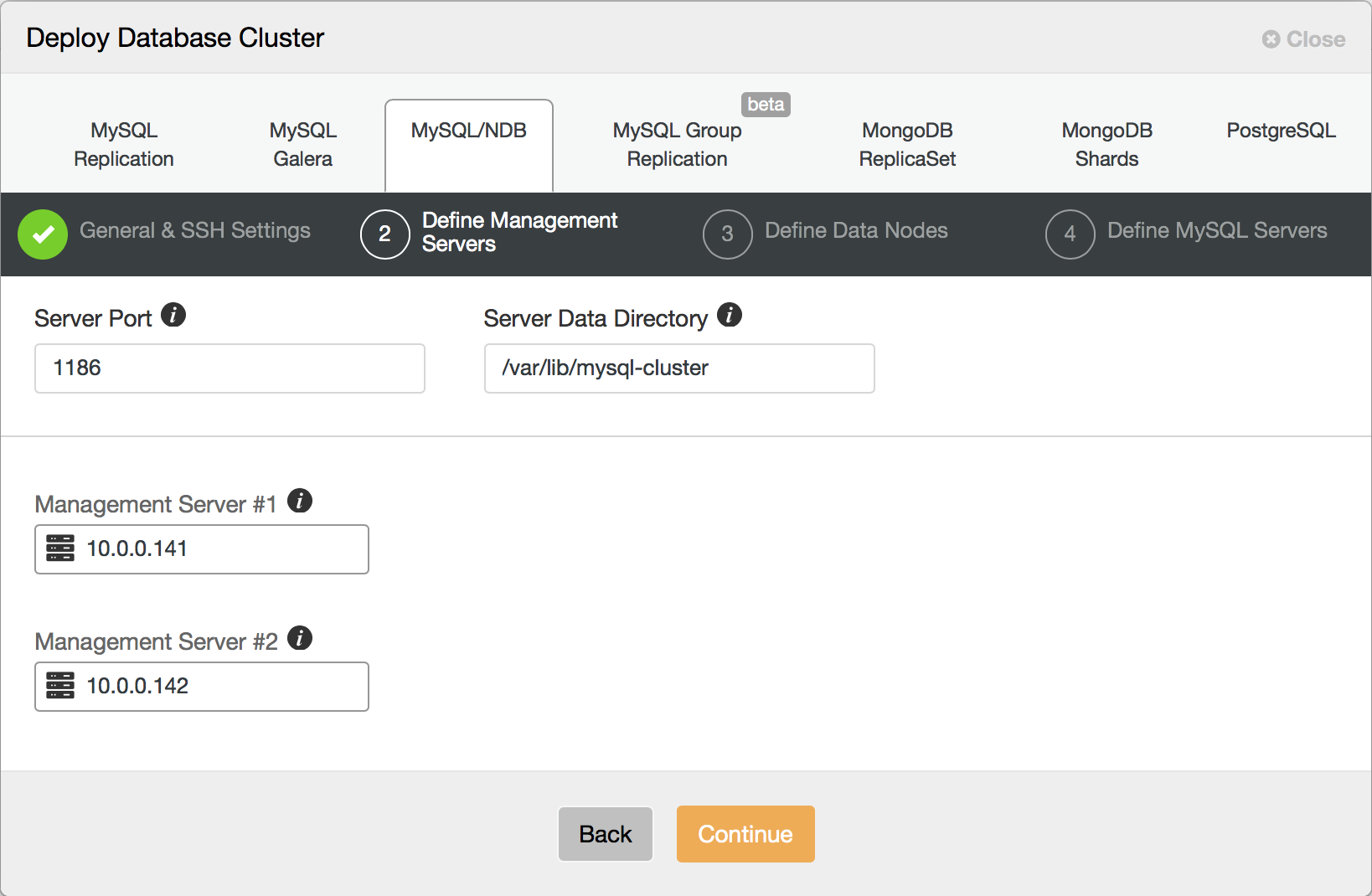
In the next step, you define management nodes for your cluster.
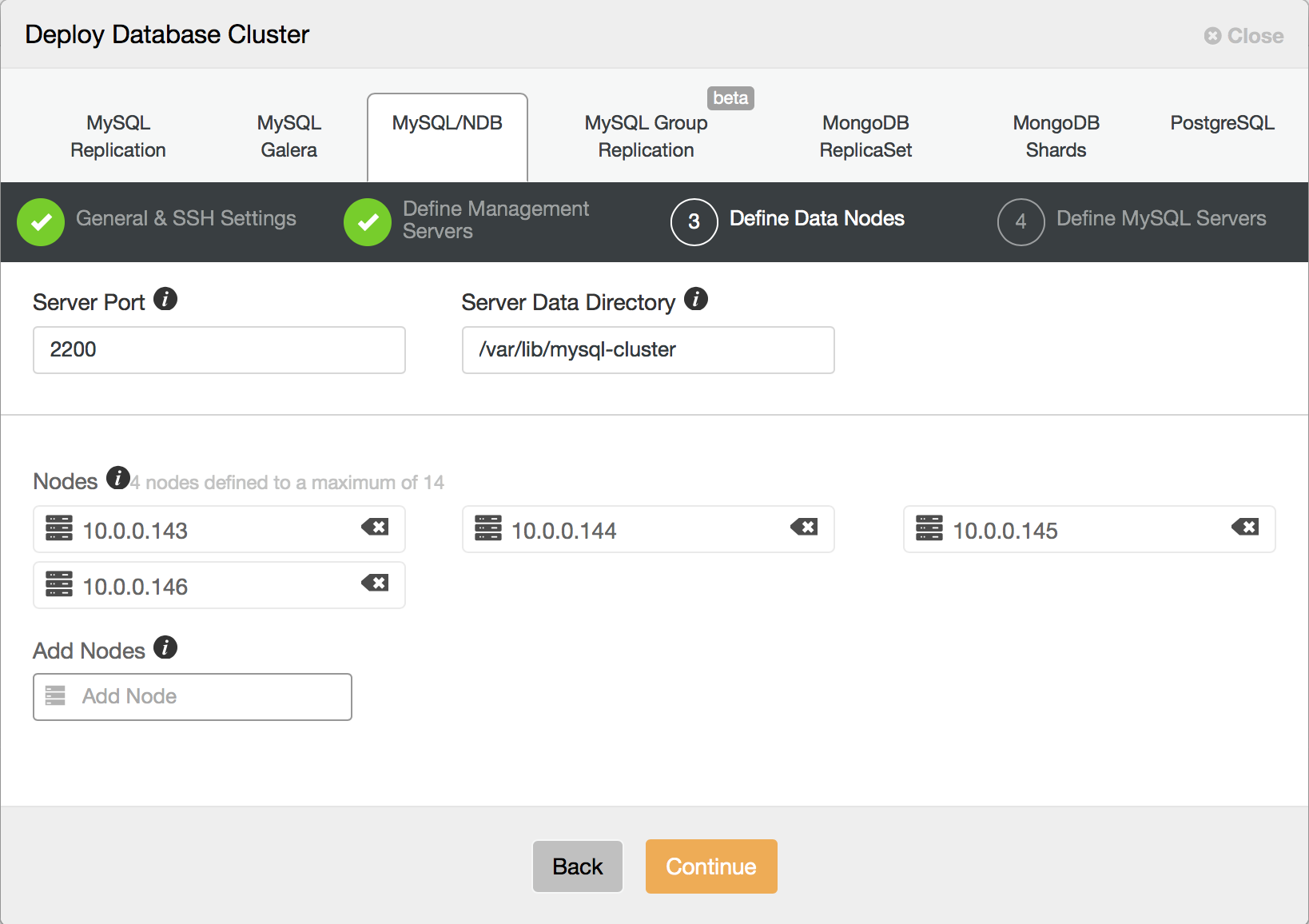
Here, you need to decide how many data nodes you’d like to have. As we previously stated, every 2 nodes will be part of a node group so this should be an even number.
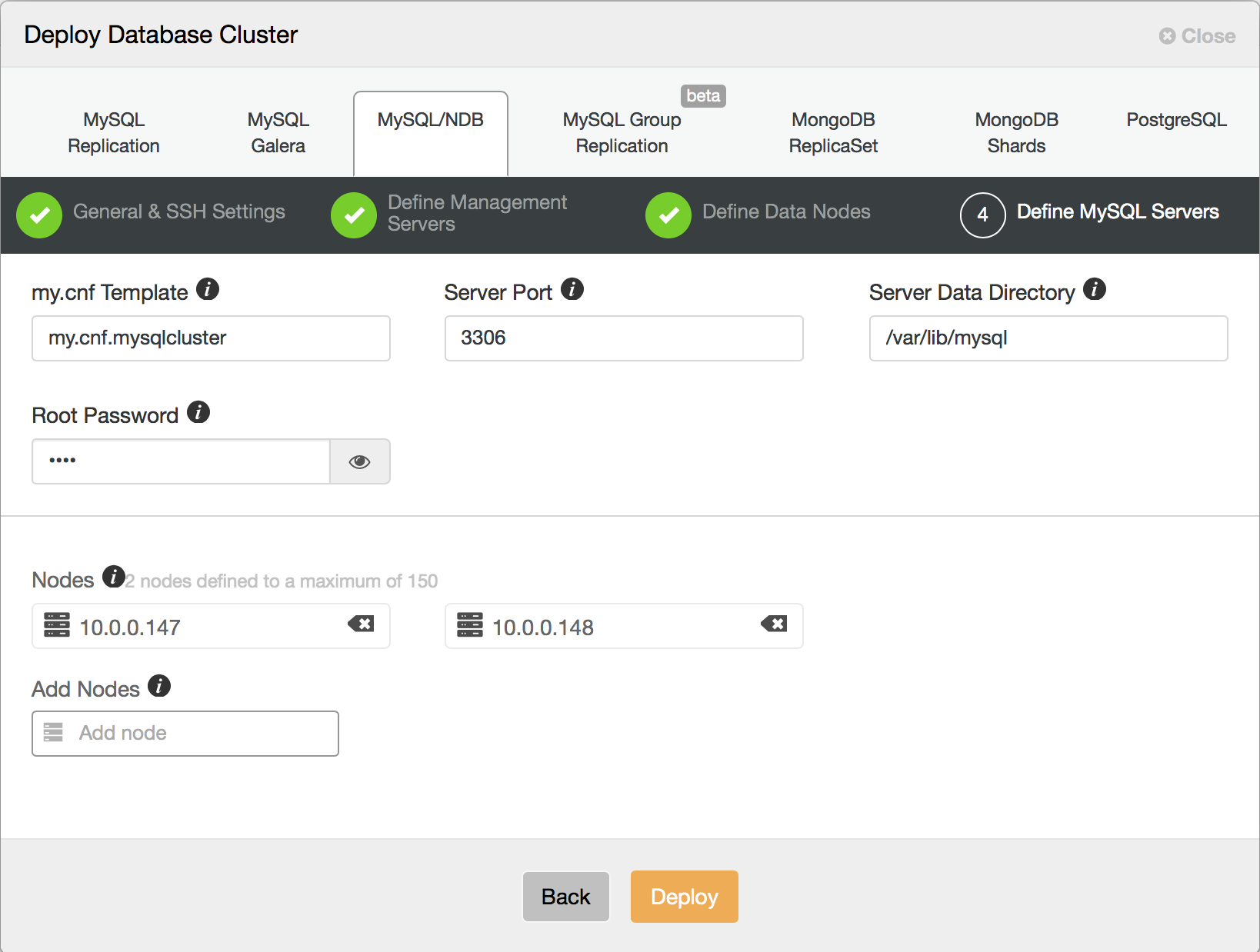
Finally, you need to decide how many SQL nodes you’d like to deploy in your cluster. Once you click deploy, ClusterControl will connect to the hosts, install the software and configure all services. After a while, you should see your cluster deployed.
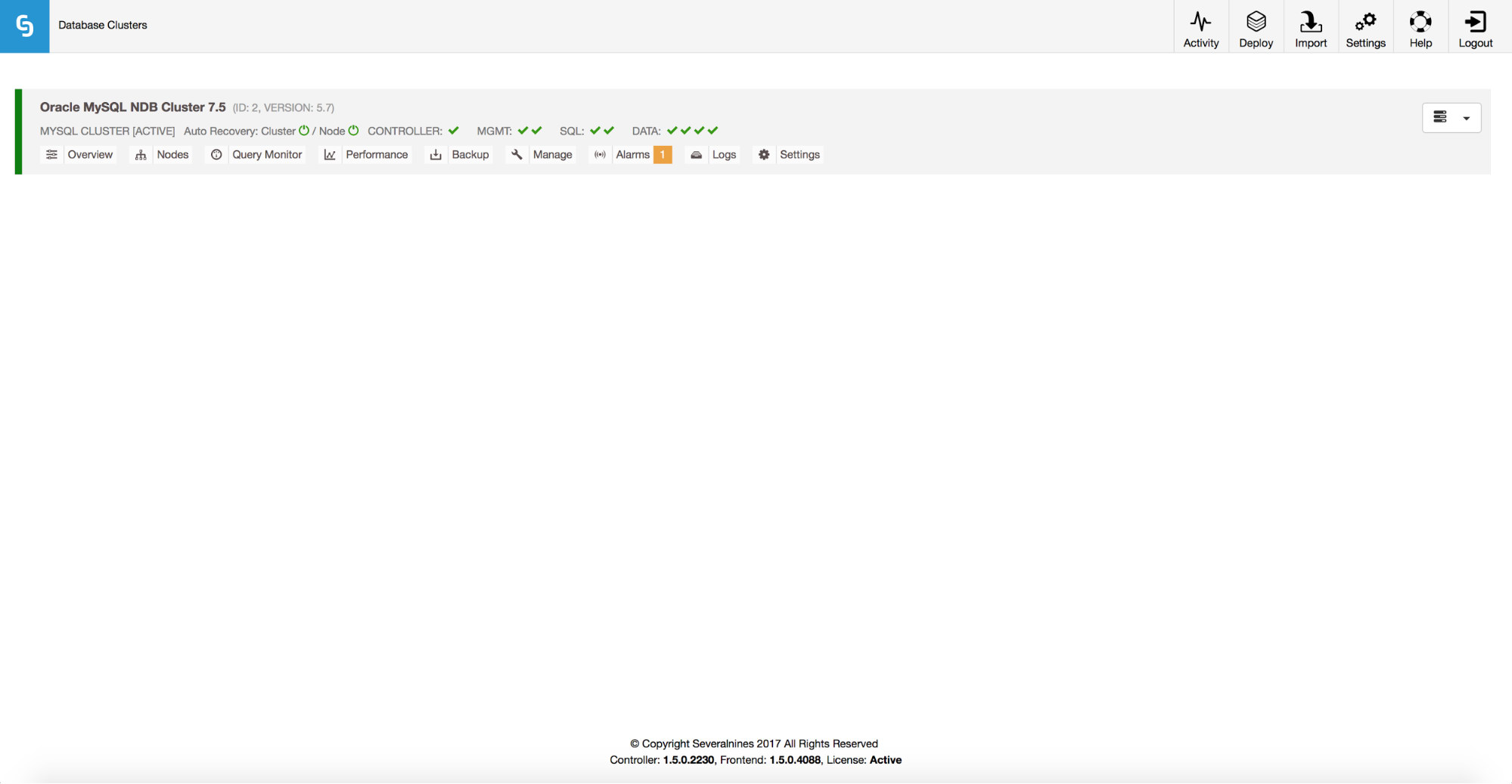
Scaling of MySQL NDB Cluster
For MySQL NDB Cluster, ClusterControl 1.5.0 supports scaling of SQL nodes. You can access the job from the Cluster jobs dropdown.
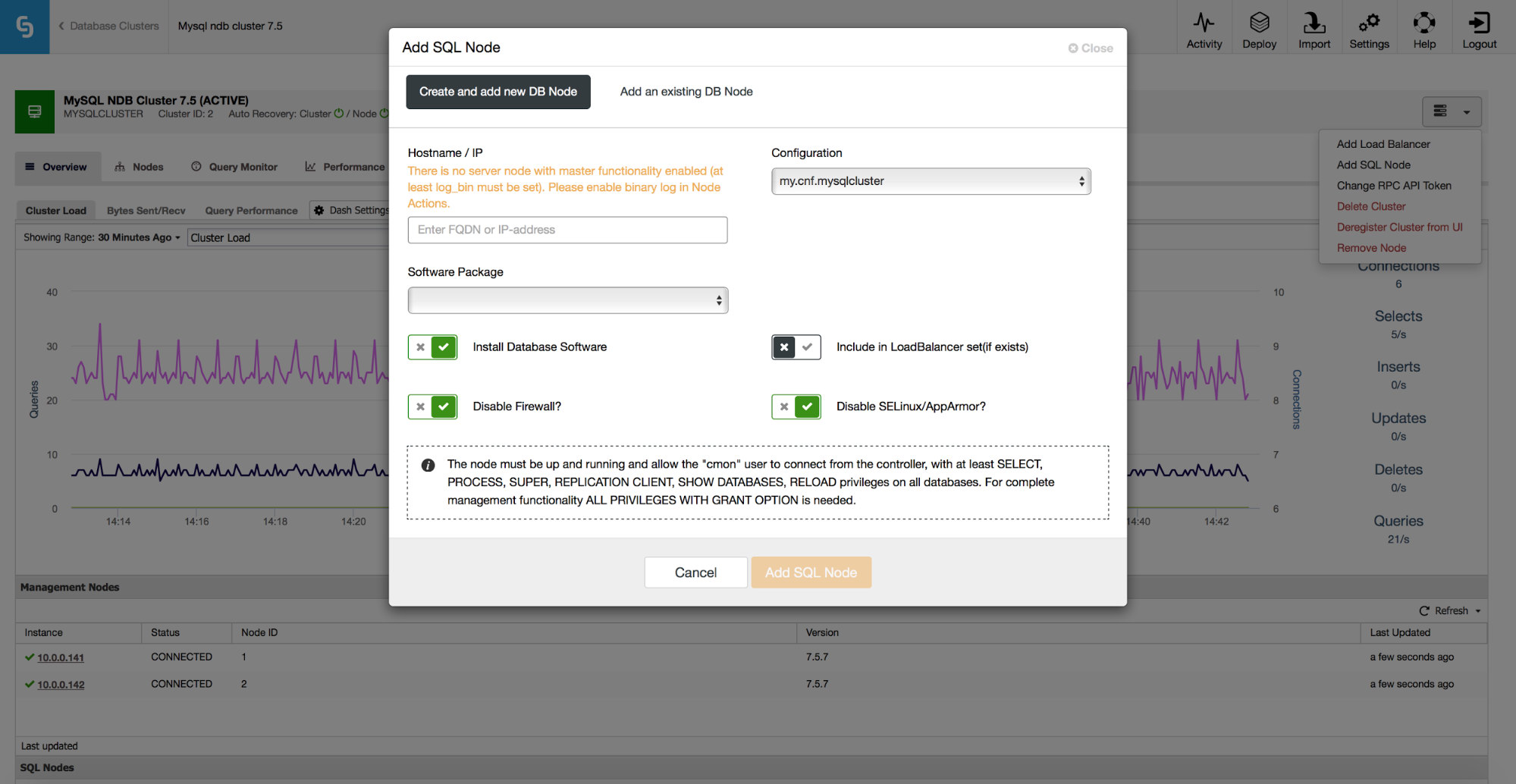
There you can fill in the hostname of the node you’d like to add and that’s all you need – ClusterControl will take care of the rest.
Management of MySQL NDB Cluster
ClusterControl helps you manage MySQL NDB Cluster. In this section we’d like to go through some of the management features that we have.
Backups
Backups are crucial for any production environment. In case of disaster, only a good backup can minimize the data loss and help you to quickly recover from the issue. Replication might not always be a solution that works – DROP TABLE will drop the table on all of the hosts in the topology. Even a delayed slave can delay the inevitable only by so much.
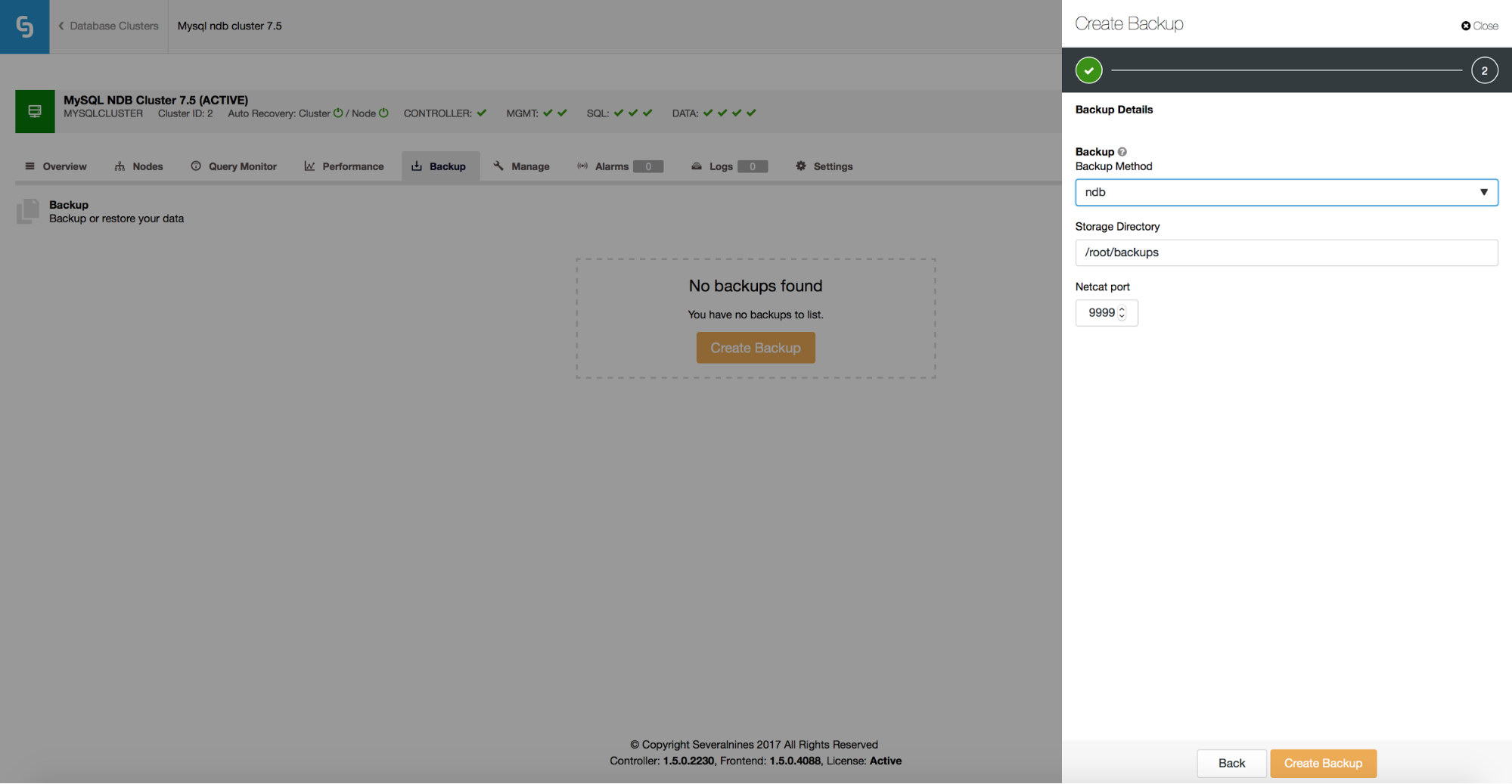
ClusterControl supports ndb backup for MySQL NDB Cluster.
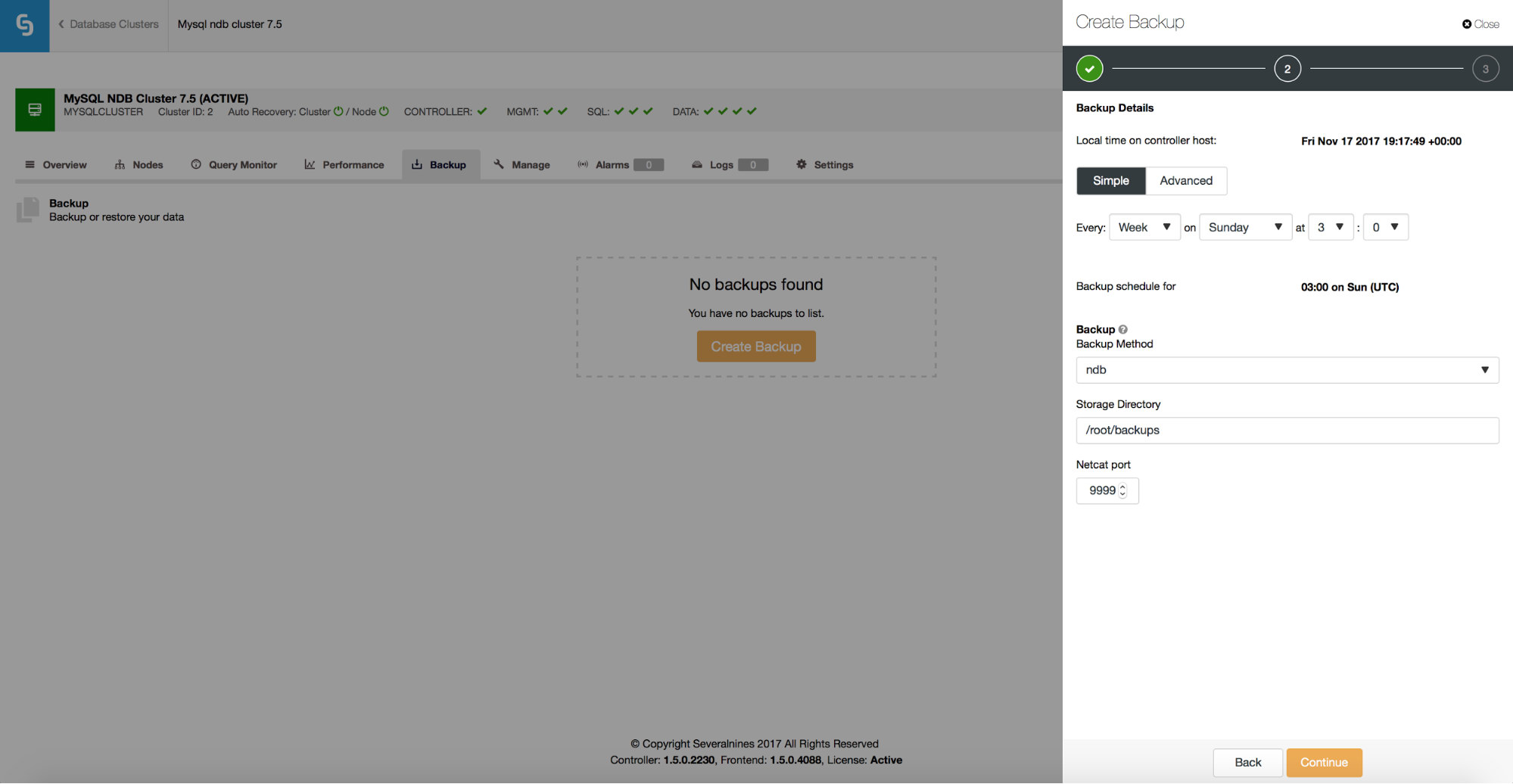
You can easily create a backup schedule to be executed by ClusterControl.
Proxy layer
ClusterControl lets you deploy a full high availability stack on top of the MySQL NDB Cluster. For the proxy layer, we support deployment of HAProxy and MaxScale.
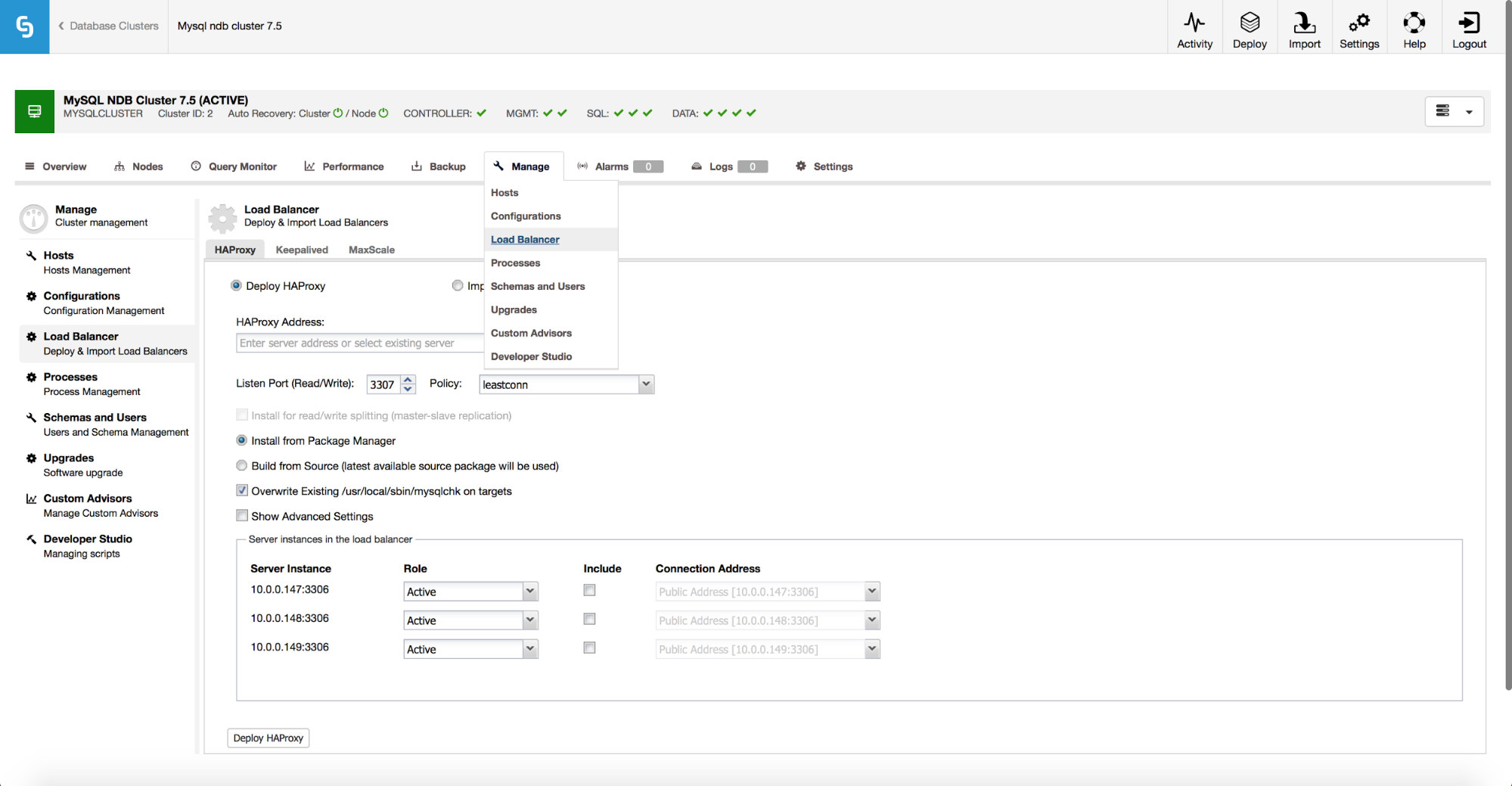
As shown on the screenshot above, deployment looks very similar to the other cluster types. You need to decide if you want to use an existing HAProxy or deploy a new one. Then you need to make a choice how to install it – using packages from repositories available on the node or compile it from the source code of the latest release.
If you decide to use HAProxy, you will have the possibility to configure high availability using Keepalived and Virtual IP.
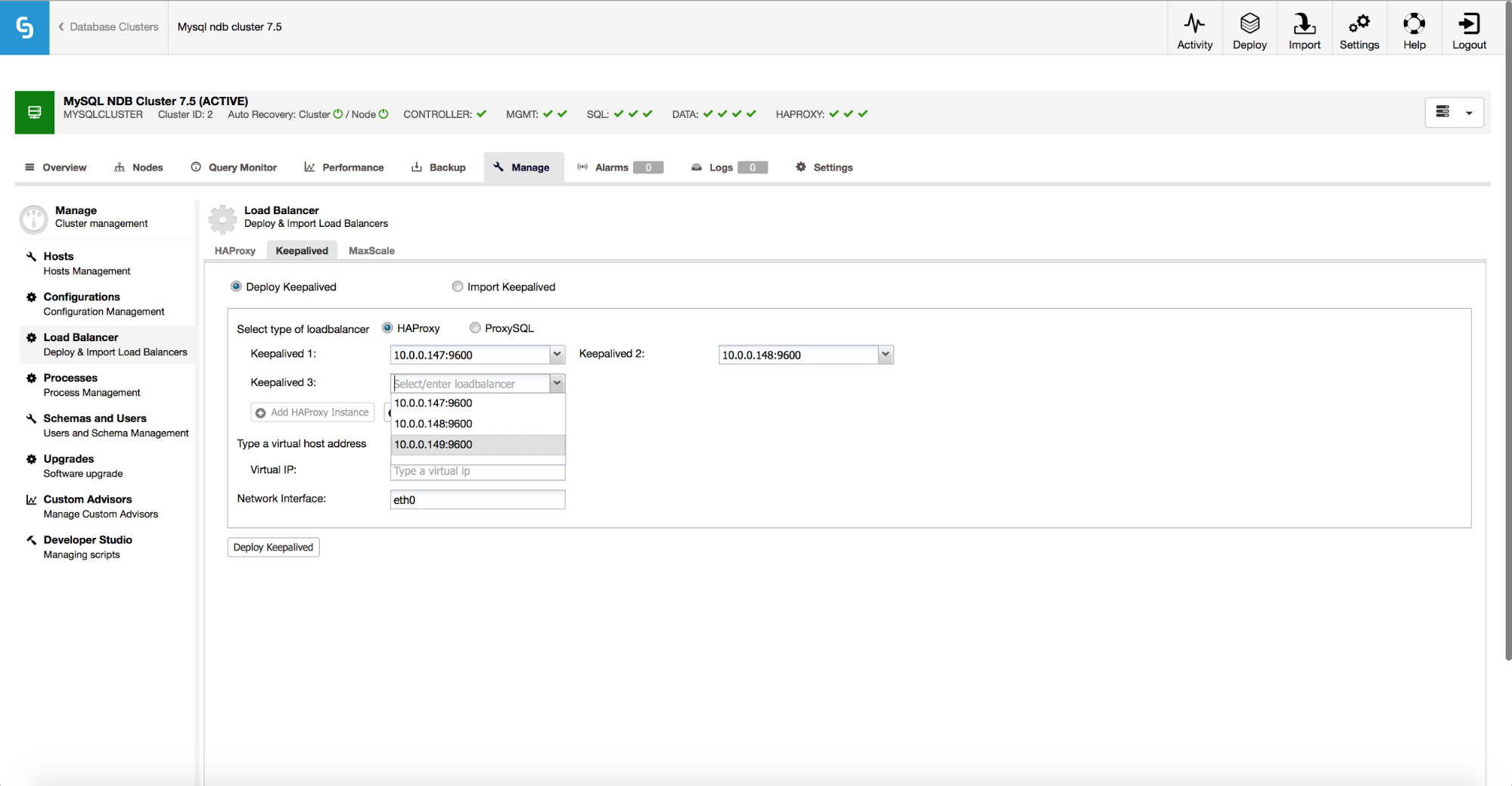
The process is the following – you define a Virtual IP and the interface on which it should be brought up. Then, you can deploy it for every HAProxy that you have installed. One of the Keepalived processes will be determined as a “master” and it’ll enable VIP on its node. Your application then connects to this particular IP. When a current active HAProxy is not available, the VIP will be moved to another available HAProxy, restoring the connectivity.
Recovery management
While MySQL NDB Cluster can tolerate failures of individual nodes, it is important to promptly react to these. ClusterControl provides automated recovery for all components of the cluster. No matter what fails (management node, data node or SQL node), ClusterControl will automatically restart them.
Monitoring of the MySQL NDB Cluster
Any production-ready environment has to be monitored. ClusterControl provides you with a range of metrics to monitor. In the “Overview” page, we show graphs based on the most important metrics for your cluster. You can also create your own dashboards, showing additional data that would be useful in your environment.
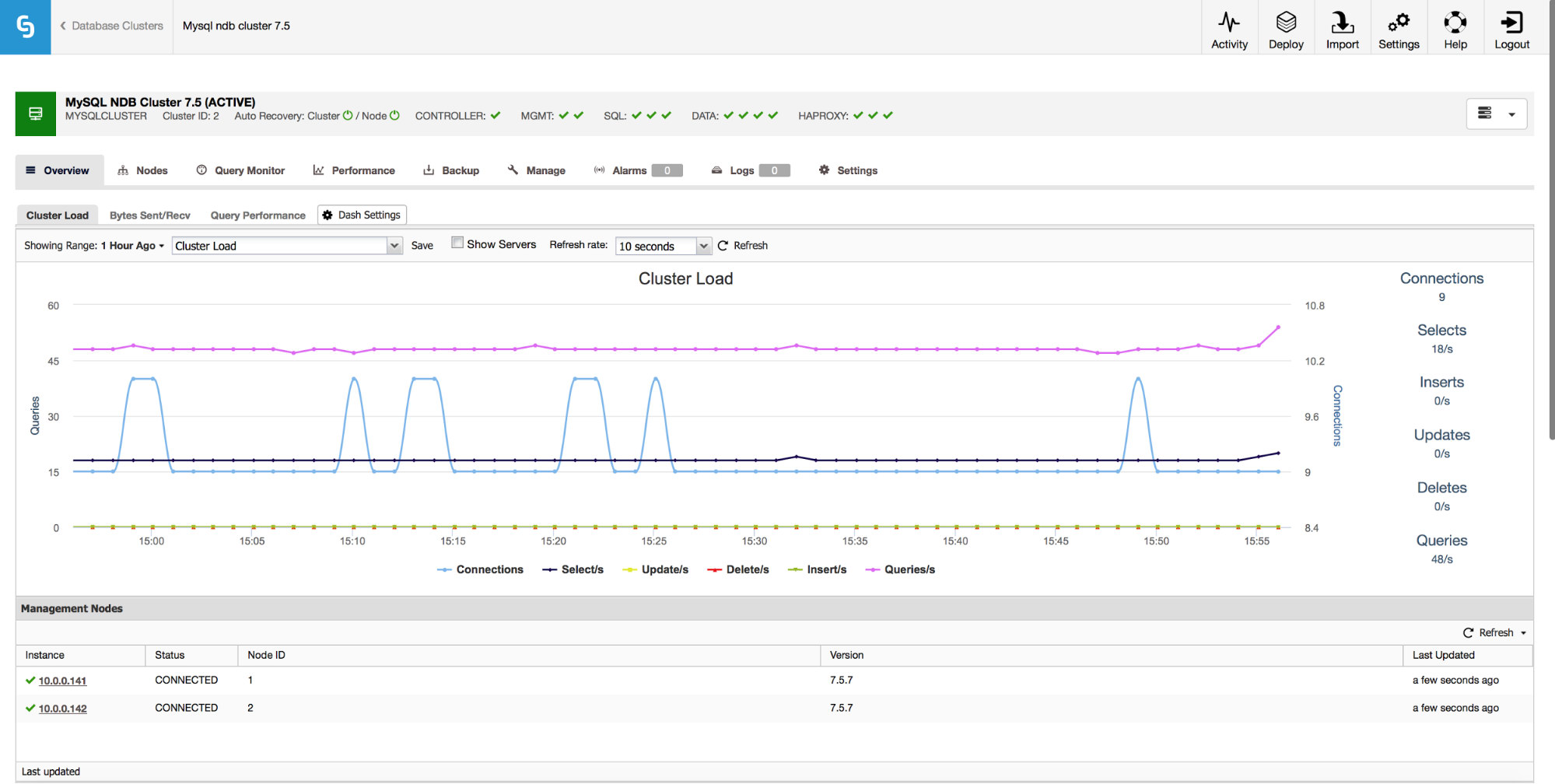
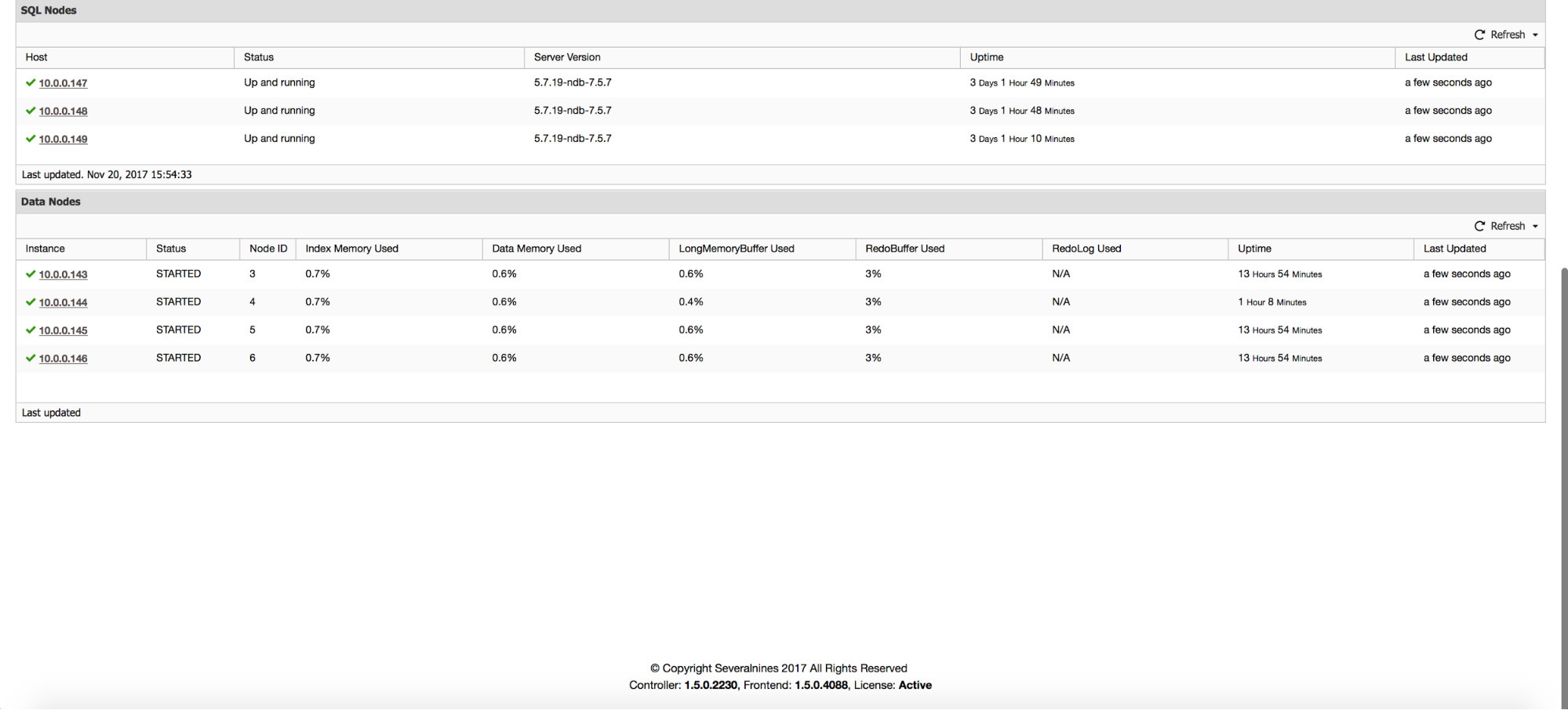
In addition to the graphs, the “Overview” page gives you insights into the state of the cluster based on some MySQL NDB Cluster metrics like used Index Memory, Data Memory and state of some buffers.
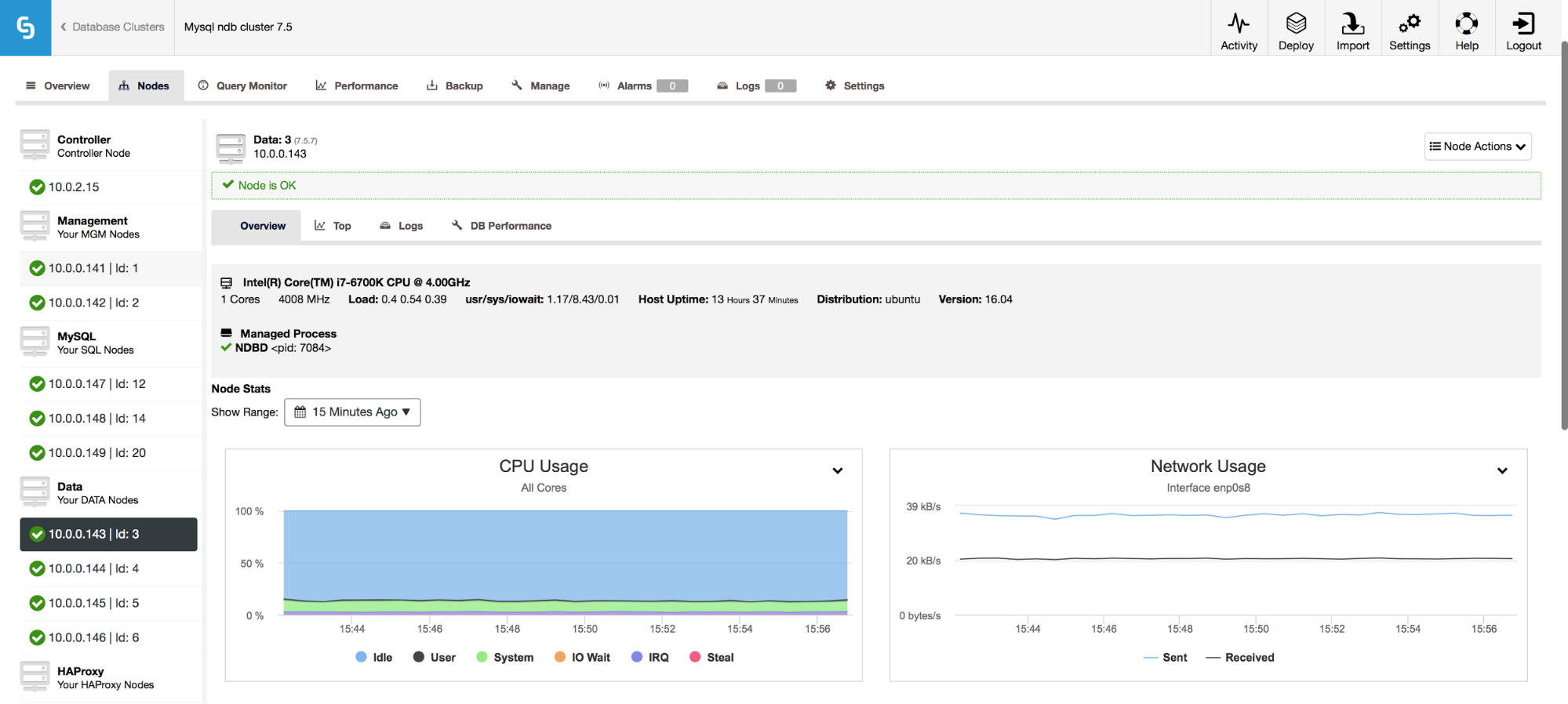
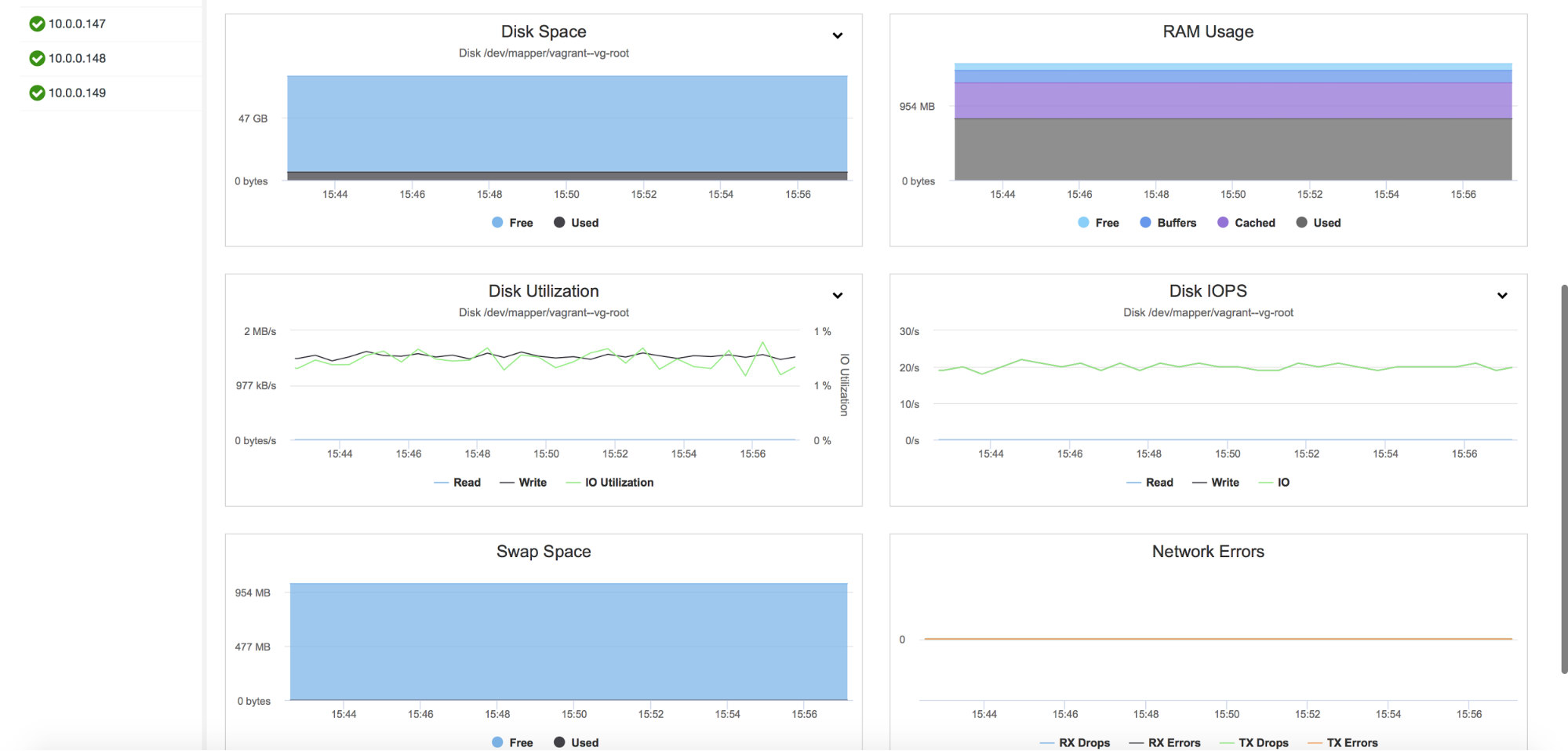
It also provides monitoring of the host metrics, including CPU utilization, RAM, Disk or Network stats. Those graphs are also crucial in building a view of the health of the cluster.
ClusterControl can also help you to improve performance of your databases by giving you access to the Query Monitor, which holds statistics about your traffic.
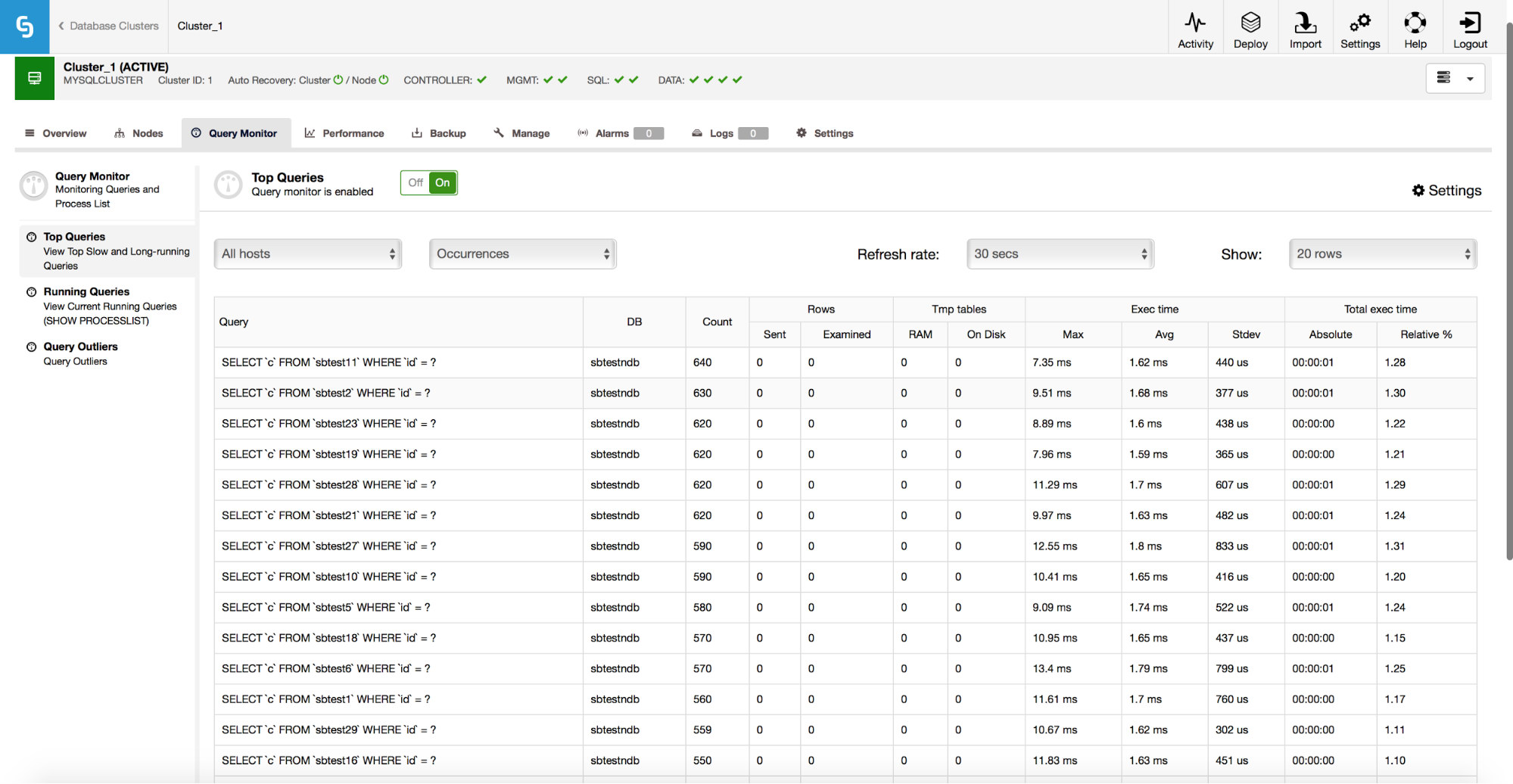
As seen on the screenshot above, you can see what kind of queries are running against your cluster, how many queries of a given type, what are their execution times and the total execution times. This helps identify which queries are slow and which of them are responsible for the majority of the traffic. You can then focus on the queries which can provide you with the biggest performance improvement.



