blog
Troubleshooting MySQL Replication: Part Two

In Troubleshooting MySQL Replication: Part One, we discussed how to verify that MySQL Replication is in good shape. We also looked at some of the typical problems. In this post, we will have a look at some more issues that you might see when dealing with MySQL replication.
Missing or Duplicated Entries
This is something which should not happen, yet it happens very often – a situation in which an SQL statement executed on the master succeeds but the same statement executed on one of slaves fails. Main reason is slave drift – something (usually errant transactions but also other issues or bugs in the replication) causes the slave to differ from its master. For example, a row which existed on the master does not exist on a slave and it cannot be deleted or updated. How often this problem shows up depends mostly on your replication settings. In short, there are three ways in which MySQL stores binary log events. First, “statement”, means that SQL is written in plain text, just as it has been executed on a master. This setting has the highest tolerance on slave drift but it’s also the one which cannot guarantee slave consistency – it’s hard to recommend to use it in production. Second format, “row”, stores the query result instead of query statement. For example, an event may look like below:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4This means that we are updating a row in ‘tab’ table in ‘test’ schema where first column has a value of 2 and second column has a value of 5. We set first column to 2 (value doesn’t change) and second column to 4. As you can see, there’s not much room for interpretation – it’s precisely defined which row is used and how it’s changed. As a result, this format is great for slave consistency but, as you can imagine, it’s very vulnerable when it comes to data drift. Still it is the recommended way of running MySQL replication.
Finally, the third one, “mixed”, works in a way that those events which are safe to write in the form of statements use “statement” format. Those which could cause data drift will use “row” format.
How do you Detect Them?
As usual, SHOW SLAVE STATUS will help us identify the problem.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229As you can see, errors are clear and self-explanatory (and they are basically identical between MySQL and MariaDB.
How do you fix the Issue?
This is, unfortunately the complex part. First of all, you need to identify a source of truth. Which host contains the correct data? Master or slave? Usually you’d assume it’s the master but don’t assume it by default – investigate! It could be that after failover, some part of the application still issued writes to the old master, which now acts as a slave. It could be that read_only hasn’t been set correctly on that host or maybe the application uses superuser to connect to database (yes, we’ve seen this in production environments). In such case, the slave could be the source of truth – at least to some extent.
Depending on which data should stay and which should go, the best course of action would be to identify what’s needed to get replication back in sync. First of all, replication is broken so you need to attend to this. Log into the master and check the binary log even that caused replication to break.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671As you can see, we miss one event: 5d1e2227-07c6-11e7-8123-080027495a77:1106672. Let’s check it in the master’s binary logs:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;We can see it was an insert which sets first column to 3 and second to 7. Let’s verify how our table looks like now:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Now we have two options, depending on which data should prevail. If correct data is on the master, we can simply delete row with id=3 on the slave. Just make sure you disable binary logging to avoid introducing errant transactions. On the other hand, if we decided that the correct data is on the slave, we need to run REPLACE command on the master to set row with id=3 to correct content of (3, 10) from current (3, 7). On the slave, though, we will have to skip current GTID (or, to be more precise, we will have to create an empty GTID event) to be able to restart replication.
Deleting a row on a slave is simple:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Inserting an empty GTID is almost as simple:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Another method of solving this particular issue (as long as we accept the master as a source of truth) is to use tools like pt-table-checksum and pt-table-sync to identify where the slave is not consistent with its master and what SQL has to be executed on the master to bring the slave back in sync. Unfortunately, this method is rather on the heavy side – lots of load is added to master and a bunch of queries are written into the replication stream which may affect lag on slaves and general performance of the replication setup. This is especially true if there is a significant number of rows which need to be synced.
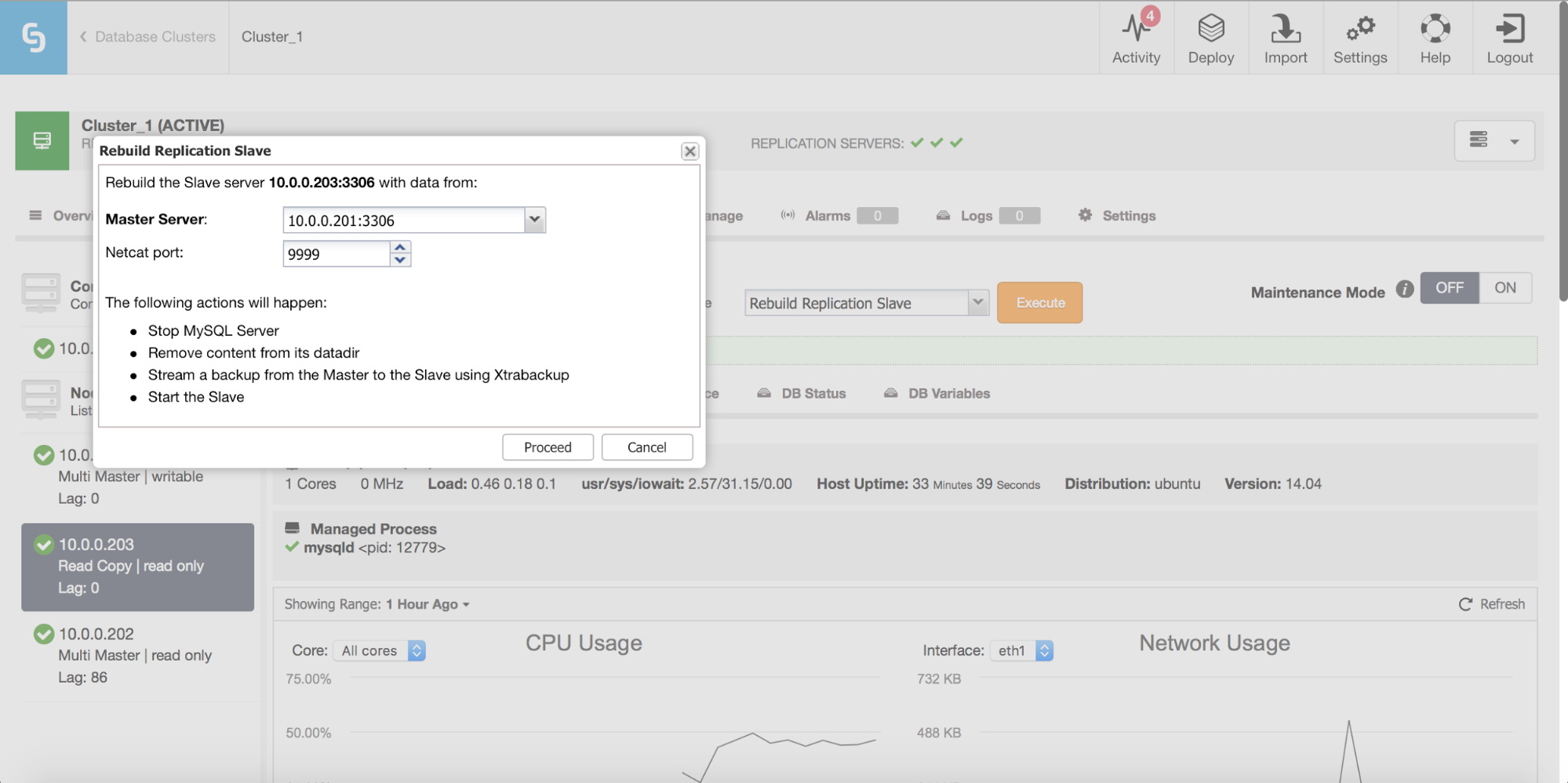
Finally, as always, you can rebuild your slave using data from the master – in this way you can be sure that the slave will be refreshed with the freshest, up-to-date data. This is, actually, not necessarily a bad idea – when we are talking about large number of rows to sync using pt-table-checksum/pt-table-sync, this comes with significant overhead in replication performance, overall CPU and I/O load and man-hours required.
ClusterControl allows you to rebuild a slave, using a fresh copy of the master data.
Consistency Checks
As we mentioned in the previous chapter, consistency can become a serious issue and can cause lots of headaches for users running MySQL replication setups. Let’s see how you can verify that your MySQL slaves are in sync with the master and what you can do about it.
How to Detect an Inconsistent Slave
Unfortunately, the typical way an user gets to know that a slave is inconsistent is by running into one of the issues we mentioned in the previous chapter. To avoid that proactive monitoring of slave consistency is required. Let’s check how it can be done.
We are going to use a tool from Percona Toolkit: pt-table-checksum. It is designed to scan replication cluster and identify any discrepancies.
We built a custom scenario using sysbench and we introduced a bit of inconsistency on one of the slaves. What’s important (if you’d like to test it like we did), you need to apply a patch below to force pt-table-checksum to recognize ‘sbtest’ schema as non-system schema:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}At first, we are going to execute pt-table-checksum in following way:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Couple of important notes on how we invoked the tool. First of all, user that we set has to exists on all slaves. If you want, you can also use ‘–slave-user’ to define other, less privileged user to access slaves. Another thing worth explaining – we use row-based replication which is not fully compatible with pt-table-checksum. If you have row-based replication, what happens is pt-table-checksum will change binary log format on a session level to ‘statement’ as this is the only format supported. The problem is that such change will work only on a first level of slaves which are directly connected to a master. If you have intermediate masters (so, more than one level of slaves), using pt-table-checksum may break the replication. This is why, by default, if the tool detects row-based replication, it exits and prints error:
“Replica slave1 has binlog_format ROW which could cause pt-table-checksum to break replication. Please read “Replicas using row-based replication” in the LIMITATIONS section of the tool’s documentation. If you understand the risks, specify –no-check-binlog-format to disable this check.”
We used only one level of slaves so it was safe to specify “–no-check-binlog-format” and move forward.
Finally, we set maximum lag to 5 seconds. If this threshold will be reached, pt-table-checksum will pause for a time needed to bring the lag under the threshold.
As you could see from the output,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2an inconsistency has been detected on table sbtest.sbtest2.
By default, pt-table-checksum stores checksums in percona.checksums table. This data can be used for another tool from Percona Toolkit, pt-table-sync, to identify which parts of the table should be checked in detail to find exact difference in data.
How to fix Inconsistent Slave
As mentioned above, we will use pt-table-sync to do that. In our case we are going to use data collected by pt-table-checksum although it is also possible to point pt-table-sync to two hosts (the master and a slave) and it will compare all data on both hosts. It is definitely more time- and resource-consuming process therefore, as long as you have already data from pt-table-checksum, it’s much better to use it. This is how we executed it to test the output:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn_h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn_h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;As you can see, as a result some SQL has been generated. Important to note is –replicate variable. What happens here is we point pt-table-sync to table generated by pt-table-checksum. We also point it to master.
To verify if SQL makes sense we used –print option. Please note SQL generated is valid only at the time it’s generated – you cannot really store it somewhere, review it and then execute. All you can do is to verify if the SQL makes any sense and, immediately after, reexecute tool with –execute flag:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeThis should make slave back in sync with the master. We can verify it with pt-table-checksum:
root@vagrant-ubuntu-trusty-64:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8As you can see, there are no diffs anymore in sbtest.sbtest2 table.
We hope you found this blog post informative and useful — but you’re not alone. Check out ClusterControl free for 30 days to see how you can make your MySQL operations more transparent, efficient, and consistent. Otherwise, make sure you sign up for our monthly newsletter and follow us on LinkedIn to get more premium, in-depth content!



