blog
Key Things to Monitor in MongoDB

Enhancing system performance, especially for computer structures, requires a process of getting a good overview of performance. This process is generally called monitoring. Monitoring is an essential part of database management and the detailed performance information of your MongoDB will not only help you to gauge its functional state; but also give a clue on anomalies, which is helpful when doing maintenance. It is essential to identify unusual behaviours and fix them before they escalate into more serious failures.
Some of the types of failures that could arise are…
- Lag or slowdown
- Resource inadequacy
- System hiccup
Monitoring is often centered on analyzing metrics. Some of the key metrics you will want to monitor include…
- Performance of the database
- Utilization of resources (CPU usage, available memory and Network usage)
- Emerging setbacks
- Saturation and limitation of the resources
- Throughput operations
In this blog we are going to discuss, in detail, these metrics and look at available tools from MongoDB (such as utilities and commands.) We will also look at other software tools such as Pandora, FMS Open Source, and Robo 3T. For the sake of simplicity, we are going to use the Robo 3T software in this article to demonstrate the metrics.
Performance of the Database
The first and foremost thing to check on a database is its general performance, for example, whether the server is active or not. If you run this command db.serverStatus() on a database in Robo 3T, you will be presented with this information showing the state of your server.
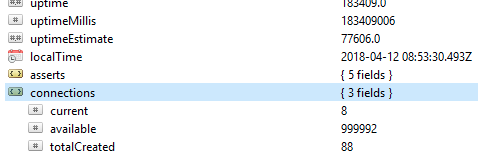

Replica Sets
Replica set is a group of mongod processes that maintain the same data set. If you are using replica sets especially in the production mode, operation logs will provide a foundation for the replication process. All the write operations are tracked using nodes, that is a primary node and a secondary node, which store a limited-size collection. On the primary node, the write operations are applied and processed. However, if the primary node fails before they are copied to the operation logs, then the secondary writing is made but in this case the data might not be replicated.
Key metrics to keep an eye on…
Replication Lag
This defines how far the secondary node is behind the primary node. An optimal state requires the gap be as minute as possible. On a normal operating system, this lag is estimated to be 0. If the gap is too wide then data integrity will be compromised once the secondary node is promoted to primary. In this case you can set a threshold, for example 1 minute, and if it is exceeded an alert is set. Common causes of wide replication lag include…
- Shards that may have an insufficient write capacity which is often associated with resources saturation.
- The secondary node is providing data at a slower rate than the primary node.
- Nodes may also be hindered in some way from communicating, possibly due to a poor network.
- Operations on the primary node could also be slower, thereby blocking replication. If this happens you can run the following commands:
- db.getProfilingLevel(): if you get a value of 0, then your db operations are optimal.
If the value is 1, then it corresponds to slow operations which can be consequently due to slow queries. - db.getProfilingStatus(): in this case we check the value of slowms, by default it is 100ms. If the value is larger than this, then you might be having heavy write operations on the primary or inadequate resources on the secondary. In order to solve this, you can scale the secondary so it has as much resources as the primary.
- db.getProfilingLevel(): if you get a value of 0, then your db operations are optimal.
Cursors
If you make a read request for example find, you will be provided with a cursor which is a pointer to the data set of the result. If you run this command db.serverStatus() and navigate to the metrics object then cursor, you will see this…

In this case, the cursor.timeOut property was updated incrementally to 9 because there were 9 connections that died without closing the cursor. The consequence is that it will remain open on the server and hence consuming memory, unless it is reaped by the default MongoDB setting. An alert to you should be identifying non-active cursors and reaping them off in order to save on memory. You can also avoid non-timeout cursors because they often hold on to resources, thereby slowing down the internal system performance. This can be achieved by setting the value of the cursor.open.noTimeout property to a value of 0.
Journaling
Considering the WiredTiger Storage Engine, before data is recorded, it is first written to the disk files. This is referred to as journaling. Journaling ensures the availability and durability of data on an event of failure from which a recovery can be carried out.
For the purpose of recovery, we often use checkpoints (especially for the WiredTiger storage system) to recover from the last checkpoint. However, if MongoDB shuts down unexpectedly, then we use the journaling technique to recover any data that was processed or provided after the last checkpoint.
Journaling should not be turned off in the first case, since it only takes like 60 seconds to create a new checkpoint. Hence if a failure occurs, MongoDB can replay the journal to recover data lost within these seconds.
Journaling generally narrows the time interval from when data is applied to memory until it is durable on disk. The storage.journal object has a property that describes the commiting frequency, that is, commitIntervalMs which is often set to a value of 100ms for WiredTiger. Tuning it to a lower value will enhance frequent recording of writes hence reducing instances of data loss.
Locking Performance
This can be caused by multiple read and write requests from many clients. When this happens there is a need to keep consistency and avoid write conflicts. In order to achieve this MongoDB uses multi-granularity-locking which allows locking operations to occur at different levels, such as global, database, or collection level.
If you have poor schema design patterns, then you will be vulnerable to locks being held for long durations. This is often experienced when making two or more different write operations to a single document in the same collection, with a consequence of blocking each other. For the WiredTiger storage engine we can use the ticket system where read or write requests come from something like a queue or thread.
By default the concurrent number of read and write operations are defined by the parameters wiredTigerConcurrentWriteTransactions and wiredTigerConcurrentReadTransactions which are both set to a value of 128.
If you scale this value too high then you will end up being limited by CPU resources. To increase throughput operations, it would be advisable to scale horizontally by providing more shards.
Utilization of Resources
This generally describes usage of available resources such as the CPU capacity/ processing rate and RAM. The performance, especially for the CPU can change drastically in accordance to unusual traffic loads. Things to check on include…
- Number of connections
- Storage
- Cache
Number of Connections
If the number of connections is higher than what the database system can handle then there will be a lot of queuing. Consequently, this will overwhelm performance of the database and make your setup run slowly. This number can result in driver issues or even complications with your application.
If you monitor a certain number of connections for some period and then notice that that value has peaked, it is always a good practice to set an alert if the connection exceeds this number.
If the number is getting too high then you can scale up in order to cater to this rise. To do this you have to know the number of connections available within a given period, otherwise, if the available connections are not enough, then requests will not be handled in a timely fashion.
By default MongoDB provides support for up to 1 million connections. With your monitoring, always ensure the current connections never get too close to this value. You can check the value in the connections object.

Storage
Every row and data record in MongoDB is referred to as a document. Document data is in BSON format. On a given database, if you run the command db.stats(), you will be presented with this data.
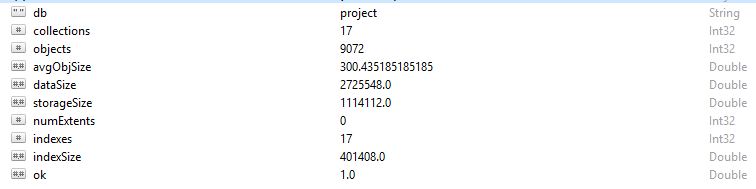
- StorageSize defines the size of all data extents in the database.
- IndexSize outlines the size of all indexes created within that database.
- dataSize is a measure of the total space taken by the documents in the database.
You can sometimes see a change in memory, especially if a lot of data has been deleted. In this case you should set up an alert in order to ensure it was not due to malicious activity.
Sometimes, the overall storage size may shoot up while the database traffic graph is constant and in this case, you should check your application or database structure to avoid having duplicates if not needed.
Like the general memory of a computer, MongoDB also has caches in which active data is temporarily stored. However, an operation may request for data which is not in this active memory, hence making a request from the main disk storage. This request or situation is referred to as page fault. Page fault requests come with a limitation of taking longer time to execute, and can be detrimental when they occur frequently. To avoid this scenario, ensure the size of your RAM is always enough to cater to the data sets you are working with. You should also ensure you have no schema redundancy or unnecessary indices.
Cache
Cache is a temporal data storage item for frequently accessed data. In WiredTiger the file system cache and storage engine cache are often employed. Always ensure that your working set does not bulge beyond the available cache, otherwise, the page faults will increase in number causing some performance issues.
At some point you may decide to modify your frequent operations, but the changes are sometimes not reflected in the cache. This unmodified data is referred to as “Dirty Data.” It exists because it has not yet been flushed to disk. Bottlenecks will result if the amount of “Dirty Data” grows to some average value defined by slow writing to the disk. Adding more shards will help to reduce this number.
CPU Utilization
Improper indexing, poor schema structure and unfriendly designed queries will require more CPU attention hence will obviously increase its utilization.
Throughput Operations
To a large extent getting enough information on these operations can enable one to avoid consequential setbacks such as errors, saturation of resources, and functional complications.
You should always take note of the number of read and write operations to the database, that is, a high-level view of the cluster’s activities. Knowing the number of operations generated for the requests will enable you to calculate the load that the database is expected to handle. The load can then be handled either scaling up your database or scaling out; depending on the type of resources you have. This allows you to easily gauge the quotient ratio in which the requests are accumulating to the rate at which they are being processed. Furthermore, you can optimize your queries appropriately in order to improve the performance.
In order to check the number of read and write operations, run this command db.serverStatus(), then navigate to the locks.global object, the value for the property r represents the number of read requests and w number of writes.
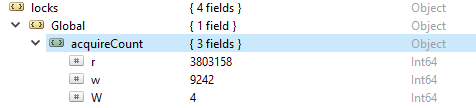
More often the read operations are more than the write operations. Active client metrics are reported under globalLock.
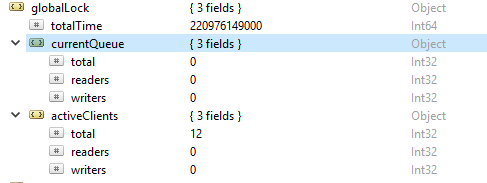
Saturation and Limitation of Resources
Sometimes the database may fail to keep in pace with the rate of writing and reading, as portrayed by an increasing number of queued requests. In this case, you have to scale up your database by providing more shards to enable MongoDB to address the requests fast enough.
Emerging Setbacks
MongoDB log files always give a general overview on assert exceptions returned. This result will give you a clue on the possible causes of errors. If you run the command, db.serverStatus(), some of the error alerts you will note include:

- Regular asserts: these are as a result of an operation failure. For example in a schema if a string value is provided to an integer field hence resulting in failure reading the BSON document.
- Warning asserts: these are often alerts on some issue but are not having much impact on its operation. For example when you upgrade your MongoDB you might be alerted using deprecated functions.
- Msg asserts: they are as a result of internal server exceptions such as slow network or if the server is not active.
- User asserts: like regular asserts, these errors arise when executing a command but they are often returned to the client. For example if there are duplicate keys, inadequate disk space or no access to write into the database. You will opt to check your application to fix these errors.