blog
How to Use MongoDB Data Modeling to Improve Throughput Operations

The efficiency of a database not only relies on fine-tuning the most critical parameters, but also goes further to appropriate data presentation in the related collections. Recently, I worked on a project that developed a social chat application, and after a few days of testing, we noticed some lag when fetching data from the database. We did not have so many users, so we ruled out the database parameters tuning and focused on our queries to get to the root cause.
To our surprise, we realized our data structuring was not entirely appropriate in that we had more than 1 read requests to fetch some specific information.
The conceptual model of how application sections are put into place greatly depends on the database collections structure. For instance, if you log into a social app, data is fed into the different sections according to the application design as depicted from database presentation.
In a nutshell, for a well designed database, schema structure and collection relationships are key things towards its improved speed and integrity as we will see in the following sections.
We shall discuss the factors you should consider when modelling your data.
What is Data Modeling
Data modeling is generally the analysis of data items in a database and how related they are to other objects within that database.
In MongoDB for example, we can have a users collection and a profile collection. The users collection lists names of users for a given application whereas the profile collection captures the profile settings for each user.
In data modeling, we need to design a relationship for connecting each user to the correspondent profile. In a nutshell, data modeling is the fundamental step in database design besides forming the architecture basis for object-oriented programing. It also gives a clue on how the physical application will look like during development progress. An application-database integration architecture can be illustrated as below.
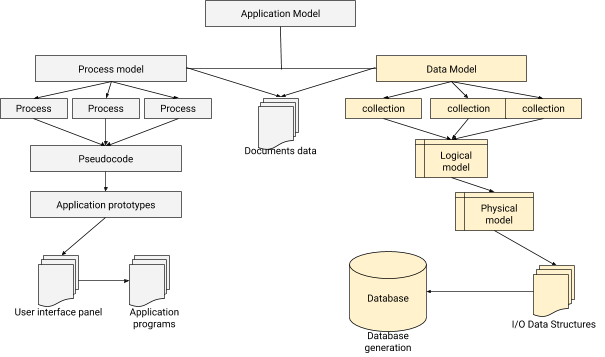
The Process of Data Modeling in MongoDB
Data modeling comes with improved database performance, but at the expense of some considerations which include:
- Data retrieval patterns
- Balancing needs of the application such as: queries, updates and data processing
- Performance features of the chosen database engine
- The Inherent structure of the data itself
MongoDB Document Structure
Documents in MongoDB play a major role in the decision making over which technique to apply for a given set of data. There are generally two relationships between data, which are:
- Embedded Data
- Reference Data
Embedded Data
In this case, related data is stored within a single document either as a field value or an array within the document itself. The main advantage of this approach is that data is denormalized and therefore provides an opportunity for manipulating the related data in a single database operation. Consequently, this improves the rate at which CRUD operations are carried out, hence fewer queries are required. Let’s consider an example of a document below:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}In this set of data, we have a student with his name and some other additional information. The Settings field has been embedded with an object and further the placeLocation field is also embedded with an object with the latitude and longitude configurations. All data for this student has been contained within a single document. If we need to fetch all information for this student we just run:
db.students.findOne({StudentName : "George Beckonn"})Strengths of Embedding
- Increased data access speed: For an improved rate of access to data, embedding is the best option since a single query operation can manipulate data within the specified document with just a single database look-up.
- Reduced data inconsistency: During operation, if something goes wrong (for example a network disconnection or power failure) only a few numbers of documents may be affected since the criteria often select a single document.
- Reduced CRUD operations. This is to say, the read operations will actually outnumber the writes. Besides, it is possible to update related data in a single atomic write operation. I.e for the above data, we can update the phone number and also increase the distance with this single operation:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Weaknesses of Embedding
- Restricted document size. All documents in MongoDB are constrained to the BSON size of 16 megabytes. Therefore, overall document size together with embedded data should not surpass this limit. Otherwise, for some storage engines such as MMAPv1, data may outgrow and result in data fragmentation as a result of degraded write performance.
- Data duplication: multiple copies of the same data make it harder to query the replicated data and it may take longer to filter embedded documents, hence outdo the core advantage of embedding.
Dot Notation
The dot notation is the identifying feature for embedded data in the programming part. It is used to access elements of an embedded field or an array. In the sample data above, we can return information of the student whose location is “Embassy” with this query using the dot notation.
db.users.find({'Settings.location': 'Embassy'})Reference Data
The data relationship in this case is the related data is stored within different documents, but some reference link is issued to these related documents. For the sample data above we can reconstruct it in such a way that:
User document
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Settings document
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}There are 2 different documents, but they are linked by the same value for the _id and id fields. The data model is thus normalized. However, for us to access information from a related document we need to issue additional queries and consequently this results in increased execution time. For instance, if we want to update the ParentPhone and the related distance settings we will have at least 3 queries i.e.
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Strengths of Referencing
- Data consistency. For every document, a canonical form is maintained hence chances of data inconsistency are pretty low.
- Improved data integrity. Due to normalization, it is easy to update data regardless of operation duration length and therefore ensure correct data for every document without causing any confusion.
- Improved cache utilization. Canonical documents accessed frequently are stored in the cache rather than for embedded documents which are accessed a few times.
- Efficient hardware utilization. Contrary to embedding, which may result in document outgrow, referencing does not promote document growth thus reduces disk and RAM usage.
- Improved flexibility especially with a large set of subdocuments.
- Faster writes.
Weaknesses of Referencing
- Multiple lookups: Since we have to look in a number of documents that match criteria there is increased read time when retrieving from disk. Besides, this may result into cache misses.
- Many queries are issued to achieve some operation hence normalized data models require more round trips to the server to complete a specific operation.
Data Normalization
Data normalization refers to restructuring a database in accordance with some normal forms in order to improve data integrity and reduce events of data redundancy.
Data modeling revolves around 2 major normalization techniques that is:
-
Normalized data models
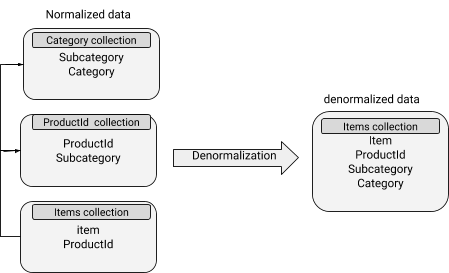
As applied in reference data, normalization divides data into multiple collections with references between the new collections. A single document update will be issued to the other collection and applied accordingly to the matching document. This provides an efficient data update representation and is commonly used for data that changes quite often.
-
Denormalized data models
Data contains embedded documents thereby making read operations quite efficient. However, it is associated with more disk space usage and also difficulties to keep in sync. The denormalization concept can be well applied to subdocuments whose data do not change quite often.
MongoDB Schema
A schema is basically an outlined skeleton of fields and data type each field should hold for a given set of data. Considering the SQL point of view, all rows are designed to have the same columns and each column should hold the defined data type. However, in MongoDB, we have a flexible Schema by default which does not hold the same conformity for all documents.
Flexible Schema
A flexible schema in MongoDB defines that the documents not necessarily need to have the same fields or data type, for a field can differ across documents within a collection. The core advantage with this concept is that one can add new fields, remove existing ones or change the field values to a new type and hence update the document into a new structure.
For example we can have these 2 documents in the same collection:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}In the first document, we have an age field whereas in the second document there is no age field. Further, the data type for ParentPhone field is a number whereas in the second document it has been set to false which is a boolean type.
Schema flexibility facilitates mapping of documents to an object and each document can match data fields of the represented entity.
Rigid Schema
As much as we have said that these documents may differ from one another, sometimes you may decide to create a rigid schema. A rigid schema will define that all documents in a collection will share the same structure and this will give you a better chance to set some document validation rules as a way of improving data integrity during insert and update operations.
Schema data types
When using some server drivers for MongoDB such as mongoose, there are some provided data types which enable you to do data validation. The basic data types are:
- String
- Number
- Boolean
- Date
- Buffer
- ObjectId
- Array
- Mixed
- Decimal128
- Map
Take a look of the sample schema below
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Example use case
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “[email protected]”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Schema Validation
As much as you can do data validation from the application side, it is always good practice to do the validation from the server end, too. We achieve this by employing the schema validation rules.
These rules are applied during the insertion and update operations. They are declared on a collection basis during the creation process normally. However, you can also add the document validation rules to an existing collection using the collMod command with validator options but these rules are not applied to the existing documents until when an update applied to them.
Likewise, when creating a new collection using the command db.createCollection() you can issue the validator option. Take a look at this example when creating a collection for students. From version 3.6, MongoDB supports the JSON Schema validation hence all you need is to use the $jsonSchema operator.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})In this schema design, if we try to insert a new document like:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})The callback function will return the error below, because of some violated validation rules such as the supplied year value is not within the specified limits.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Further, you can add query expressions to your validation option using query operators except $where, $text, near and $nearSphere, i.e.:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Schema Validation Levels
As mentioned before, validation is issued to the write operations, normally.
However, validation can also be applied to already existing documents.
There are 3 levels of validation:
- Strict: this is the default MongoDB validation level and it applies validation rules to all inserts and updates.
- Moderate: The validation rules are applied during inserts, updates and to already existing documents that fulfill the validation criteria only.
- Off: this level sets the validation rules for a given schema to null hence no validation will be done to the documents.
Example:
Let’s insert the data below in a client collection.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]If we apply the moderate validation level using:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )The validation rules will be applied only to the document with _id of 1 since it will match all the criteria.
For the second document, since the validation rules are not met with the issued criteria, the document will not be validated.
Schema Validation Actions
After doing validation on documents, there may be some that may violate the validation rules. There is always a need to provide an action when this happens.
MongoDB provides two actions that can be issued to the documents that fail the validation rules:
- Error: this is the default MongoDB action, which rejects any insert or update in case it violates the validation criteria.
-
Warn: This action will record the violation in the MongoDB log, but allows the insert or update operation to be completed. For example:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })If we try to insert a document like this:
db.students.insert( { name: "Amanda", status: "Updated" } );The gpa is missing regardless of the fact that it is a required field in the schema design, but since the validation action has been set to warn, the document will be saved and an error message will be recorded in the MongoDB log.



