blog
How to Upgrade PostgreSQL10 to PostgreSQL11 With Zero Downtime

Historically, the hardest task when working with PostgreSQL has been dealing with the upgrades. The most intuitive upgrade way you can think of is to generate a replica in a new version and perform a failover of the application into it. With PostgreSQL, this was simply not possible in a native way. To accomplish upgrades you needed to think of other ways of upgrading, such as using pg_upgrade, dumping and restoring, or using some third party tools like Slony or Bucardo, all of them having their own caveats.
Why was this? Because of the way PostgreSQL implements replication.
PostgreSQL built-in streaming replication is what is called physical: it will replicate the changes on a byte-by-byte level, creating an identical copy of the database in another server. This method has a lot of limitations when thinking of an upgrade, as you simply cannot create a replica in a different server version or even in a different architecture.
So, here is where PostgreSQL 10 becomes a game changer. With these new versions 10 and 11, PostgreSQL implements built-in logical replication which, in contrast with physical replication, you can replicate between different major versions of PostgreSQL. This, of course, opens a new door for upgrading strategies.
In this blog, let’s see how we can upgrade our PostgreSQL 10 to PostgreSQL 11 with zero downtime using logical replication. First of all, let’s go through an introduction to logical replication.
What is Logical Replication?
Logical replication is a method of replicating data objects and their changes, based upon their replication identity (usually a primary key). It is based on a publish and subscribe mode, where one or more subscribers subscribe to one or more publications on a publisher node.
A publication is a set of changes generated from a table or a group of tables (also referred to as replication set). The node where a publication is defined is referred to as publisher. A subscription is the downstream side of logical replication. The node where a subscription is defined is referred to as the subscriber, and it defines the connection to another database and set of publications (one or more) to which it wants to subscribe. Subscribers pull data from the publications they subscribe to.
Logical replication is built with an architecture similar to physical streaming replication. It is implemented by “walsender” and “apply” processes. The walsender process starts logical decoding of the WAL and loads the standard logical decoding plugin. The plugin transforms the changes read from WAL to the logical replication protocol and filters the data according to the publication specification. The data is then continuously transferred using the streaming replication protocol to the apply worker, which maps the data to local tables and applies the individual changes as they are received, in a correct transactional order.
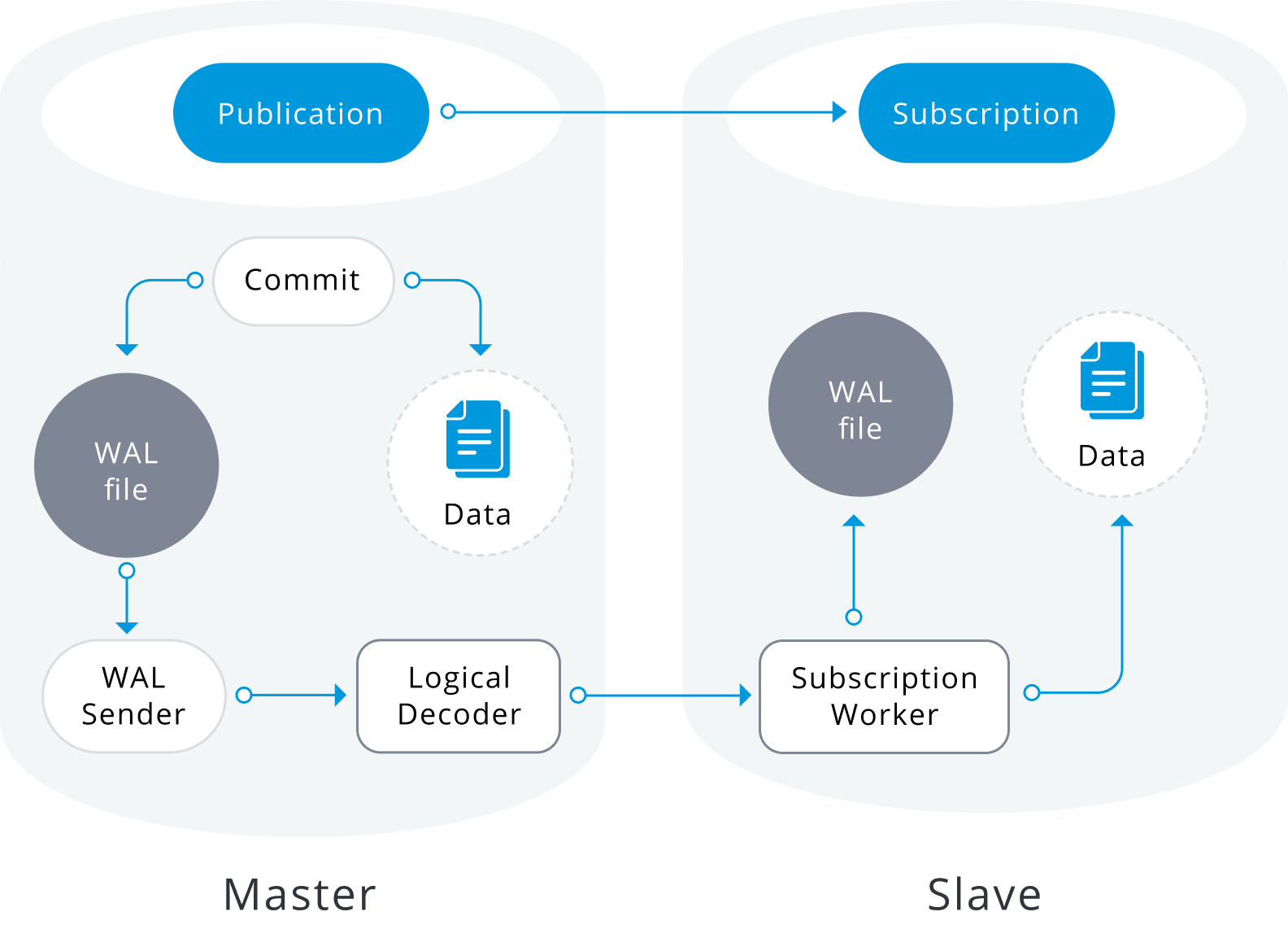
Logical replication starts by taking a snapshot of the data on the publisher database and copying that to the subscriber. The initial data in the existing subscribed tables are snapshotted and copied in a parallel instance of a special kind of apply process. This process will create its own temporary replication slot and copy the existing data. Once the existing data is copied, the worker enters synchronization mode, which ensures that the table is brought up to a synchronized state with the main apply process by streaming any changes that happened during the initial data copy using standard logical replication. Once the synchronization is done, the control of the replication of the table is given back to the main apply process where the replication continues as normal. The changes on the publisher are sent to the subscriber as they occur in real-time.
You can find more about logical replication in the following blogs:
- An Overview of Logical Replication in PostgreSQL
- PostgreSQL Streaming Replication vs Logical Replication
How to Upgrade PostgreSQL 10 to PostgreSQL 11 Using Logical Replication
So, now that we know what this new feature is about, we can think about how we can use it to solve the upgrade issue.
We are going to configure logical replication between two different major versions of PostgreSQL (10 and 11), and of course, after you have this working, it is only a matter of performing an application failover into the database with the newer version.
We are going to perform the following steps to put logical replication to work:
- Configure the publisher node
- Configure the subscriber node
- Create the subscriber user
- Create a publication
- Create the table structure in the subscriber
- Create the subscription
- Check the replication status
So let’s start.
On the publisher side, we are going to configure the following parameters in the postgresql.conf file:
- listen_addresses: What IP address(es) to listen on. We’ll use ‘*’ for all.
- wal_level: Determines how much information is written to the WAL. We are going to set it to logical.
- max_replication_slots: Specifies the maximum number of replication slots that the server can support. It must be set to at least the number of subscriptions expected to connect, plus some reserve for table synchronization.
- max_wal_senders: Specifies the maximum number of concurrent connections from standby servers or streaming base backup clients. It should be set to at least the same as max_replication_slots plus the number of physical replicas that are connected at the same time.
Keep in mind that some of these parameters required a restart of PostgreSQL service to apply.
The pg_hba.conf file also needs to be adjusted to allow replication. We need to allow the replication user to connect to the database.
So based on this, let’s configure our publisher (in this case our PostgreSQL 10 server) as follows:
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
We must change the user (in our example rep), which will be used for replication, and the IP address 192.168.100.144/32 for the IP that corresponds to our PostgreSQL 11.
On the subscriber side, it also requires the max_replication_slots to be set. In this case, it should be set to at least the number of subscriptions that will be added to the subscriber.
The other parameters that also need to be set here are:
- max_logical_replication_workers: Specifies the maximum number of logical replication workers. This includes both apply workers and table synchronization workers. Logical replication workers are taken from the pool defined by max_worker_processes. It must be set to at least the number of subscriptions, again plus some reserve for the table synchronization.
- max_worker_processes: Sets the maximum number of background processes that the system can support. It may need to be adjusted to accommodate for replication workers, at least max_logical_replication_workers + 1. This parameter requires a PostgreSQL restart.
So, we must configure our subscriber (in this case our PostgreSQL 11 server) as follows:
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
As this PostgreSQL 11 will be our new master soon, we should consider adding the wal_level and archive_mode parameters in this step, to avoid a new restart of the service later.
wal_level = logical
archive_mode = onThese parameters will be useful if we want to add a new replication slave or for using PITR backups.
In the publisher, we must create the user with which our subscriber will connect:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLEThe role used for the replication connection must have the REPLICATION attribute. Access for the role must be configured in pg_hba.conf and it must have the LOGIN attribute.
In order to be able to copy the initial data, the role used for the replication connection must have the SELECT privilege on a published table.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTWe’ll create pub1 publication in the publisher node, for all the tables:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONThe user that will create a publication must have the CREATE privilege in the database, but to create a publication that publishes all tables automatically, the user must be a superuser.
To confirm the publication created we are going to use the pg_publication catalog. This catalog contains information about all publications created in the database.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tColumn descriptions:
- pubname: Name of the publication.
- pubowner: Owner of the publication.
- puballtables: If true, this publication automatically includes all tables in the database, including any that will be created in the future.
- pubinsert: If true, INSERT operations are replicated for tables in the publication.
- pubupdate: If true, UPDATE operations are replicated for tables in the publication.
- pubdelete: If true, DELETE operations are replicated for tables in the publication.
As the schema is not replicated, we must take a backup in PostgreSQL 10 and restore it in our PostgreSQL 11. The backup will only be taken for the schema, since the information will be replicated in the initial transfer.
In PostgreSQL 10:
$ pg_dumpall -s > schema.sqlIn PostgreSQL 11:
$ psql -d postgres -f schema.sqlOnce we have our schema in PostgreSQL 11, we create the subscription, replacing the values of host, dbname, user, and password with those that correspond to our environment.
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONThe above will start the replication process, which synchronizes the initial table contents of the tables in the publication and then starts replicating incremental changes to those tables.
The user creating a subscription must be a superuser. The subscription apply process will run in the local database with the privileges of a superuser.
To verify the created subscription we can use then pg_stat_subscription catalog. This view will contain one row per subscription for the main worker (with null PID if the worker is not running), and additional rows for workers handling the initial data copy of the subscribed tables.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Column descriptions:
- subid: OID of the subscription.
- subname: Name of the subscription.
- pid: Process ID of the subscription worker process.
- relid: OID of the relation that the worker is synchronizing; null for the main apply worker.
- received_lsn: Last write-ahead log location received, the initial value of this field being 0.
- last_msg_send_time: Send time of last message received from origin WAL sender.
- last_msg_receipt_time: Receipt time of last message received from origin WAL sender.
- latest_end_lsn: Last write-ahead log location reported to origin WAL sender.
- latest_end_time: Time of last write-ahead log location reported to origin WAL sender.
To verify the status of replication in the master we can use pg_stat_replication:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncColumn descriptions:
- pid: Process ID of a WAL sender process.
- usesysid: OID of the user logged into this WAL sender process.
- usename: Name of the user logged into this WAL sender process.
- application_name: Name of the application that is connected to this WAL sender.
- client_addr: IP address of the client connected to this WAL sender. If this field is null, it indicates that the client is connected via a Unix socket on the server machine.
- client_hostname: Hostname of the connected client, as reported by a reverse DNS lookup of client_addr. This field will only be non-null for IP connections, and only when log_hostname is enabled.
- client_port: TCP port number that the client is using for communication with this WAL sender, or -1 if a Unix socket is used.
- backend_start: Time when this process was started.
- backend_xmin: This standby’s xmin horizon reported by hot_standby_feedback.
- state: Current WAL sender state. The possible values are: startup, catchup, streaming, backup and stopping.
- sent_lsn: Last write-ahead log location sent on this connection.
- write_lsn: Last write-ahead log location written to disk by this standby server.
- flush_lsn: Last write-ahead log location flushed to disk by this standby server.
- replay_lsn: Last write-ahead log location replayed into the database on this standby server.
- write_lag: Time elapsed between flushing recent WAL locally and receiving notification that this standby server has written it (but not yet flushed it or applied it).
- flush_lag: Time elapsed between flushing recent WAL locally and receiving notification that this standby server has written and flushed it (but not yet applied it).
- replay_lag: Time elapsed between flushing recent WAL locally and receiving notification that this standby server has written, flushed and applied it.
- sync_priority: Priority of this standby server for being chosen as the synchronous standby in a priority-based synchronous replication.
- sync_state: Synchronous state of this standby server. The possible values are async, potential, sync, quorum.
To verify when the initial transfer is finished we can see the PostgreSQL log on the subscriber:
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedOr checking the srsubstate variable on pg_subscription_rel catalog. This catalog contains the state for each replicated relation in each subscription.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Column descriptions:
- srsubid: Reference to subscription.
- srrelid: Reference to relation.
- srsubstate: State code: i = initialize, d = data is being copied, s = synchronized, r = ready (normal replication).
- srsublsn: End LSN for s and r states.
We can insert some test records in our PostgreSQL 10 and validate that we have them in our PostgreSQL 11:
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)At this point, we have everything ready to point our application to our PostgreSQL 11.
For this, first of all, we need to confirm that we don’t have replication lag.
On the master:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0And now, we only need to change our endpoint from our application or load balancer (if we have one) to the new PostgreSQL 11 server.
If we have a load balancer like HAProxy, we can configure it using the PostgreSQL 10 as active and the PostgreSQL 11 as backup, in this way:
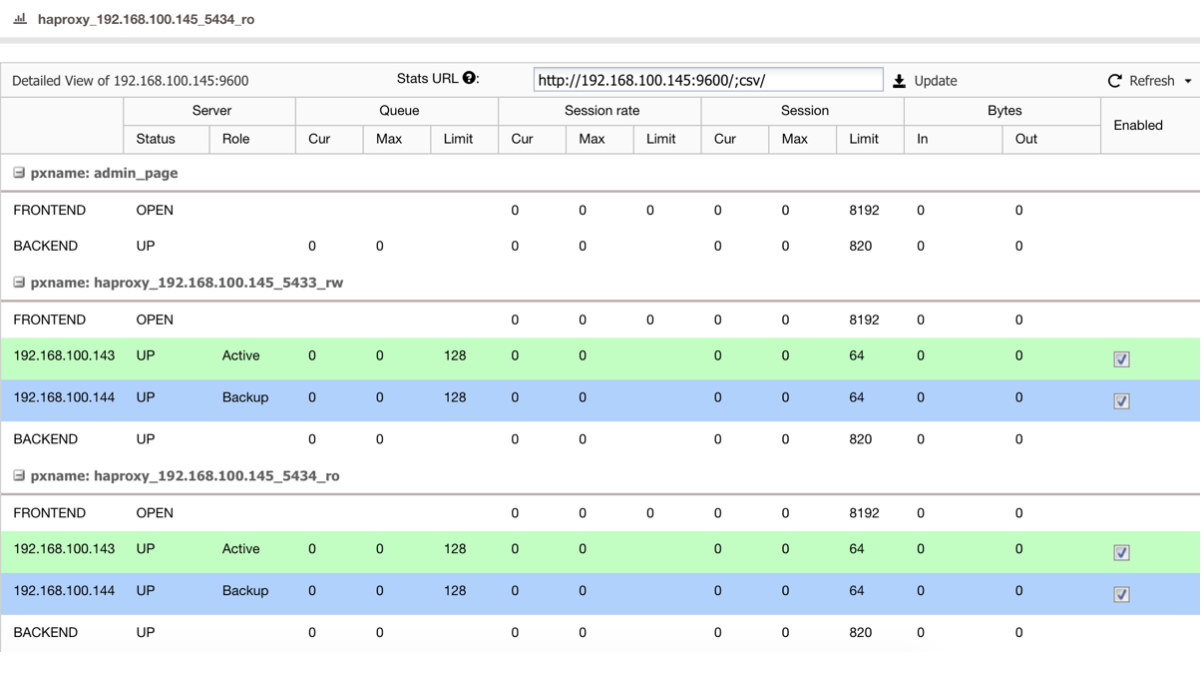
So, if you just shutdown the master in PostgreSQL 10, the backup server, in this case in PostgreSQL 11, starts to receive the traffic in a transparent way for the user/application.
At the end of the migration, we can delete the subscription in our new master in PostgreSQL 11:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONAnd verify that it is removed correctly:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Limitations
Before using the logical replication, please keep in mind the following limitations:
- The database schema and DDL commands are not replicated. The initial schema can be copied using pg_dump –schema-only.
- Sequence data is not replicated. The data in serial or identity columns backed by sequences will be replicated as part of the table, but the sequence itself would still show the start value on the subscriber.
- Replication of TRUNCATE commands is supported, but some care must be taken when truncating groups of tables connected by foreign keys. When replicating a truncate action, the subscriber will truncate the same group of tables that was truncated on the publisher, either explicitly specified or implicitly collected via CASCADE, minus tables that are not part of the subscription. This will work correctly if all affected tables are part of the same subscription. But if some tables to be truncated on the subscriber have foreign-key links to tables that are not part of the same (or any) subscription, then the application of the truncate action on the subscriber will fail.
- Large objects are not replicated. There is no workaround for that, other than storing data in normal tables.
- Replication is only possible from base tables to base tables. That is, the tables on the publication and on the subscription side must be normal tables, not views, materialized views, partition root tables, or foreign tables. In the case of partitions, you can replicate a partition hierarchy one-to-one, but you cannot currently replicate to a differently partitioned setup.
Conclusion
Keeping your PostgreSQL server up to date by performing regular upgrades has been a necessary but difficult task until PostgreSQL 10 version.
In this blog we made a brief introduction to logical replication, a PostgreSQL feature introduced natively in version 10, and we have shown you how it can help you accomplish this challenge with a zero downtime strategy.



