blog
How to Setup Automatic Failover for the Moodle MySQL Database

In a previous blog, we had discussed how to migrate a standalone Moodle setup to scalable setup based on a clustered database. The next step you will need to think about is the failover mechanism – what do you do if and when your database service goes down.
A failed database server is not unusual if you have MySQL Replication as your backend Moodle database, and if it happens, you will need to find a way to recover your topology by for instance promoting a standby server to become a new primary server. Having automatic failover for your Moodle MySQL database helps application uptime. We will explain how failover mechanisms work, and how to build automatic failover into your setup.
High Availability Architecture for MySQL Database
High availability architecture can be achieved by clustering your MySQL database in a couple of different ways. You can use MySQL Replication, set up multiple replicas that closely follow your primary database. On top of that, you can put a database load balancer to split the read/write traffic, and distribute the traffic across read-write and read-only nodes. Database high availability architecture using MySQL Replication can be described as below :
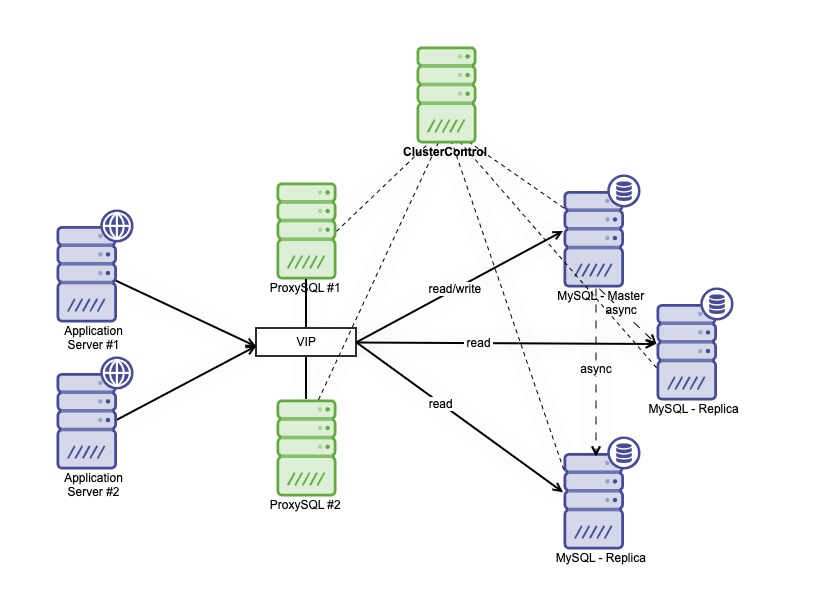
It consists of one primary database, two database replicas, and database load balancers (in this blog, we use ProxySQL as database load balancers), and keepalived as a service to monitor the ProxySQL processes. We use Virtual IP Address as a single connection from the application. The traffic will be distributed to the active load balancer based on the role flag in keepalived.
ProxySQL is able to analyze the traffic and understand whether a request is a read or a write. It will then forward the request to the appropriate host(s).
Failover on MySQL Replication
MySQL Replication uses binary logging to replicate data from the primary to the replicas. The replicas connect to the primary node, and every change is replicated and written to the replica nodes’ relay logs through IO_THREAD. After the changes are stored in the relay log, the SQL_THREAD process will proceed with applying data into the replica database.
The default setting for parameter read_only in a replica is ON. It is used to protect the replica itself from any direct write, so the changes will always come from the primary database. This is important as we do not want the replica to diverge from the primary server. Failover scenario in MySQL Replication happens when the primary is not reachable. There can be many reasons for this; e.g., server crashes or network issues.
You need to promote one of the replicas to primary, disable the read-only parameter on the promoted replica so it can be writable. You also need to change the other replica to connect to the new primary. In GTID mode, you do not need to note the binary log name and position from where to resume replication. However, in traditional binlog based replication, you definitely need to know the last binary log name and position from which to carry on. Failover in binlog based replication is quite a complex process, but even failover in GTID based replication is not trivial either as you need to look out for things like errant transactions. Detecting a failure is one thing, and then reacting to the failure within a short delay is probably not possible without automation.
How ClusterControl Enables Automatic Failover
ClusterControl has the ability to perform automatic failover for your Moodle MySQL database. There is an Automatic Recovery for Cluster and Node feature which will trigger the failover process when the database primary crashes.
We will simulate how Automatic Failover happens in ClusterControl. We will make the primary database crash, and just see on the ClusterControl dashboard. Below is the current Topology of the cluster :
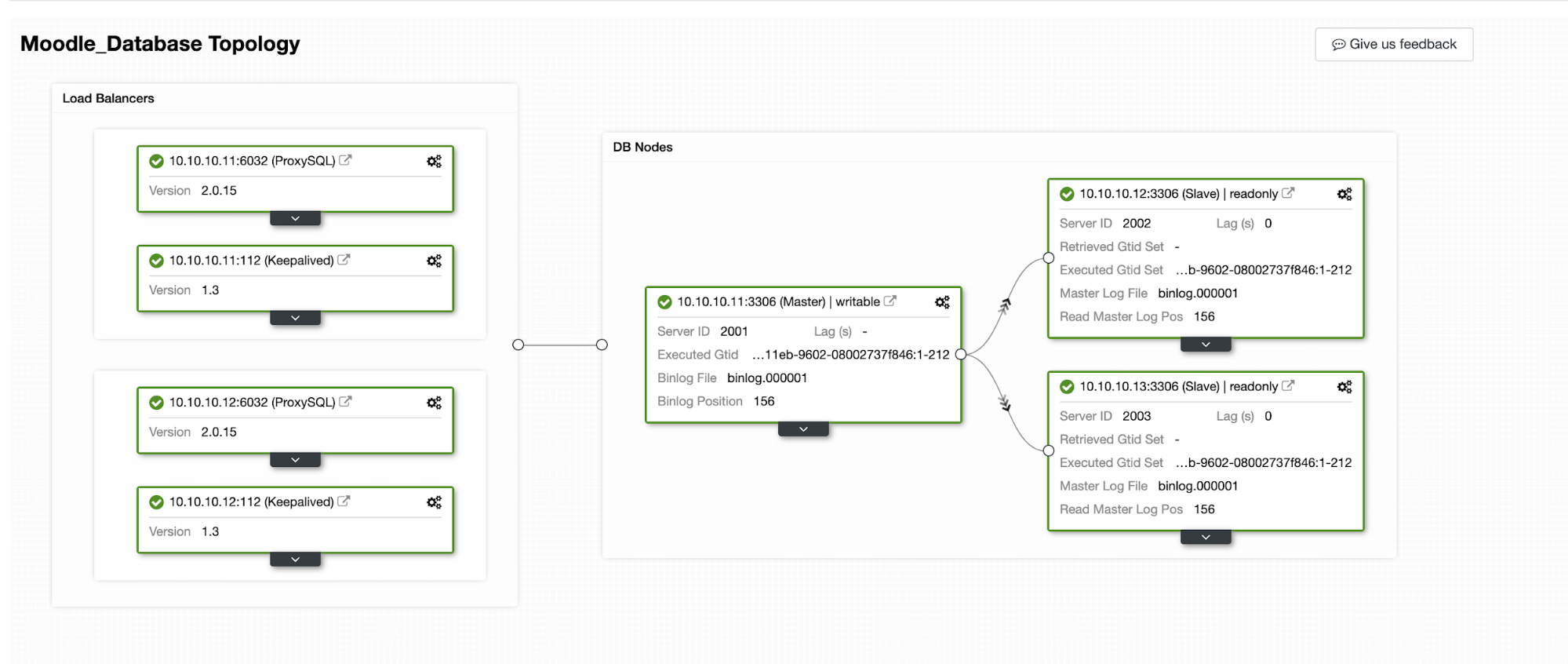
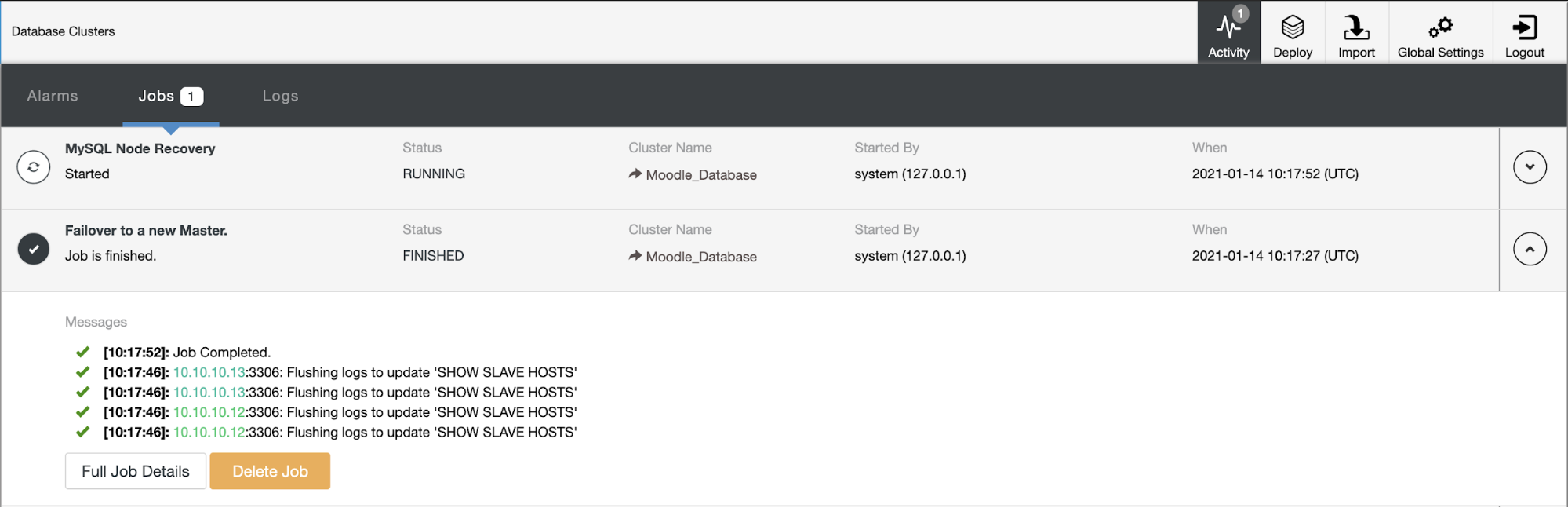
The database primary is using IP Address 10.10.10.11 and the replicas are : 10.10.10.12 and 10.10.10.13. When the crash happens on the primary, ClusterControl triggers an alert and a failover starts as shown in the below picture:
One of the replicas will be promoted to primary, resulting in the Topology as in the below picture:
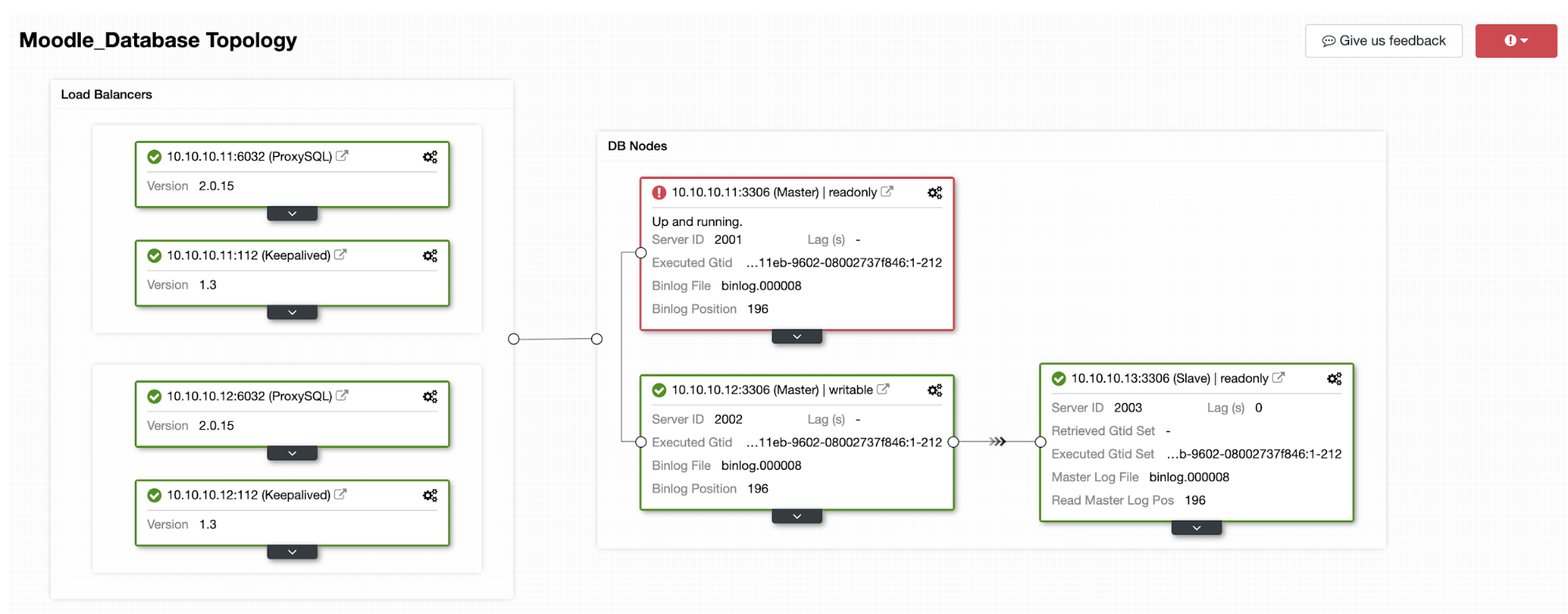
The IP address 10.10.10.12 is now serving the write traffic as primary, and also we are left with only one replica which has IP address 10.10.10.13. On the ProxySQL side, the proxy will detect the new primary automatically. Hostgroup (HG10) still serve the write traffic which has member 10.10.10.12 as shown below:

Hostgroup (HG20) still can serve read traffic, but as you can see the node 10.10.10.11 is offline because of the crash :
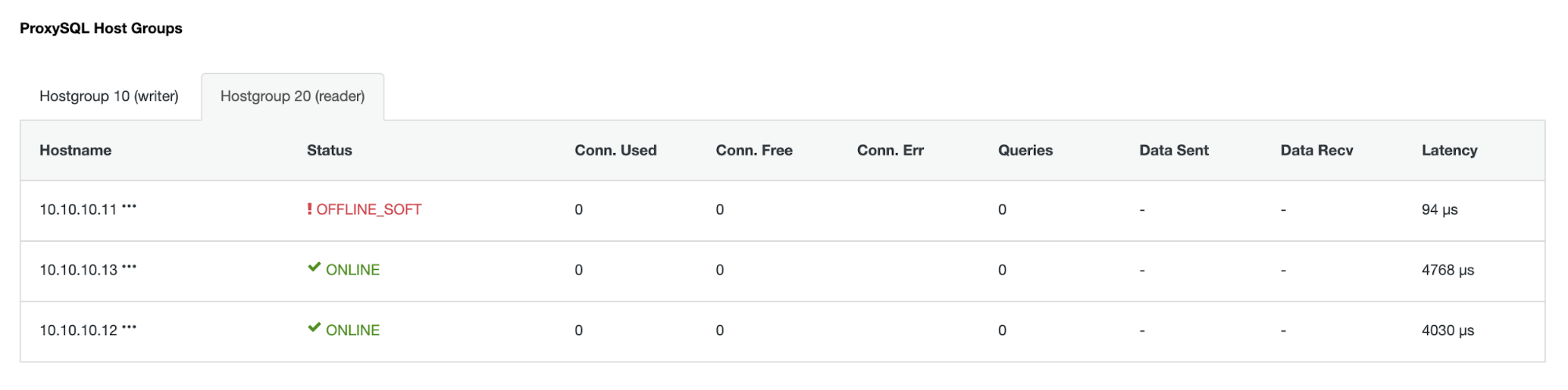
Once the primary failed server comes back online, it will not be automatically re-introduced in the database topology. This is to avoid losing troubleshooting information, as re-introducing the node as a replica might require overwriting some logs or other information. But it is possible to configure auto-rejoin of the failed node.



