blog
How to Get Started with Open Source Database Management – Tips & Tricks From an Expert

You’ve been tasked with taking care of a database and you are not sure how to proceed. Yes you have worked with databases, but you have never managed them, and are not a DBA. What should you focus on? What are the most important tasks of a DBA?
In this blog post, we’ll give you some tips to help you get started on your adventure in open source database management. We’ll try to make it as database-agnostic as possible. In the end, no matter what database you end up managing, some of the tasks and skills required are the same.
Some Basics
To set your priorities, make sure you understand how the database you will manage fits into the big picture. What is the most important asset you are working with? It is important company data you’ve been tasked to take care of. You have to make sure it’s safe no matter what task you are performing. Evaluate and be critical about every command you run, make sure it is safe to execute and it won’t impact consistency of your data. One good practice is to take a short break and review everything before you hit “enter”. Check where are you in terms of path, check that the command you are about to run makes sense. This should help you avoid issues like running “rm” in the wrong directory or executing queries like “UPDATE mytable SET my_column = 1”, which will destroy your data.
You have to be able to keep calm even when under pressure. That’s because you will be under pressure – if your database is down, some systems will stop working and that will affect the company. You will be pressed into bringing the database back up as fast as possible. You have to keep in mind that while bringing things up, you should not risk your data. Think twice before you do anything, even if you are in a hurry. You have to be fast but also precise in what you do.
It is easier to perform well under stress when you have everything planned and tested in advance. Write runbooks for every task you have to execute, no matter if it is done regularly or not. Build a list of steps to run, which you can easily copy and paste when needed. What’s also important – test your runbooks! Make sure you are certain they work. An environment usually changes in time, and rubooks have to change with it. It’s a never-ending cycle of writing runbooks, testing them, verifying, rewriting, testing… You’ll be thankful to have them when an issue shows up, and you need to perform some operations flawlessly. Just keep in mind that it’s not only about issues – you also want to have runbooks for day-to-day operations like provisioning new databases, adding capacity, restoring backups, performing upgrades or any other maintenance you need to do on your database – runbooks really help to reduce human errors.
You should keep your disaster recovery skills sharp, therefore you should constantly work with them. Large environments would implement tools like Chaos Monkey, a script which is intended to break production nodes and test resilience. Your environment has to be able to handle failures. Even if we are talking about small environments, you should test your high availability setup. Keep in mind that, while you strive to stay within the SLA you provide for customers, that SLA is never 100%. It’s always a couple of nines, the more the better. Subtract your SLA from 100%, that gives you a pool of time which you can use for downtime. Typically, this is for unplanned ones. But if, at the end of the year, you still have some time left in that pool, it’s not a bad idea to use it for some improvements – plan a failover, test your skills, improve recovery time and so on.
Make sure you automate as much as you can. Automation has a nice strong side – once something is tested and verified to work correctly, it will work just fine (until something in your environment changes), thus eliminating human errors. Automation serves also as runbooks, it just doesn’t require manual copy&paste of every step to run the procedure. There is huge number of tools which can help you to automate your procedures. It starts from shell scripts of different kinds, to infrastructure automation tools like Ansible, Chef, Puppet or Salt stack. Each of those tools will help you to speed up your procedures and make them less error-prone.
Setting up an Environment
You may be tasked with creating whole environment from scratch, or to manage an existing setup. No matter which is the case, you will be responsible for operating the database and making sure that it runs smoothly. Of course, plenty depends on what database you have but there are still commonly shared yet very important basics to keep in mind – backups, monitoring etc. We’ll discuss them in this section.
Backups
This is the number one priority – setup a reliable backup system. High availability can wait, it’s of no use to have multi-node clusters if you cannot recover from an accidental data loss.
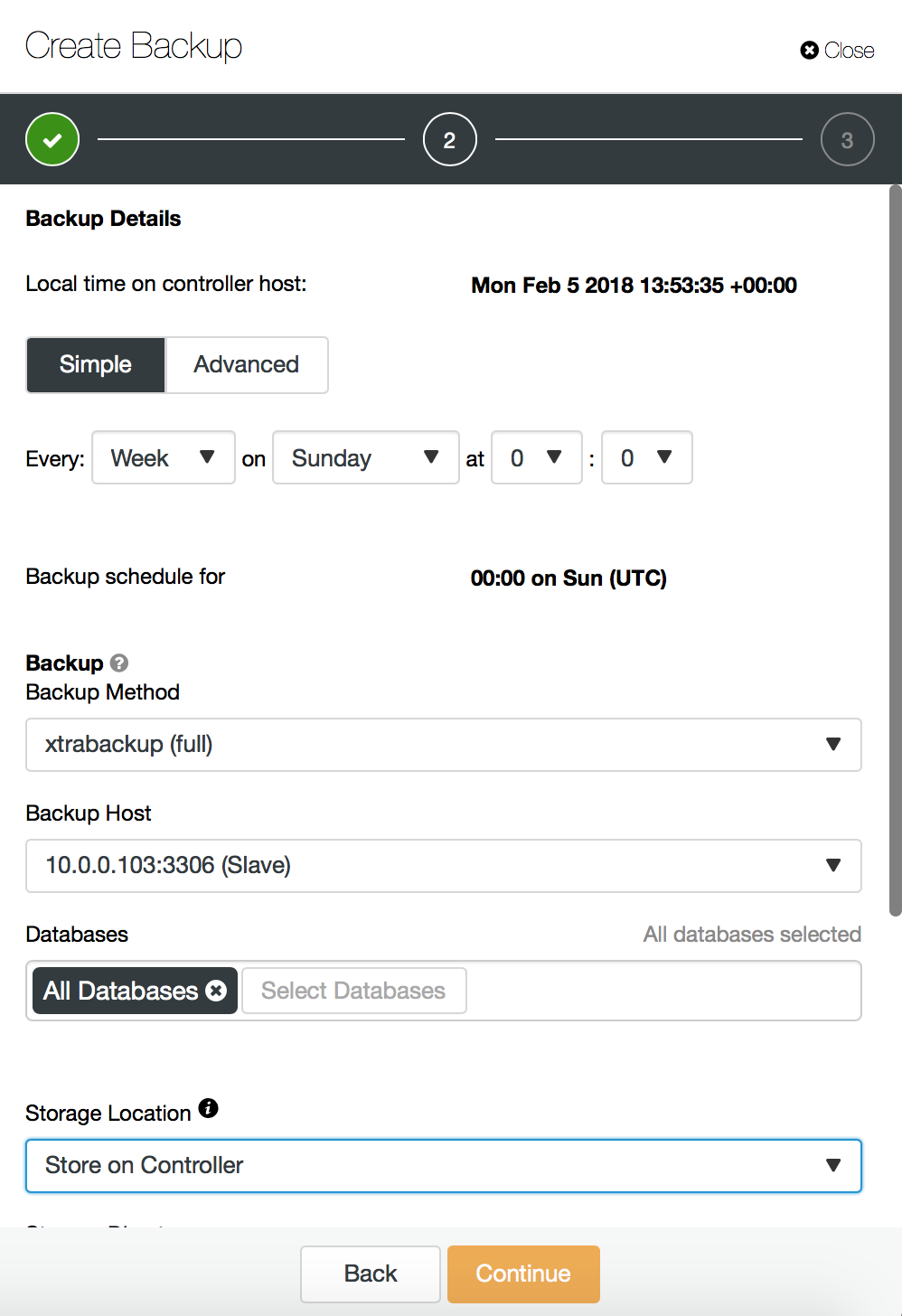
Backup is the first thing you need to cover. To take a backup can be easy or not, depending on your database type, how complex your environment is (think shards vs. single instances), what tools are available for your database etc. No matter how, you have to take those backups.
Make sure you keep all the logs available from the backup process – you’ll find them useful when debugging issues you may encounter. Ensure your backups are safely stored in a remote location, for disaster recovery. This is in case your datacenter, where your data is stored, will go down in flames. Data is your most important asset. You can build your entire environment from scratch, but if you don’t have the data, it is of no use.
For better security, encrypt your backups. This is especially true if you copy or stream them over the network.
Make sure you know what recovery time looks like in your case, so you won’t be surprised when attempting to restore everything. If the recovery time is too long, maybe you can come up with another way of taking backups? Different tool, different approach (full vs. incremental backup) may reduce recovery time
Last but not least, test your backups. There was Schrödinger’s cat which was both alive and dead unless you opened a box. Well, there is Schrödinger’s backup which is both restorable and corrupted until you actually attempt to restore it. Backup is like a black box. To make sure you have a working backup, you need to perform a recovery test.
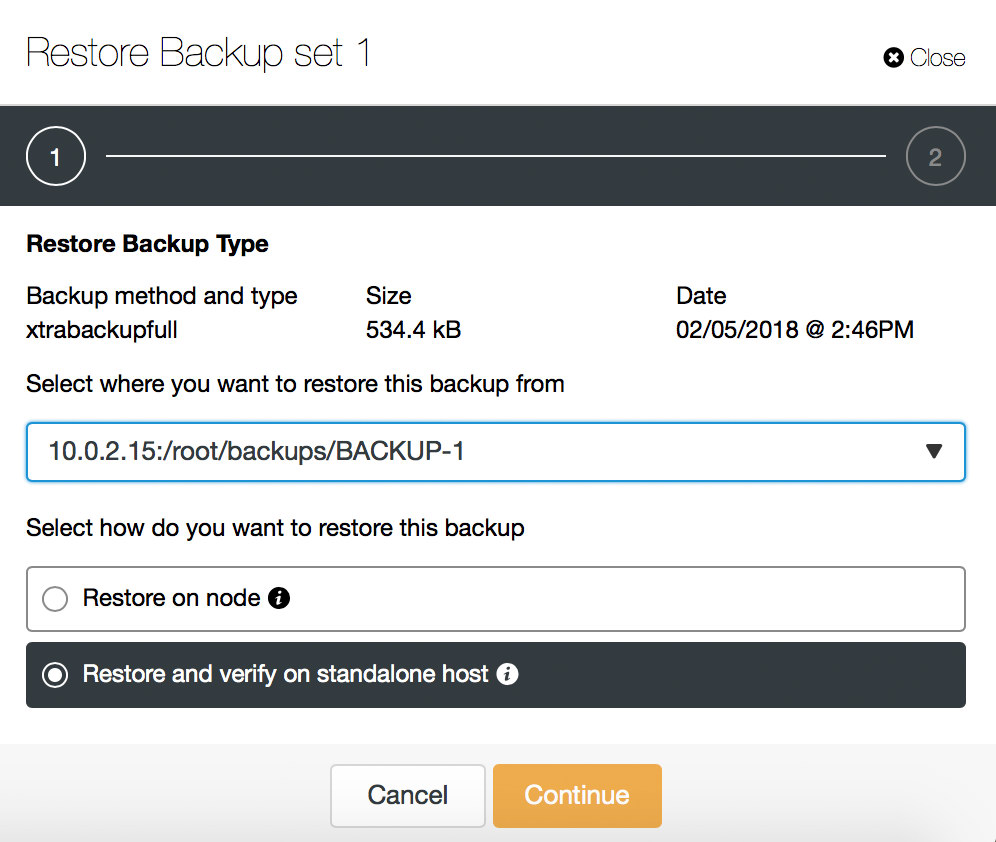
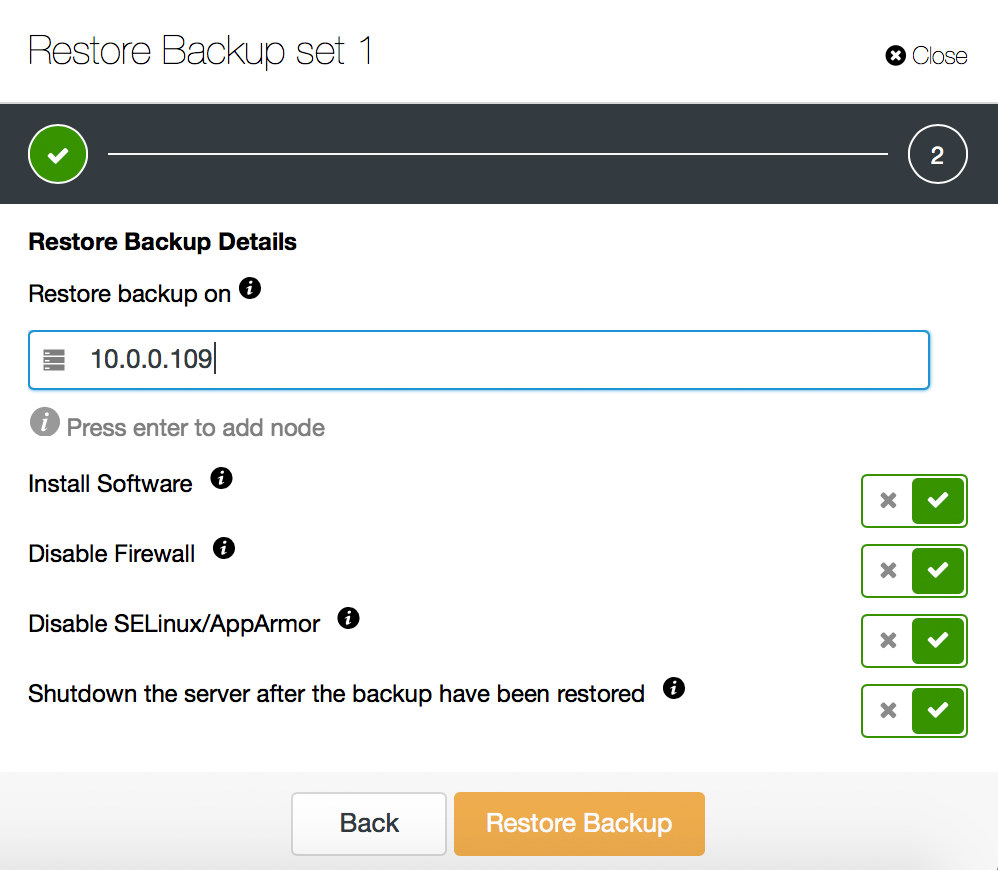
Do it frequently (ideally for every backup you take), make sure you verify backups after any changes in the flow of the backup process.
High Availability
Once backups are secured, next step is, typically, to secure availability of your database. Details differ between databases but, generally speaking, it’s all about having multiple replicas of the data and at least one copy is always available to applications.
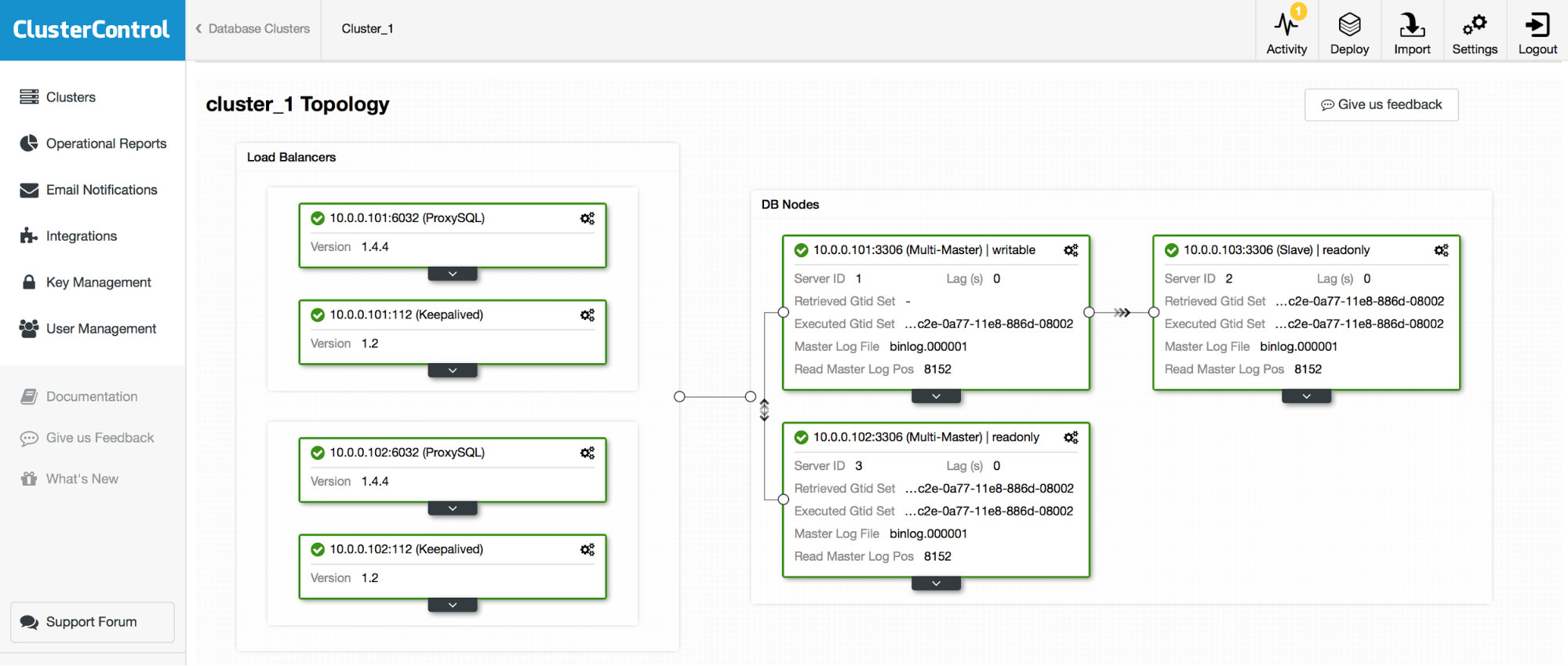
You will have to decide what kind of failures your database should be able to handle. Is it a failure of one or more servers (how many?), is it a failure of a whole datacenter, or maybe even multi-datacenter failures? Once you set your expectations, you have to start planing. How many nodes in how many data centers are required to meet your requirements? How your database handle network partitioning and quorum? Does it handle split brain at all? Can you write to multiple nodes, or is there a single “entry” point to your database. Are you going to implement sharding? Which management operations are automated by your database, and what’s left for you to automate? Provisioning of new nodes – can it provision a node or do you have to pre-provision it? Recovery – can your database detect failures and automatically handle which node (or nodes) should take over writes? What tools are available to assist you with failover?
Disaster recovery
Once you have working backups and your setup is highly available, it’s time to come up with plans for different types of disasters. Even if your environment is planned to handle large scale outages, it can always happen that one too many nodes or one too many data centers fail and the database cannot perform correctly. You have to be prepared and know how to recover from different conditions. You should plan for loss of quorum, plan for data loss (the larger your environment is, the harder it will be to recover from a backup) but also you should plan for fast scale-out should your database become overloaded.
Day-to-day Activities
For any production database, there is a list of tasks you will have to accomplish. Some of them are pretty straightforward, some are more complex. Most of them are common to every database. Let’s see some examples.
Monitoring and Trending
One of the most important things to do – you have to understand the state of your database. One has to setup some tools which would connect to the database, check its status, and track important metrics. Virtually every database exposes some sort of metrics to users – it’s then a matter of using a particular software (or writing your own) to store and track them.
Ideally you are able to plot graphs, at the end a picture is worth thousands of words. Graphs give you ability to review past data which is quite useful because, normally, no one sits in front of the screen watching metrics in real time, waiting for an incident to happen. Monitoring software or scripts should be in place to let you know if something happens. What’s very important to understand is how stressful and annoying a pager can be. You should strive to make sure only actionable alerts are called. If you alert on everything, including issues not really worth paging, your oncall staff will eventually start ignoring some of them which, at the end, may end up in them missing or deliberately ignoring alert, which later may cause a downtime.
Maintenance
No matter what database you use, there will always be maintenance operations to run. Schema changes (if your database has schema), adding indexes, increasing node capacity, adding new nodes, splitting shards etc. You will have to come up with procedures which make those tasks as smooth as possible. The key is to make the process stable and predictable: you want to reduce any impact, and know what to expect. This can be done through standardization – once you come up with a flow which is stable and reduces the impact to the minimum, you should make sure that everyone will follow the same procedure. One way is to create runbooks and make sure you follow the steps described in these. Another way – automation. Automate every process you have to (or you expect to) run more than once. Scripts work as runbooks, and it is easier to stick to the flow: once you run a script, it will execute steps as planned and no human error can cause unwanted behaviour (unless there are bugs, but that’s another story).
While preparing the process make sure you are cautious. Test every step you take and every command you execute. Prepare a way to rollback the process, in case you detect too high impact. Make it controllable – ideally you’d be able to pause the operation for a while in case you notice any performance issues.
Performance Tuning
Performance tuning is a never-ending story, and you cannot really avoid it. There are no default settings which would work for all workload types, therefore you will have to tune your database to improve its initial performance. Additionally, a workload typically changes with time. More data is added to the database, access patterns change. You will be reading more from disk than from memory and this puts more strain on different subsystems of your database, each tunable in some different way.
No matter what database you have and what load you are facing, there are a couple of things you should keep in mind. First of all, observability. You have to be able to tell if a parameter change had an impact on performance. Has it improved or degraded? For that, you have to have some sort of trending system, which we discussed a bit earlier in this post. Another rule, which is crucial to follow: change only one setting at a time. No matter how amazing your trending tools are, if you cannot tell which one of the three variables you just changed affected performance, you can’t really do any tuning.
Health Checks
You should be able to tell what’s going on in your database environment, and ideally, have enough insight so you can predict what is about to come. Therefore you should have in place some sort of process which will make you aware of potential issues, so you can proactively work on them and prevent them from getting out of control . What you may want to look into depends on your database of choice but some basics are shared.
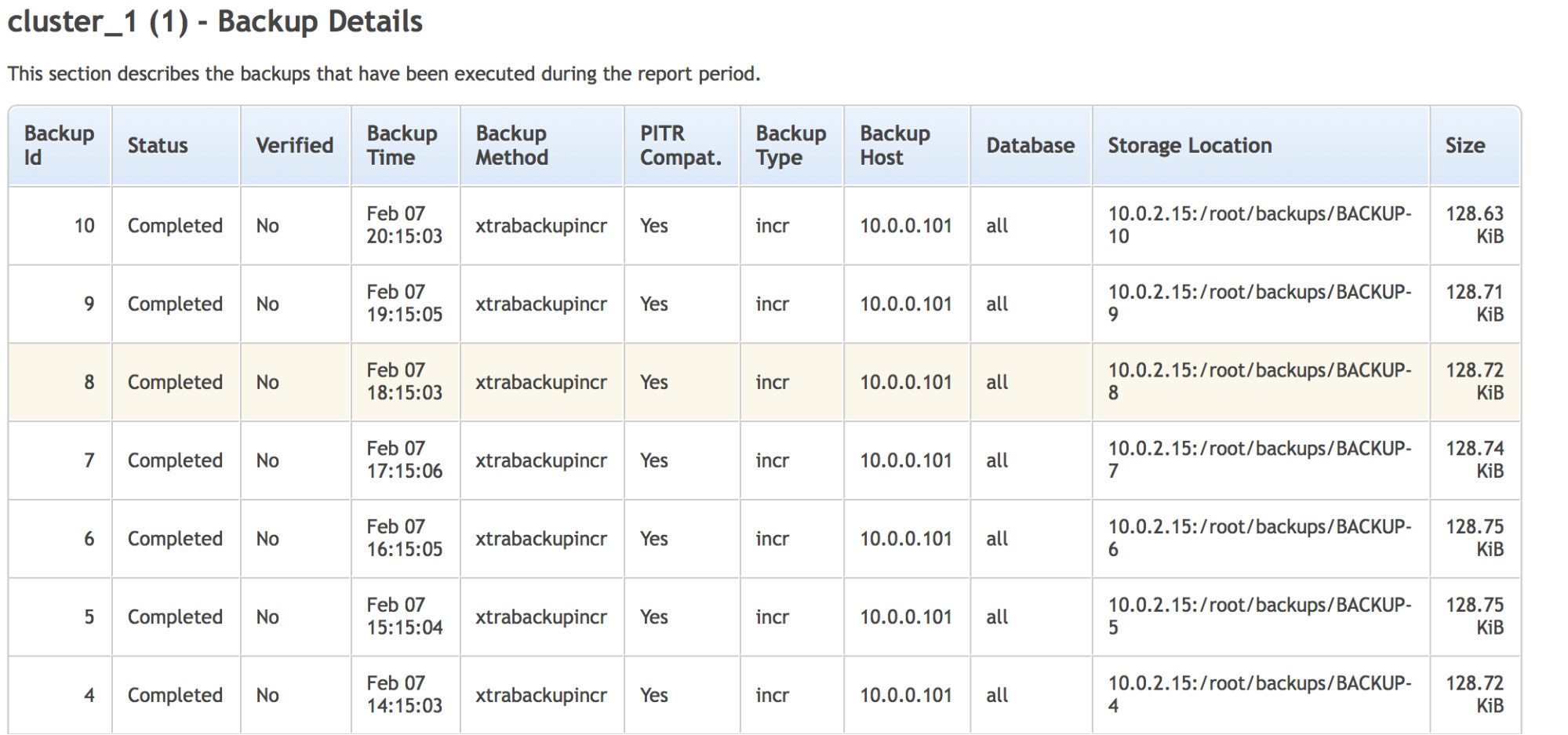
Did your backups complete ok? Did they pass verification successfully?
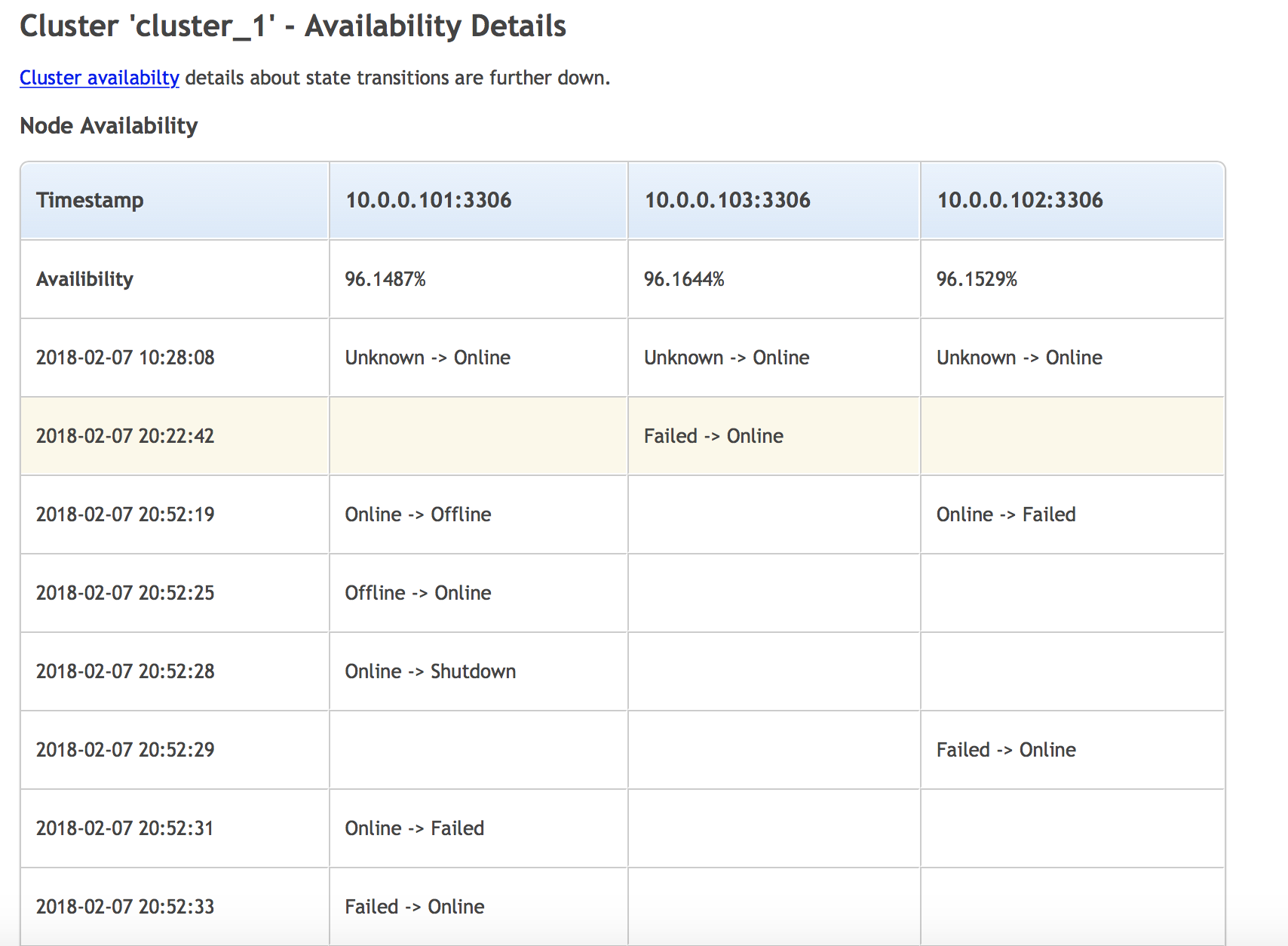
Were there any alerts triggered recently? What happened? Node down or, maybe replication broke? Or some other event related to your particular database did not occur? What about logs of your database? Are they clean or something out of ordinary was logged?
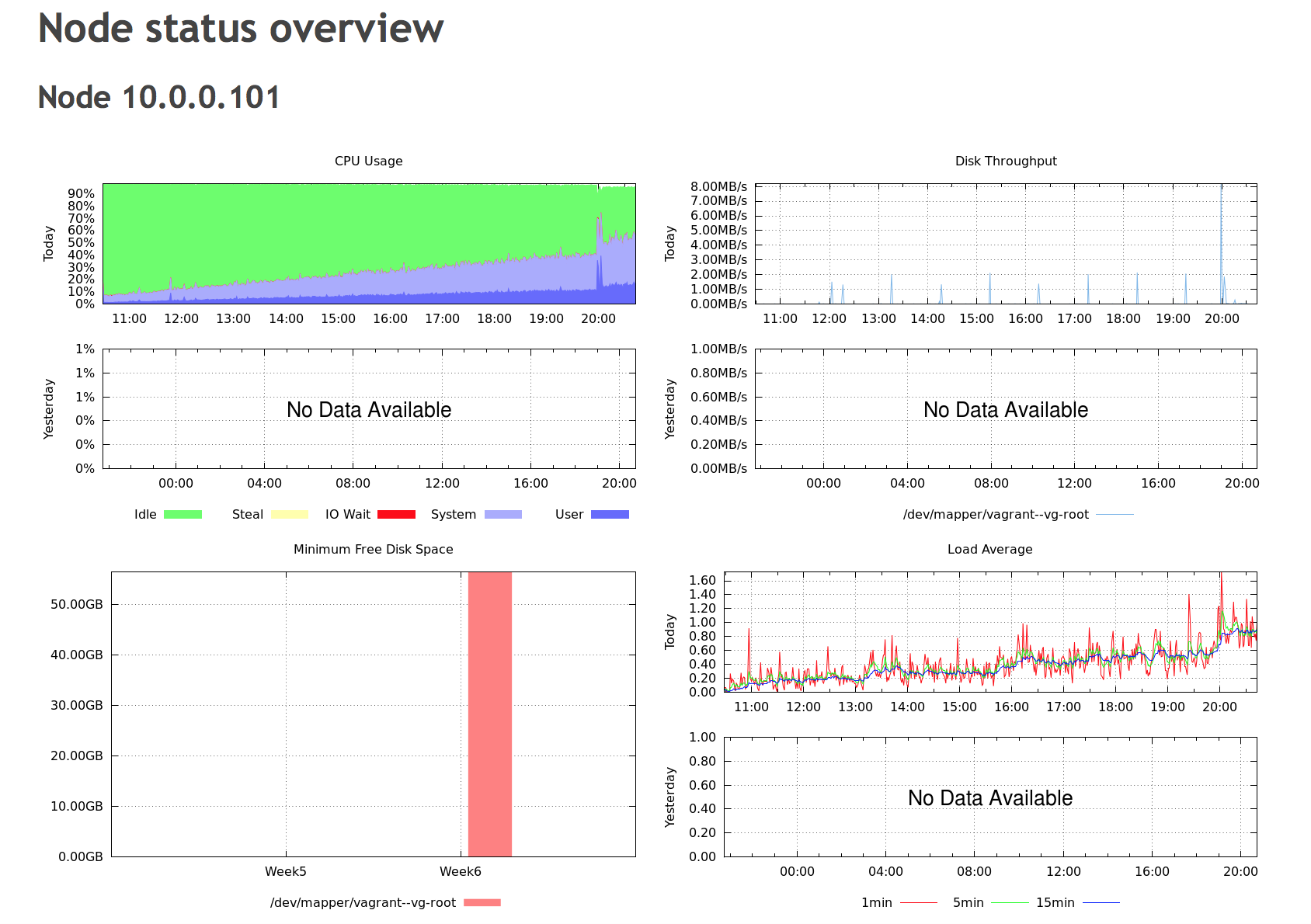
If you have a small environment, it might be possible to go through graphs, check all of the nodes, verify everything manually. If you have tens of database servers (not even speaking about hundreds) this becomes quite hard to do. Even if your environment is small, it might still be better to reduce the time needed for such checks. Automation is key here. It is also very important to focus on the most important metrics, otherwise you’ll get swamped with a lot of data which may not be critical for your database well-being.
This is it for today. We hope this blog gives you an idea about what database administrators have to deal on a daily basis, what are the most important aspects of their job. If you’d like to add something, we’d love to read your comments.



