blog
How to Automate Daily DevOps Database Tasks with Chef


Chef is a popular configuration management tool designed to deploy, configure and manage servers. It may not be that easy to use, as you need to be a programmer to manage the configurations in Ruby DSL. Nevertheless, it can be used to automate an entire infrastructure, including the databases.
In this blog, we’ll go through some Chef basics and see how we can use it to automate common routines that DBA deal with on a daily basis. We expect that you have a basic understanding of how Chef works, and how to install it. If not, I suggest to try this wonderful blog from Linode which covers introductory and installation procedures for Linux.
Before going through the process, let’s talk a bit about Chef.
What is Chef?
Chef is a Ruby based configuration management tool used to define infrastructure as code. Whether you’re operating in the cloud, on-premises, or in a hybrid environment, Chef automates how infrastructure is configured, deployed, and managed across your network, no matter its size.
This diagram shows how you develop, test, and deploy your Chef code.
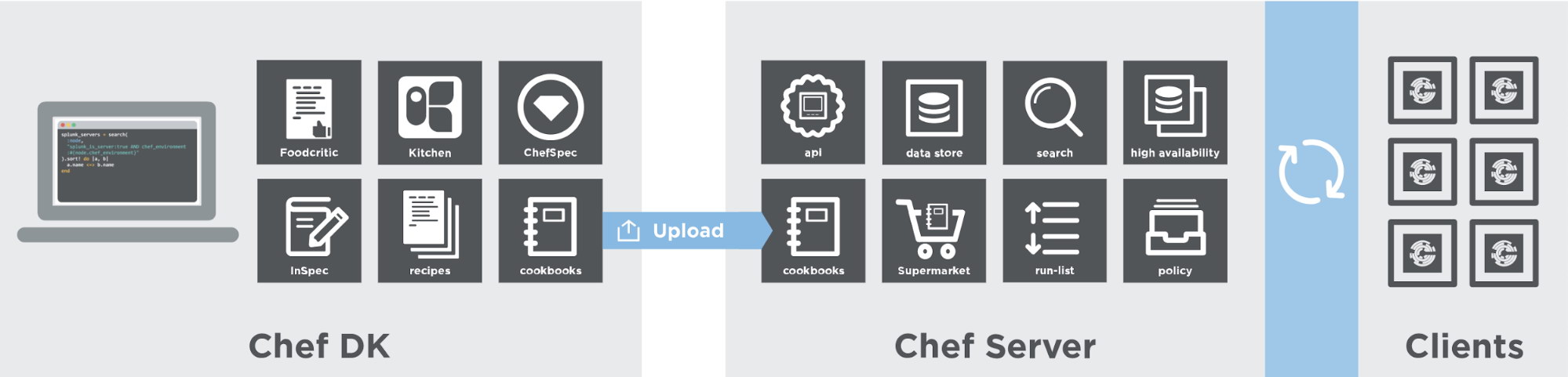
Based on the diagram above, Chef DK resides on the workstation, uploads the code into the Chef Server, and a Chef Infra Client installed on the target node(s) – the clients are in charge of applying the recipe to their corresponding node.
The Workstation is where you create and test your code before you deploy it to other environments. Your workstation is the computer where you author your cookbooks and administer your infrastructure. It’s typically the machine you use everyday. It can be any OS you choose, whether it’s Linux, macOS, or Windows. You’ll need to install a text editor (whichever you like) to write code and ChefDK to get the tools to test your code. The ChefDK includes other command line tools for interacting with Chef. These include knife for interacting with the Chef Infra Server, and chef for interacting with your local chef code repository (chef-repo).
The Chef Infra Server acts as a hub for configuration data. It stores cookbooks, the policies that are applied to the systems in your infrastructure and metadata that describes each system. The knife command lets you communicate with the Chef Infra Server from your workstation. For example, you use it to upload your cookbooks.
The Chef Infra Client has to be run periodically, for which chef-client command can be daemonized with the -d option. This iterative process ensures that the network as a whole converges to the state envisioned by business policy.
Components of Chef
There are a number of components in Chef but we’ll cover a few that we’ll be using that are important for the purpose of this blog, to understand what it does and what it serves for.
chef-repo
The chef-repo is the repository structure in which cookbooks are authored, tested, and maintained. This is configured in the workstation and should be synchronized with a version control system (such as git), and then managed as if it were source code
Cookbooks
It is the fundamental unit of configuration and policy distribution. A cookbook defines a scenario and contains everything that is required to support that scenario:
- Recipes that specify the resources to use and the order in which they are to be applied
- Attribute values
- File distributions
- Templates
- Extensions to Chef, such as custom resources and libraries
Recipe
It is the fundamental configuration element within the organization. A Chef recipe is a file that groups related resources, such as everything needed to configure a web server, database server, or a load balancer. A recipe can be included in another recipe, may use the results of a search query and read the contents of a data bag (including an encrypted data bag). It must be added to a run-list before it can be used by the Chef Infra Client. It is always executed in the same order as listed in a run-list. It has also its own DSL (Domain Specific Language) but uses Ruby. Most of the methods in the Recipe DSL are used to find a specific parameter and then tell the Chef Infra Client what action(s) to take, based on whether that parameter is present on a node.
Chef Infra is a powerful automation platform and it has a lot of areas to cover but we won’t be doing it here. Let’s proceed to the next section and see how you can use Chef to make things easier for you.
Automating Database Tasks With Chef
Using the first time with Chef requires you to create a repo for which cookbooks are stored. Let’s generate one:
$ chef generate repo dba-tasks-repoThis shall create a directory in your $HOME directory of the system user you are using that you have setup in the Chef Server.
Our example directory for the dba-tasks-repo shall look like this,
[vagrant@node2 ~]$ tree dba-tasks-repo/
dba-tasks-repo/
├── chefignore
├── cookbooks
│ ├── example
│ │ ├── attributes
│ │ │ └── default.rb
│ │ ├── metadata.rb
│ │ ├── README.md
│ │ └── recipes
│ │ └── default.rb
│ └── README.md
├── data_bags
│ ├── example
│ │ └── example_item.json
│ └── README.md
├── environments
│ ├── example.json
│ └── README.md
├── LICENSE
├── README.md
└── roles
├── example.json
└── README.mdAs stated earlier, your Chef repo must be managed by a version control system like git. So we need to configure that using the series of commands below:
$ git config --global user.name
$ git config --global user.email ~/dba-tasks-repo/.gitignore
$ git init .
$ git add .
$ git commit -m "Initialize a commit for our dba-tasks-repo" Creating a Cookbook to Install a Database
On this section, we’ll try to automate the installation of one PostgreSQL instance on a Centos 7 machine using Chef.
- Let’s generate a cookbook for this scenario.
$ cd ~/dba-tasks-repo/cookbooks/ $ chef generate cookbook pg_installThis shall create your cookbook named pg_install with the following directory structure under the $HOME/dba-tasks-repo/cookbooks/ path. See below:
[vagrant@node2 cookbooks]$ tree . ├── example │ ├── attributes │ │ └── default.rb │ ├── metadata.rb │ ├── README.md │ └── recipes │ └── default.rb ├── pg_install │ ├── Berksfile │ ├── CHANGELOG.md │ ├── chefignore │ ├── LICENSE │ ├── metadata.rb │ ├── README.md │ ├── recipes │ │ └── default.rb │ ├── spec │ │ ├── spec_helper.rb │ │ └── unit │ │ └── recipes │ │ └── default_spec.rb │ └── test │ └── integration │ └── default │ └── default_test.rb └── README.md -
Now, let’s create the recipe by editing the file recipes/default.rb and add the following contents in the file,
node['lamp_stack']['repos'].each do |repo, params| yum_repository repo do description params['description'] repositoryid repo baseurl params['baseurl'] enabled params['enabled'] gpgcheck params['gpgcheck'] end end include_recipe 'pg_install::package_install' unless ::File.exist?("/var/lib/pgsql/11/data/postgresql.conf")The contents for recipes/default.rb will create the repository on the target client node and includes the package_install recipe only if its PostgreSQL has not yet installed or postgresql.conf is not found.
-
We’ll also create a separate recipe which will manage the installation of PostgreSQL. Create the file recipes/package_install.rb and fill-up with the contents below:
package "postgresql11" do action :install end package "postgresql11-contrib" do action :install end package "postgresql11-libs" do action :install end package "postgresql11-server" do action :install end execute "pg11_initdb" do user "postgres" group "postgres" command "/usr/pgsql-11/bin/initdb --locale en_US.UTF-8 -E UTF8 -D /var/lib/pgsql/11/data" action :run end service "postgresql-11" do action [:enable, :start] end -
In step #2, we’re using variables (e.g. node[‘lamp_stack’]) which can be accessed by the recipe. These variables are defined using attributes in Chef. This is not necessary though. However, when your Chef recipes and cookbooks tend to get bigger, using the attribute will provide you convenience to handle this easily. To use that, generate an attribute by using the command below:
$ chef generate attribute defaultThis will generate a directory and a file named “default” for which you can declare the variables, like the one we’ve used in the above example. See the directory structure below,
[vagrant@node2 pg_install]$ tree attributes/ attributes/ └── default.rb -
Now let’s provide the variables in attributes/default.rb file.
default["lamp_stack"]["repos"]["pgdg"] = { "repositoryid" => "postgres", "description" => "PostgreSQL 11 $releasever - $basearch", "baseurl" => "http://download.postgresql.org/pub/repos/yum/11/redhat/rhel-$releasever-$basearch/", "enabled" => true, "gpgcheck" => false } default["lamp_stack"]["repos"]["pgdg-source"] = { "repositoryid" => "postgres", "description" => "PostgreSQL 11 $releasever - $basearch - Source", "baseurl" => "http://yum.postgresql.org/srpms/11/redhat/rhel-$releasever-$basearch", "enabled" => true, "gpgcheck" => false } -
We’re now setup and finished with the configuration, but we need to identify if all we have setup or configured is correct. To determine this, you can use the following commands below:
$ cd ~/dba-tasks-repo/ $ cookstyle cookbooks/pg_install/This will let you know of any errors in the code or .rb file that we setup. Example output is shown below:

Another way to check is through “knife” command. Example,
[vagrant@node2 dba-tasks-repo]$ knife cookbook test pg_install WARNING: DEPRECATED: Please use ChefSpec or Cookstyle to syntax-check cookbooks. checking pg_install Running syntax check on pg_install Validating ruby files Validating templates
Using the Cookbook – Bootstrapping a Node
The setup and the code has been done, we need to upload the files to the Chef Server and then target a node for which we need to bootstrap and execute our cookbook. For the purpose of this blog, we will provision a node as the client, using Centos 7.6 with IP 192.168.70.90. We also need to modify the /etc/hosts so we can reference the client using hostname as its valid FQDN (Fully Qualified Domain Name). This is how my /etc/hosts looks like as follows:
[root@node9 vagrant]# cat /etc/hosts
127.0.0.1 node9 node9
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.70.20 workstation
192.168.70.10 node1
192.168.70.30 node3
192.168.70.90 node9The host workstation is where we placed the cookbook while the node1 serves as the Chef Server. Hence, node3 and node9 are the client nodes. Let’s proceed and continue on bootstrapping and running the cookbook in the node9 client. Take note that you need to apply the same /etc/hosts to your workstation, Chef Server, as well as the client unless you are using a DNS. Chef requires that all the nodes are able to resolve the network connectivity and establish a connection to each other.
- Run the bootstrap command below on the workstation,
$ knife bootstrap 192.168.70.90 -x vagrant --sudo --node-name node9Wondering the -x argument means. It’s the system user that you have setup in your Chef Server for which I’m using the system user “vagrant“.
- For this setup, we’ll be using a self-signed certificate so we’ll have to run the following command below,
$ knife ssl fetchYou can also determine the list of clients you have associated. See below as an example:
[vagrant@node2 dba-tasks-repo]$ knife client list devops-validator node3 node9 - Add the recipe now on the client’s run list. This will be executed when chef-client command run.
knife node run_list add node9 "recipe[pg_install]"You can also determine and query the information what has the node’s run-list recipe has.
[vagrant@node2 cookbooks]$ knife node show node9 Node Name: node9 Environment: _default FQDN: node9 IP: 10.0.2.15 Run List: recipe[pg_install], role[pg_nodes] Roles: pg_nodes Recipes: pg_install, pg_install::default Platform: centos 7.6.1810 Tags: - Upload the cookbook to the Chef server
$ knife cookbook upload pg_install - Lastly, let’s execute chef-client command in the workstation. See the example result below:
[vagrant@node2 dba-tasks-repo]$ knife ssh 'name:node9' 'sudo chef-client' -x vagrant node9 Starting Chef Client, version 14.12.9 node9 resolving cookbooks for run list: ["pg_install"] node9 Synchronizing Cookbooks: node9 - pg_install (0.1.0) node9 Installing Cookbook Gems: node9 Compiling Cookbooks... node9 Converging 8 resources node9 Recipe: pg_install::default node9 * yum_repository[pgdg] action create node9 * template[/etc/yum.repos.d/pgdg.repo] action create node9 - create new file /etc/yum.repos.d/pgdg.repo node9 - update content in file /etc/yum.repos.d/pgdg.repo from none to 5b813e node9 --- /etc/yum.repos.d/pgdg.repo 2019-05-15 06:35:45.116882856 +0000 node9 +++ /etc/yum.repos.d/.chef-pgdg20190515-11985-1y5w714.repo 2019-05-15 06:35:45.116882856 +0000 node9 @@ -1 +1,10 @@ node9 +# This file was generated by Chef node9 +# Do NOT modify this file by hand. node9 + node9 +[pgdg] node9 +name=PostgreSQL 11 $releasever - $basearch node9 +baseurl=http://download.postgresql.org/pub/repos/yum/11/redhat/rhel-$releasever-$basearch/ node9 +enabled=1 node9 +fastestmirror_enabled=0 node9 +gpgcheck=0 node9 - change mode from '' to '0644' node9 - restore selinux security context node9 * execute[yum clean metadata pgdg] action run node9 - execute yum clean metadata --disablerepo=* --enablerepo=pgdg node9 * execute[yum-makecache-pgdg] action run node9 - execute yum -q -y makecache --disablerepo=* --enablerepo=pgdg node9 * ruby_block[package-cache-reload-pgdg] action create node9 - execute the ruby block package-cache-reload-pgdg node9 * execute[yum clean metadata pgdg] action nothing (skipped due to action :nothing) node9 * execute[yum-makecache-pgdg] action nothing (skipped due to action :nothing) node9 * ruby_block[package-cache-reload-pgdg] action nothing (skipped due to action :nothing) node9 node9 * yum_repository[pgdg-source] action create node9 * template[/etc/yum.repos.d/pgdg-source.repo] action create node9 - create new file /etc/yum.repos.d/pgdg-source.repo node9 - update content in file /etc/yum.repos.d/pgdg-source.repo from none to 9148de node9 --- /etc/yum.repos.d/pgdg-source.repo 2019-05-15 06:35:48.705922418 +0000 node9 +++ /etc/yum.repos.d/.chef-pgdg-source20190515-11985-1qtu1o1.repo 2019-05-15 06:35:48.705922418 +0000 node9 @@ -1 +1,10 @@ node9 +# This file was generated by Chef node9 +# Do NOT modify this file by hand. node9 + node9 +[pgdg-source] node9 +name=PostgreSQL 11 $releasever - $basearch - Source node9 +baseurl=http://yum.postgresql.org/srpms/11/redhat/rhel-$releasever-$basearch node9 +enabled=1 node9 +fastestmirror_enabled=0 node9 +gpgcheck=0 node9 - change mode from '' to '0644' node9 - restore selinux security context node9 * execute[yum clean metadata pgdg-source] action run node9 - execute yum clean metadata --disablerepo=* --enablerepo=pgdg-source node9 * execute[yum-makecache-pgdg-source] action run node9 - execute yum -q -y makecache --disablerepo=* --enablerepo=pgdg-source node9 * ruby_block[package-cache-reload-pgdg-source] action create node9 - execute the ruby block package-cache-reload-pgdg-source node9 * execute[yum clean metadata pgdg-source] action nothing (skipped due to action :nothing) node9 * execute[yum-makecache-pgdg-source] action nothing (skipped due to action :nothing) node9 * ruby_block[package-cache-reload-pgdg-source] action nothing (skipped due to action :nothing) node9 node9 Recipe: pg_install::package_install node9 * yum_package[postgresql11] action install node9 - install version 0:11.3-1PGDG.rhel7.x86_64 of package postgresql11 node9 * yum_package[postgresql11-contrib] action install node9 - install version 0:11.3-1PGDG.rhel7.x86_64 of package postgresql11-contrib node9 * yum_package[postgresql11-libs] action install (up to date) node9 * yum_package[postgresql11-server] action install node9 - install version 0:11.3-1PGDG.rhel7.x86_64 of package postgresql11-server node9 * execute[pg11_initdb] action run node9 - execute /usr/pgsql-11/bin/initdb --locale en_US.UTF-8 -E UTF8 -D /var/lib/pgsql/11/data node9 * service[postgresql-11] action enable node9 - enable service service[postgresql-11] node9 * service[postgresql-11] action start node9 - start service service[postgresql-11] node9 node9 Running handlers: node9 Running handlers complete node9 Chef Client finished, 16/23 resources updated in 40 seconds
Automating Other Daily DBA Tasks
Since we have a cookbook for automating the installation of PostgreSQL 11 in CentOS. Let’s consider a scenario – what if the pg_hba.conf file has been updated by someone without following the runbooks or policy your company wants to impose. Let’s look at an example on how we can automate this as auto-default and overwrite any manual modification of pg_hba.conf, so that any unauthorized changes will be undone and we’ll keep our desired default values set up in the cookbook.
- Generate a new cookbook called pg_daily_checker
$ chef generate cookbook pg_daily_checker - Let’s create a cookbook file which will have a static contents of the file and named it pg_hba.conf under folder files/default of the cookbook pg_daily_checker directory.
$ cd ~/dba-tasks-repo/cookbooks/pg_daily_checker/ $ mkdir -p files/default/Where your pg_hba.conf will contain an example like below,
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all trust # IPv4 local connections: host all all 127.0.0.1/32 trust # IPv6 local connections: host all all ::1/128 trust # Allow replication connections from localhost, by a user with the # replication privilege. local replication all trust host replication all 127.0.0.1/32 trust host replication all ::1/128 trust - In your recipes/default.rb file, paste the contents below,
cookbook_file "/var/lib/pgsql/11/data/pg_hba.conf" do user "postgres" group "postgres" source "pg_hba.conf" mode "0600" end - Let’s register as a run-list for the node, and upload it to the Chef Server,
$ knife node run_list add node9 recipe[pg_daily_checker] $ knife cookbook upload pg_daily_checker -
Try to edit the file /var/lib/pgsql/11/data/pg_hba.conf with unwanted entry or username. In my example, this what it looks like,
### File pg_hba.conf BEFORE pg_daily_checker cookbook ran [root@node9 vagrant]# tail -5 /var/lib/pgsql/11/data/pg_hba.conf host replication cmon_replication 192.168.70.150/32 md5 host replication cmon_replication 192.168.70.140/32 md5 host all postgresqldbadmin 192.168.70.200/32 md5 host all hackuser 192.168.70.200/32 md5 ## pg_daily_checker cook is executed [vagrant@node2 pg_daily_checker]$ knife cookbook delete pg_daily_checker -y; knife cookbook upload pg_daily_checker; knife ssh 'name:node9' 'sudo chef-client' -x vagrant | tail -15 Deleted cookbook[pg_daily_checker version 0.1.0] Uploading pg_daily_checker [0.1.0] Uploaded 1 cookbook. node9 * cookbook_file[/var/lib/pgsql/11/data/pg_hba.conf] action create node9 - update content in file /var/lib/pgsql/11/data/pg_hba.conf from 3c551f to 25d756 node9 --- /var/lib/pgsql/11/data/pg_hba.conf 2019-05-15 09:41:47.442101182 +0000 node9 +++ /var/lib/pgsql/11/data/.chef-pg_hba20190515-17898-1ugwemp.conf 2019-05-15 09:43:55.065554035 +0000 node9 @@ -17,6 +17,5 @@ node9 host replication cmon_replication 192.168.70.150/32 md5 node9 host replication cmon_replication 192.168.70.140/32 md5 node9 host all postgresqldbadmin 192.168.70.200/32 md5 node9 -host all hackuser 192.168.70.200/32 md5 node9 node9 - restore selinux security context node9 node9 Running handlers: node9 Running handlers complete node9 Chef Client finished, 1/11 resources updated in 01 seconds ### File pg_hba.conf AFTER pg_daily_checker cookbook ran [root@node9 vagrant]# tail -5 /var/lib/pgsql/11/data/pg_hba.conf host replication cmon_replication 192.168.70.150/32 md5 host replication cmon_replication 192.168.70.140/32 md5 host all postgresqldbadmin 192.168.70.200/32 md5
Here, we exemplified how feasible it is to use automation platform tools like Chef, and how to monitor your database nodes.
With Chef, you can also run ad-hoc commands that you want to run or apply just-in-time results when you need to. For example, let’s create a role first:
$ knife role create pg_nodes
{
"name": "pg_nodes",
"description": "These are the postgresql nodes",
"json_class": "Chef::Role",
"default_attributes": {
},
"override_attributes": {
},
"chef_type": "role",
"run_list": [
],
"env_run_lists": {
}
}
"/tmp/knife-edit-20190515-13682-1sl56tp.json" 18L, 243C writtenThen list the roles created to verify,
[vagrant@node2 dba-tasks-repo]$ knife role list
pg_nodesThen add the roles to your desired nodes. In this example, I am adding it to node3 and node9 as follows,
[vagrant@node2 dba-tasks-repo]$ knife node run_list add node9 'role[pg_nodes]'
node9:
run_list:
recipe[pg_install]
role[pg_nodes]
[vagrant@node2 dba-tasks-repo]$ knife node run_list add node3 'role[pg_nodes]'
node3:
run_list:
recipe[lamp_stack]
role[pg_nodes]Now, let’s try to list the information of the specified block devices in the nodes node3 and node9 like as follows,
[vagrant@node2 dba-tasks-repo]$ knife ssh "role:pg_nodes" --ssh-user vagrant "lsblk -a"
node9 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
node9 sda 8:0 0 40G 0 disk
node9 |-sda1 8:1 0 1M 0 part
node9 |-sda2 8:2 0 1G 0 part /boot
node9 `-sda3 8:3 0 39G 0 part
node9 |-VolGroup00-LogVol00 253:0 0 37.5G 0 lvm /
node9 `-VolGroup00-LogVol01 253:1 0 1.5G 0 lvm [SWAP]
node9 loop0 7:0 0 0 loop
node3 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
node3 sda 8:0 0 40G 0 disk
node3 |-sda1 8:1 0 1M 0 part
node3 |-sda2 8:2 0 1G 0 part /boot
node3 `-sda3 8:3 0 39G 0 part
node3 |-VolGroup00-LogVol00 253:0 0 37.5G 0 lvm /
node3 `-VolGroup00-LogVol01 253:1 0 1.5G 0 lvm [SWAP]Using this approach provides a great way to automate routine tasks and save a bunch of time.
Lastly, to enforce the consistency of your managed files by Chef to your nodes, you can run the chef-client as a daemon to keep your registered clients/nodes enforce the run-list be applied periodically as desired. This shall keep your managed files constant or updated when overwritten and avoid manual actions that do not adhere to your company policy and runbooks.
e.g.
$ sudo chef-client --daemonize -i 60 The –daemonize option will run chef-client as a daemon and -i specifies the interval that chef-client command will run again to execute the run-list.
Conclusion
You can pretty much automate most things with Chef, but as we have seen, it does come with a significant amount of coding. Cookbooks need to be built for the specific database versions you want to automate, and these cookbooks need to be maintained whenever you upgrade the databases. Building cookbooks to deploy and manage databases, especially when it comes to deploying replicated or clustered setups, may be especially challenging. And managing availability can also be tricky, as you really need to know how to perform failovers and reconfigurations so you do not end up losing data.
In our next blog, we’ll show you how to leverage ClusterControl in your cookbooks, and delegate all the DBA tasks to it (so you don’t have to build and maintain thousands of lines of ruby code to manage databases).



