blog
How to Achieve Automatic Failover for TimescaleDB

The rising demand for high availability systems and tight SLA’s pushes us to replace manual procedures with automated solutions. But do you have the time and necessary resources to address the complexity of failover operations by yourself? Will you sacrifice production database downtime to learn it the hard way?
ClusterControl provides advanced support for failure detection and handling. It’s used by many enterprise organizations, keeping the most critical productions systems up and running in 24/7 mode.
This database management solution also supports you with the deployment of different load proxies. These proxies play a key role in the HA stack so there is no need to adjust application connection string or DNS entry to redirect application connections to the new master node.
When failure is detected, ClusterControl does all the background work to elect a new master, deploy fail-over slave servers, and configure load balancers. In this blog, you will learn how to achieve automatic failover of TimescaleDB in your production systems.
Deploying Entire Replication Topologies
Starting from ClusterControl 1.7.2 you can deploy an entire TimescaleDB replication setup in the same way as you would deploy PostgreSQL: you can use “Deploy Cluster” menu to deploy a primary and one or more TimescaleDB standby servers. Let’s see what it looks like.
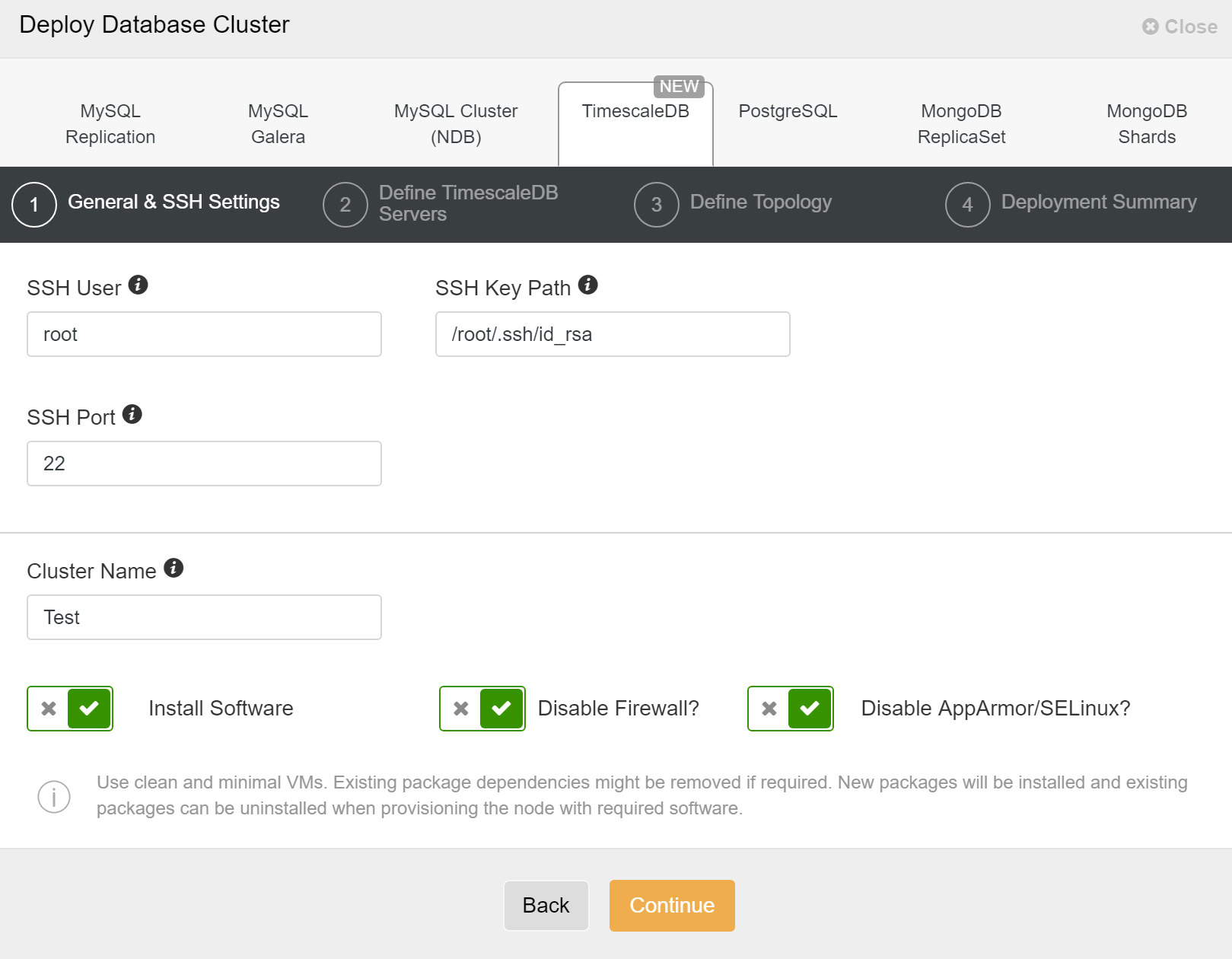
First, you need to define access details when deploying new clusters using ClusterControl. It requires root or sudo password access to all nodes on which your new cluster will be deployed.
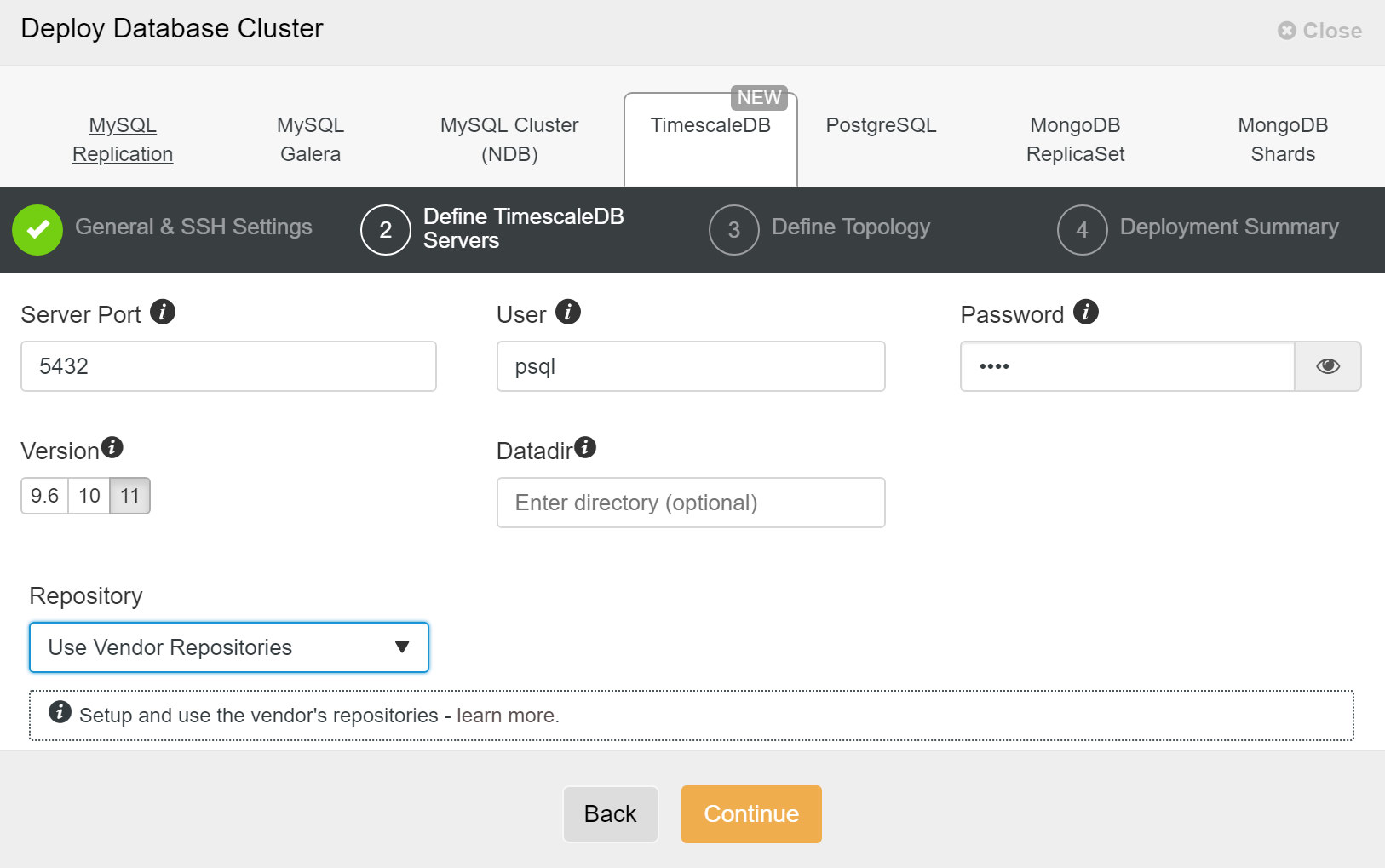
Next, we need to define the user and password for the TimescaleDB user.
Finally, you want to define the topology – which host should be the primary and which hosts should be configured as standby. While you define hosts in the topology, ClusterControl will check if the ssh access works as expected – this lets you catch any connectivity issues early on. On the last screen, you will be asked about the type of replication synchronous or asynchronous.
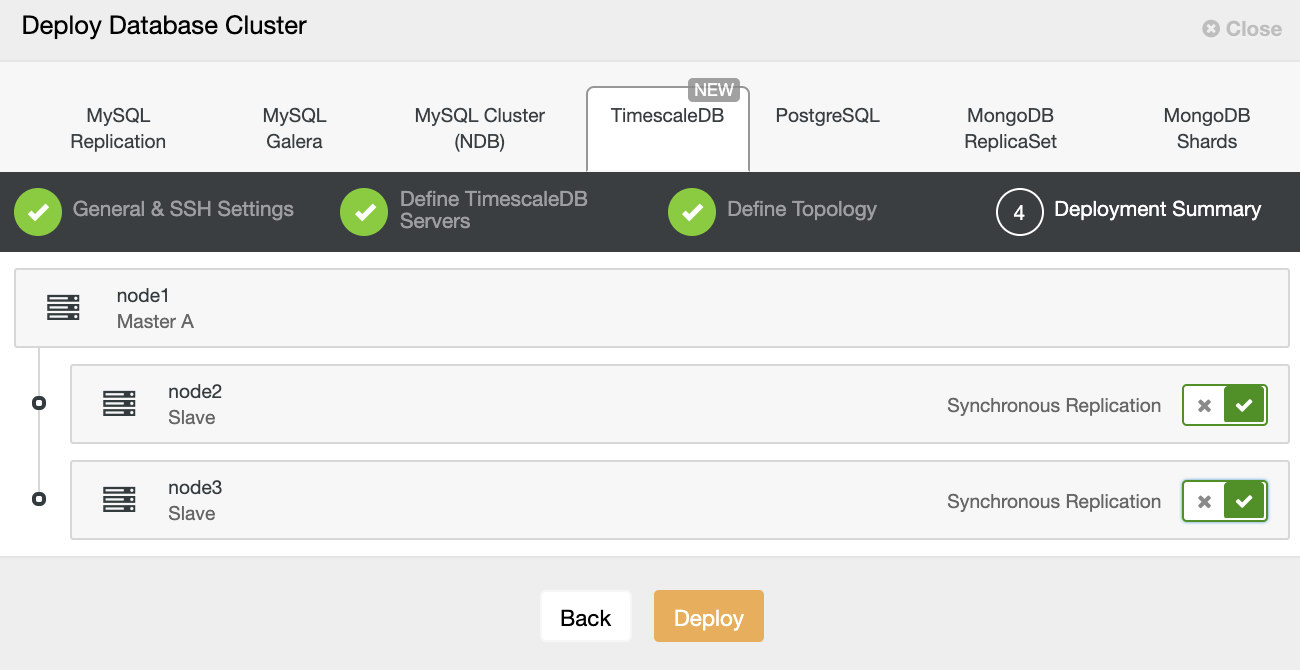
That’s it, it is then a matter of starting the deployment. A job is created in ClusterControl, and you will be able to follow the progress.
Once you finish you will see the topology setup with roles in the cluster. Note that we also added a load balancer (HAProxy) in front of the database instances so the automatic failover will not require changes in the database connection settings.
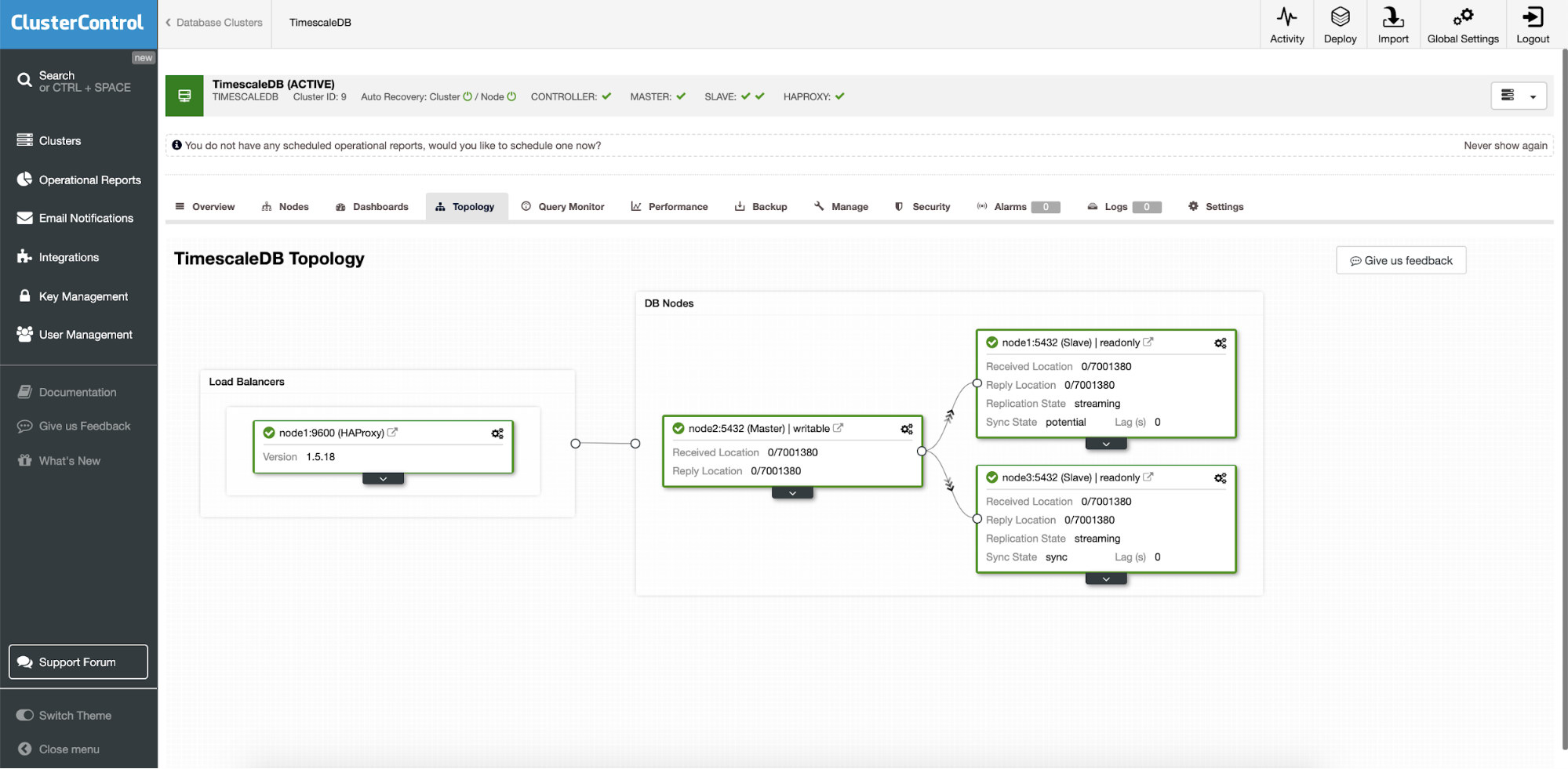
When Timescale is deployed by ClusterControl automatic recovery is enabled by default. The state can be checked in the cluster bar.

Failover Configuration
Once the replication setup is deployed, ClusterControl is able to monitor the setup and automatically recover any failed servers. It can also orchestrate changes in topology.
ClusterControl automatic failover was designed with the following principles:
- Make sure the master is really dead before you failover
- Failover only once
- Do not failover to an inconsistent slave
- Only write to the master
- Do not automatically recover the failed master
With the built-in algorithms, failover can often be performed pretty quickly so you can assure the highest SLA’s for your database environment.
The process is configurable. It comes with multiple parameters which you can use to adopt recovery to the specifics of your environment.
| max_replication_lag | Max allowed replication lag in seconds before |
| replication_stop_on_error | Failover/switchover procedures will fail if errors are encountered that may cause data loss. Enabled by default. 0 means disable, |
| replication_auto_rebuild_slave | If the SQL THREAD is stopped and the error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default). |
| replication_failover_blacklist | Comma-separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set. |
| replication_failover_whitelist | Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set. |
Failover Handling
When a master failure is detected, a list of master candidates is created and one of them is chosen to be the new master. It is possible to have a whitelist of servers to promote to primary, as well as a blacklist of servers that cannot be promoted to primary. The remaining slaves are now slaved off the new primary, and the old primary is not restarted.
Below we can see a simulation of node failure.
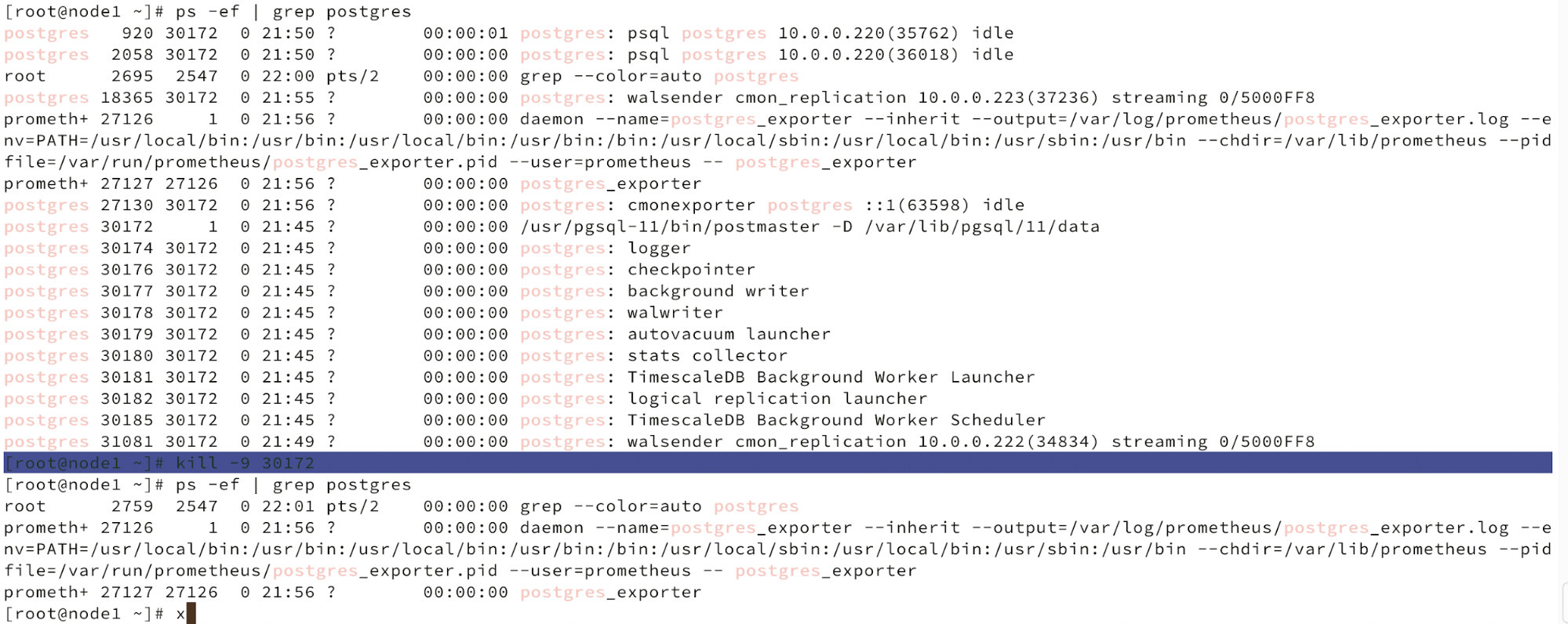
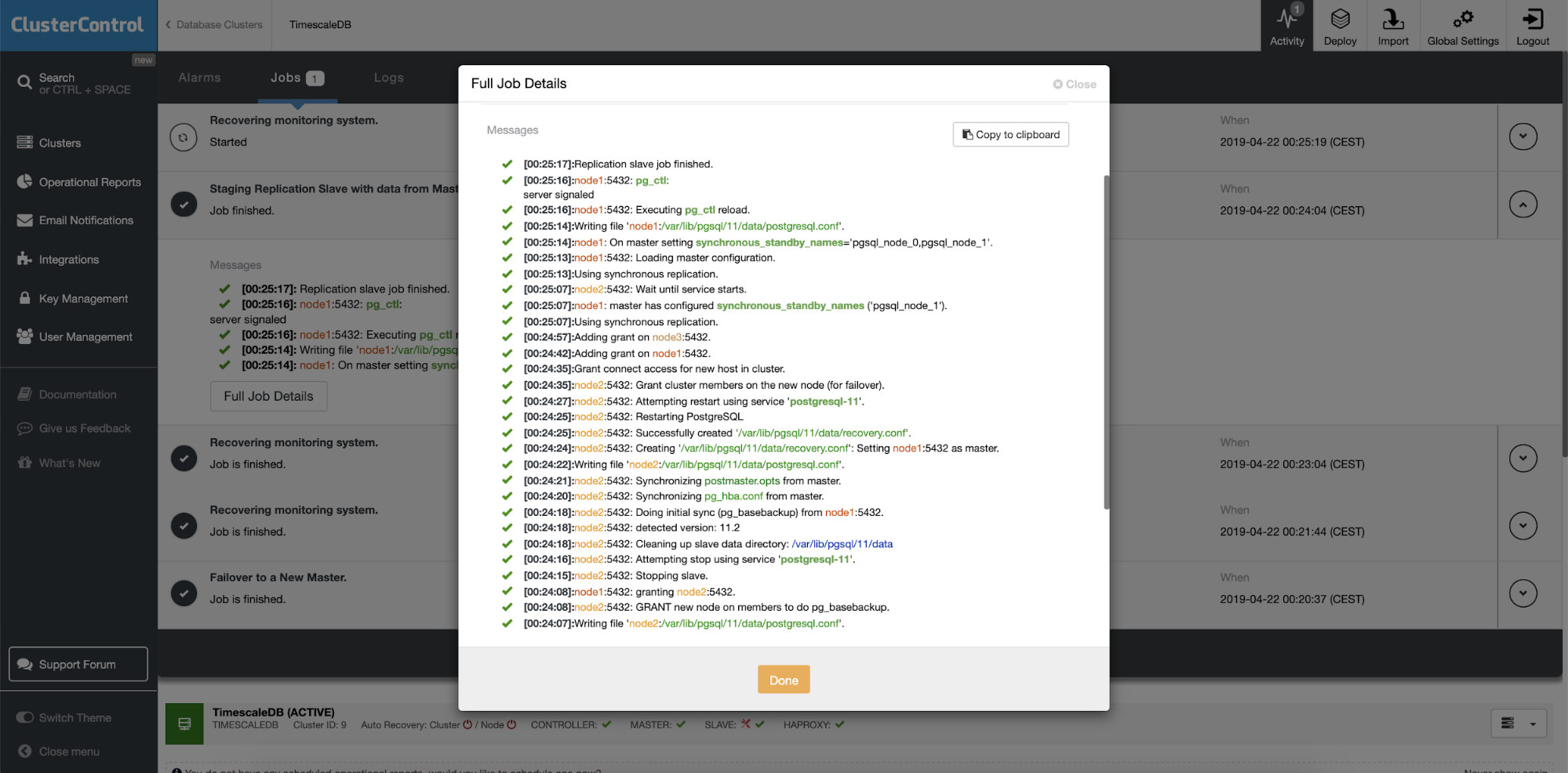
When nodes malfunction is detected and auto recovery is detected ClusterControl triggers job to perform failover. Below we can see actions taken to recover the cluster.
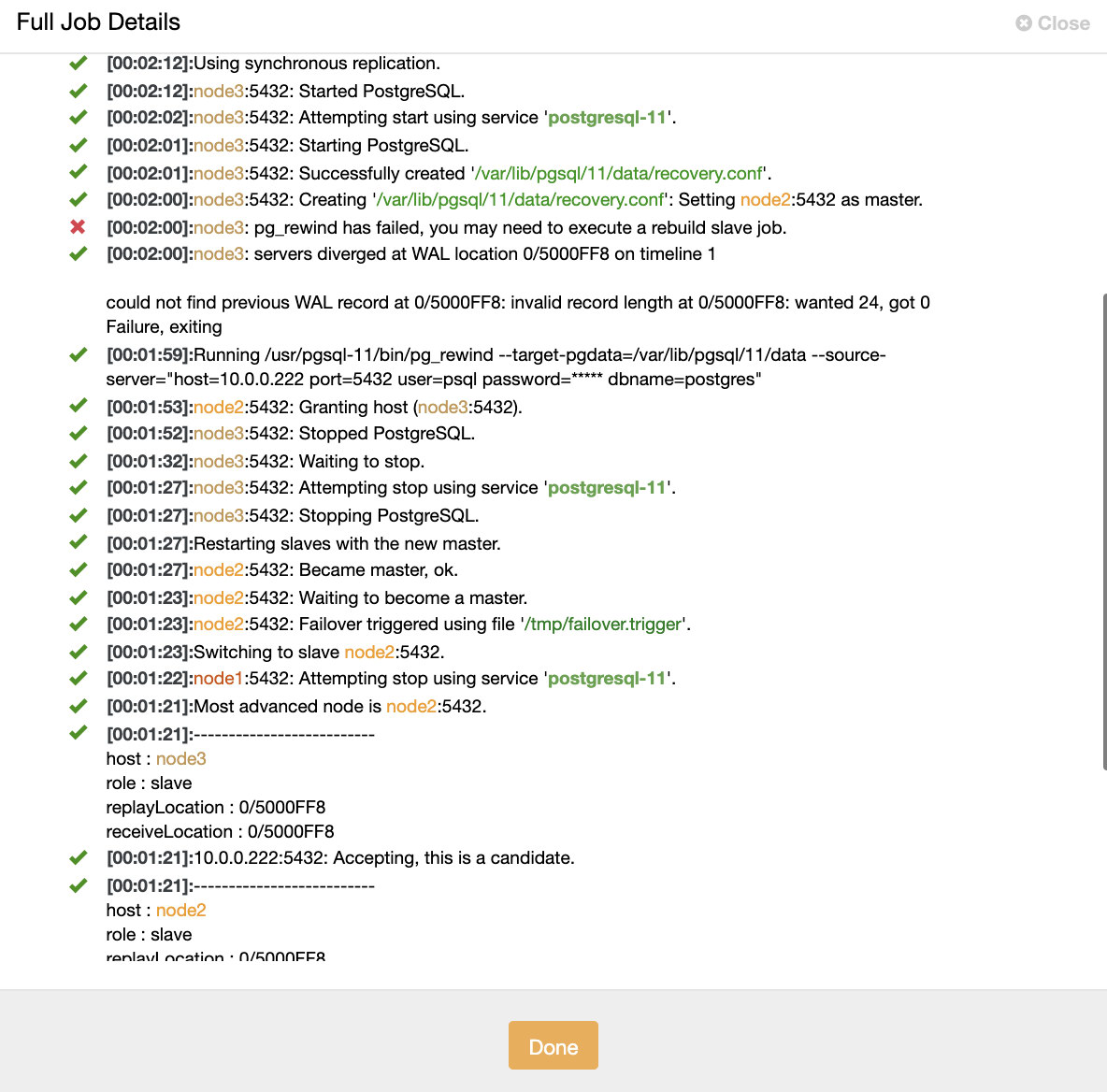
ClusterControl intentionally keeps the old primary offline because it may happen that some of the data have not been transferred to the standby servers. In such a case, the primary is the only host containing this data and you may want to recover the missing data manually. For those who want to have the failed primary automatically rebuilt, there is an option in the cmon configuration file: replication_auto_rebuild_slave. By default, it’s disabled but when the user enables it, the failed primary will be rebuilt as a slave of the new primary. Of course, if there is any lacking data which exists only on the failed primary, that data will be lost.
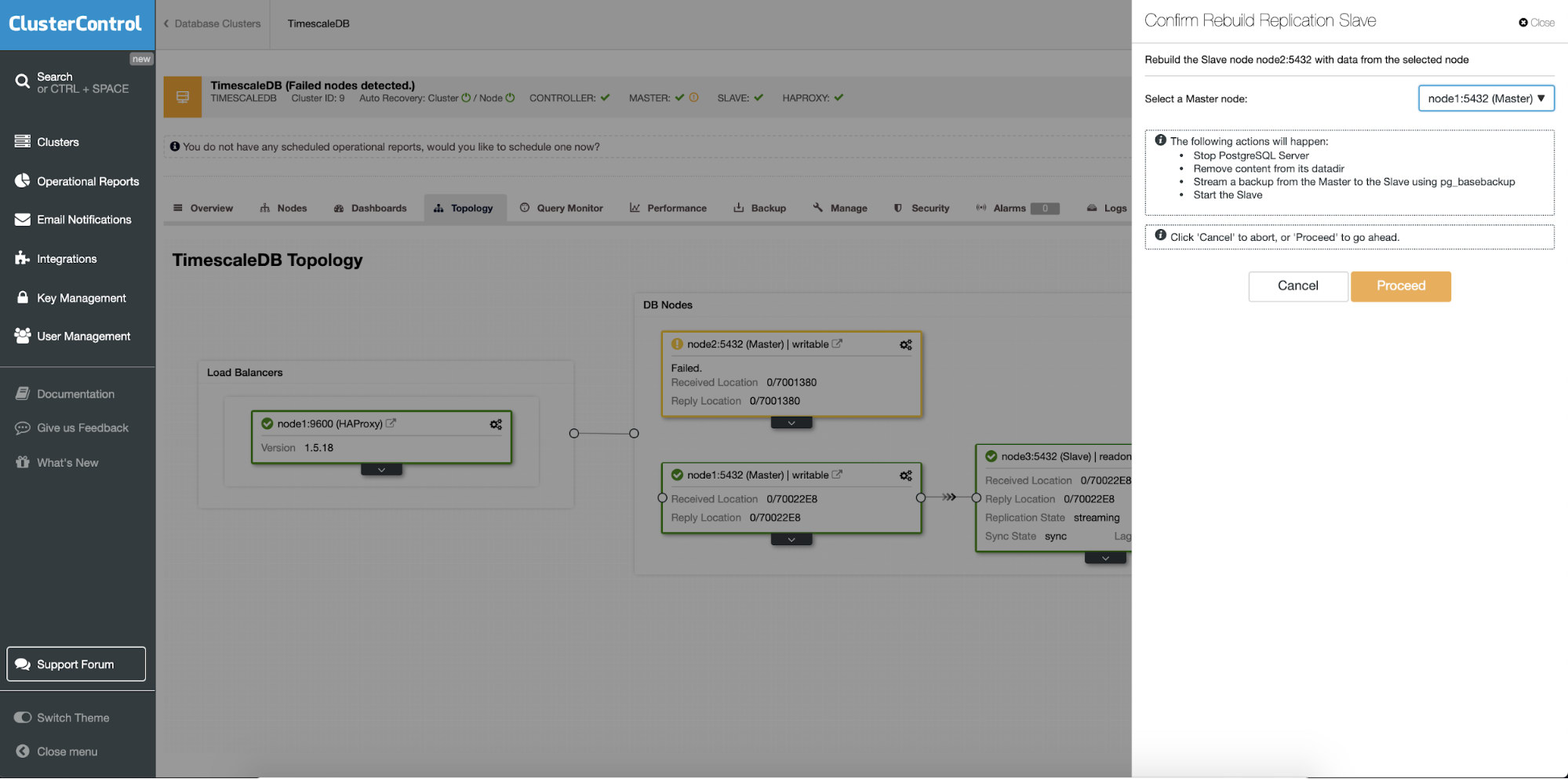
Rebuilding Standby Servers
Different feature is “Rebuild Replication Slave” job which is available for all slaves (or standby servers) in the replication setup. This is to be used for instance when you want to clear out the data on the standby and rebuild it again with a fresh copy of data of the primary. It can be beneficial if a standby server is not able to connect and replicate from the primary for some reason.