blog
Deploy MySQL Replication and ProxySQL With Automatic Failover

MySQL replication is a very popular choice to build highly available setups. It is fairly predictable, robust and efficient. It is also quite easy to setup – install MySQL software, create replication users and configure replication. However, building a complete high availability stack takes a bit more work. How do you ensure that applications are always writing to the master, even in case where the master role has switched? How do you ensure that e.g. a master failure will be detected, and another server will be elected as master? What do you do if a slave fails and refuses to rejoin the setup? These are all things that one needs to consider when architecting a high availability solution on top of MySQL Replication. In our case here, we will make use of ProxySQL to ensure writes are sent to the master and reads are load balanced across slaves. Keepalived will be used to manage a VirtualIP on active/passive ProxySQL instances. ClusterControl will be used to deploy all the components and manage failover.
First, we need to deploy our cluster. ClusterControl requires key-based SSH access, either via root or using sudo (with or without the password), so this has to be prepared beforehand.
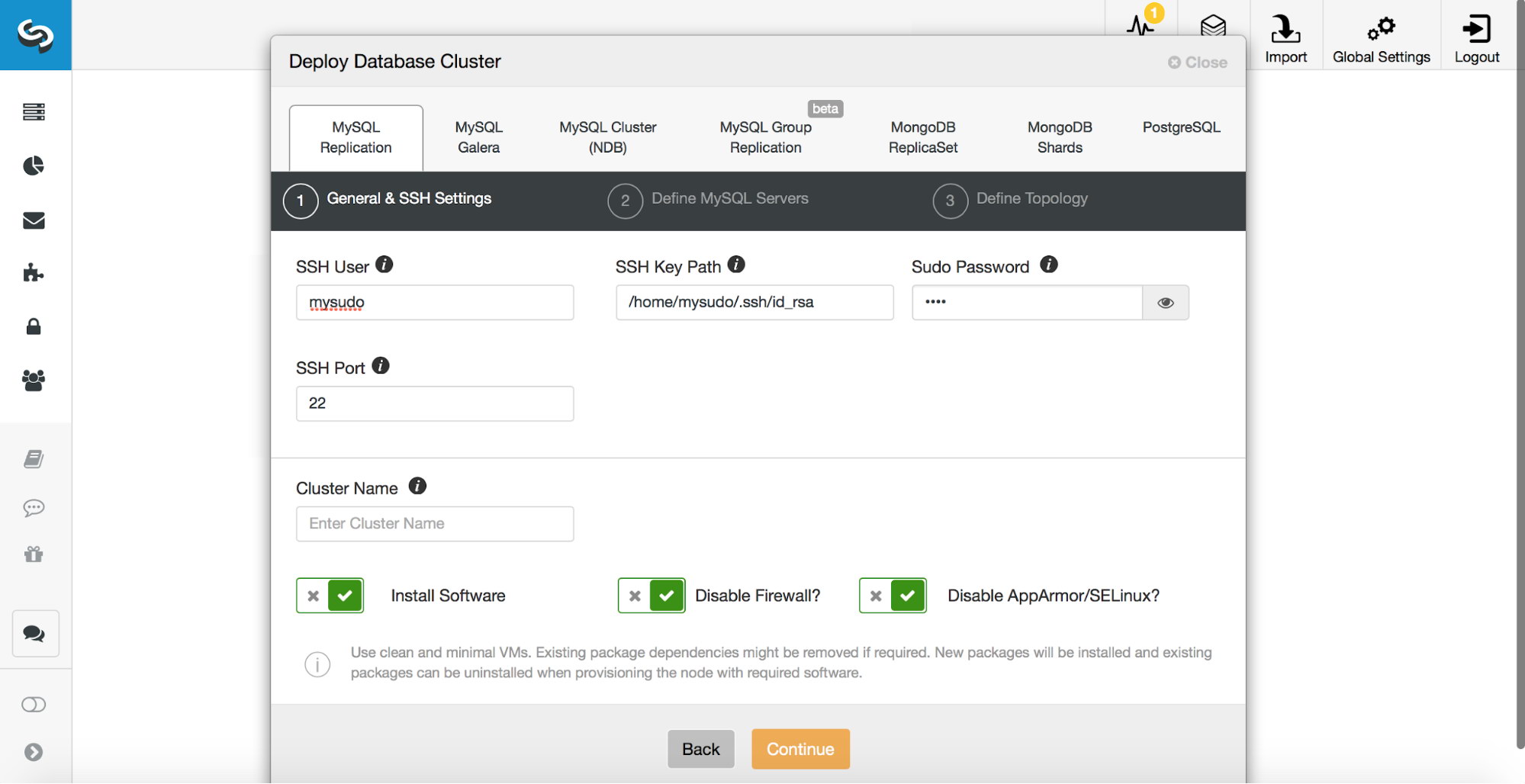
Once the access is configured, you can proceed with the deployment. In the deployment wizard, pick MySQL Replication and pass the access details.
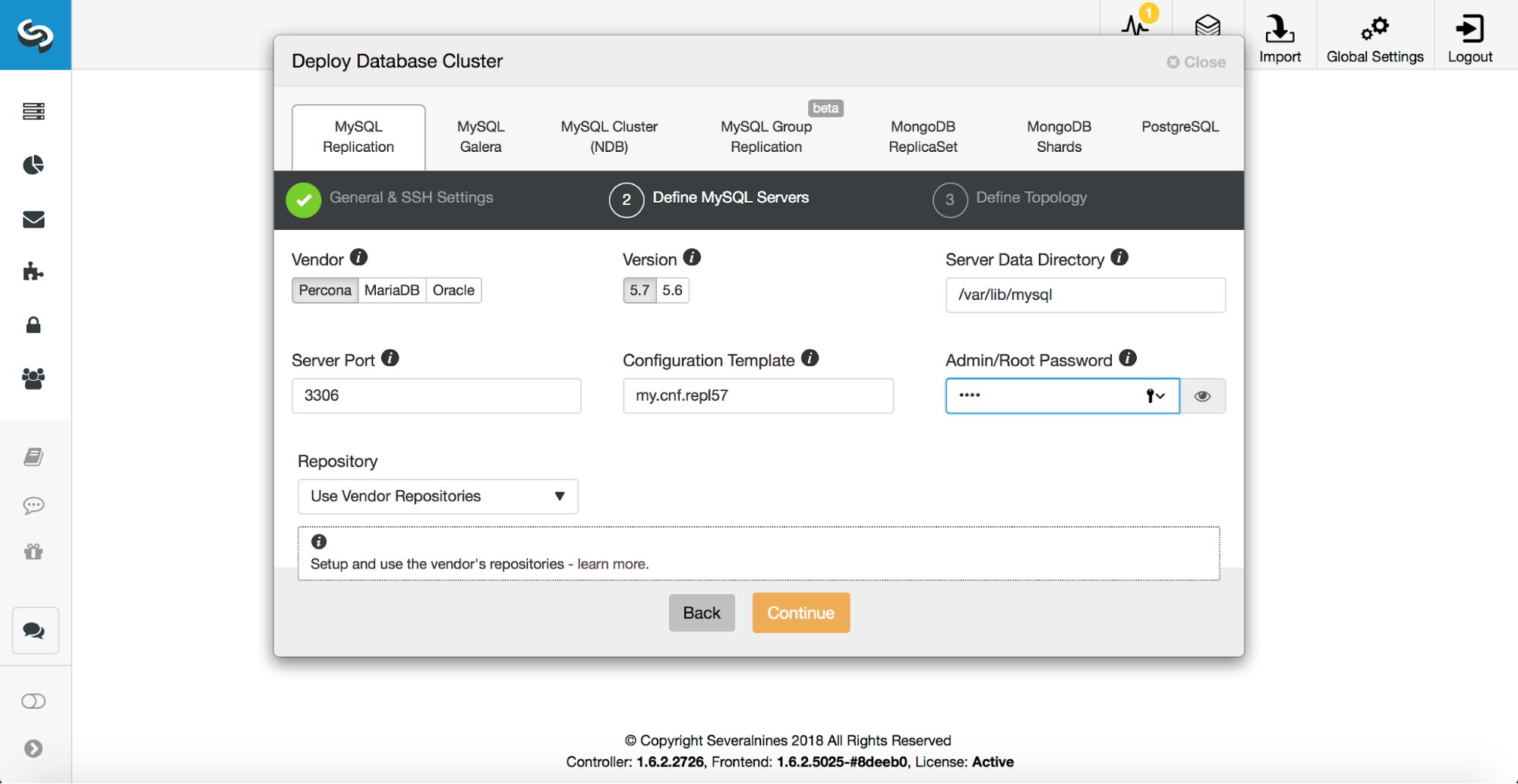
Then, you need to decide which database vendor and version to use. You have to pass a password for superuser in MySQL. You can also configure which template should be used for the my.cnf file.
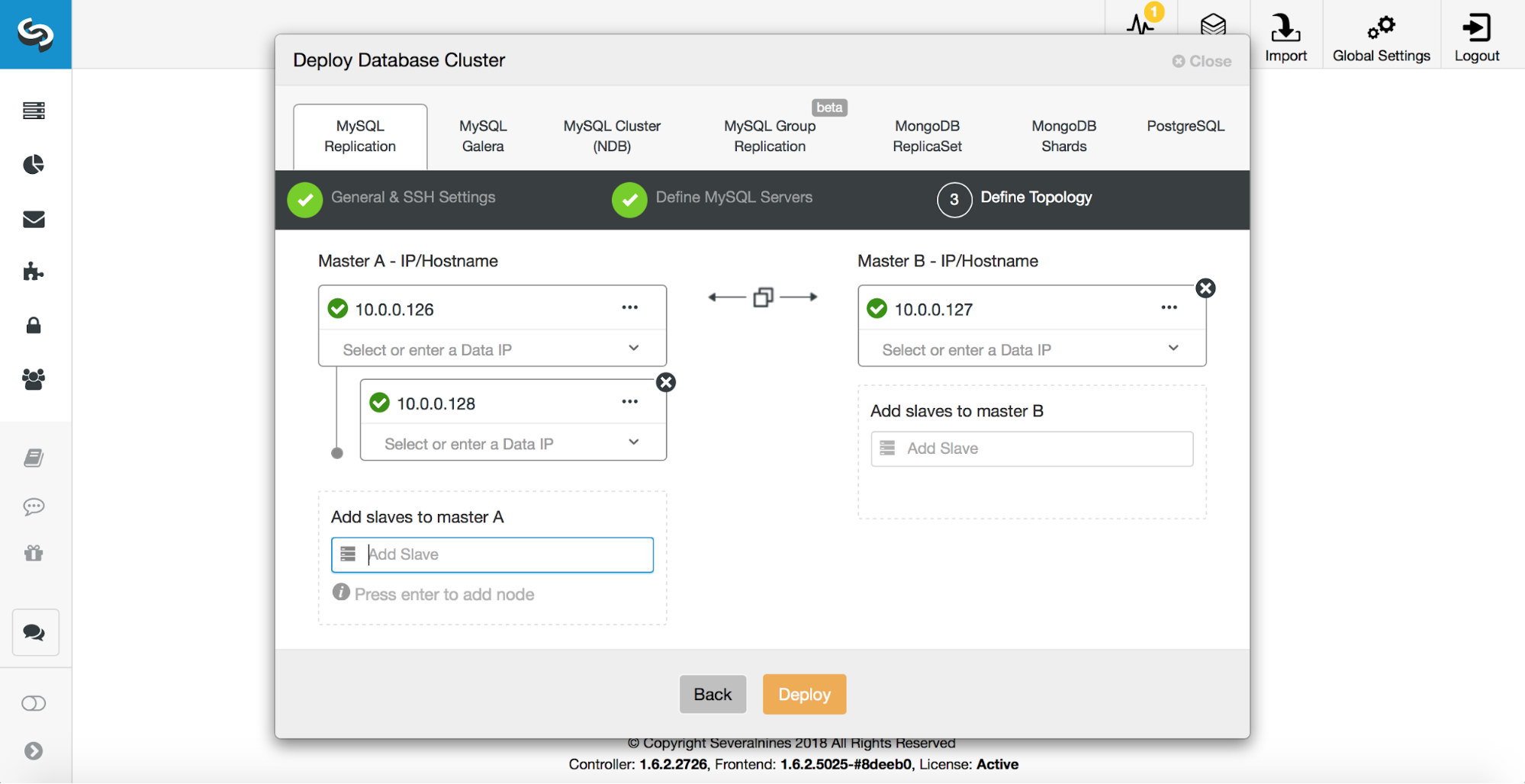
Finally, it’s time to decide upon the topology and key in the hosts. One can deploy simple master – slave setups, or more complex active-standby master-master deployments. Each master may have its own slaves. ClusterControl deploys MySQL replication setups using semi-synchronous replication. This is not a perfect solution which would guarantee that the replicas (or slaves) would be up to date in case of a master failure. Semi-sync replicas can also lag and may not be fully caught up with their master. What semi-sync replication guarantees is that at least one of those replicas will contain all the data from the master stored in its relay logs. It may take a moment to process those logs, should the replica be lagging, but the data is there.
Deploying a master-slave setup is just the first step in building a production-ready infrastructure. Next, we will use a proxy to make the underlying database layer as transparent to the application as possible. Below, we can see how to deploy ProxySQL and Keepalived.
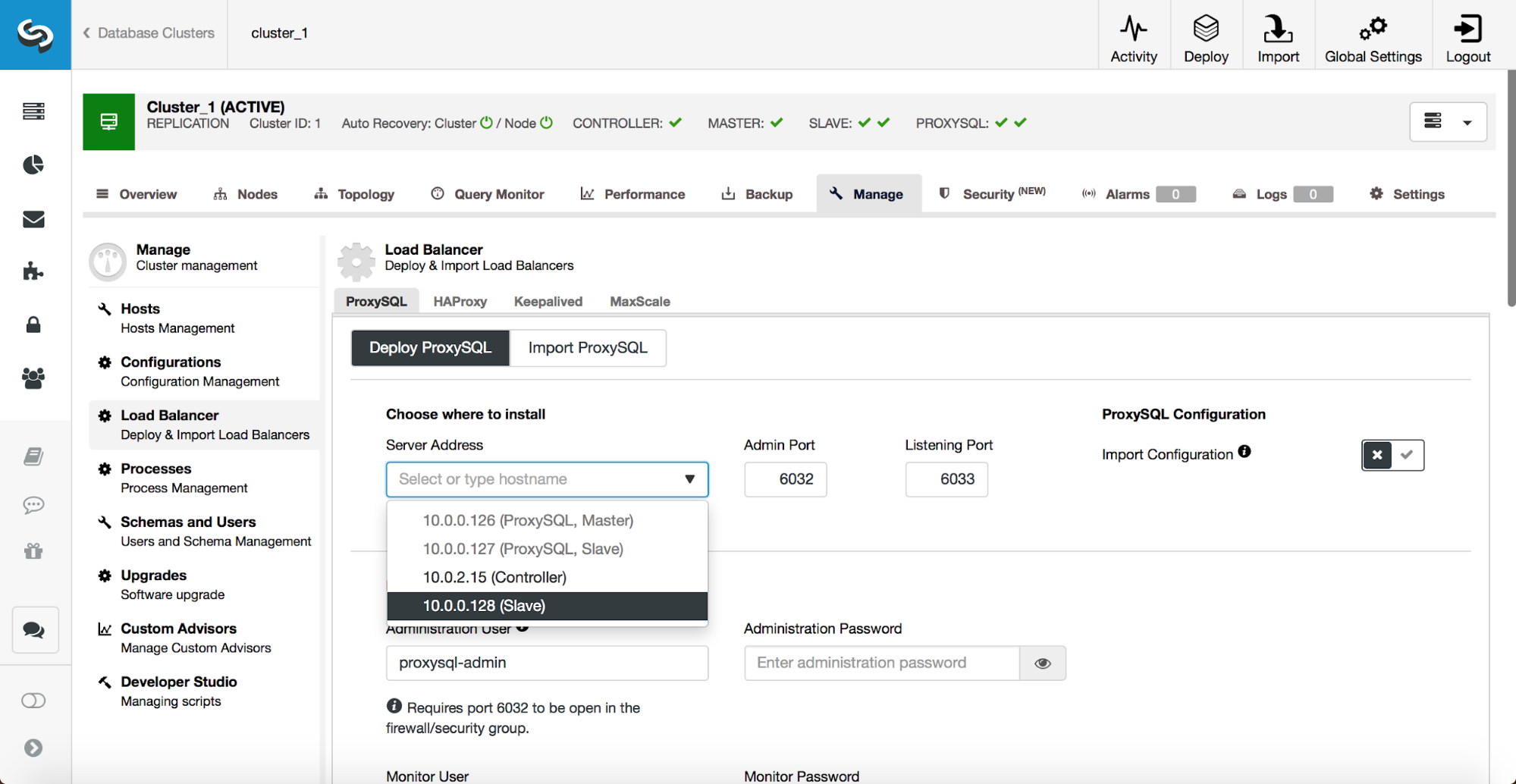
Pick where ProxySQL should be deployed – either colocated with one of the database hosts or some other host. Or if you already have ProxySQL deployed, you can also import its configuration. If not, you need to fill the rest of the details.
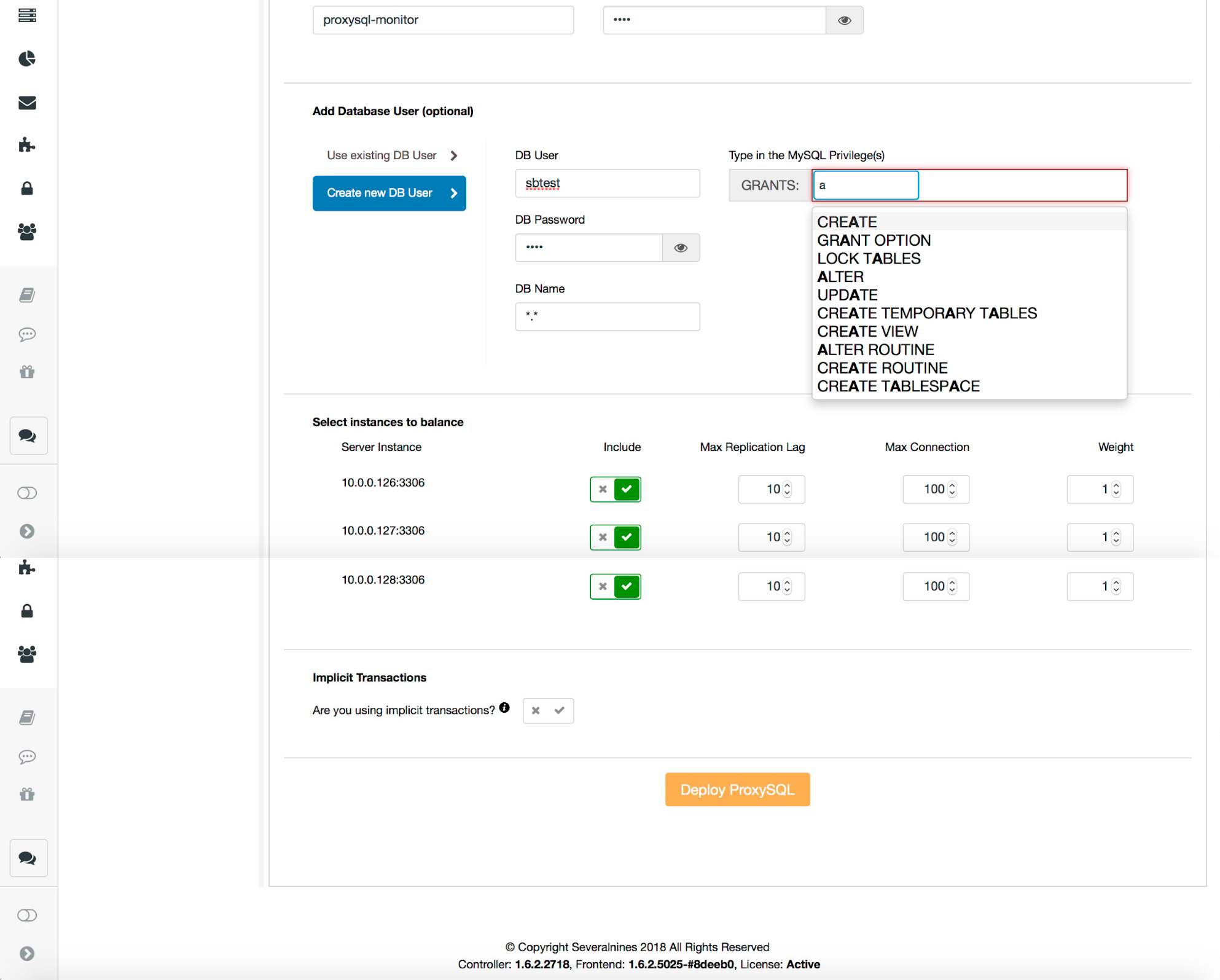
Key in a password for administrative user for CLI as well as a password for the monitoring user that ProxySQL will use to connect to the databases and perform monitoring. ProxySQL has to know the access details for MySQL users which will connect through ProxySQL. This is required as authentication is done against ProxySQL instead of the backend. ProxySQL then opens the backend connection. If you have users already created in MySQL, you can import them to ProxySQL. If not, you can easily create new users on both ProxySQL and MySQL backend. Finally, you may want to change some of the settings like maximum replication lag before a slave is removed from the pool of active servers, maximum number of connections to a given backend or weight. You should also tell whether you use implicit transactions created by “SET autocommit=0” or not. This affects how ProxySQL will be configured. If you use implicit transactions, to maintain transactional behavior only one node will be accessible in ProxySQL – there will be no read scaling, just high availability. If you do not use implicit transactions, ProxySQL will be configured for read/write split and read scaling.
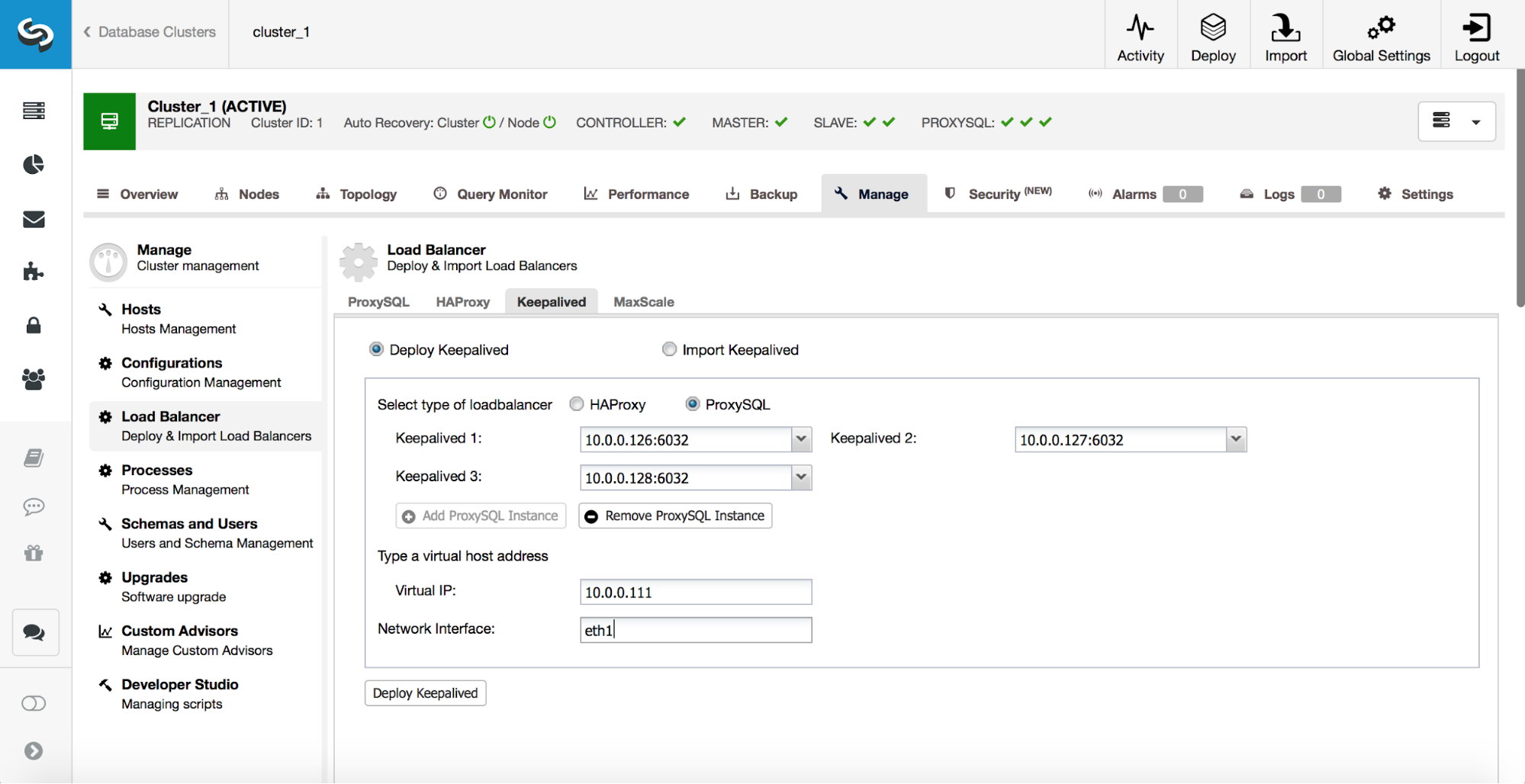
Once ProxySQL instances are deployed, it’s time to deploy Keepalived. This is to ensure that ProxySQL does not become a single point of failure. Pick up to three ProxySQL instances, define the VIP and on which network interface it should be created. This is all you need to do. As soon as Keepalived services are ready, the application can use the VIP to connect to one of ProxySQL instances. Should that ProxySQL go down, Keepalived will move the VIP to another ProxySQL instance.
That’s it for now



