blog
Database Load Balancing: Distributed vs Centralized Setups

A database load balancer, or database reverse proxy, distributes the incoming database workload across multiple database servers running behind it. The goals of having database load balancers are to provide a single database endpoint to applications to connect to, increase queries throughput, minimize latency, and maximize resource utilization of the database servers.
There can be two ways of database load balancer topology:
- Centralized topology
- Distributed topology
In this blog post, we are going to cover both topologies and understand some pros and cons of each setup. Also, would it be possible to mix both topologies together?
Centralized Topology
In a centralized setup, a reverse proxy is located in between the data and presentation tier, as represented by the following diagram:
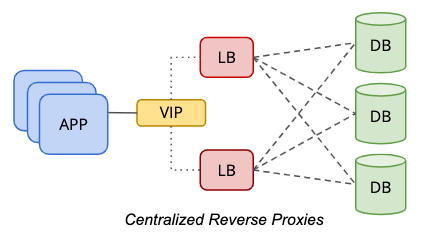
To eliminate a single-point-of-failure, one has to set up two or more load balancer nodes for redundancy purposes. If your application can handle multiple database endpoints, for example, the application or database driver is capable of performing health checks if the load balancer is healthy for query processing, you probably can skip the virtual IP address part. Otherwise, both load balancer nodes should be tied together with a common hostname or virtual IP address, to provide transparency to the database clients where it just needs to use a single database endpoint to access the data tier. Using DNS or host mapping is also possible if you want to skip using virtual IP addresses.
This tier-based approach is far simpler to manage because of its independent static host placement. It’s very unlikely for the load balancer tier to be scaled out (adding more nodes) because of its solid foundation in resiliency, redundancy and transparency to the application tier. You probably need to scale the host up (adding more resources to the host), which commonly will happen long away in the future, after the load balancer workloads have become more demanding as your business grows.
This topology requires an additional tier and hosts, which might be costly in a bare-metal infrastructure with physical servers. This setup is easier to manage in a cloud or virtual environment, where you have the flexibility to add an additional tier between the application and database tier, without costing you too much on the physical infrastructure cost like electricity, rack space and networking costs.
Distributed Topology
In a distributed topology setup, the load balancers are co-located within the presentation tier (application or web servers), as simplified by the following diagram:
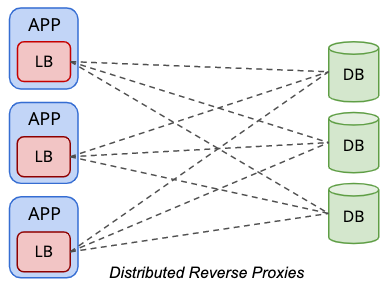
Applications treat the database load balancer similarly to a local database server, where the load balancer becomes the representation of the remote databases from the perspective of the application. Commonly, the load balancer will be listening to the local network interface like 127.0.0.1 or “localhost” which will streamline the database endpoint database host for the applications.
One of the advantages of running in this topology is that you don’t need extra hosts for load balancing purposes. By combining the load balancer tier within the presentation tier, we could save at least two hosts. In a bare-metal environment, this topology could potentially save you a lot of money throughout the years. Generally, load balancer workload is far less demanding if compared to database or application workloads, which makes it justifiable to share the same hardware resources with the applications.
When co-located with the application server, you bring the reverse proxy closer to the application and eliminate the single-point-of-failure. This can significantly improve the application performance when you have a geographical separation between the application and the data tier, especially for database load balancers that support resultset caching like ProxySQL and MaxScale. On the other hand, the number of database load balancers is commonly equal to the number of application nodes, which means if the application tier is scaled up, the number of database load balancers will be increasing which might potentially degrade the performance for the database health check service. Note that the load balancer health checks are a bit chattier because of its responsibility to keep up with the correct state of the database nodes.
With the help of IT infrastructure automation tools like Chef, Puppet and Ansible together with the container orchestration tools, it is no longer an impossible task to automate the deployment and management of multiple load balancer instances for this topology. However, there will be another learning curve for the operation team to come up with a battle-tested, production-grade deployment and management policies to reduce the excessive work when handling many load balancer nodes. Don’t miss out on all the important management aspects for database load balancer like backup/restore, upgrade/downgrade, configuration management, service control, fault management and so on.
Distributed topology can be mixed together with the centralized topology for some supported database load balancers like ProxySQL, as illustrated in the following diagram:
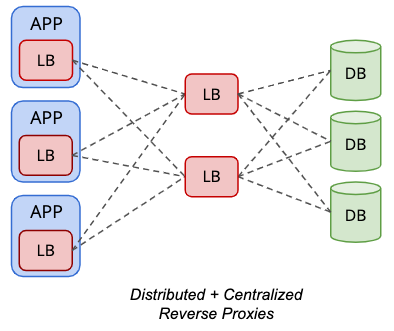
The backend “servers” of a ProxySQL instance can be another set of ProxySQL nodes instead. With this configuration, a virtual IP address is not necessary for single endpoint access to the database nodes, since the local ProxySQL instance hosted locally on the application server will be the single endpoint access from the application standpoint.
However, this requires two versions of load balancer configurations – one that resides on the application tier, and another one resides on the load balancer tiers. It also requires more hosts, excluding the need to learn about virtual IP address technology, IP failover and so on. The advantages and disadvantages of both distributed and centralized setups are fusion together in this topology.
Conclusion
Each topology has its own advantages and disadvantages and must be well-planned from the beginning. This early decision is critical and can hugely influence your application performance, scalability, reliability and availability in the long run.



