blog
Database Backup Encryption – Best Practices

Offsite backup storage should be a critical part of any organisation’s disaster recovery plan. The ability to store data in a separate physical location, where it could survive a catastrophic event which destroys all the data in your primary data center, ensures your data survival and continuity of your organisation. A Cloud storage service is quite a good method to store offsite backups. No matter if you are using a cloud provider or if you are just copying data to an external data center, the backup encryption is a must in such cases. In one of our previous blogs, we discussed several methods of encrypting your backups. Today we will focus on some best practices around backup encryption.
Ensure that Your Secrets are Safe
To encrypt and decrypt your data you have to use some sort of a password or a key. Depending on the encryption method (symmetrical or asymmetrical), it can be one secret for both encryption and decryption or it can be a public key for encryption and a private key for decryption. What is important, you should keep those safe. If you happen to use asymmetric encryption, you should focus on the private key, the one you will use for decrypting backups.
You can store keys in a key management system or a vault – there are numerous options on the market to pick from like Amazon’s KMS or Hashicorp’s Vault. Even if you decide not to use those solutions, you still should apply generic security practices like to ensure that only the correct users can access your keys and passwords. You should also consider preparing your backup scripts in a way that you will not expose keys or passwords in the list of running processes. Ideally, put them in the file instead of passing them as an argument to some commands.
Consider Asymmetric Encryption
The main difference between symmetric and asymmetric encryption is that while using symmetric encryption for both encryption and decryption, you use a single key or password. This requires higher security standards on both ends of the process. You have to make sure that the host on which you encrypt the data is very secure as a leak of the symmetric encryption key will allow the access to all of your encrypted backups.
On the other hand, if you use asymmetric encryption, you have two keys: the public key for encrypting the data and the private key for decryption. This makes things so much easier – you don’t really have to care about the public key. Even if it would be compromised, it will still not allow for any kind of access to the data from backups. You have to focus on the security of the private key only. It is easier – you are most likely encrypting backups on a daily basis (if not more frequent) while restore happens from time to time, making it feasible to store the private key in more secure location (even on a dedicated physical device). Below is a very quick example on how you can use gpg to generate a key pair and use it to encrypt data.
First, you have to generate the keys:
root@vagrant:~# gpg --gen-key
gpg (GnuPG) 1.4.20; Copyright (C) 2015 Free Software Foundation, Inc.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
gpg: directory `/root/.gnupg' created
gpg: new configuration file `/root/.gnupg/gpg.conf' created
gpg: WARNING: options in `/root/.gnupg/gpg.conf' are not yet active during this run
gpg: keyring `/root/.gnupg/secring.gpg' created
gpg: keyring `/root/.gnupg/pubring.gpg' created
Please select what kind of key you want:
(1) RSA and RSA (default)
(2) DSA and Elgamal
(3) DSA (sign only)
(4) RSA (sign only)
Your selection?
RSA keys may be between 1024 and 4096 bits long.
What keysize do you want? (2048) 4096
Requested keysize is 4096 bits
Please specify how long the key should be valid.
0 = key does not expire
= key expires in n days
w = key expires in n weeks
m = key expires in n months
y = key expires in n years
Key is valid for? (0)
Key does not expire at all
Is this correct? (y/N) y
You need a user ID to identify your key; the software constructs the user ID
from the Real Name, Comment and Email Address in this form:
"Heinrich Heine (Der Dichter) "
Real name: Krzysztof Ksiazek
Email address: [email protected]
Comment: Backup key
You selected this USER-ID:
"Krzysztof Ksiazek (Backup key) "
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? o
You need a Passphrase to protect your secret key. This created both public and private keys. Next, you want to export your public key to use for encrypting the data:
gpg --armor --export [email protected] > mybackupkey.ascNext, you can use it to encrypt your backup.
root@vagrant:~# xtrabackup --backup --stream=xbstream | gzip | gpg -e --armor -r [email protected] -o /backup/pgp_encrypted.backupFinally, an example how you can use your primary key (in this case it’s stored in the local key ring) to decrypt your backups:
root@vagrant:/backup# gpg -d /backup/pgp_encrypted.backup | gunzip | xbstream -x
encryption: using gcrypt 1.6.5
You need a passphrase to unlock the secret key for
user: "Krzysztof Ksiazek (Backup key) "
4096-bit RSA key, ID E047CD69, created 2018-11-19 (main key ID BC341551)
gpg: gpg-agent is not available in this session
gpg: encrypted with 4096-bit RSA key, ID E047CD69, created 2018-11-19
"Krzysztof Ksiazek (Backup key) " Rotate Your Encryption keys
No matter what kind of encryption you implemented, symmetric or asymmetric, you have to think about the key rotation. First of all, it is very important to have a mechanism in place to rotate the keys. This might be useful in case of a security breach, and you would have to quickly change keys that you use for backup encryption and decryption. Of course, in case of a security breach, you need to consider what is going to happen with the old backups which were encrypted using compromised keys. They have been compromised although they still may be useful and required as per Recovery Point Objective. There are couple of options including re-encrypting them or moving them to a non-compromised localization.
Speed up the Encryption Process by Parallelizing it
If you have an option to implement parallelization of the encryption process, consider it. Encryption performance mostly depends on the CPU power, thus allowing more CPU cores to work in parallel to encrypt the file should result in much smaller encryption times. Some of the encryption tools give such option. One of them is xtrabackup which has an option to use embedded encryption and parallelize the process.
What you are looking for is either “–encrypt-key” or “–encrypt-key-file” options which enable embedded encryption. While doing that you can also define “–encrypt-threads” and “–encrypt-chunk-size”. Second increases a working buffer for encryption, first defines how many threads should be used for encryption.
Of course, this is just one of the solutions you can implement. You can achieve this using shell tools. An example below:
root@vagrant:~# files=2 ; mariabackup --user=root --backup --pass=pass --stream=xbstream |split -b 60M - backup ; ls backup* | parallel -j ${files} --workdir "$(pwd)" 'echo "encrypting {}" ; openssl enc -aes-256-cbc -salt -in "{}" -k mypass > "111{}"'This is by no means a perfect solution as you have to know in advance how big, more or less, the backup will be to split it to predefined number of files matching the parallelization level you want to achieve (if you want to use 2 CPU cores, you should have two files, if you want to use 4 cores, 4 files etc). It also requires disk space that is twice the size of the backup, as at first it generates multiple files using split and then encryption creates another set of encrypted files. On the other hand, if your data set size is acceptable and you would like to improve encryption performance, that’s an option you can consider. To decrypt the backup you will have to decrypt each of the individual files and then use ‘cat’ to join them together.
Test Your Backups
No matter how you are going to implement the backup encryption, you have to test it. First of all, all backups have to be tested, encrypted or not. Backups may not be complete, or may suffer from some type of corruption. You cannot be sure that your backup can be restored until you actually perform the restore. That’s why regular backup verification is a must. Encryption adds more complexity to the backup process. Issues may show up at the encryption time, again – bugs or glitches may corrupt the encrypted files. Once encrypted, the question is then if it is possible to decrypt it and restore?
You should have a restore test process in place. Ideally, the restore test would be executed after each backup. As a minimum, you should test your backups a couple of times per year. Definitely you have to test it as soon as a change in the backup process had been introduced. Have you added compression to the backup? Did you change the encryption method? Did you rotate the encryption key? All of those actions may have some impact on your ability to actually restore your backup. Therefore you should make sure you test the whole process after every change.
ClusterControl can automate the verification process, both on demand or scheduled after every backup.
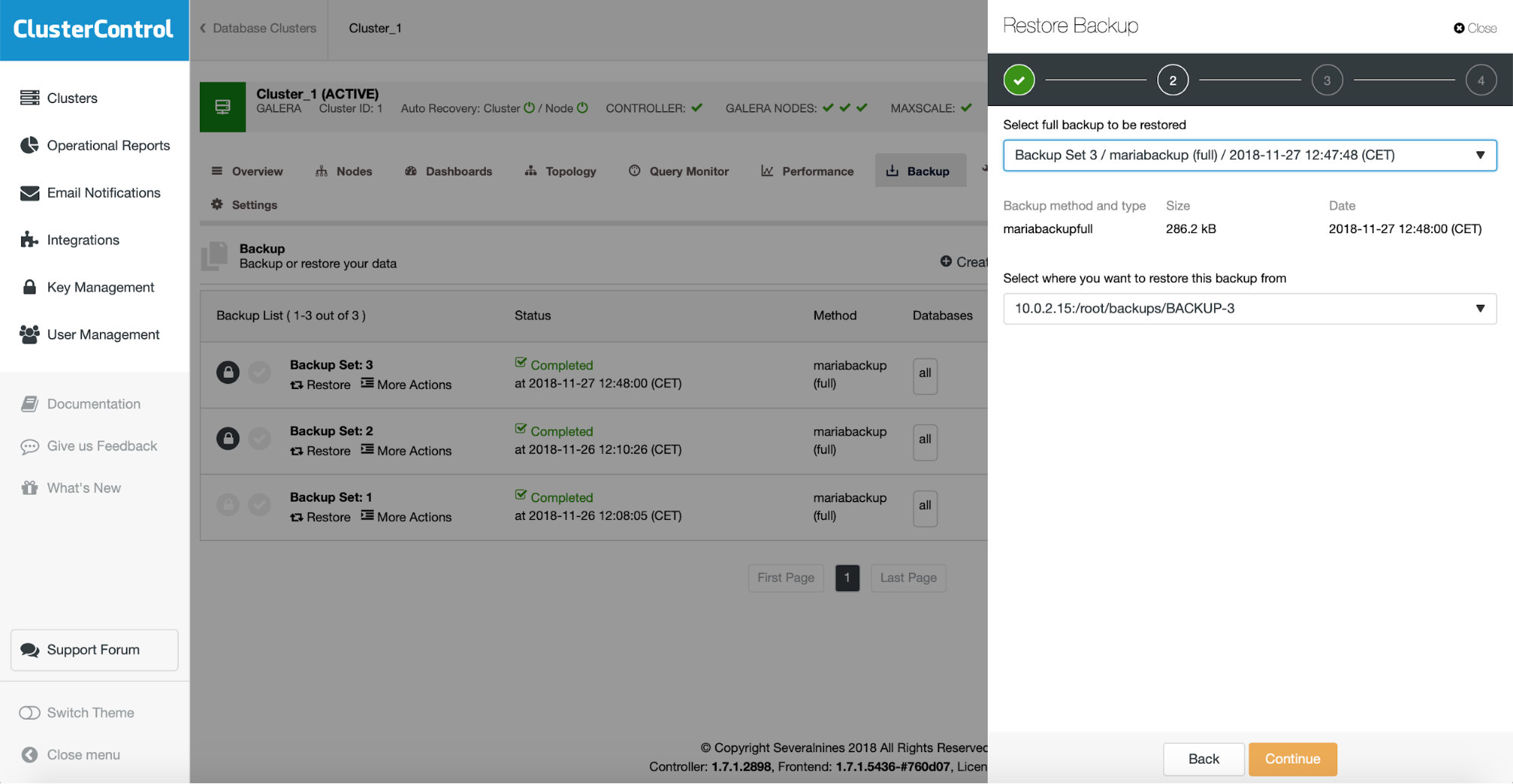
To verify an existing backup, you just need to pick the one from the list, click on “Restore” option and then go through the restore wizard. First, you need to verify which backup you want to restore.
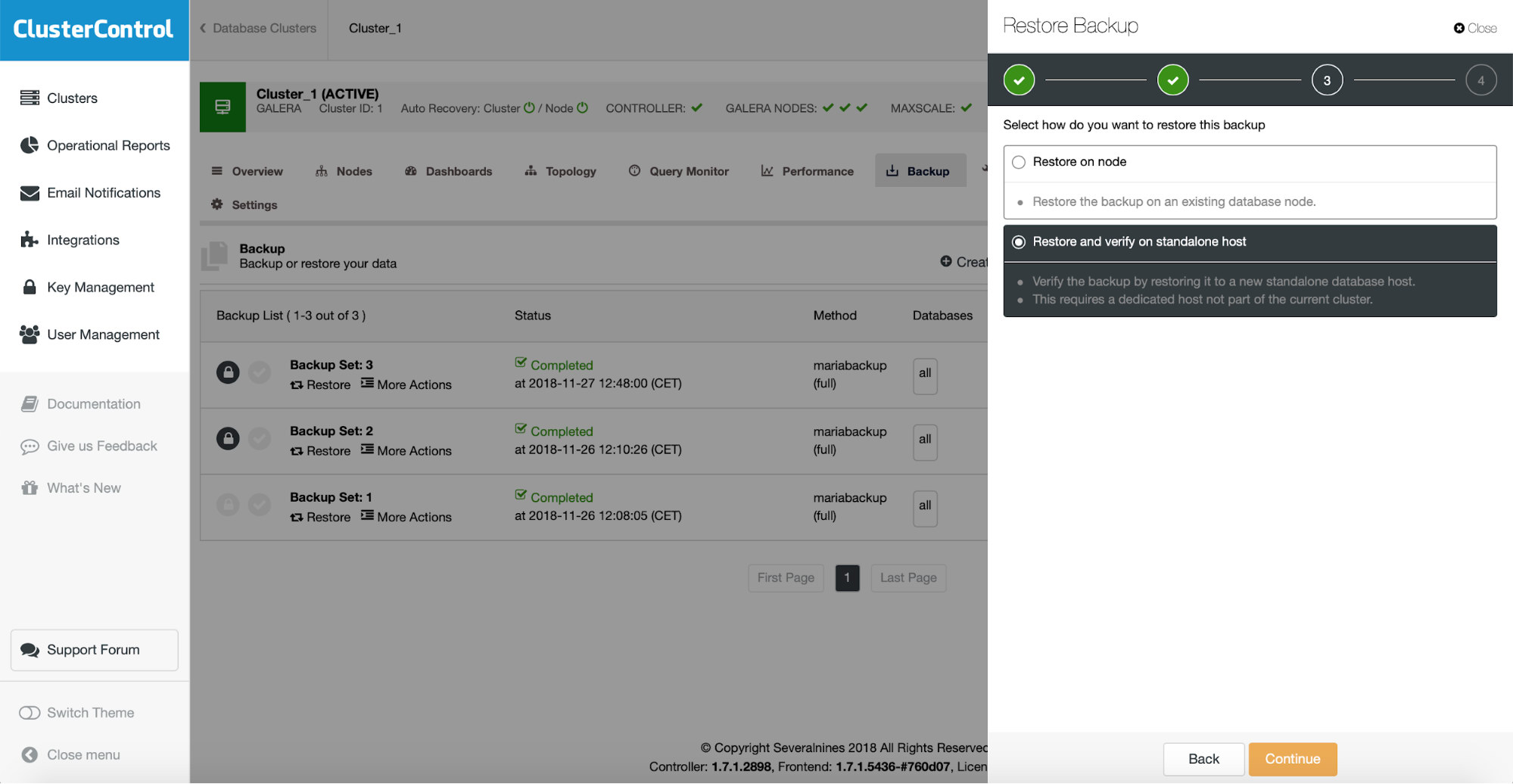
Then, on the next step, you should pick the restore and verify option.
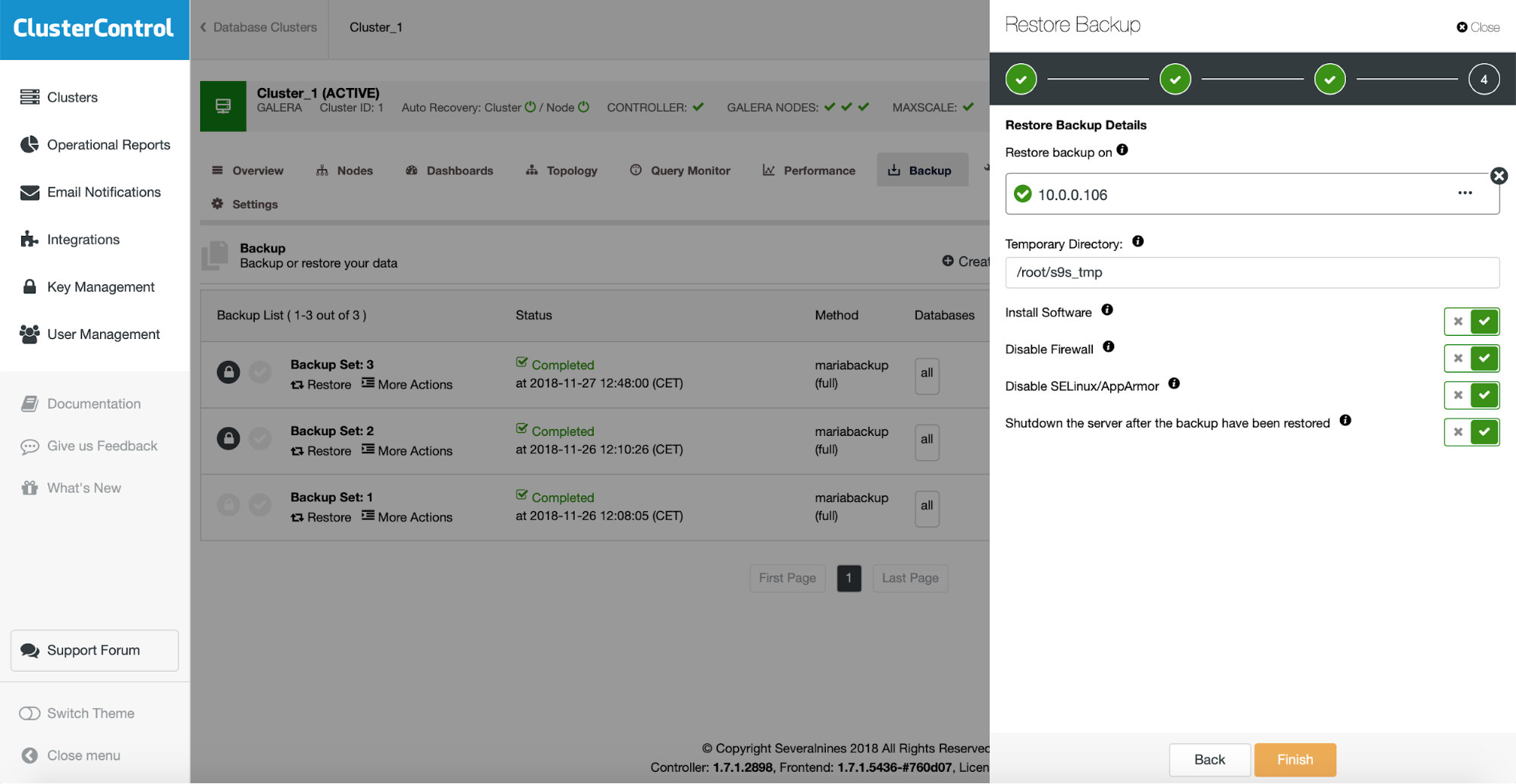
You need to pass some information about the host on which you want to test the restore. It has to be accessible via SSH from the ClusterControl instance. You may decide to keep the restore test server up and running (and then dump some partial data from it if you wanted to go for a partial restore) or shut it down.
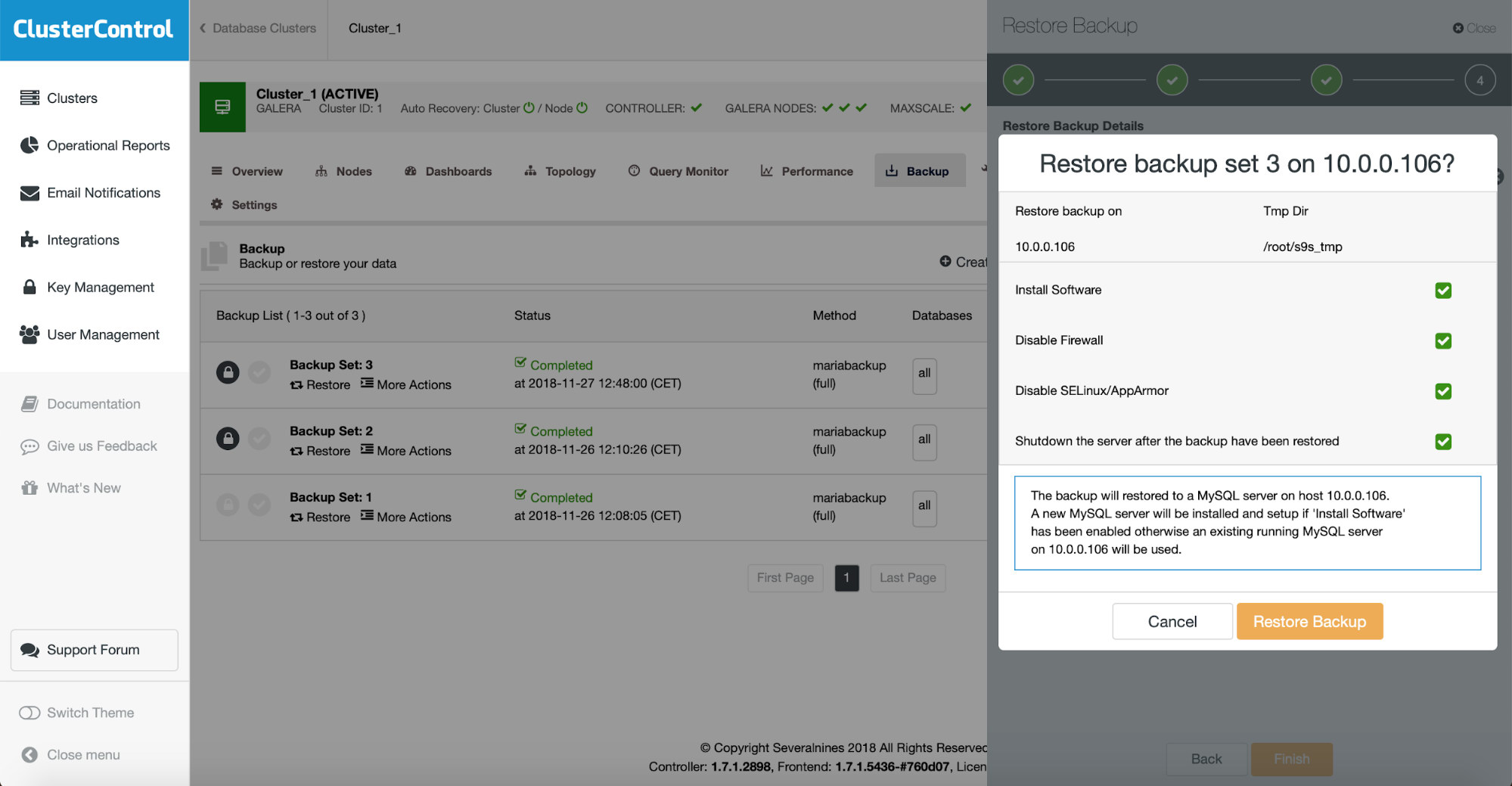
The final step is all about verifying if you made the correct choices. If yes, you can start the backup verification job.
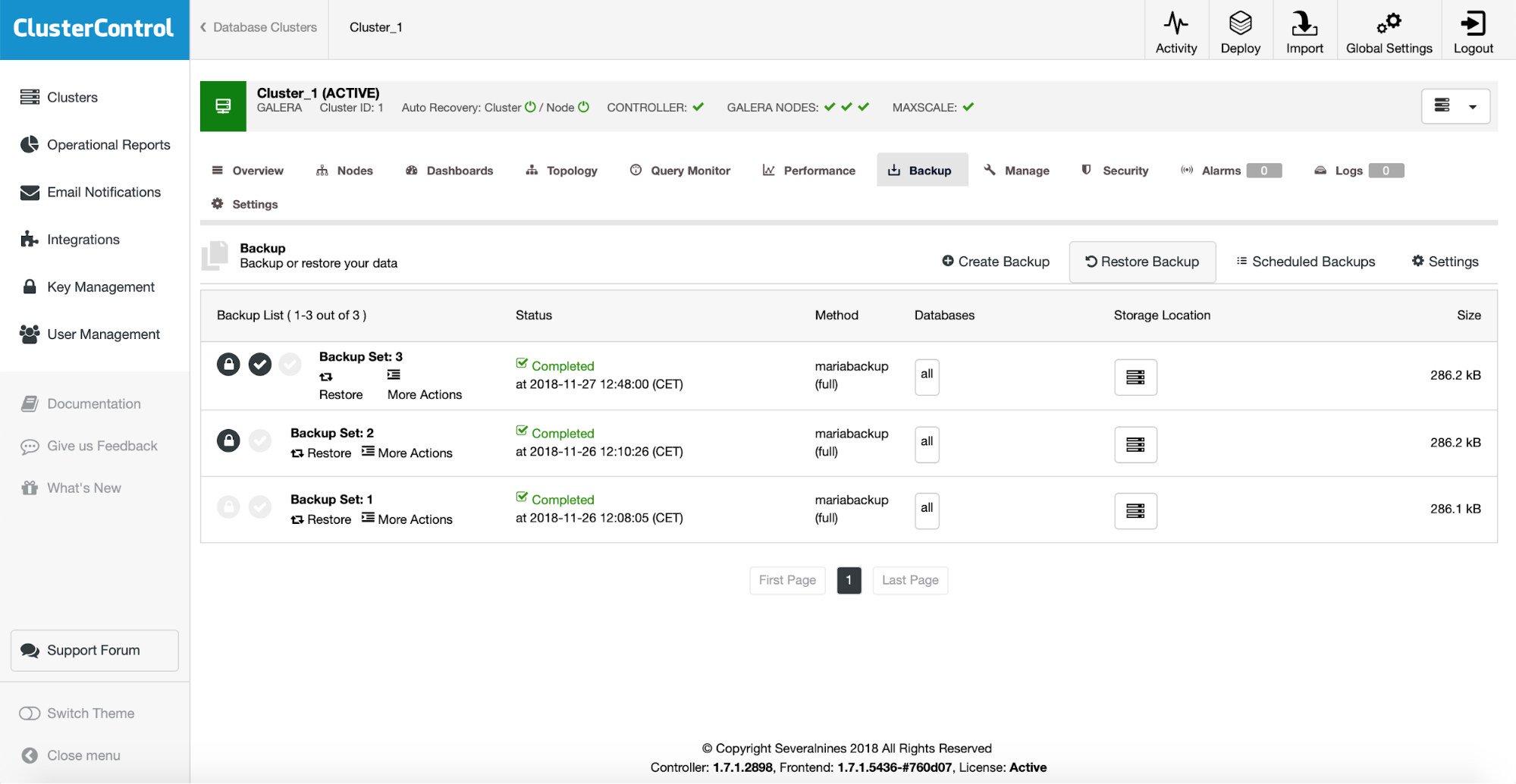
If the verification completed successfully, you will see that the backup is marked as verified on the list of the backups.
If you want to automate this process, it is also possible with ClusterControl. When scheduling the backup you can enable backup verification:
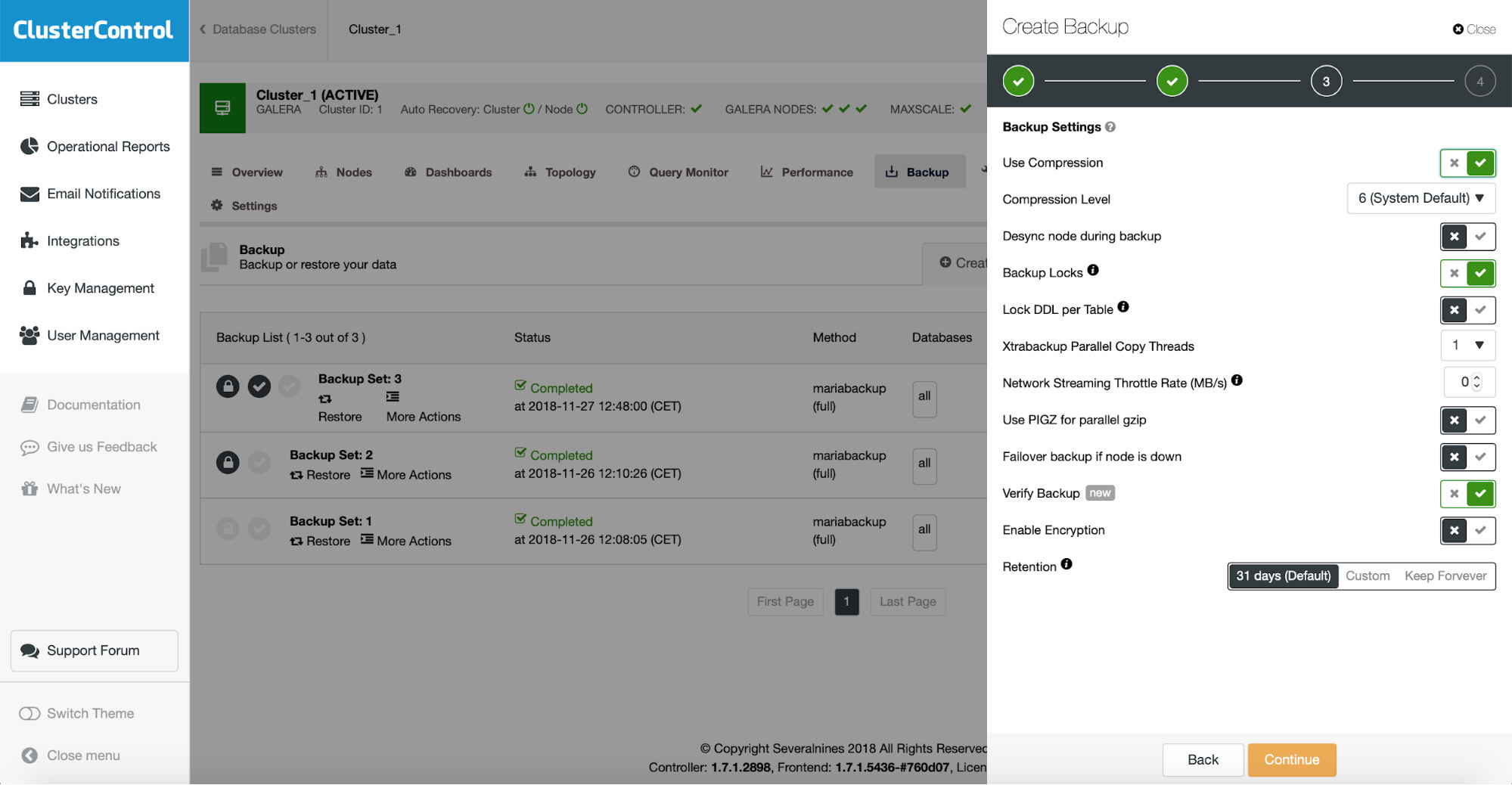
This adds another step in the backup scheduling wizard.
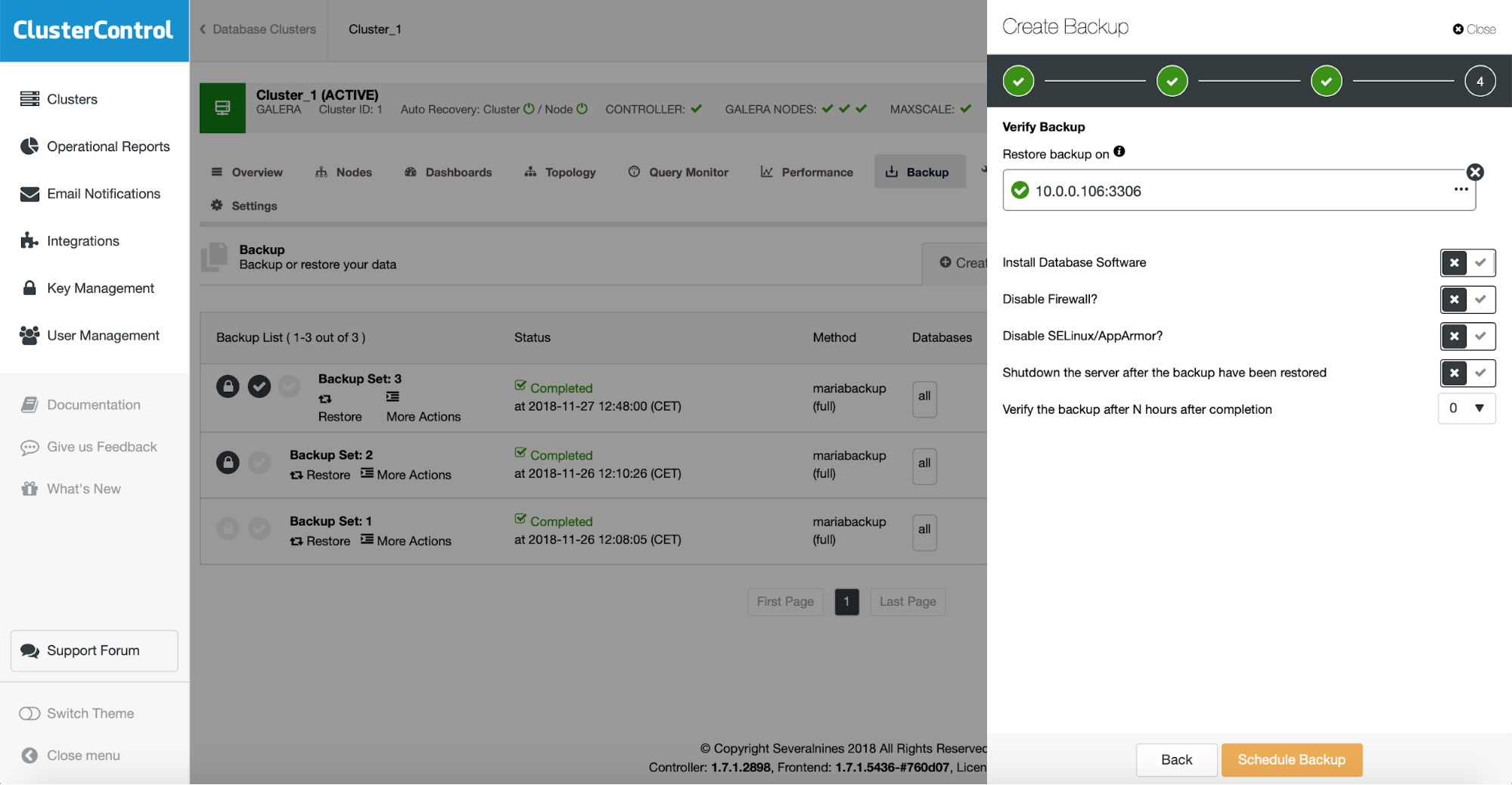
Here you again have to define the host which you want to use for backup restore tests, decide if you want to install the software on it (or maybe you already have it done), if you want to keep the restore server up and whether you want to test the backup immediately after it is completed or maybe you want to wait a bit.



