blog
Connection Management in PostgreSQL: A Guide

Performance is always important in any system. You will need to make good use of the available resources to ensure the best response time possible and there are different ways to do this. Every connection to a database consumes resources so one of these ways is to have a good connection manager between your application and the database. In this blog, we will talk about pgBouncer, a connection pooler for PostgreSQL, and we will show how to implement this to improve your PostgreSQL performance.
Connection Poolers
Depending on the traffic of your systems, it could be useful to add an external tool to reduce the load on your database which will improve performance. Maybe it is not enough, but it is a good starting point. For this, it is a good idea to implement a connection pooler
A connection pooling is a method of creating a pool of connections and reuse them, avoiding opening new connections to the database all the time, which will increase the performance of your applications considerably. PgBouncer is a popular connection pooler designed for PostgreSQL.
How PgBouncer Works
PgBouncer acts as a PostgreSQL server, so you just need to access your database using the PgBouncer information (IP Address/Hostname and Port), and PgBouncer will create a connection to the PostgreSQL server, or it will reuse one if it exists.
When PgBouncer receives a connection, it performs the authentication, which depends on the method specified in the configuration file. PgBouncer supports all the authentication mechanisms that the PostgreSQL server supports. After this, PgBouncer checks for a cached connection, with the same username+database combination. If a cached connection is found, it returns the connection to the client, if not, it creates a new connection. Depending on the PgBouncer configuration and the number of active connections, it could be possible that the new connection is queued until it can be created, or even aborted.
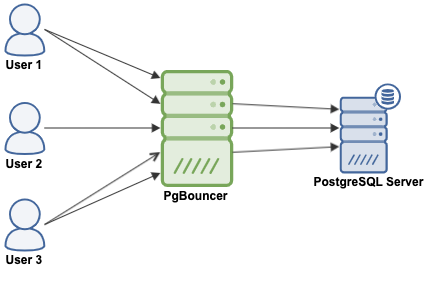
The PgBouncer behavior depends on the pooling mode configured:
-
session pooling (default): When a client connects, a server connection will be assigned to it for the whole duration the client stays connected. When the client disconnects, the server connection will be put back into the pool.
-
transaction pooling: A server connection is assigned to a client only during a transaction. When PgBouncer notices that the transaction is over, the server connection will be put back into the pool.
-
statement pooling: The server connection will be put back into the pool immediately after a query completes. Multi-statement transactions are disallowed in this mode as they would break.
How to Implement PgBouncer Using ClusterControl
For this, we will assume you have your PostgreSQL cluster up and running and you are using ClusterControl to manage it, otherwise, you can follow this blog post to easily deploy PostgreSQL for High Availability.
Go to ClusterControl -> Select PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer -> PgBouncer. There you can deploy a new PgBouncer node that will be deployed in the selected database node, or even import an existing PgBouncer node.
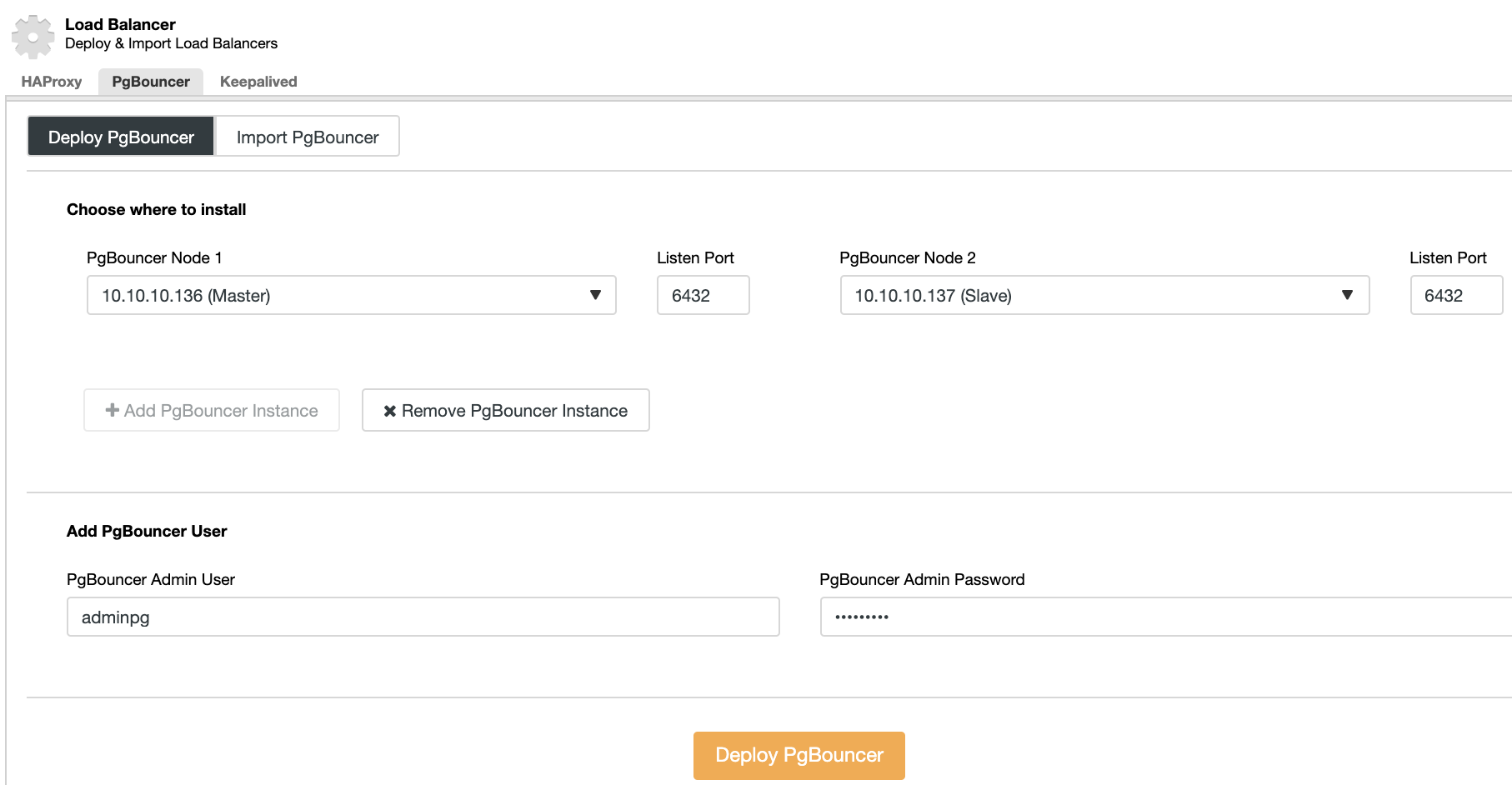
You will need to specify IP Address or Hostname, Listen Port, and PgBouncer credentials. When you press on Deploy PgBouncer, ClusterControl will access the node, install, and configure everything without any manual intervention.
You can monitor the progress in the ClusterControl Activity Section. When it finishes, you need to create the new Pool. For this, go to ClusterControl -> Select the PostgreSQL cluster -> Nodes -> PgBouncer Node.
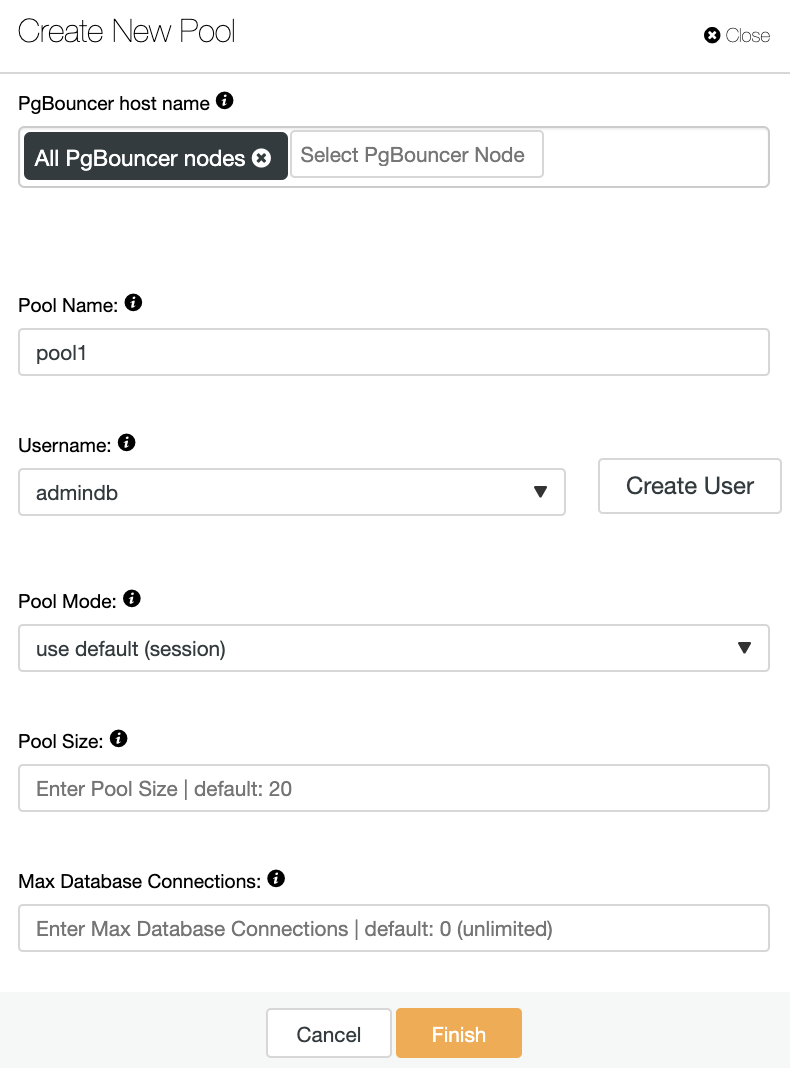
Here you will need to add the following information:
-
PgBouncer hostname: Select the node hosts to create the connection pool.
-
Pool Name: Pool and database names must be the same.
-
Username: Select a user from the PostgreSQL primary node or create a new one.
-
Pool Mode: It can be one of the modes that we mentioned earlier: session (default), transaction, or statement pooling.
-
Pool Size: Maximum size of pools for this database. The default value is 20.
-
Max Database Connections: Configure a database-wide maximum. The default value is 0, which means unlimited.
Now, you should be able to see the Pool in the Node section.
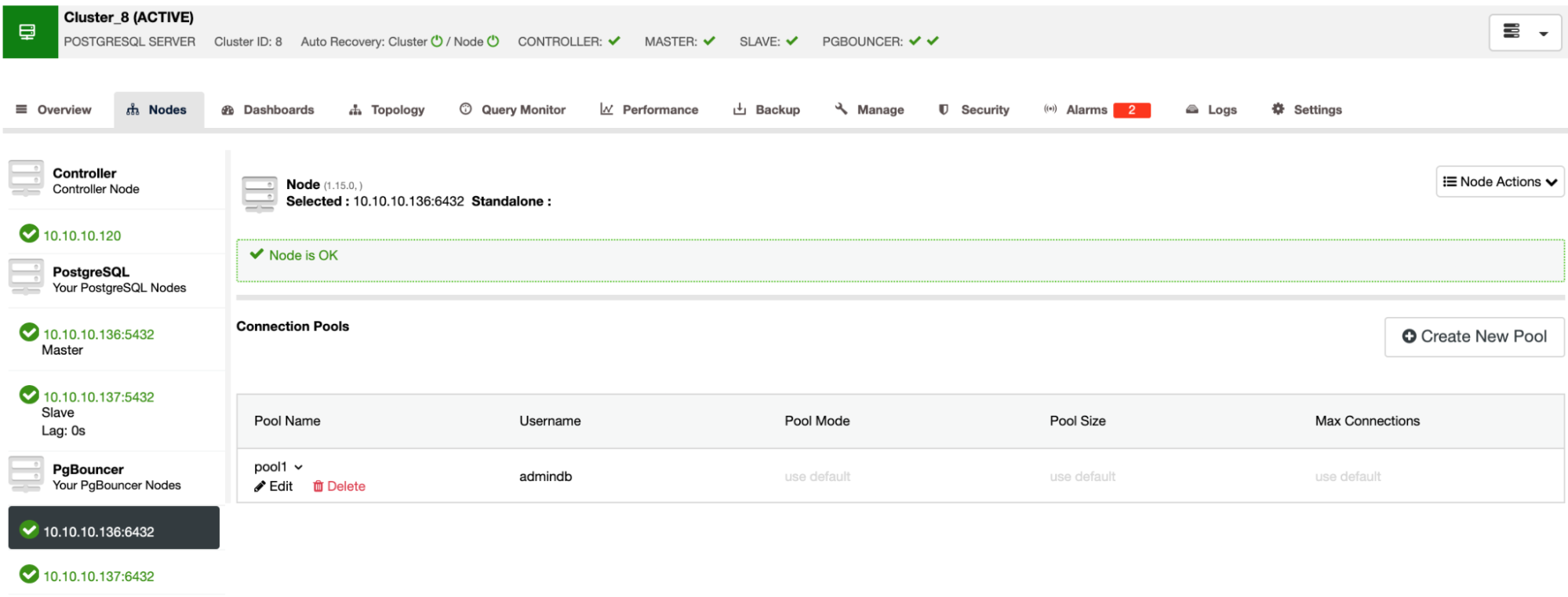
This is a basic topology. You can improve it, for example, adding load balancer nodes, more than one to avoid a single point of failure, and using some tool like “Keepalived”, to ensure the availability. It can also be done using ClusterControl.
Conclusion
Using PgBouncer as a connection pooler is a good way to improve database performance making good usage of the available resources in the server.
You can also improve this topology by using a combination of PgBouncer + HAProxy to achieve High Availability for your PostgreSQL cluster. All these things can be done from the same ClusterControl UI.



