blog
CMON High Availability and Failover

High availability is a must these days and ClusterControl performs a key role in ensuring that your database clusters will stay up and running. On the other hand, how can we ensure that ClusterControl itself will be highly available and be able to manage the database nodes? ClusterControl may be deployed in a couple of different ways, one of them is to form a cluster of ClusterControl nodes and then ensure that there is always a node that will be able to deal with the cluster management.
We have two blog posts in which we have explained how to setup Cmon HA, using Galera Cluster as a backend database across the ClusterControl nodes and how to configure HAProxy as a loadbalancer to point to an active ClusterControl node. In this blog post we would like to focus on how the ClusterControl cluster behaves in a situation where one of the nodes becomes unavailable. Let’s go through some scenarios that may happen.
Initial situation
First, let’s take a look at how the initial situation looks like. We have a ClusterControl cluster that consists of three nodes:
root@node2:~# s9s controller --list --long
S VERSION OWNER GROUP NAME IP PORT COMMENT
f 1.8.2.4596 system admins 10.0.0.181 10.0.0.181 9501 Accepting heartbeats.
f 1.8.2.4596 system admins 10.0.0.182 10.0.0.182 9501 Accepting heartbeats.
l 1.8.2.4596 system admins 10.0.0.183 10.0.0.183 9501 Acting as leader.
Total: 3 controller(s)As you can see, 10.0.0.183 is the leader node and it is also the node where HAProxy will redirect all requests:
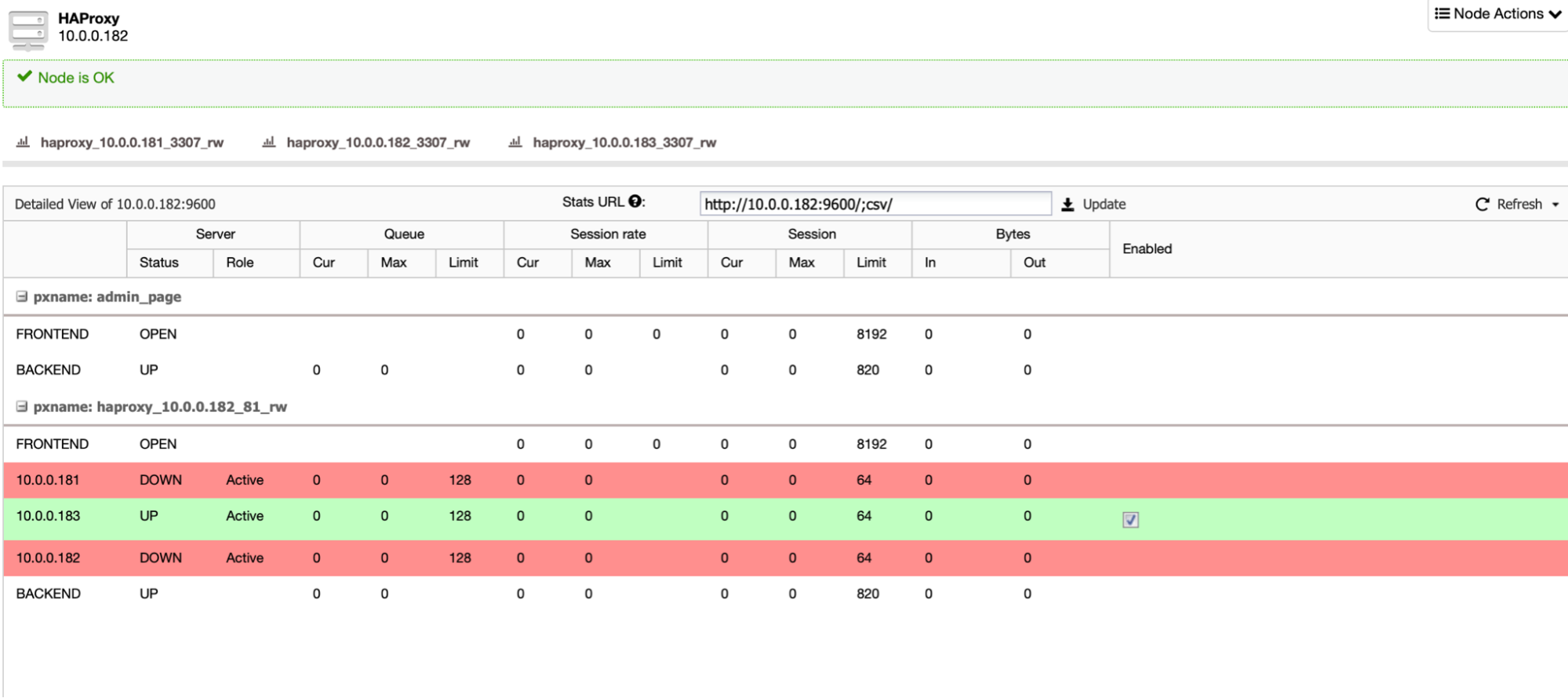
This is the starting point, let’s see where we’ll head up.
ClusterControl is down
If for some reason the CMON process becomes unavailable, we need to investigate a couple of different scenarios including a possible bug, an OOM killer or some script that unexpectedly stopped the CMON service. First of all, what we’ll see is the fact that node is reported as not working:
root@node2:~# s9s controller --list --long
S VERSION OWNER GROUP NAME IP PORT COMMENT
f 1.8.2.4596 system admins 10.0.0.181 10.0.0.181 9501 Accepting heartbeats.
l 1.8.2.4596 system admins 10.0.0.182 10.0.0.182 9501 Acting as leader.
- 1.8.2.4596 system admins 10.0.0.183 10.0.0.183 9501 Not accepting heartbeats.
Total: 3 controller(s)To make things harder, we killed our leader node. As you can see, a new leader has been promoted and the failed node is marked as “Not accepting heartbeats”.
Of course, HAProxy picks up the leader change:
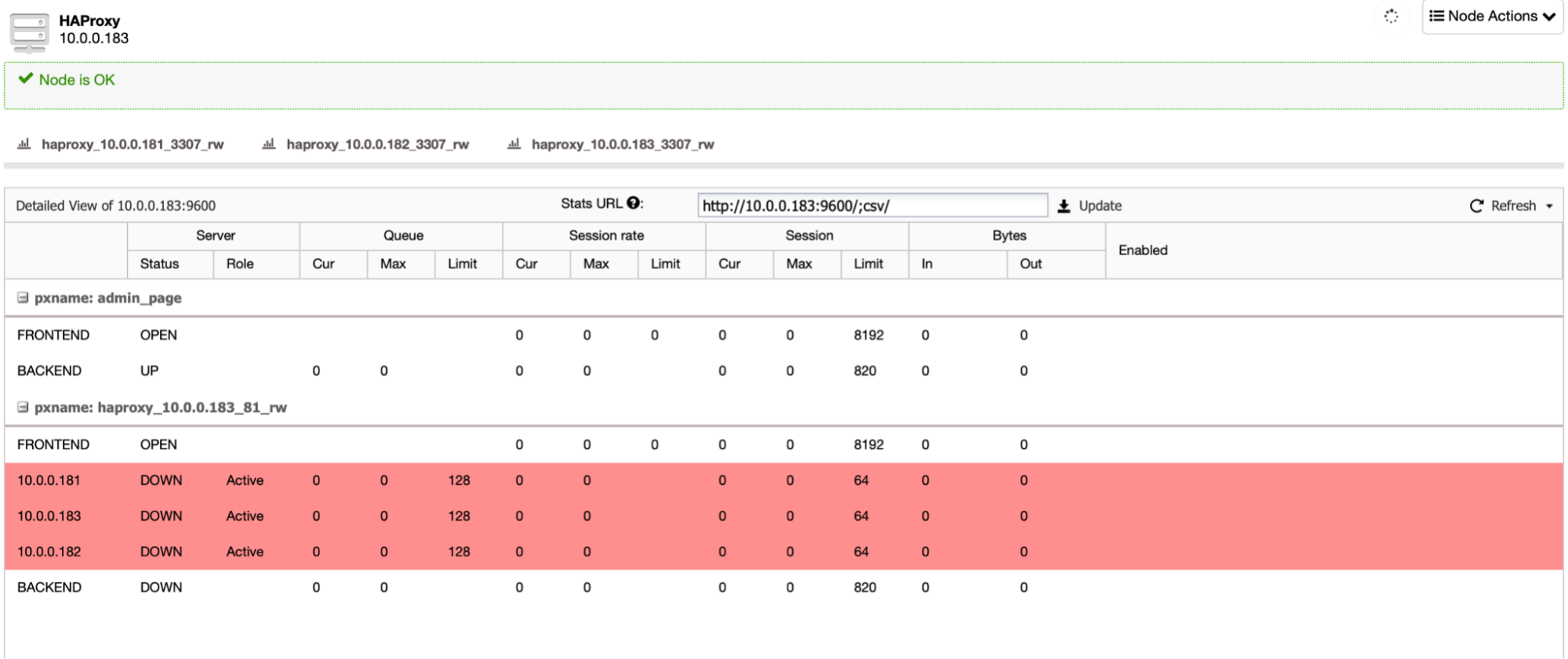
What is quite useful is that as long as it is doable, the ClusterControl cluster will recover the failed node. We can observe that via s9s command:
root@node2:~# s9s controller --list --long
S VERSION OWNER GROUP NAME IP PORT COMMENT
f 1.8.2.4596 system admins 10.0.0.181 10.0.0.181 9501 Accepting heartbeats.
l 1.8.2.4596 system admins 10.0.0.182 10.0.0.182 9501 Acting as leader.
f 1.8.2.4596 system admins 10.0.0.183 10.0.0.183 9501 Accepting heartbeats.
Total: 3 controller(s)As you can see, node 10.0.0.183 is up and “Accepting heartbeats” – it is acting now as a follower, the leader has not changed.
Cmon node is not responding
Another scenario that may happen is a case where the whole node becomes unresponsive. Let’s simulate it in our lab by stopping the virtual machine on which node 10.0.0.182 – the current leader – is located.
root@node1:~# s9s controller --list --long
S VERSION OWNER GROUP NAME IP PORT COMMENT
f 1.8.2.4596 system admins 10.0.0.181 10.0.0.181 9501 Accepting heartbeats.
- 1.8.2.4596 system admins 10.0.0.182 10.0.0.182 9501 Not accepting heartbeats.
l 1.8.2.4596 system admins 10.0.0.183 10.0.0.183 9501 Acting as leader.
Total: 3 controller(s)As expected, the process was exactly the same as in the previous example. One of the remaining nodes has been promoted to a “leader” status while the failed node is marked as out of the cluster and without connectivity. The only difference is that ClusterControl will not be able to recover a failed node because it is no longer a process that is not running but it is a whole VM that has failed.
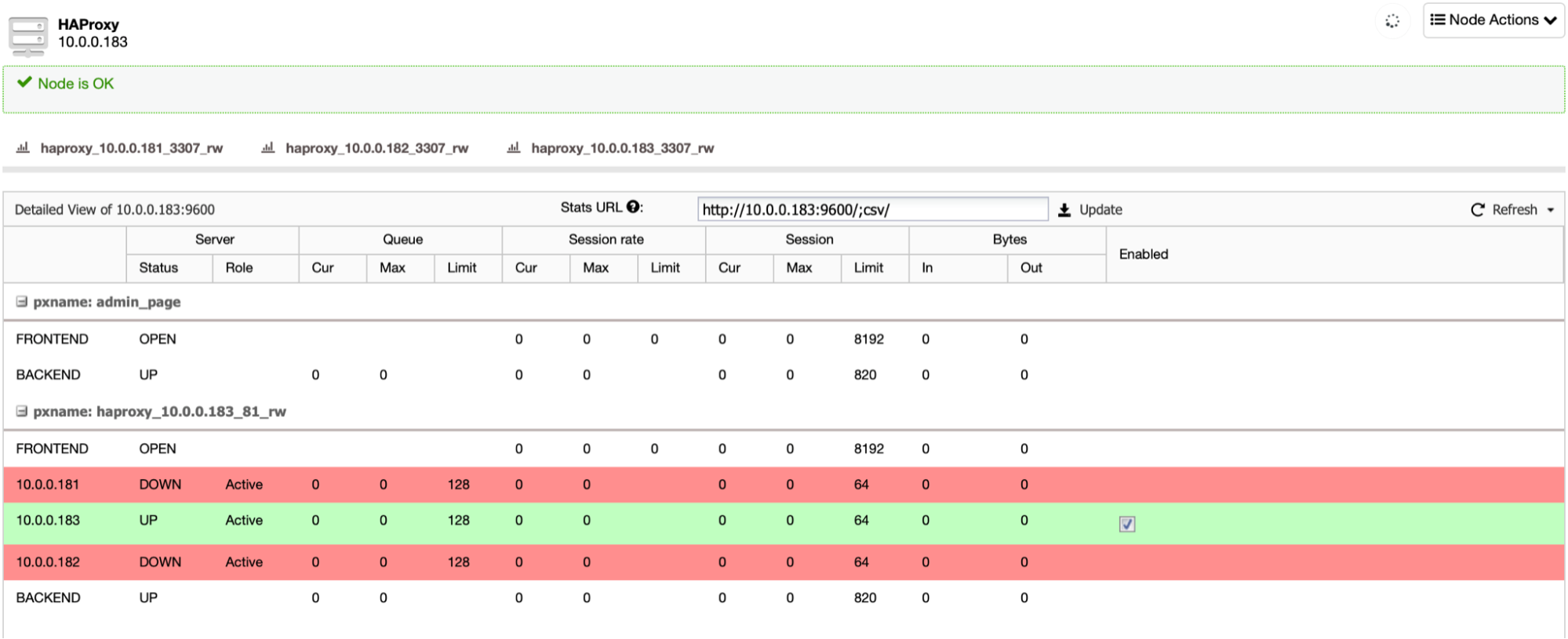
No surprises in our HAProxy panel, the new leader is marked as up, remaining nodes are down.
You can also track this in the configuration file for cmon service:
2021-06-14T13:28:35.999Z : (INFO) 10.0.0.183:9501: Cmon HA cluster contains 3 controller(s).
2021-06-14T13:28:35.999Z : (INFO)
HOSTNAME PORT ROLE STATUS_MESSAGE
10.0.0.181 9501 follower Accepting heartbeats.
10.0.0.182 9501 leader Acting as leader.
10.0.0.183 9501 follower Accepting heartbeats.
2021-06-14T13:28:39.023Z : (WARNING) 10.0.0.183:9501: Heartbeat timeout (elapsed: 3025ms > timeout: 2200ms).
2021-06-14T13:28:39.023Z : (INFO) 10.0.0.183:9501: +++ Starting an election. +++++++++
2021-06-14T13:28:39.023Z : (INFO) 10.0.0.183:9501: Controller state change from CmonControllerFollower to CmonControllerCandidate.
2021-06-14T13:28:39.023Z : (INFO) 10.0.0.183:9501: Stopping heartbeat receiver.
2021-06-14T13:28:39.029Z : (INFO) 10.0.0.183:9501: Requesting votes.
2021-06-14T13:28:39.029Z : (INFO) 10.0.0.183:9501: Requesting vote from 10.0.0.181:9501 for term 24.
2021-06-14T13:28:39.030Z : (INFO) 10.0.0.183:9501: Requesting vote from 10.0.0.182:9501 for term 24.
2021-06-14T13:28:39.042Z : (INFO) 10.0.0.183:9501: Has the majority votes: yes.
2021-06-14T13:28:39.042Z : (INFO) 10.0.0.183:9501: Controller state change from CmonControllerCandidate to CmonControllerLeader.
2021-06-14T13:28:39.042Z : (INFO) 10.0.0.183:9501: Stopping heartbeat receiver.
2021-06-14T13:28:39.042Z : (INFO) 10.0.0.183:9501: Heartbeat receiver stopped.
2021-06-14T13:28:39.043Z : (INFO) 10.0.0.183:9501: Starting heartbeats to 10.0.0.181:9501
2021-06-14T13:28:39.044Z : (INFO) 10.0.0.183:9501: The value for cmon_ha_heartbeat_network_timeout is 2.
2021-06-14T13:28:39.044Z : (INFO) 10.0.0.183:9501: The value for cmon_ha_heartbeat_interval_millis is 140698833650664.
2021-06-14T13:28:39.044Z : (INFO) 10.0.0.183:9501: Starting heartbeats to 10.0.0.182:9501
2021-06-14T13:28:39.045Z : (INFO) 10.0.0.183:9501: The value for cmon_ha_heartbeat_network_timeout is 2.
2021-06-14T13:28:39.045Z : (INFO) 10.0.0.183:9501: The value for cmon_ha_heartbeat_interval_millis is 140698833650664.
2021-06-14T13:28:39.046Z : (INFO) 10.0.0.183:9501: [853f] Controller become a leader, starting services.
2021-06-14T13:28:39.047Z : (INFO) Setting controller status to 'leader' in host manager.
2021-06-14T13:28:39.049Z : (INFO) Checking command handler.
2021-06-14T13:28:39.051Z : (INFO) 10.0.0.183:9501: Cmon HA cluster contains 3 controller(s).
2021-06-14T13:28:39.051Z : (INFO)
HOSTNAME PORT ROLE STATUS_MESSAGE
10.0.0.181 9501 follower Accepting heartbeats.
10.0.0.182 9501 controller Lost the leadership.
10.0.0.183 9501 leader Acting as leader.
2021-06-14T13:28:39.052Z : (INFO) Cmon HA is enabled, multiple controllers are allowed.
2021-06-14T13:28:39.052Z : (INFO) Starting the command handler.
2021-06-14T13:28:39.052Z : (INFO) Starting main loop.
2021-06-14T13:28:39.053Z : (INFO) Starting CmonCommandHandler.
2021-06-14T13:28:39.054Z : (INFO) The Cmon version is 1.8.2.4596.
2021-06-14T13:28:39.060Z : (INFO) CmonDb database is 'cmon' with schema version 107060.
2021-06-14T13:28:39.060Z : (INFO) Running cmon schema hot-fixes.
2021-06-14T13:28:39.060Z : (INFO) Applying modifications from 'cmon_db_mods_hotfix.sql'.
2021-06-14T13:28:41.046Z : (ERROR) 10.0.0.183:9501: Sending heartbeat to 10.0.0.182:9501 (leader) failed.
2021-06-14T13:28:41.047Z : (INFO) Host 10.0.0.182:9501 state changed from 'CmonHostOnline' to 'CmonHostOffLine'.
2021-06-14T13:28:41.048Z : (INFO) 10.0.0.183:9501: Cmon HA cluster contains 3 controller(s).
2021-06-14T13:28:41.048Z : (INFO)
HOSTNAME PORT ROLE STATUS_MESSAGE
10.0.0.181 9501 follower Accepting heartbeats.
10.0.0.182 9501 follower Not accepting heartbeats.
10.0.0.183 9501 leader Acting as leader.As you can see, there’s a clear indication that the leader stopped responding, a new leader has been elected and, finally, the old leader has been marked as unavailable.
If we will continue stopping more ClusterControl nodes, we will end up with a broken cluster:
The reason that this cluster has broken down is very simple: a three node cluster can survive failure of only one member node at the same time. If two nodes are down, the cluster will not be able to operate. This is represented in the log file:
2021-06-14T13:43:23.123Z : (ERROR) Cmon HA leader lost the quorum.
2021-06-14T13:43:23.123Z : (ERROR)
{ "class_name": "CmonHaLogEntry", "comment": "", "committed": false, "executed": false, "index": 5346, "last_committed_index": 5345, "last_committed_term": 24, "term": 24, "payload": { "class_name": "CmonHaLogPayload", "instruction": "SaveCmonUser", "cmon_user": { "class_name": "CmonUser", "cdt_path": "/", "owner_user_id": 3, "owner_user_name": "admin", "owner_group_id": 1, "owner_group_name": "admins", "acl": "user::rwx,group::r--,other::r--", "created": "2021-06-14T10:08:02.687Z", "disabled": false, "first_name": "Default", "last_failed_login": "", "last_login": "2021-06-14T13:43:22.958Z", "last_name": "User", "n_failed_logins": 0, "origin": "CmonDb", "password_encrypted": "77cb319920a407003449d9c248d475ce4445b3cf1a06fadfc4afb5f9c642c426", "password_format": "sha256", "password_salt": "a07c922c-c974-4160-8145-e8dfb24a23df", "suspended": false, "user_id": 3, "user_name": "admin", "groups": [ { "class_name": "CmonGroup", "cdt_path": "/groups", "owner_user_id": 1, "owner_user_name": "system", "owner_group_id": 1, "owner_group_name": "admins", "acl": "user::rwx,group::rwx,other::---", "created": "2021-06-14T10:08:02.539Z", "group_id": 1, "group_name": "admins" } ], "timezone": { "class_name": "CmonTimeZone", "name": "Coordinated Universal Time", "abbreviation": "UTC", "offset": 0, "use_dst": false } } } }Once you solve the problems with failed nodes, the cluster will rejoin:
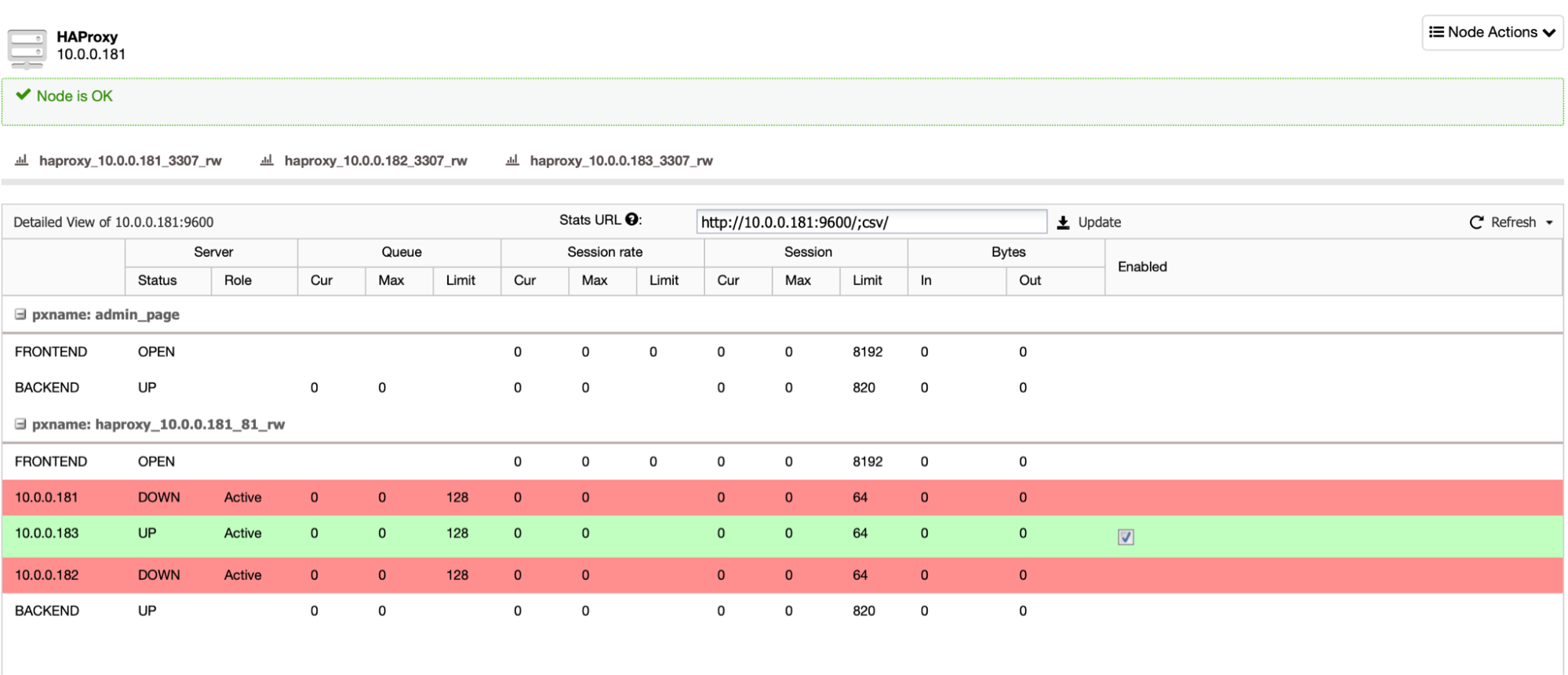
As you can see, the ClusterControl cluster can provide you with a highly available installation that can handle failure of some of the nodes, as long as the majority of the cluster is available. It can also self-heal and recover from more critical failures, ensuring that ClusterControl will keep monitoring your database and ensuring your business continuity is not compromised.
Summary
In this blog post we have covered a couple of scenarios where one of its database clusters’ nodes becomes unavailable. A couple of scenarios that you might notice is where one of the remaining database nodes will be promoted to a “leader” status where the failed node will be marked as unresponsive with or without ClusterControl being able to recover it. However, even if your clusters break down, solve a couple of problems (identify them by looking at log files) and you should be good to go!



