blog
Best Practices for Database Backups

Backups – one of the most important things to take care of while managing databases. It is said there are two types of people – those who backup their data and those who will backup their data. In this blog post, we will discuss good practices around backups and show you how you can build a reliable backup system using ClusterControl.
We will see how ClusterControl’s provides you with centralized backup management for MySQL, MariaDB, MongoDB and PostgreSQL. It provides you with hot backups of large datasets, point in time recovery, at-rest and in-transit data encryption, data integrity via automatic restore verification, cloud backups (AWS, Google and Azure) for Disaster Recovery, retention policies to ensure compliance, and automated alerts and reporting.
Backup types
There are two main types of backup that we can do in ClusterControl:
- Logical backup – backup of data is stored in a human-readable format like SQL
- Physical backup – backup contains binary data
Both complement each other – logical backup allows you to (more or less easily) retrieve up to a single row of data. Physical backups would require more time to accomplish that, but, on the other hand, they allow you to restore an entire host very quickly (something which may take hours or even days when using logical backup).
ClusterControl supports backup for MySQL/MariaDB/Percona Server, PostgreSQL, and MongoDB.
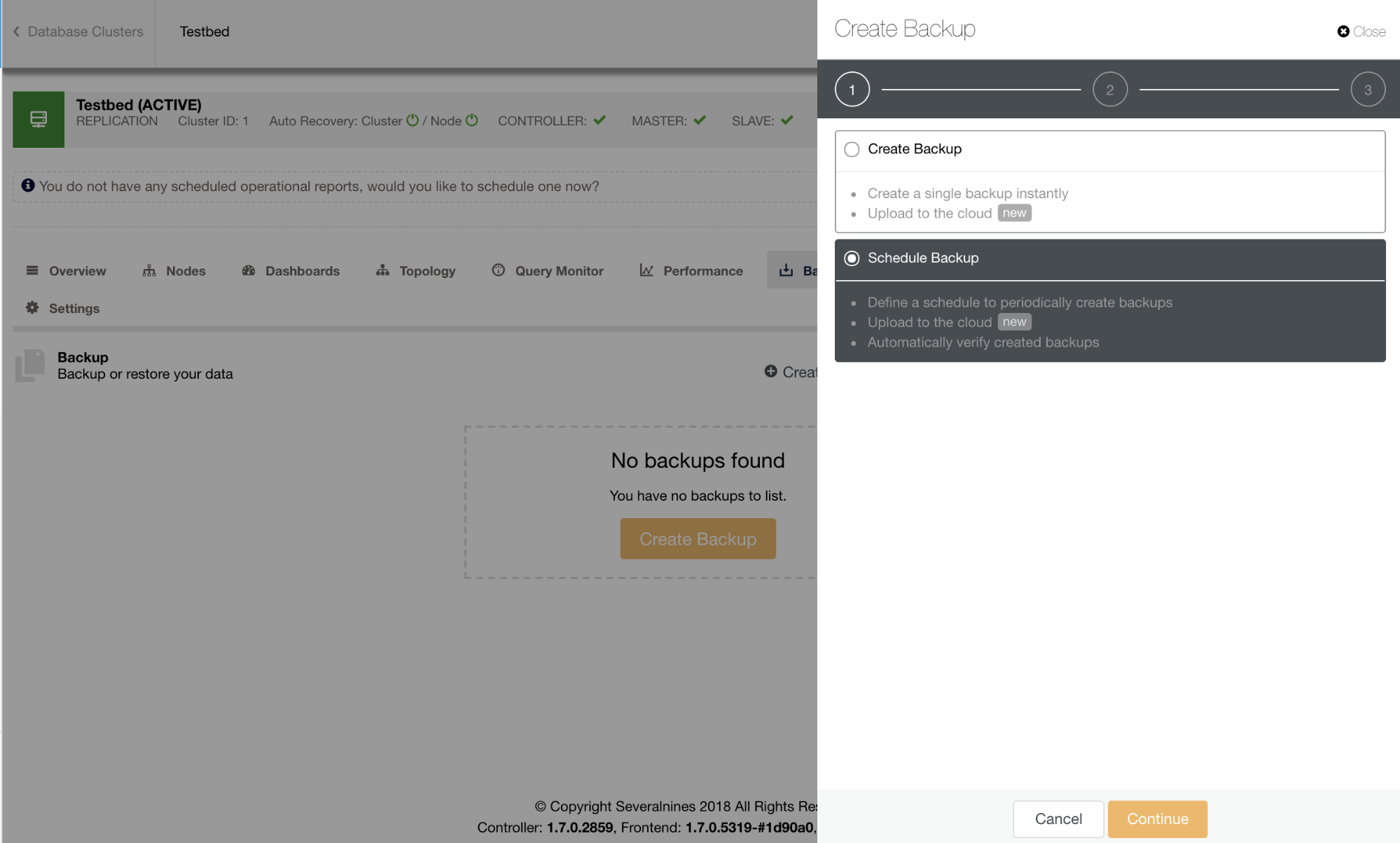
Schedule Backup
Starting a backup in ClusterControl is simple and efficient using a wizard. Scheduling a backup offers user-friendliness and accessibility to other features like encryption, automatic test/verification of backup, or cloud archiving.
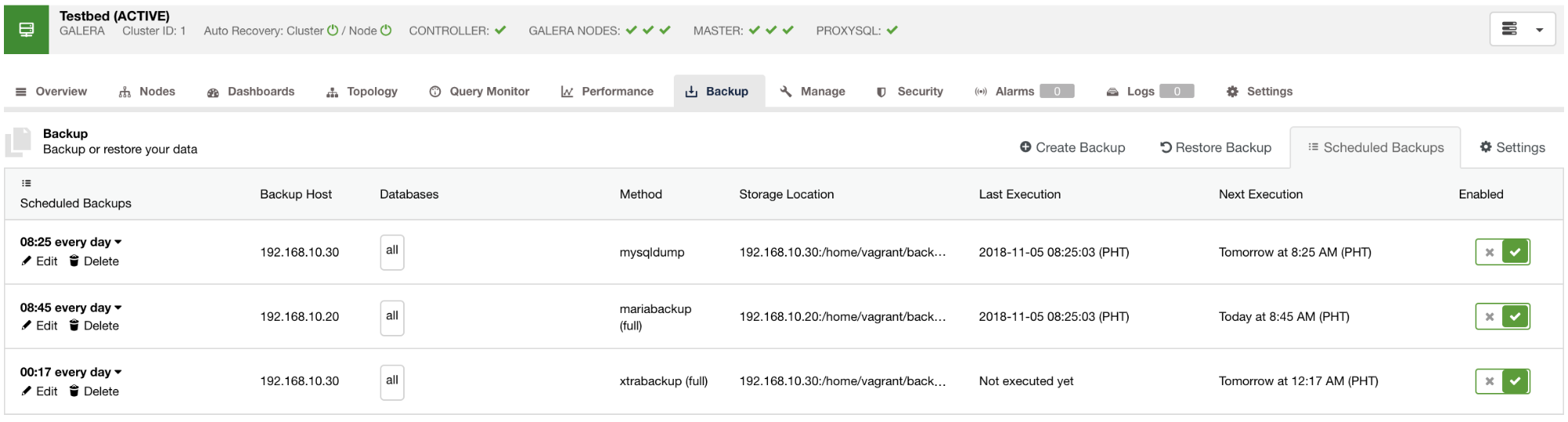
Scheduled backups available will be listed in the Scheduled Backups tab as seen in the image below:
As a good practice for scheduling a backup, you must have already your defined backup retention and a daily backup is recommended. However, it also depends on the data you need, the traffic you might expect and the availability of the data whenever you need them especially during data recovery where data had been accidentally deleted or a disk corruption – which are inevitable. There are situations also that data loss is reproducible or can be duplicated manually like for example, report generation, thumbnails, or cached data. Though the question relies on how immediately you need them whenever a disaster happens; when possible, you’d want to take both mysqldump and xtrabackup backups on a daily basis for MySQL leveraging the logical and physical backup availability. To cover even more bases, you may want to schedule several incremental xtrabackup runs per day. This could save some disk space, disk I/O, or even CPU I/O than taking a full backup.
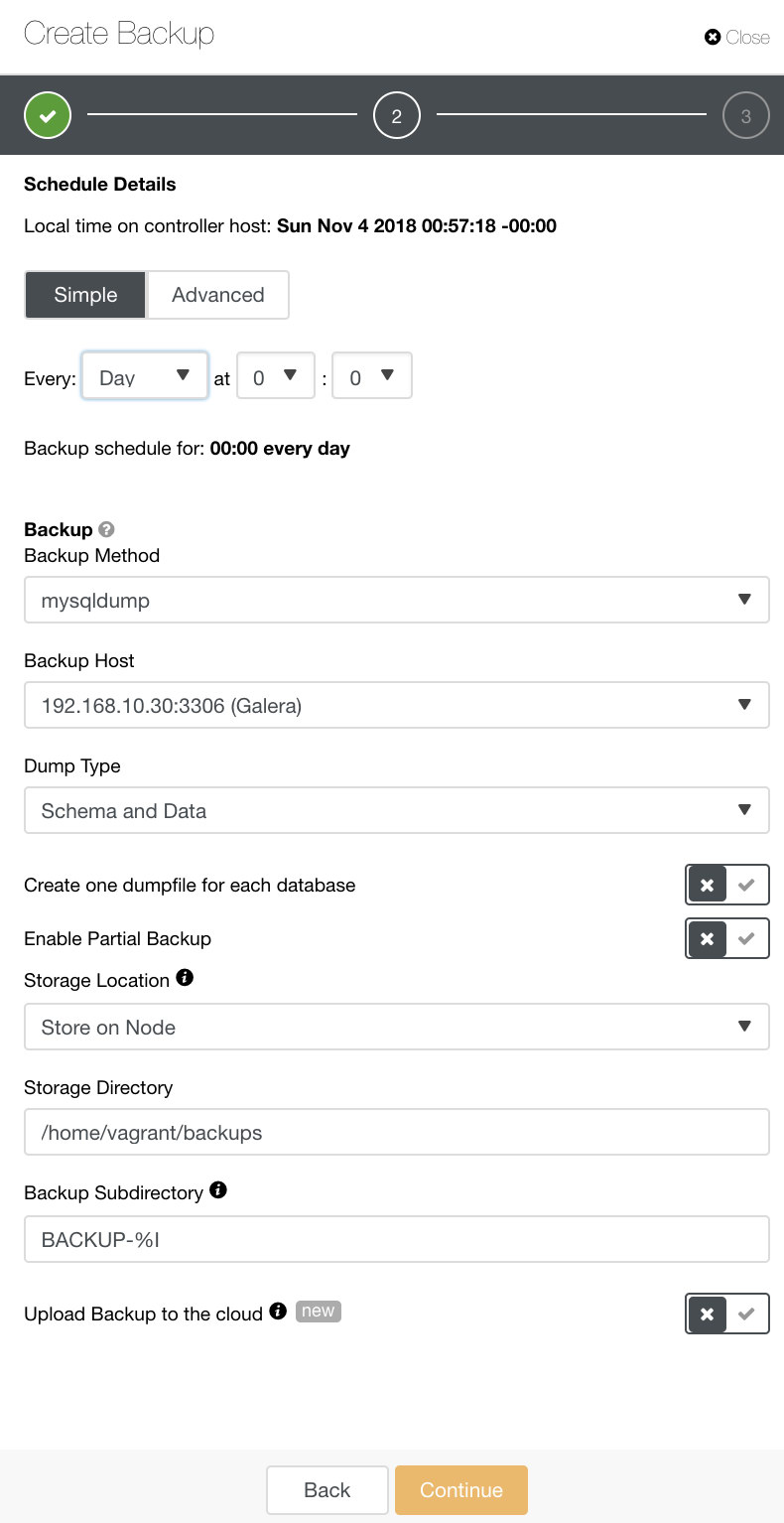
In ClusterControl, you can easily schedule these different types of backups. There are a couple of settings to decide on. You can store a backup on the controller or locally, on the database node where the backup is taken. You need to decide on the location in which the backup should be stored, and which databases you’d like to backup–all data set or separate schemas? See the image below:
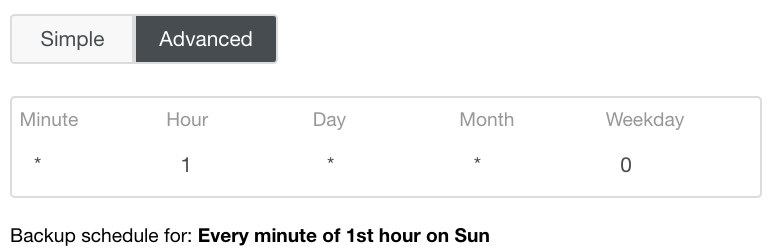
The Advanced setting would take advantage of a cron-like configuration for more granularity. See image below:
Whenever a failure occurs, ClusterControl handle these issues efficiently and does produces logs for further diagnosis of the backup failure.
Depending on the backup type you’ve chosen, there are separate settings to configure. For Xtrabackup and Galera Cluster, you may have the options to choose what settings your physical backup would apply upon running. See below:
- Use Compression
- Compression Level
- Desync node during backup
- Backup Locks
- Lock DDL per Table
- Xtrabackup Parallel Copy Threads
- Network Streaming Throttle Rate (MB/s)
- Use PIGZ for parallel gzip
- Enable Encryption
- Retention
You can see, in the image below, how you could flag the options accordingly and there are tooltip icons which provide more information of the options you would like to leverage for your backup policy.
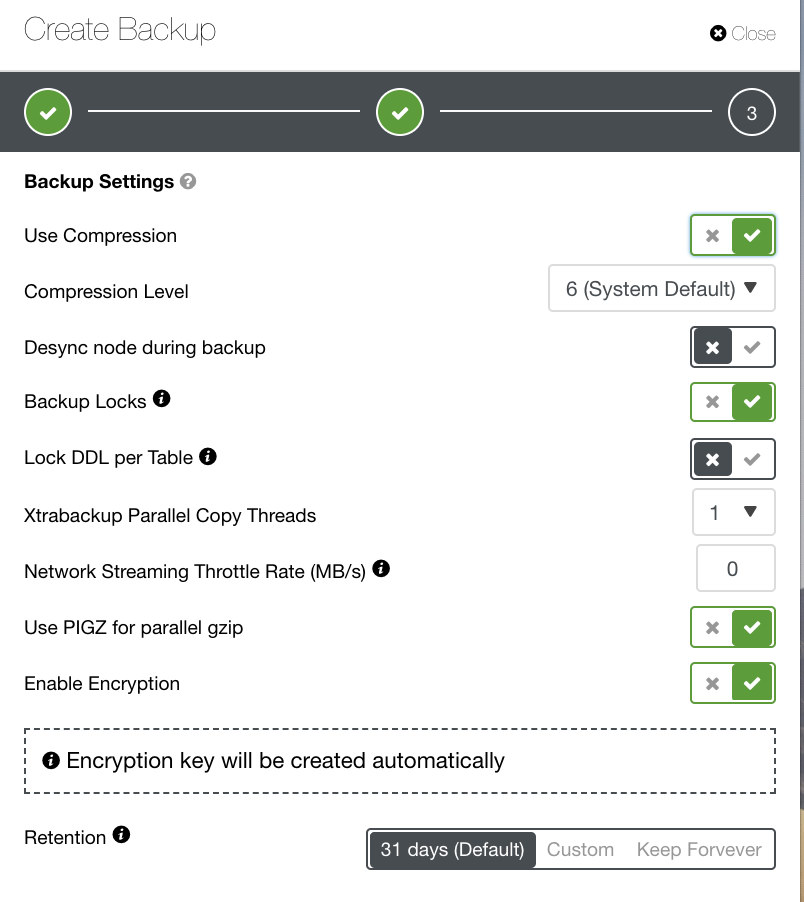
Depending on your backup policy, ClusterControl can be tailored in accordance to the best practices for taking your backups that are available up-to-date. Upon defining your backup policy, it is anticipated that you must have your required setup available from hardware to software to cloud, durability, high availability, or scalability.
When taking backups on a Galera Cluster, it’s a good practice to set the Galera node wsrep_desync=ON while the backup is running. This will take out the node from participating the Flow Control and will protect the whole cluster from replication lag, especially if your data to be backed up is large. In ClusterControl, please keep in mind that this may also remove your target backup node from the load balancing set. This is especially true if you use HAProxy, ProxySQL, orMaxScale proxies. If you have alert manager set up in case the node is desynced, you can turn off during those period when the backup has been triggered.
Another popular way of minimizing the impact of a backup on a Galera Cluster or a replication master is to deploy a replication slave and then use it as a source of backups – this way Galera Cluster will not be affected at any point as the backup on the slave is decoupled from the cluster.
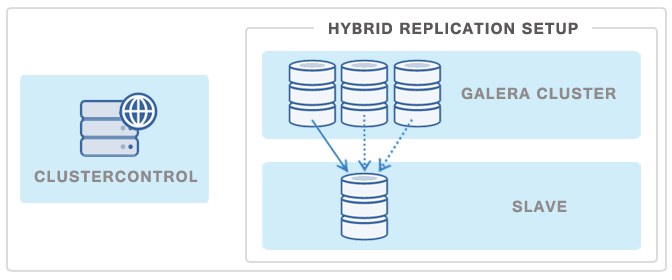
You can deploy such a slave in just a few clicks using ClusterControl. See image below:
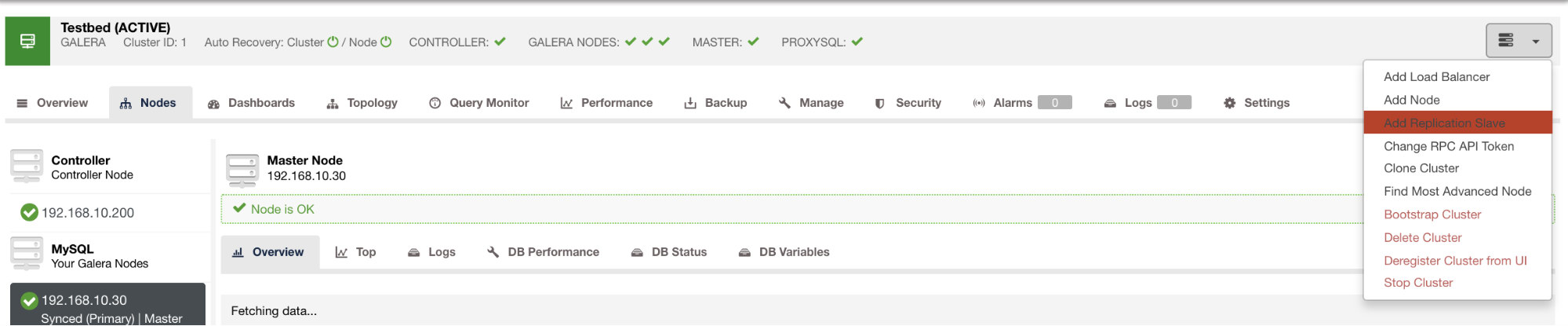
and once you click that button, you can select which nodes to setup a slave on. Make sure that the nodes binary logging enabled. Enabling the binary log can also be done through ClusterControl which adds more feasibility for administrating your desired master. See image below:
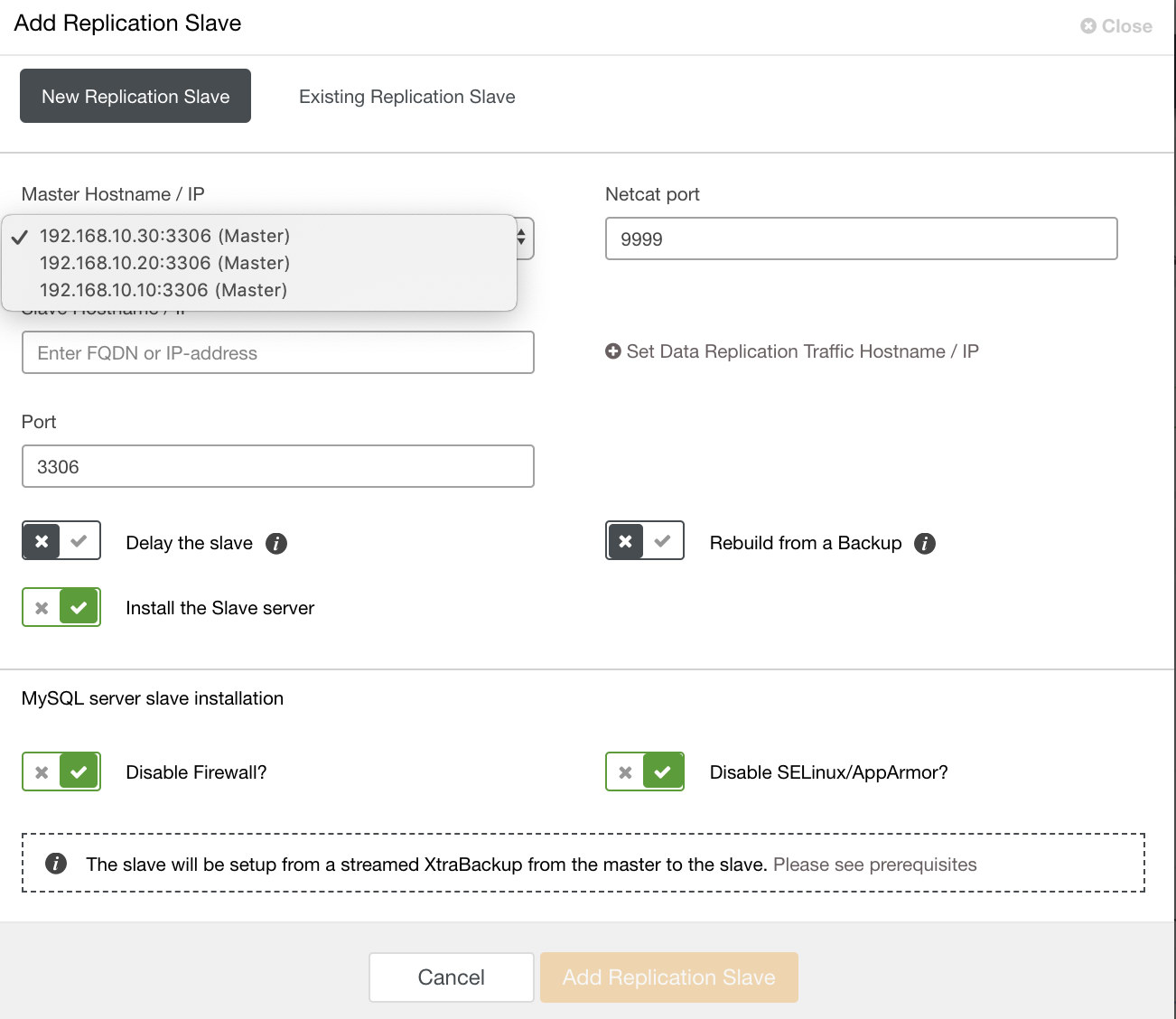
and you can also setup existing replication slave as well,
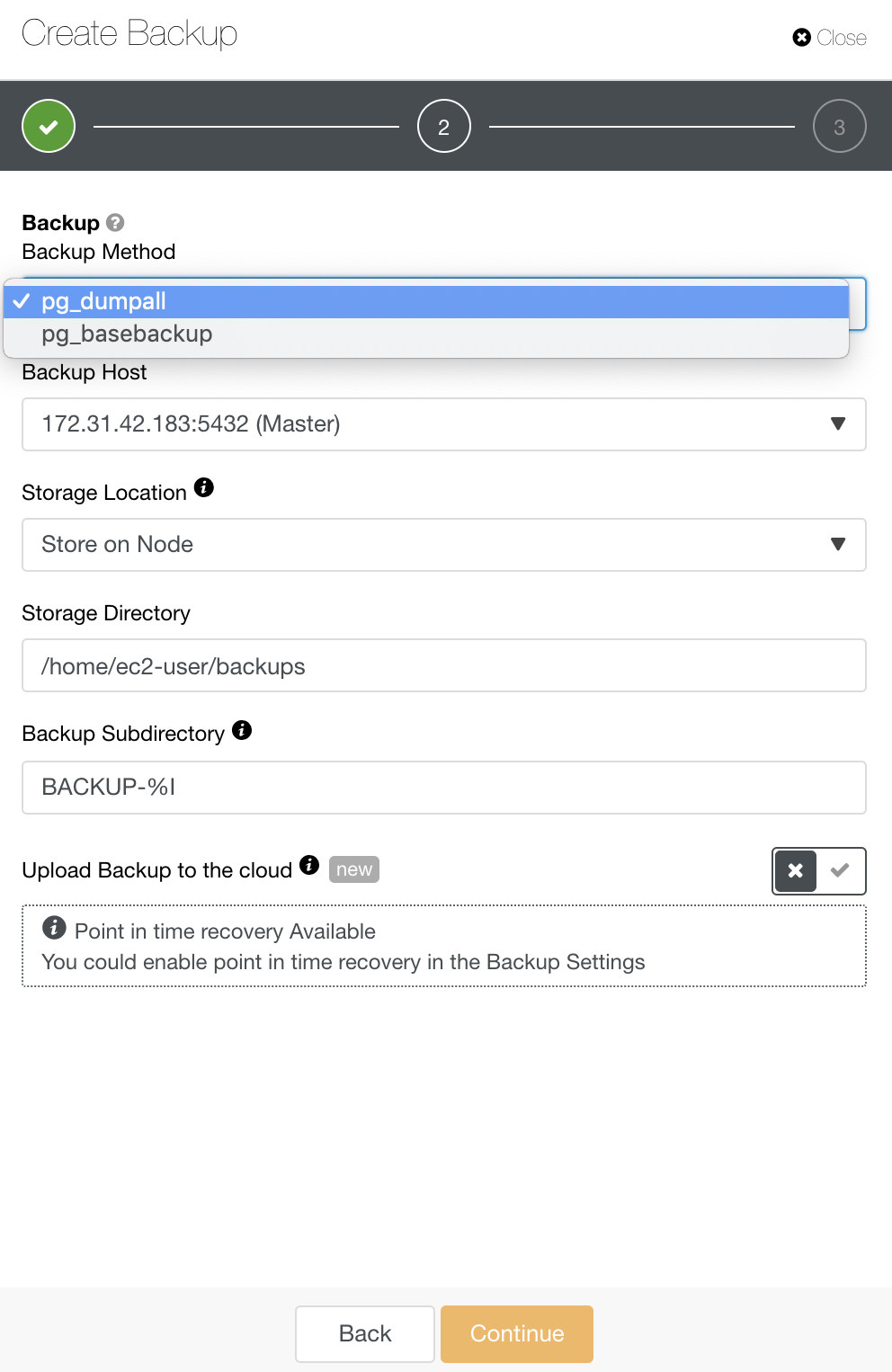
For PostgreSQL, you have options to backup either logical or physical backups. In ClusterControl, you can leverage your PostgreSQL backups by selecting pg_dump or pg_basebackup. pg_basebackup will not work for versions older than 9.3.
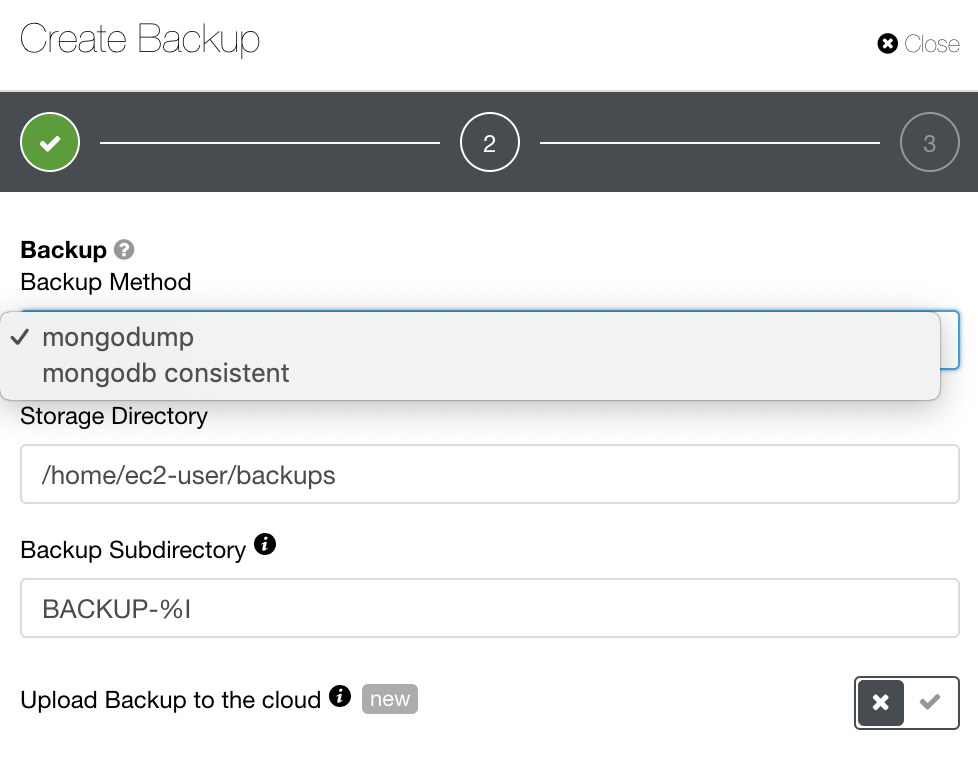
For MongoDB, ClusterControl offers mongodump or mongodb consistent. You might have to take note that mongodb consistent does not support RHEL 7 but you might be able to install it manually.
By default, ClusterControl will list a report for all the backups that have been taken, successful or failed ones. See below:
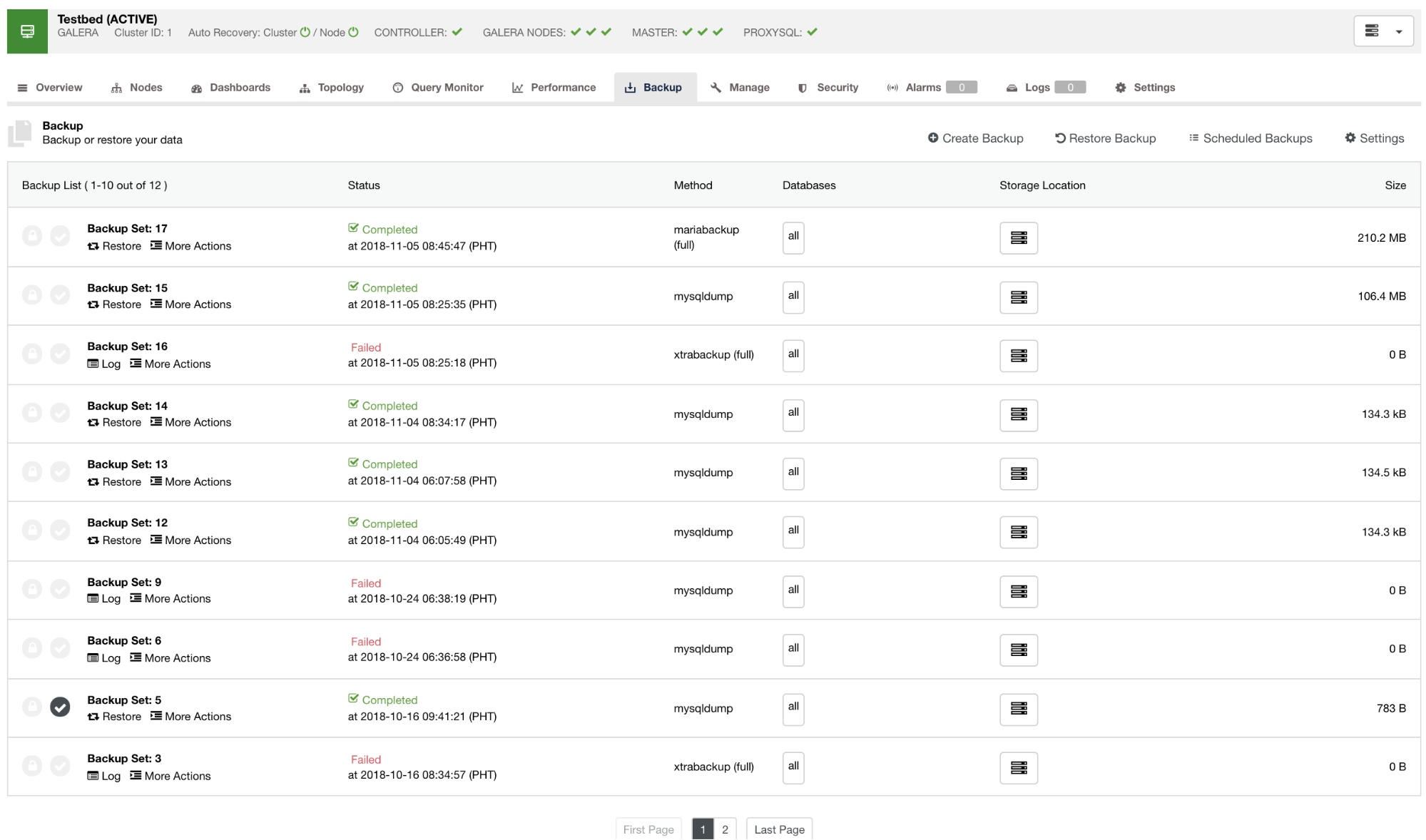
You can check on the list of backup reports that have been created or scheduled using ClusterControl. Within the list, you can view the logs for further investigation and diagnosis. For instance, if the backup did finish correctly according to your desired backup policy, whether compression and encryption is set correctly, or if the desired backup data size is correct. This is a good way to do a quick sanity check – if your dataset is around 1GB of size, there’s no way a full backup can be as small as 100KB – something must have gone wrong at some point.
Disaster Recovery
Storing backups within the cluster (either directly on a database node or on the ClusterControl host) comes in handy when you want to quickly restore your data: all backup files are in place and can be decompressed and restored promptly. When it comes to Disaster Recovery (DR), this may not be the best option. Different issues may happen – servers may crash, network may not work reliably, even entire data centers may not be accessible due to some kind of outage. It may happen whether you work with a smaller service provider with a single data center, or a global vendor like Amazon Web Services. It is therefore not safe to keep all your eggs in a single basket – you should make sure you have a copy of your backup stored in some external location. ClusterControl supports Amazon S3, Google Storage and Azure Cloud Storage .
For those who would like to implement their own DR policies, ClusterControl backups are stored in a nicely structured directory. You have also the option to upload your backup to the cloud. See image below:
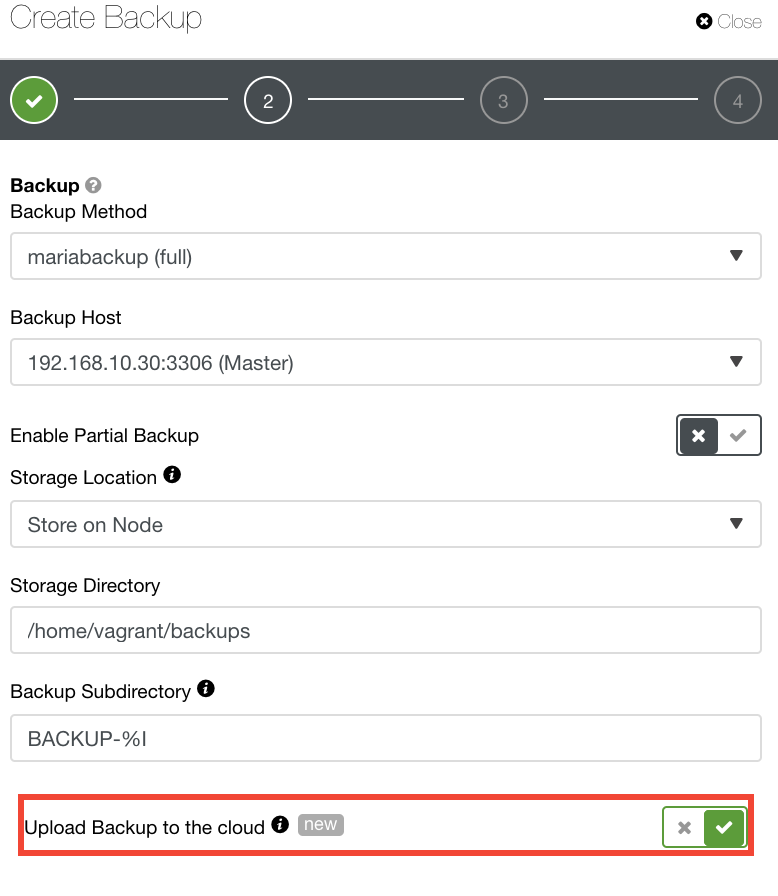
You can select and upload to Amazon Web Services, Google Cloud, and Microsoft Azure. See image below:
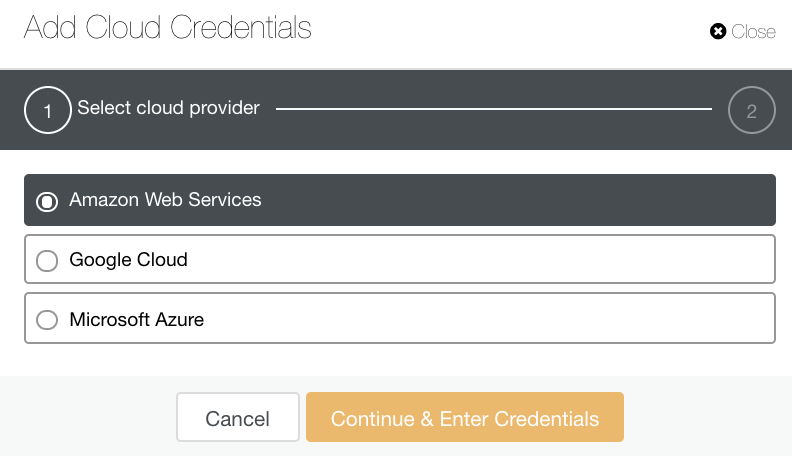
As a good practice when archiving your database backups, make sure that your target cloud destination is based on the same region as your database servers, or at least the nearest. Ensure that it offers high availability, durability, and scalability; as you have to consider how often and immediate do you need your data.
In addition to creating a logical or physical backup for your DR, creating a full snapshot of your data (e.g. using LVM Snapshot, Amazon EBS Snapshots, or Volume Snapshots if using Veritas file system) on the particular node can increase your backup recovery. You can also use WAL (for Postgres) for your Point In Time Recovery (PITR) or your MySQL binary logs for your PITR. Thus, you have to consider that you might need to create your own archiving for your PITR. So it is perfectly fine to build and deploy your own set of scripts and handle DR according to your exact requirements.
Another great way of implementing a Disaster Recovery policy is to use an asynchronous replication slave – something we mentioned earlier in this blog post. You can deploy such asynchronous slave in a remote location, some other data center maybe, and then use it to do backups and store them locally on that slave. Of course, you’d want to take a local backup of your cluster to have it around locally if you’d need to recover the cluster. Moving data between data centers may take a long time, so having a backup files available locally can save you some time. In case you lose the access to your main production cluster, you may still have an access to the slave. This setup is very flexible – first, you have a running MySQL host with your production data so it shouldn’t be too hard to deploy your full application in the DR site. You’ll also have backups of your production data which you could use to scale out your DR environment.
Lastly and most importantly, a backup that has not been tested remains an unverified backup, aka Schroedinger Backup. To make sure you have a working backup, you need to perform a recovery test. ClusterControl offers a way to automatically verify and test your backup.
We hope this gives you enough information to build a safe and reliable backup procedure for your open source databases.



