blog
ClusterControl 1.5 – Automatic Backup Verification, Build Slave From Backup and Cloud Integration

At the core of ClusterControl is its automation, as is ensuring that your data is is securely backed up and ready for restoration whenever something goes wrong. Having an effective backup strategy and disaster recovery plan is key to the success of any application or environment.
In our latest release, ClusterControl 1.5, we have introduced a number of enhancements for backing up MySQL and MariaDB-based systems.
One of the key improvements is the ability to backup from ClusterControl to the cloud provider of your choice. Cloud providers like Google Cloud Services and Amazon S3 each offer virtually unlimited storage, reducing local space needs. This allows you to retain your backup files longer, for as long as you would like and not have concerns around local disk space.
Let’s explore all the exciting new backup features for ClusterControl 1.5…
Backup/Restore Wizard Redesign
First of all, you will notice backup and restore wizards have been revamped to better improve the user experience. It will now load as a side menu on the right of the screen:
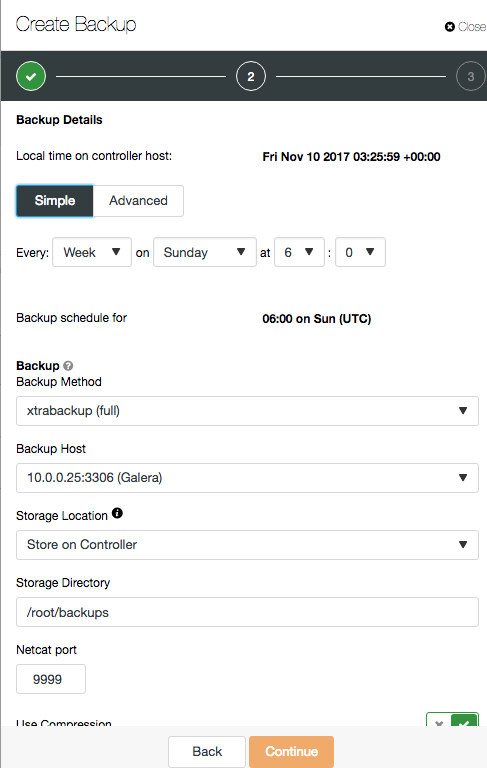
The backup list is also getting a minor tweak where backup details are displayed when you click on the particular backup:
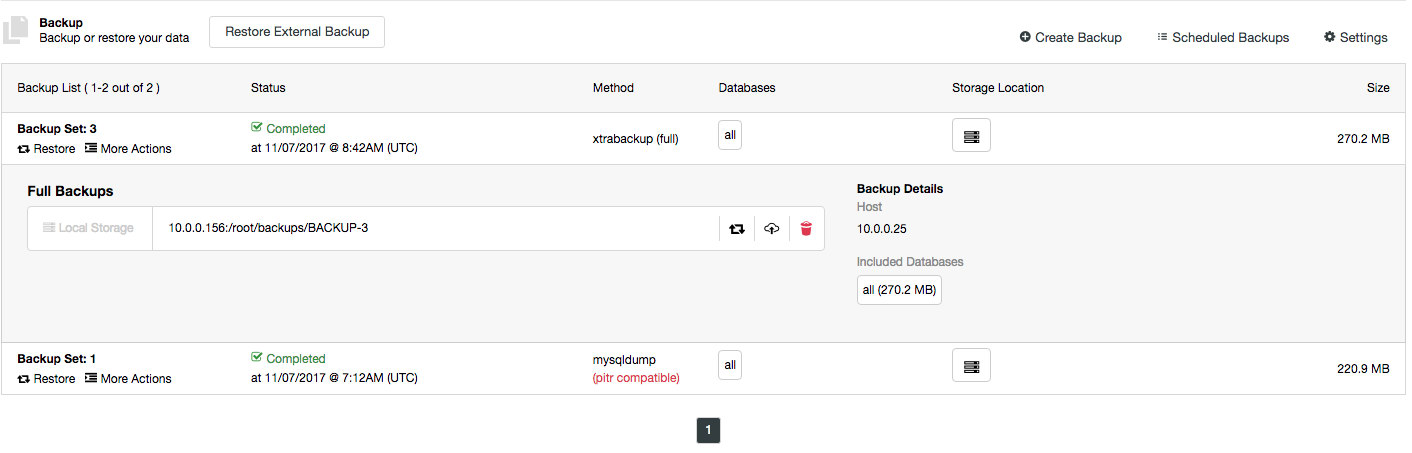
You will be able to view backup location and which databases are inside the backup. There are also options to restore the backup or upload it into the cloud.
PITR Compatible Backup
ClusterControl performs the standard mysqldump backup with separate schema and data dumps. This makes it easy to restore partial backups. However, it breaks the consistency of the backup (schema and data are dumped in two separate sessions), thus it cannot be used to provision a slave or point-in-time recovery.
A mysqldump PITR-compatible backup contains one single dump file, with GTID info, binlog file and position. Thus, only the database node that produces binary log will have the “PITR compatible” option available, as highlighted in the screenshot below:
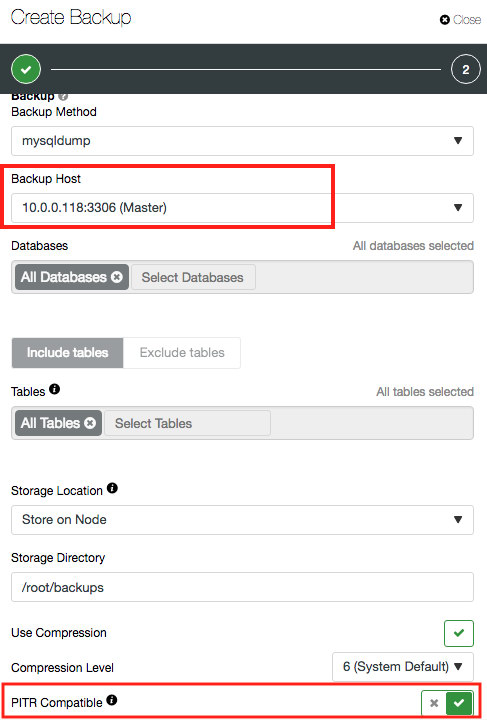
When PITR compatible option is toggled, the database and table fields are greyed out since ClusterControl will always perform the backup against all databases, events, triggers and routines of the target MySQL server.
The following lines will appear in the first ~50 lines of the completed dump file:
$ head -50 mysqldump_2017-11-07_072250_complete.sql
...
-- GTID state at the beginning of the backup
--
SET @@GLOBAL.GTID_PURGED='20dc5247-4a98-ee18-73af-5c79373388ee:1-1681';
--
-- Position to start replication or point-in-time recovery from
--
CHANGE MASTER TO MASTER_LOG_FILE='binlog.000001', MASTER_LOG_POS=2457790;
...The information can be used to build slaves from backup, or perform point-in-time recovery together with binary logs, where you can start the recovery from the MASTER_LOG_FILE and MASTER_LOG_POS reported in the dump file using “mysqlbinlog” utility. Note that binary logs are not backed up by ClusterControl.
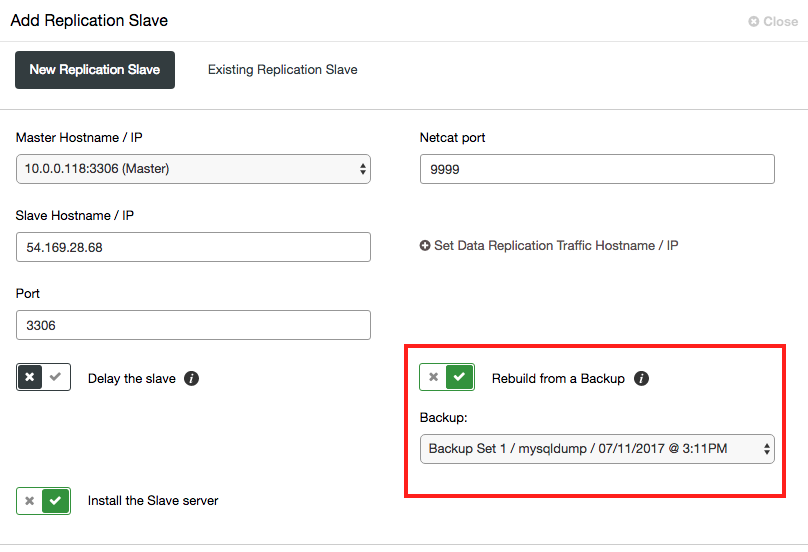
Once the staging completes, the slave will connect to the chosen master and start catching up. Previously, ClusterControl performed a streaming backup directly from the chosen master using Percona Xtrabackup. This could impact performance of the master when scaling out a large dataset, despite the operation being non blocking on the master. With the new option, if the backup is stored on ClusterControl, only these hosts (ClusterControl + the slave) will be busy when staging the data on the slave.
Backup to Cloud
Backups can now be automatically uploaded in the cloud. This requires a ClusterControl module to be installed, called clustercontrol-cloud (Cloud integration module) and clustercontrol-clud (Cloud download/upload CLI) which are available in v1.5 and later. The upgrade instructions have been included with these packages and they come without any extra configuration. At the moment, the supported cloud platforms are Amazon Web Services and Google Cloud Platform. Cloud credentials are configured under ClusterControl -> Settings -> Integrations -> Cloud Providers.
When creating or scheduling a backup, you should see the following additional options when “Upload Backup to the cloud” is toggled:
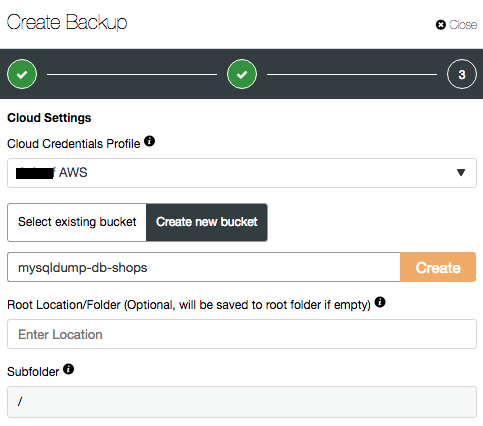
The feature allows a one time upload or to schedule backups to be uploaded after completion (Amazon S3 or Google Cloud Storage). You can then download and restore the backups as required.
Custom Compression for mysqldump
This feature was in fact first introduced with ClusterControl v1.4.2 after its release. We added a backup compression level based on gzip. Previously, ClusterControl used the default backup compression (level 6) if the backup destination was on the controller node. The lowest compression (level 1 – fastest, less compression) was used if the backup destination was on the database host itself, to ensure minimal impact to the database during the compressing operation.
In this version, we have polished the compression aspect and you can now customize the compression level, regardless of the backup destination. When upgrading your ClusterControl instance, all the scheduled backups will be automatically converted to use level 6, unless you explicitly edit them in v1.5.
Backup compression is vital when your dataset is large, combined with a long backup retention policy, while storage space is limited. Mysqldump, which is text-based, can benefit from compression with savings of up to 60% of disk space of the original file size. On some occasions, the highest compression ratio is the best option to go, although it comes at the price of longer decompression when restoring.
Bonus Feature: Automatic Backup Verification
As old sysadmins say – A backup is not a backup if it’s not restorable. Backup verification is something that is usually neglected by many. Some sysadmins have developed in-house routines for this, usually more manual than automated. Automating it is hard, mainly due to the complexity of the operation as a whole – starting from host provisioning, MySQL installation and preparation, backup files transfer, decompression, restore operation, verification procedures and finally cleaning up the system after the process. All these hassles make people neglect such an important aspect of a reliable backup. In general a backup restore test should be done at least once a month, or in case of significant changes in data size or database structure. Find a schedule that works for you and formalize it with a scheduled event.
ClusterControl can automate the backup verification by performing the restoration on a fresh host, without compromising any of the verification procedures mentioned above. This can be done after some delay, or right after the backup has completed. It will report the backup status based on the exit code of the restore operation, perform automatic shutdown if the backup is verified, or simply let the restored host run so you perform additional manual verifications on the data.
When creating or scheduling a backup, you will have additional options if “Verify Backup” is toggled:
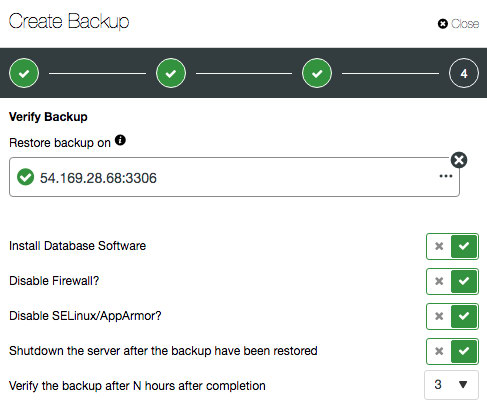
If “Install Database Software” is enabled, ClusterControl will remove any existing MySQL installation on the target host and reinstall the database software with the same version as the existing MySQL server. Otherwise, if you have a specific setup for the restored host, you can skip this option. The rest of the options are self-explanatory.
Bonus Feature: Don’t Forget PostgreSQL
In addition to all this great functionality for MySQL and MariaDB ClusterControl 1.5 also now provides PostgreSQL with an additional backup method (pg_basebackup) that can be used for online binary backups. Backups taken with pg_basebackup can be used later for point-in-time recovery and as the starting point for a log shipping or streaming replication standby servers.
That’s it for now. Do give ClusterControl v1.5 a try, play around with the new features and let us know what you think.



