blog
Big Data with PostgreSQL and Apache Spark

PostgreSQL is well known as the most advanced opensource database, and it helps you to manage your data no matter how big, small or different the dataset is, so you can use it to manage or analyze your big data, and of course, there are several ways to make this possible, e.g Apache Spark. In this blog, we’ll see what Apache Spark is and how we can use it to work with our PostgreSQL database.
For big data analytics, we have two different types of analytics:
- Batch analytics: Based on the data collected over a period of time.
- Real-time (stream) analytics: Based on an immediate data for an instant result.
What is Apache Spark?
Apache Spark is a unified analytics engine for large-scale data processing that can work on both batch and real-time analytics in a faster and easier way.
It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs.
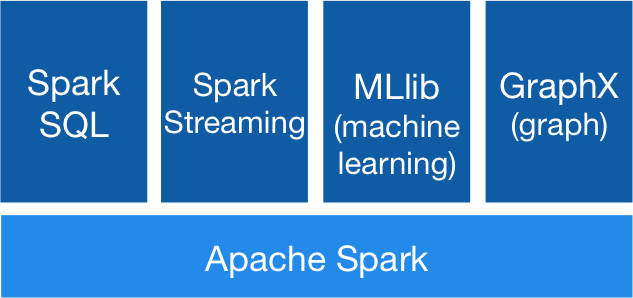
Apache Spark Libraries
Apache Spark includes different libraries:
- Spark SQL: It’s a module for working with structured data using SQL or a DataFrame API. It provides a common way to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC. You can even join data across these sources.
- Spark Streaming: It makes easy to build scalable fault-tolerant streaming applications using a language-integrated API to stream processing, letting you write streaming jobs the same way you write batch jobs. It supports Java, Scala and Python. Spark Streaming recovers both lost work and operator state out of the box, without any extra code on your part. It lets you reuse the same code for batch processing, join streams against historical data, or run ad-hoc queries on stream state.
- MLib (Machine Learning): It’s a scalable machine learning library. MLlib contains high-quality algorithms that leverage iteration and can yield better results than the one-pass approximations sometimes used on MapReduce.
- GraphX: It’s an API for graphs and graph-parallel computation. GraphX unifies ETL, exploratory analysis, and iterative graph computation within a single system. You can view the same data as both graphs and collections, transform and join graphs with RDDs efficiently, and write custom iterative graph algorithms using the Pregel API.
Apache Spark Advantages
According to the official documentation, some advantages of Apache Spark are:
- Speed: Run workloads 100x faster. Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG (Direct Acyclic Graph) scheduler, a query optimizer, and a physical execution engine.
- Ease of Use: Write applications quickly in Java, Scala, Python, R, and SQL. Spark offers over 80 high-level operators that make it easy to build parallel apps. You can use it interactively from the Scala, Python, R, and SQL shells.
- Generality: Combine SQL, streaming, and complex analytics. Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
- Runs Everywhere: Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources. You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
Now, let’s see how we can integrate this with our PostgreSQL database.
How to Use Apache Spark with PostgreSQL
We’ll assume you have your PostgreSQL cluster up and running. For this task, we’ll use a PostgreSQL 11 server running on CentOS7.
First, let’s create our testing database on our PostgreSQL server:
postgres=# CREATE DATABASE testing;
CREATE DATABASE
postgres=# c testing
You are now connected to database "testing" as user "postgres".Now, we’re going to create a table called t1:
testing=# CREATE TABLE t1 (id int, name text);
CREATE TABLEAnd insert some data there:
testing=# INSERT INTO t1 VALUES (1,'name1');
INSERT 0 1
testing=# INSERT INTO t1 VALUES (2,'name2');
INSERT 0 1Check the data created:
testing=# SELECT * FROM t1;
id | name
----+-------
1 | name1
2 | name2
(2 rows)To connect Apache Spark to our PostgreSQL database, we’ll use a JDBC connector. You can download it from here.
$ wget https://jdbc.postgresql.org/download/postgresql-42.2.6.jarNow, let’s install Apache Spark. For this, we need to download the spark packages from here.
$ wget http://us.mirrors.quenda.co/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
$ tar zxvf spark-2.4.3-bin-hadoop2.7.tgz
$ cd spark-2.4.3-bin-hadoop2.7/To run the Spark shell we’ll need JAVA installed on our server:
$ yum install javaSo now, we can run our Spark Shell:
$ ./bin/spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://ApacheSpark1:4040
Spark context available as 'sc' (master = local[*], app id = local-1563907528854).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/_,_/_/ /_/_ version 2.4.3
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala>We can access our Spark context Web UI available in the port 4040 on our server:
Into the Spark shell, we need to add the PostgreSQL JDBC driver:
scala> :require /path/to/postgresql-42.2.6.jar
Added '/path/to/postgresql-42.2.6.jar' to classpath.
scala> import java.util.Properties
import java.util.PropertiesAnd add the JDBC information to be used by Spark:
scala> val url = "jdbc:postgresql://localhost:5432/testing"
url: String = jdbc:postgresql://localhost:5432/testing
scala> val connectionProperties = new Properties()
connectionProperties: java.util.Properties = {}
scala> connectionProperties.setProperty("Driver", "org.postgresql.Driver")
res6: Object = nullNow, we can execute SQL queries. First, let’s define query1 as SELECT * FROM t1, our testing table.
scala> val query1 = "(SELECT * FROM t1) as q1"
query1: String = (SELECT * FROM t1) as q1And create the DataFrame:
scala> val query1df = spark.read.jdbc(url, query1, connectionProperties)
query1df: org.apache.spark.sql.DataFrame = [id: int, name: string]
So now, we can perform an action over this DataFrame:
scala> query1df.show()
+---+-----+
| id| name|
+---+-----+
| 1|name1|
| 2|name2|
+---+-----+scala> query1df.explain
== Physical Plan ==
*(1) Scan JDBCRelation((SELECT * FROM t1) as q1) [numPartitions=1] [id#19,name#20] PushedFilters: [], ReadSchema: structWe can add more values and run it again just to confirm that it’s returning the current values.
PostgreSQL
testing=# INSERT INTO t1 VALUES (10,'name10'), (11,'name11'), (12,'name12'), (13,'name13'), (14,'name14'), (15,'name15');
INSERT 0 6
testing=# SELECT * FROM t1;
id | name
----+--------
1 | name1
2 | name2
10 | name10
11 | name11
12 | name12
13 | name13
14 | name14
15 | name15
(8 rows)Spark
scala> query1df.show()
+---+------+
| id| name|
+---+------+
| 1| name1|
| 2| name2|
| 10|name10|
| 11|name11|
| 12|name12|
| 13|name13|
| 14|name14|
| 15|name15|
+---+------+In our example, we’re showing only how Apache Spark works with our PostgreSQL database, not how it manages our Big Data information.
Conclusion
Nowadays, it’s pretty common to have the challenge to manage big data in a company, and as we could see, we can use Apache Spark to cope with it and make use of all the features that we mentioned earlier. The big data is a huge world, so you can check the official documentation for more information about the usage of Apache Spark and PostgreSQL and fit it to your requirements.



